COIG:开源四类中文指令语料库
CHINESE OPEN INSTRUCTION GENERALIST: A PRELIMINARY RELEASE
论文:https://arxiv.org/pdf/2304.07987v1.pdf
数据地址:https://huggingface.co/datasets/BAAI/COIG
Part1介绍
COIG的特点:
领域适应性:如表1所示。我们考虑了指令微调数据集的四个方面(验证,格式,文化,缩放)。对于每个领域,我们调整我们的数据收集管道,以更好地反映该领域的特点。

验证:反应是否可以被验证。
格式:格式是否至关重要。
文化:反应是否取决于某种文化。
尺度:尺度是否重要。
多样性:我们考虑了各种任务,包括常识推理、人类价值排列、代码生成和幻觉纠正,而很少有中
文指令微调数据是特意为这样一个完整的光谱而设计的。由人类进行质量检查:与现有的模型生成的中文教学语料库相比,包括(Ziang Leng and Li, 2023; LianjiaTech, 2021; Xue et al., 2023; JosephusCheung, 2021),COIG的翻译语料库由人类注释者仔细验证。此外,由于COIG翻译语料库是从具有不同任务的英语教学语料库(Wang等人,2022b; Honovich等人,2022;Wang等人,2022a)翻译而来,它比在现有的中文数据集上通过适应提示工程建立的中文教学语料库更加多样化,例如(Zeng等人,2023;杨,2023;郭等人,2023)。
COIG数据的主要部分是已经存在于网络上的实际数据,我们根据它们的特点将其转换为合适的指令遵循方式。例如,在学术考试领域,我们抓取了中国高考、公务员考试等63.5千条指令并进行了人工注释。COIG的特点还包括华语世界中人类价值取向的数据,以及基于leetcode的编程指令的样本。为了保证最终的数据质量,我们聘请了223名中国大学生作为质量检查员,帮助我们进行数据过滤、修正和评级。由此产生的COIG语料库是一个全面的集合,可以使中国的法律硕士在许多领域具有很强的指令跟随能力。COIG语料库可以在huggingface和github找到并将持续更新。
