zookeeper入门知识
ZooKeeper 是什么?
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、小猪(Pig) 的管理员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项目中都采用到了 Zookeeper。ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,ZooKeeper是以Fast Paxos算法为基础,实现同步服务,配置维护和命名服务等分布式应用。
Zookeeper是hadoop的一个子项目,虽然源自hadoop,但是我发现zookeeper脱离hadoop的范畴开发分布式框架的运 用越来越多。今天我想谈谈zookeeper,本文不谈如何使用zookeeper,而是zookeeper到底有哪些实际的运用,哪些类型的应用能发挥 zookeeper的优势,最后谈谈zookeeper对分布式网站架构能产生怎样的作用。
Zookeeper是针对大型分布式系统的高可靠的协调系统。由这个定义我们知道zookeeper是个协调系统,作用的对象是分布式系统。为什么分布式系统需要一个协调系统了?理由如下:
开发分布式系统是件很困难的事情,其中的困难主要体现在分布式系统的“部分失败”。“部分失败”是指信息在网络的两个节点之间传送时候,如果网 络出了故障,发送者无法知道接收者是否收到了这个信息,而且这种故障的原因很复杂,接收者可能在出现网络错误之前已经收到了信息,也可能没有收到,又或接 收者的进程死掉了。发送者能够获得真实情况的唯一办法就是重新连接到接收者,询问接收者错误的原因,这就是分布式系统开发里的“部分失败”问题。
Zookeeper就是解决分布式系统“部分失败”的框架。Zookeeper不是让分布式系统避免“部分失败”问题,而是让分布式系统当碰到部分失败时候,可以正确的处理此类的问题,让分布式系统能正常的运行。
下面我要讲讲zookeeper的实际运用场景:
场景一:有一组服务器向客户端提供某种服务(例如:我前面做的分布式网站的服务端,就是由四台服务器组成的 集群,向前端集群提供服务),我们希望客户端每次请求服务端都可以找到服务端集群中某一台服务器,这样服务端就可以向客户端提供客户端所需的服务。对于这 种场景,我们的程序中一定有一份这组服务器的列表,每次客户端请求时候,都是从这份列表里读取这份服务器列表。那么这分列表显然不能存储在一台单节点的服 务器上,否则这个节点挂掉了,整个集群都会发生故障,我们希望这份列表时高可用的。高可用的解决方案是:这份列表是分布式存储的,它是由存储这份列表的服 务器共同管理的,如果存储列表里的某台服务器坏掉了,其他服务器马上可以替代坏掉的服务器,并且可以把坏掉的服务器从列表里删除掉,让故障服务器退出整个 集群的运行,而这一切的操作又不会由故障的服务器来操作,而是集群里正常的服务器来完成。这是一种主动的分布式数据结构,能够在外部情况发生变化时候主动 修改数据项状态的数据机构。Zookeeper框架提供了这种服务。这种服务名字就是:统一命名服务,它和javaEE里的JNDI服务很像。
场景二:分布式锁服务。当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据。在分布式系统里这 些操作可能会分散到集群里不同的节点上,那么这时候就存在数据操作过程中一致性的问题,如果不一致,我们将会得到一个错误的运算结果,在单一进程的程序 里,一致性的问题很好解决,但是到了分布式系统就比较困难,因为分布式系统里不同服务器的运算都是在独立的进程里,运算的中间结果和过程还要通过网络进行 传递,那么想做到数据操作一致性要困难的多。Zookeeper提供了一个锁服务解决了这样的问题,能让我们在做分布式数据运算时候,保证数据操作的一致 性。
场景三:配置管理。在分布式系统里,我们会把一个服务应用分别部署到n台服务器上,这些服务器的配置文件是 相同的(例如:我设计的分布式网站框架里,服务端就有4台服务器,4台服务器上的程序都是一样,配置文件都是一样),如果配置文件的配置选项发生变化,那 么我们就得一个个去改这些配置文件,如果我们需要改的服务器比较少,这些操作还不是太麻烦,如果我们分布式的服务器特别多,比如某些大型互联网公司的 hadoop集群有数千台服务器,那么更改配置选项就是一件麻烦而且危险的事情。这时候zookeeper就可以派上用场了,我们可以把 zookeeper当成一个高可用的配置存储器,把这样的事情交给zookeeper进行管理,我们将集群的配置文件拷贝到zookeeper的文件系统 的某个节点上,然后用zookeeper监控所有分布式系统里配置文件的状态,一旦发现有配置文件发生了变化,每台服务器都会收到zookeeper的通 知,让每台服务器同步zookeeper里的配置文件,zookeeper服务也会保证同步操作原子性,确保每个服务器的配置文件都能被正确的更新。
场景四:为分布式系统提供故障修复的功能。集群管理是很困难的,在分布式系统里加入了zookeeper服 务,能让我们很容易的对集群进行管理。集群管理最麻烦的事情就是节点故障管理,zookeeper可以让集群选出一个健康的节点作为 master,master节点会知道当前集群的每台服务器的运行状况,一旦某个节点发生故障,master会把这个情况通知给集群其他服务器,从而重新 分配不同节点的计算任务。Zookeeper不仅可以发现故障,也会对有故障的服务器进行甄别,看故障服务器是什么样的故障,如果该故障可以修 复,zookeeper可以自动修复或者告诉系统管理员错误的原因让管理员迅速定位问题,修复节点的故障。大家也许还会有个疑问,master故障了,那 怎么办了?zookeeper也考虑到了这点,zookeeper内部有一个“选举领导者的算法”,master可以动态选择,当master故障时 候,zookeeper能马上选出新的master对集群进行管理。
下面我要讲讲zookeeper的特点:
- zookeeper是一个精简的文件系统。这点它和hadoop有点像,但是zookeeper这个文件系统是管理小文件的,而hadoop是管理超大文件的。
- zookeeper提供了丰富的“构件”,这些构件可以实现很多协调数据结构和协议的操作。例如:分布式队列、分布式锁以及一组同级节点的“领导者选举”算法。
- zookeeper是高可用的,它本身的稳定性是相当之好,分布式集群完全可以依赖zookeeper集群的管理,利用zookeeper避免分布式系统的单点故障的问题。
- zookeeper采用了松耦合的交互模式。这点在zookeeper提供分布式锁上表现最为明显,zookeeper可以被用作一个约会机制, 让参入的进程不在了解其他进程的(或网络)的情况下能够彼此发现并进行交互,参入的各方甚至不必同时存在,只要在zookeeper留下一条消息,在该进 程结束后,另外一个进程还可以读取这条信息,从而解耦了各个节点之间的关系。
- zookeeper为集群提供了一个共享存储库,集群可以从这里集中读写共享的信息,避免了每个节点的共享操作编程,减轻了分布式系统的开发难度。
- zookeeper的设计采用的是观察者的设计模式,zookeeper主要是负责存储和管理大家关心的数据,然后接受观察者的注册,一旦这些数 据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
由此可见zookeeper很利于分布式系统开发,它能让分布式系统更加健壮和高效。
前不久我参加了部门的hadoop兴趣小组,测试环境的hadoop、mapreduce、hive及hbase都是我来安装的,安装 hbase时候安装要预先安装zookeeper,最早我是在四台服务器上都安装了zookeeper,但是同事说安装四台和安装三台是一回事,这是因为 zookeeper要求半数以上的机器可用,zookeeper才能提供服务,所以3台的半数以上就是2台了,4台的半数以上也是两台,因此装了三台服务 器完全可以达到4台服务器的效果,这个问题说明zookeeper进行安装的时候通常选择奇数台服务器。在学习hadoop的过程中,我感觉 zookeeper是最难理解的一个子项目,原因倒不是它技术负责,而是它的应用方向很让我困惑,所以我有关hadoop技术第一篇文章就从 zookeeper开始,也不讲具体技术实现,而从zookeeper的应用场景讲起,理解了zookeeper应用的领域,我想再学习 zookeeper就会更加事半功倍。
之所以今天要谈谈zookeeper,也是为我上一篇文章分布式网站框架的补充。虽然我设计网站架构是分布式结构,也做了简单的故障处理机制, 比如:心跳机制,但是对集群的单点故障还是没有办法的,如果某一台服务器坏掉了,客户端任然会尝试连接这个服务器,导致部分请求的阻塞,也会导致服务器资 源的浪费。不过我目前也不想去修改自己的框架,因为我总觉得在现有的服务上添加zookeeper服务会影响网站的效率,如果有独立的服务器集群部署 zookeeper还是值得考虑的,但是服务器资源太宝贵了,这个可能性不大。幸好我们部门也发现了这样的问题,我们部门将开发一个强大的远程调用框架, 将集群管理和通讯管理这块剥离出来,集中式提供高效可用的服务,等部门的远程框架开发完毕,我们的网站加入新的服务,我想我们的网站将会更加稳定和高效。
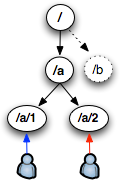
ZooKeeper 如何工作?