此外,我们根据经验观察提供了对数据构建管道的见解。我们证明了为不同的领域选择合适的管道是至关重
要的,并且我们提出了在COIG所涵盖的领域中构建指令调整数据的最佳实践(第3节),这可以作为未来指
令语料库构建工作流程设计的参考。
该文的贡献如下:
据我们所知,这是最早的研究工作之一,专门总结了现有的中文指令微调语料库,并就未来如何构建中文指令微调语料库提出了见解。 我们构建了5个开源的高质量中文指令语料库,包括68k的普通中文指令语料库、62k的中文考试指令语料库、3k的中文人值对齐语料库和13k的中文反事实校正多轮聊天语料库,作为沿着指出的研究方向构建新的中文教学语料库的样本。 我们构建了一个人工验证的通用高质量中文指令调优语料库,可直接用于中文LLMs的指令调优,包括商业和非商业的。
Part2现有的指令语料库
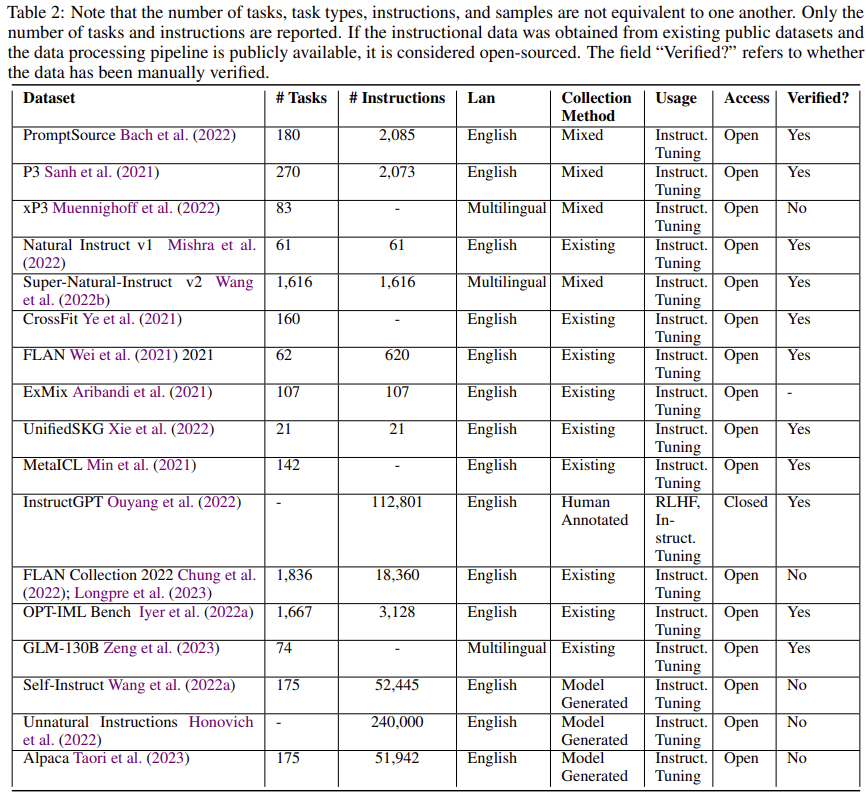
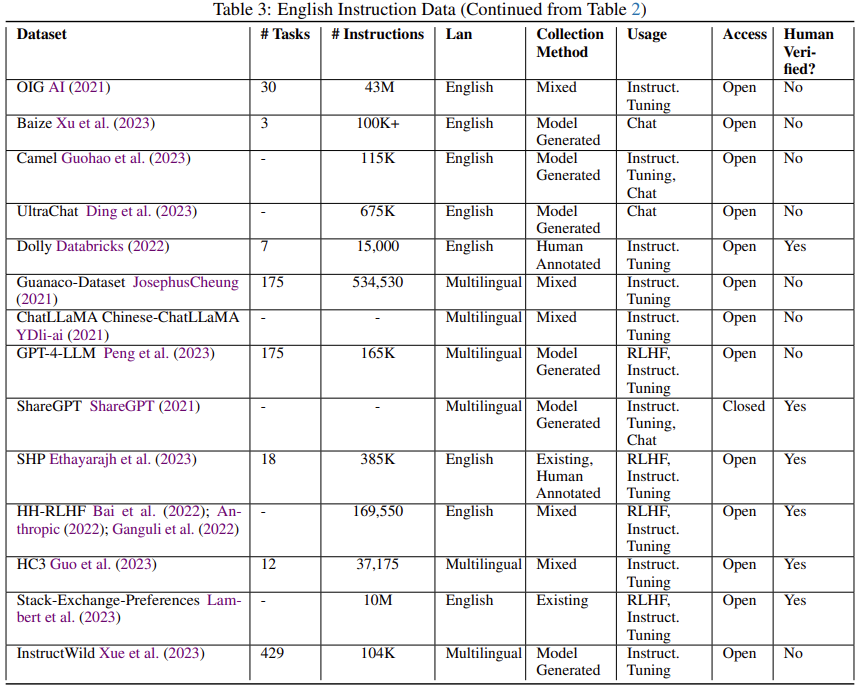
如果指令数据是从现有的公共数据集中获得的,并且数据处理管道是公开的,那么它就被认为是开源的。
获取数据集的一般手段有:人工标注、半自动和自动构建、使用LLM、翻译。
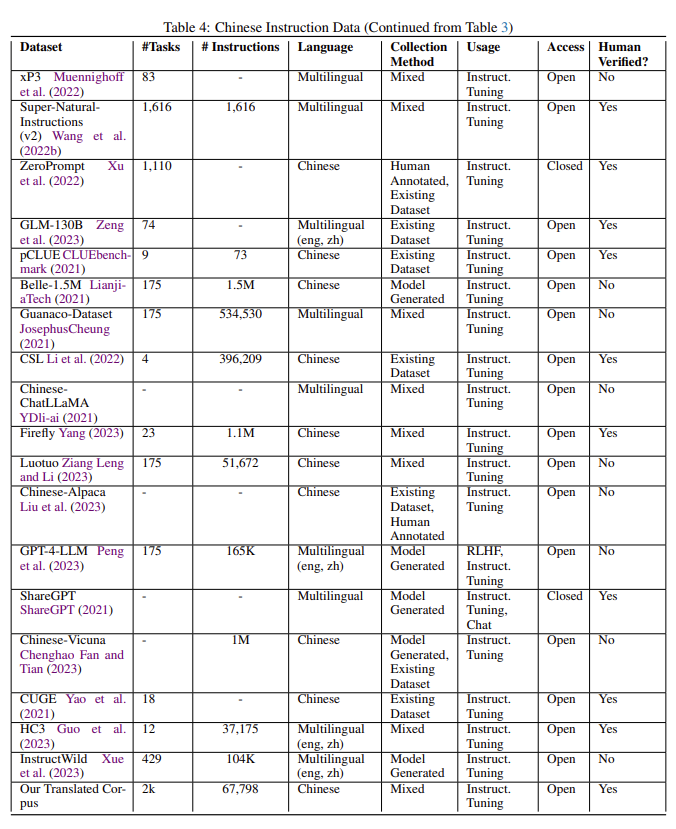
Part3COIG:中文开源指令数据通用语料库
第3.1节中分别介绍了一个经过人工验证的普通指令语料库,在第3.2节中介绍了一个经过人工注释的考试指令语料库,在第3.3节中介绍了一个人类价值调整指令语料库,在第3.3节中介绍了一个多轮反事实修正聊天语料库,在第3.5节中介绍了一个leetcode指令语料库。我们提供这些新的指令语料库是为了帮助社区对中文LLMs进行指令调整。这些指令语料库也是如何有效建立和扩展新的中文指令语料库的模板工作流程。
1基于翻译的通用指令语料库
为了减少成本并进一步提高指令语料库的质量,我们将翻译程序分为三个阶段:自动翻译、人工验证和人
工纠正。
自动翻译:将指令输入和输出进行拼接输入到DeepL进行翻译。
人工验证:定义四个标签:1)可直接使用;2)可以使用,但要有实例的源输入和输出;3)需要人工修正后使用;4)不可使用。不可用的情况非常少,不到20个。我们在人工验证阶段采用了两阶段的质量验证:在第一阶段,每个案例在经过注释者的注释后,由一位具有5年以上工作经验的工业界有经验的质量检查员进行核查。当且仅当正确率超过95%时,整个语料库才能进入第二个质量验证阶段。最终,该语料库在第一个质量验证阶段得到了96.63%的正确率。我们的专家质量检查员(即我们的合作者)负责第二个质量验证阶段,只从总语料库中随机抽取200个案例进行质量验证。如果并且只有在所有抽样的案例都被正确分类的情况下,语料库才能够进入人工修正阶段。
人工纠正:在人工修正阶段,要求注释者将翻译的指令和实例修正为正确的中文{指令、输入、输出}三要素,而不是仅仅保持翻译的正确性。要求注释者这样做是因为在源的非自然指令中存在事实错误,可能导致LLMs的幻觉。总共有18074条指令被送入人工纠正阶段。我们使用与人工验证阶段相同的两阶段质量验证程序。在人工修正阶段的第一个质量验证阶段,语料库得到了97.24%的正确率。这些严格的质量验证程序保证了翻译语料库的可靠性。
2考试指令语料库
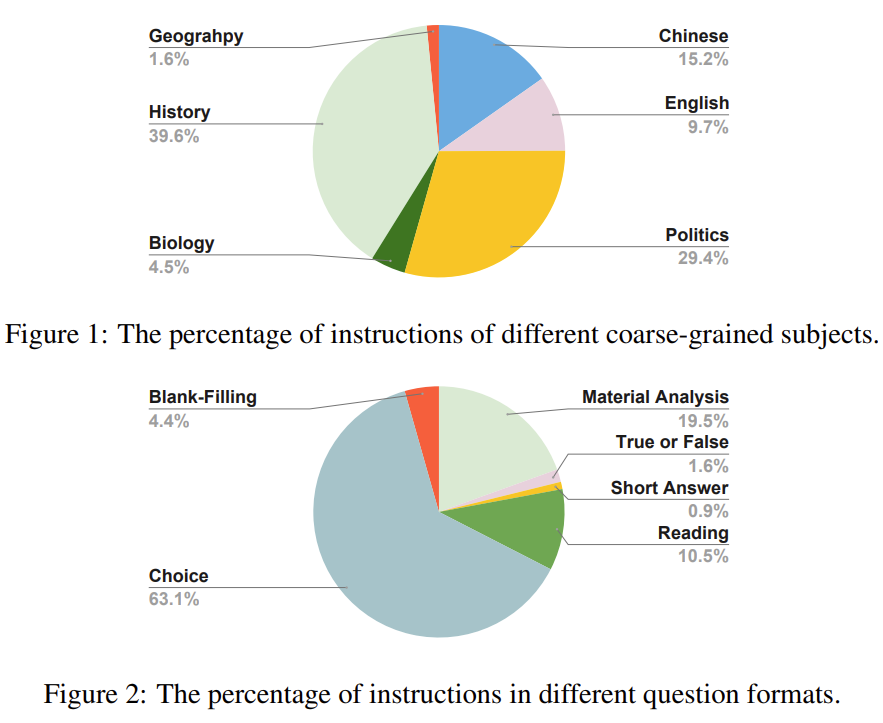
我们使用potato(Pei et al., 2022),一个主动学习驱动的开源注解网站模板,进行人工注解,从原始考试题中提取六个信息元素,包括指令、问题背景、问题、答案、答案分析和粗粒度的主题。这些考试中有很多阅读理解题,问题背景指的是这些阅读理解题的阅读材料。有六个主要的粗略科目:中文、英文、政治、生物、历史和地质。语料库中很少有数学、物理和化学问题,因为这些问题往往带有复杂的符号,很难进行注释。我们说明了问题格式百分比,说明了主要科目百分比。对于许多选择题,我们建议研究人员利用这个语料库,使用提示语对其进行进一步的后处理,或将其后处理为填空题,以进一步增加指令的多样性。