ZooKeeper是作为分布式应用建立更高层次的同步(synchronization)、配置管理 (configuration maintenance)、群组(groups)以及名称服务(naming)。在编程上,ZooKeeper设计很简单,所使用的数据模型风格很像文件 系统的目录树结构,简单来说,有点类似windows中注册表的结构,有名称,有树节点,有Key(键)/Value(值)对的关系,可以看做一个树形结 构的数据库,分布在不同的机器上做名称管理。
Zookeeper分为2个部分:服务器端和客户端,客户端只连接到整个ZooKeeper服务的某个服务器上。客户端使用并维护一个TCP连接,通过这 个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个TCP连接中断,客户端将尝试连接到另外的ZooKeeper服务器。客户端第一次连接 到ZooKeeper服务时,接受这个连接的 ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
启动Zookeeper服务器集群环境后,多个Zookeeper服务器在工作前会选举出一个Leader,在接下来的工作中这个被选举出来的 Leader死了,而剩下的Zookeeper服务器会知道这个Leader死掉了,在活着的Zookeeper集群中会继续选出一个Leader,选举 出leader的目的是为了可以在分布式的环境中保证数据的一致性。如图所示:

另外,ZooKeeper
支持watch(观察)的概念。客户端可以在每个znode结点上设置一个观察。如果被观察服务端的znode结点有变更,那么watch就会被触发,这
个watch所属的客户端将接收到一个通知包被告知结点已经发生变化。若客户端和所连接的ZooKeeper服务器断开连接时,其他客户端也会收到一个通
知,也就说一个Zookeeper服务器端可以对于多个客户端,当然也可以多个Zookeeper服务器端可以对于多个客户端,如图所示:

你还可以通过命令查看出,当前那个Zookeeper服务端的节点是Leader,哪个是Follower,如图所示:

我通过试验观察到 Zookeeper的集群环境最好有3台以上的节点,如果只有2台,那么2台当中不管那台机器down掉,将只会剩下一个leader,那么如果有再有客户端连接上来,将无法工作,并且剩下的leader服务器会不断的抛出异常。并且客户端连接时还会抛出这样的异常,说明连接被拒绝,并且等待一个socket连接新的连接,这里socket新的连接指的是zookeeper中的一个Follower。
记得大约在2006年的时候Google出了Chubby来解决分布一致性的问题(distributed consensus
problem),所有集群中的服务器通过Chubby最终选出一个Master Server ,最后这个Master
Server来协调工作。简单来说其原理就是:在一个分布式系统中,有一组服务器在运行同样的程序,它们需要确定一个Value,以那个服务器提供的信息
为主/为准,当这个服务器经过n/2+1的方式被选出来后,所有的机器上的Process都会被通知到这个服务器就是主服务器
Master服务器,大家以他提供的信息为准。很想知道Google
Chubby中的奥妙,可惜人家Google不开源,自家用。
但是在2009年3年以后沉默已久的Yahoo在Apache上推出了类似的产品ZooKeeper,并且在Google原有Chubby的设计思想上做
了一些改进,因为ZooKeeper并不是完全遵循Paxos协议,而是基于自身设计并优化的一个2 phase commit的协议,如图所示:

ZooKeeper跟Chubby一样用来存放一些相互协作的信息(Coordination),这些信息比较小一般不会超过1M,在zookeeper
中是以一种hierarchical tree的形式来存放,这些具体的Key/Value信息就store在tree node中,如图所示:
当有事件导致node数据,例如:变更,增加,删除时,Zookeeper就会调用
triggerWatch方法,判断当前的path来是否有对应的监听者(watcher),如果有watcher,会触发其process方法,执行
process方法中的业务逻辑,如图所示:

应用实例
ZooKeeper有了上述的这些用途,让我们设想一下,在一个分布式系统中有这这样的一个应用:
2个任务工厂(Task
Factory)一主一从,如果从的发现主的死了以后,从的就开始工作,他的工作就是向下面很多台代理(Agent)发送指令,让每台代理(Agent)
获得不同的账户进行分布式并行计算,而每台代理(Agent)中将分配很多帐号,如果其中一台代理(Agent)死掉了,那么这台死掉的代理上的账户就不
会继续工作了。
上述,出现了3个最主要的问题:
1.Task Factory 主/从一致性的问题
2.Task Factory 主/从心跳如何用简单+稳定 或者2者折中的方式实现。
3.一台代理(Agent)死掉了以后,一部分的账户就无法继续工作,需要通知所有在线的代理(Agent)重新分配一次帐号。
怕文字阐述的不够清楚,画了系统中的Task Factory和Agent的大概系统关系,如图所示:

OK,让我们想想ZooKeeper是不是能帮助我们去解决目前遇到的这3个最主要的问题呢?
解决思路
1. 任务工厂Task Factory都连接到ZooKeeper上,创建节点,设置对这个节点进行监控,监控方法例如:
event= new WatchedEvent(EventType.NodeDeleted, KeeperState.SyncConnected, "/TaskFactory");
这个方法的意思就是只要Task Factory与zookeeper断开连接后,这个节点就会被自动删除。
2.原来主的任务工厂断开了TCP连接,这个被创建的/TaskFactory节点就不存在了,而且另外一个连接在上面的Task Factory可以立刻收到这个事件(Event),知道这个节点不存在了,也就是说主TaskFactory死了。
3.接下来另外一个活着的TaskFactory会再次创建/TaskFactory节点,并且写入自己的ip到znode里面,作为新的标记。
4.此时Agents也会知道主的TaskFactory不工作了,为了防止系统中大量的抛出异常,他们将会先把自己手上的事情做完,然后挂起,等待收到
Zookeeper上重新创建一个/TaskFactory节点,收到 EventType.NodeCreated 类型的事件将会继续工作。
5.原来从的TaskFactory 将自己变成一个主TaskFactory,当系统管理员启动原来死掉的主的TaskFactory,世界又恢复平静了。
6.如果一台代理死掉,其他代理他们将会先把自己手上的事情做完,然后挂起,向TaskFactory发送请求,TaskFactory会重新分配(sharding)帐户到每个Agent上了,继续工作。
上述内容,大致如图所示:

本文来源于夏天的森林
zookeeper入门知识的更多相关文章
- zookeeper 入门知识
作为开启分布式架构的基石,除了必会还有的选么 自己的一些理解,有错误的话请一定要给予指正! 一.是什么? 分布式数据一致性的解决方案. 二.有什么用 数据的发布/订阅(配置中心) . 负载均衡(du ...
- [置顶] Mysql存储过程入门知识
Mysql存储过程入门知识 #1,查看数据库所有的存储过程名 #--这个语句被用来移除一个存储程序.不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程 #SELECT NAME FROM ...
- 移动H5开发入门知识,CSS的单位汇总与用法
说到css的单位,大家应该首先想到的是px,也就是像素,我们在网页布局中一般都是用px,但是近年来自适应网页布局越来越多,em和百分比也经常用到了.然后随着手机的流行,web app和hybrid a ...