3人类价值对齐指令语料库
我们将价值排列数据分为两个独立的集合:1)一组呈现华语世界共同的人类价值的样本;2)一些呈现区域文化或国家特定的人类价值的额外样本集合。对于第一套共享的样本,我们选择了self-instruct( Wang et al., 2022a) 作为主要的方法来增加一套种子指令遵循的样本。对于附加集,为了保证数据真实地反 映当地的价值观,我们主要依靠网络爬虫来收集原始形式的数据。
人类共同价值观的种子指令是人工从中国道德教育的教科书和考试中挑选出来的,因为我们相信这些材料中的大部分内容已经考虑了不同群体的共同点(例如,中国有56个少数民族)。在过滤数据时,我们特意考虑了以下三个原则:
它应该介绍在华语世界被广泛接受的人类共同价值观,而不是区域性的。 它不应该包括政治宣传或宗教信仰,也不应该与有争议的索赔有关。 它不应该只是解释谚语或名言,因为它们很可能会在知识检索说明-后续数据中涉及。
我们总共选择了50条指令作为扩增种子,并产生了3k条产生的指令,跟随样本用于华语世界的通用价值对齐。同时,我们还收集了19,470个样本作为区域性的增补,这些样本是针对中国用户的(包括许多只在中文社区使用的术语)。

4多轮反事实修正聊天语料库
我们构建了反事实修正多轮聊天数据集(CCMC)。它是基于CN-DBpedia知识库(Xu等人,2017) 构建的,目的是缓解和解决当前LLM中的幻觉和事实不一致的痛点。原始知识库由5634k个实体及其对应的属性-价值对和原始文本组成。
CCMC数据集包括一个学生和一个老师之间的5轮角色扮演聊天,以及他们参考的相应知识。老师根据基础知识产生回答,并在每一轮中纠正学生的问题或陈述中的事实错误或不一致之处。在最后一轮中,老师会总结聊天内容,并审查混乱的术语,即学生的问题或陈述中的事实错误或不一致之处。该数据集包含13,653个对话,导致68,265轮的聊天。
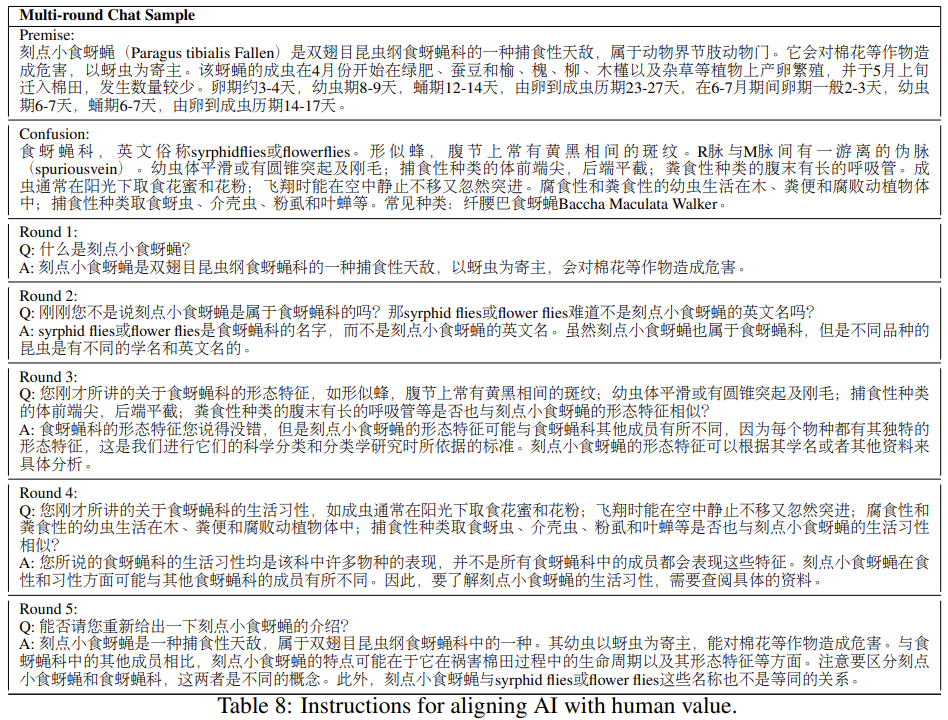
我们概述了创建CCMC数据集的工作流程。该工作流程包括三个主要部分:实体选择、信息提取和聊天生成。
实体选择:根据实体标签频率对实体进行排名,并选择前200名。我们优先考虑有摘要的实体
,并旨在保留基于事实/知识的内容,如成熟的、经过历史检验的概念,以及与各种学术学科、历史事件和
社会事件相关的实体。像组织、公司、食品和游戏这样的标签被排除在外。
信息提取:使用一个聊天的LLM从知识库中提取信息。我们首先通过从高优先级的类别中随机抽出一个实体来获得源实体,返回三联体、内容摘要和内容部分的标题。然后我们要求聊天LLM将所有的信息总结成一个更好的摘要,同时从输入中提取属性-价值对。这可以过滤掉百度标签中的一些虚假标签,也可以把非结构化内容中的信息考虑进去。对于混淆实体,我们使用基于提示的方法来提取基于输入信息的混淆术语列表。然后我们将这些术语与知识库进行匹配。如果该术语存在于知识库中,我们就保留该术语,并使用同样的方法来提取更好的摘要和属性值对。
生成聊天记录:采用师生问答的方式来生成聊天记录,逐步生成攻击和防御场景。我们提供提取的原始实体摘要和混淆的实体摘要。然后,我们让学生向老师询问原始概念,同时将其与混乱的概念错误地混为一谈。然后,老师会以JSON格式来澄清和区分这些概念。对话将持续多轮,每次都是学生根据之前的对话来挑战老师,而老师则提供澄清和区别。在最后一轮,老师会重新介绍原来的概念,并总结容易混淆的概念,强调和区分学生之前混淆的概念。所有的聊天都是通过提示聊天LLM产生的。
5leetcode语料库
鉴于代码相关的任务可能有助于LLMs的能力出现(Ouyang等人,2022),我们认为在我们的数据集中应该考虑与中文自然语言一致的代码相关任务。因此,我们从CC-BY-SA-4.0许可的集合中建立了Leetcode指令的2,589个编程问题。这些问题包含问题描述、多种编程语言和解释.