- H5移动端开发入门知识以及CSS的单位汇总与用法
说到css的单位,大家应该首先想到的是px,也就是像素,我们在网页布局中一般都是用px,但是近年来自适应网页布局越来越多,em和百分比也经常用到了.然后随着手机的流行,web app和hybrid a ...
- Java web 入门知识 及HTTP协议详解
Java web 入门知识 及HTTP协议详解 WEB入门 WEB,在英语中web即表示网页的意思,它用于表示Internet主机上供外界访问的资源. Internet上供外界访问的Web资 ...
- Java基础入门知识
Java编程入门知识 知识概要: (1)Java入门基本常识 (2)Java的特性跨平台性 (3)Java的编程环境的搭建 (4)Java的运行机制 (5)第一个Java小程序入门 (1)Java ...
- zabbix入门知识
zabbix入门知识 zabbix中文手册 https://www.zabbix.com/documentation/3.4/manual/ 1.zabbix介绍 Zabbix 是一个企业级的分布式开 ...
- 分布式进阶(十六)Zookeeper入门基础
Zookeeper入门基础 前言 在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据.如果在创建znode时Flag设置为EPHEMERAL,那么当 ...
- React的入门知识与概念【1】
回顾在以往的项目开发中,从最初的使用的原生html+js+css+jquery开发,到后来随着项目功能的增加,也渐渐学习了Vue.js框架的开发,以及Vue.js的全家桶Axios,Vue-route ...
随机推荐
- 非root用户搭建hadoop伪分布式
0.安装软件列表 jdk-7u25-linux-x64.tar.gz hadoop-2.5.0.tar.gz hadoop-native-64-2.5.0.tar 1.准备Linux环境(root ...
- 编写简单的爬虫从流行的Scrapy 框架讲起
到目前为止,我们已经完成了向站点添加搜索和过滤的功能,并且我们已经可以向站点添加一些分类和产品信息.下面我们将考虑当尝试删除实体信息时会发生什么事情. 首先,向站点添加一个名为Test的新分类,然后再 ...
- UI_APPEARANCE_SELECTOR 延伸
iOS后属性带UI_APPEARANCE_SELECTOR 可以统一设置全局作用 例如: 1>开关控件 @property(nullable, nonatomic, strong) UIColo ...
- Scala学习---数组
1.编写一段代码,将a设置为一个n个随机整数的数组,要求随机数介于0(包含)和n(不包含)之间 /** * Created by vito on 2017/1/11. */ object ex1 { ...
- 单词缩写(abbr.cpp)每日一题
题目描述:YXY 发现好多计算机中的单词都是缩写,如 GDB,它是全称 Gnu DeBug 的缩写.但是,有时缩写对应的全称并不固定,如缩写 LINUX,可以理解为:(1)LINus's UniX ( ...
- 在UE4中使用SVN作为source control工具
==========预先处理 1.到这个目录下 2.鼠标在空白处 按住shift键 同时右键 会多出一个 可以打开的cmd 3.输入命令,修改红线部分. me: 登陆svn地址的用户名, URL网址: ...
- openstack私有云布署实践【13.2 网络Neutron-compute节点配置(办公网环境)】
所有compute节点 下载安装组件 # yum install openstack-neutron openstack-neutron-linuxbridge ebtables ipset -y ...
- 不容忽略的——CSS规范
一.CSS分类方法: 公共型样式 特殊型样式 皮肤型样式 并以此顺序引用 <link href="assets/css/global.css" rel="style ...
- phantomjs处理alert、confirm弹窗
一:phantomjs处理alert弹窗 脚本实现功能为:点击click me按钮弹出弹窗消息为cheese,点击确定按钮,弹窗关闭 脚本代码为:注意的是phantomjs处理alert弹窗需要将ph ...
- ZooKeeper搭建
ZooKeeper系列之一:ZooKeeper简介 ZooKeeper 是一个为分布式应用所设计的分布的.开源的协调服务.分布式的应用可以建立在同步.配置管理.分组和命名等服务的更高级别的实现的基础之 ...