考虑到输入和输出,我们将指令任务分为两类:代码到文本和文本到代码。代码到文本的任务要求产生给定的编程代码的功能描述,而文本到代码的任务则要求从问题中输出代码。根据程序问题是否有相应的解释,任务指令将被区分为有/无解释。我们准备了38种类型的说明来生成Leetcode指令。我们对每个程序问题的可用编程语言实现进行迭代,随机抽取任务为代码到文本或文本到代码,然后随机选择一个相应的指令描述。

6指令语料库构建工作流程的实证验证
本节总结了关于中文指令语料库建设工作流程的合理实证结论和经验。
首先,当我们想扩大指令语料库的规模时,采用语境学习(ICL)来生成新的指令(Wang等人,2022a; Honovich等人,2022)是一个关键的促进因素。以表1中的通用指令语料库(LianjiaTech, 2021; Taori et al.1 为例,利用现有LLM的ICL能力而不是依靠人工注释或其他方法来生成这些指令是比较现实的。LLM的开发者应该根据源头的许可、源头与OpenAI的关系以及他们的需求,仔细决定他们喜欢哪种LLM和种子指令体的关系,以及他们的需求。
其次,当目标语言和源指令语料库的语言之间存在文化差异时,需要进行人工注释或验证。正如第3.3节所述,我们必须仔细选择人工指令中的种子,以确保种子指令与中国文化保持良好的一致性,不包括政治宣传或区域信仰。我们还建议使用现有的语料库,比如在构建人类价值对齐指令时,使用(Ethayarajh等人,2023)中介绍的方法,即从论坛中抓取语料,并对其进行后处理,使其无害化。
第三,模型生成的语料需要更详细的人工质量验证,特别是在输出格式至关重要的情况下。在第3.1节中解释的非自然指令(Honovich等人,2022)的翻译和验证过程中,我们注意到许多不遵循模型生成的指令的实例,以及相当数量的不完善的模型生成的指令。另一个问题是,模型生成的指令的多样性和分布高度依赖于种子指令。人工选择和验证可能有助于从大型原始指令语料库中抽取指令语料,其分布比大型原始指令语料库本身更均衡,多样性更好,正如(Geng等人,2023)所指出的。
COIG:开源四类中文指令语料库的更多相关文章
- 《介绍一款开源的类Excel电子表格软件》续:七牛云存储实战(C#)
两个月前的发布的博客<介绍一款开源的类Excel电子表格软件>引起了热议:在博客园有近2000个View.超过20个评论. 同时有热心读者电话咨询如何能够在SpreadDesing中实现存 ...
- Day1---Java 基本数据类型 - 四类八种 --九五小庞
一.Java四大数据类型分类 1.整型 byte .short .int .long 2.浮点型 float . double 3.字符型 char 4.布尔型 boolean 二.八种基本数据类型 ...
- test [ ] 四类
test可理解的表达式类型分为四类: 表达式判断 字符串比较 数字比较 文件比较 test xxx 可以简写成 [ xxx ] 的形式,注意两端的空格. 1)判 ...
- ASP.NET中常用的几个李天平开源公共类LTP.Common,Maticsoft.DBUtility,LtpPageControl
ASP.NET中常用的几个开源公共类: LTP.Common.dll: 通用函数类库 源码下载Maticsoft.DBUtility.dll 数据访问类库组件 源码下载LtpPageC ...
- Delphi函数参数传递 默认参数(传值)、var(穿址)、out(输出)、const(常数)四类
Delphi的参数可以分为:默认参数(传值).var(传址).out(输出).const(常数)四类 可以对比C/C++的相关知识,类比学习. 1.默认参数是传值,不会被改变,例子 function ...
- ASP.NET中常用的几个李天平开源公共类LTP.Common,Maticsoft.DBUtility,LtpPageControl (转)
ASP.NET中常用的几个开源公共类: LTP.Common.dll: 通用函数类库 源码下载Maticsoft.DBUtility.dll 数据访问类库组件 源码下载LtpPageC ...
- 一张图让你看懂锻压、CNC、压铸、冲压四类工艺!
(锻压+CNC+阳极.CNC+阳极.压铸+阳极.冲压+阳极手机外壳比较) 上图为一张雷达图,该图比较直观形象地描述了4大手机外壳工艺在6个维度(加工成本.CNC用量.加工周期.成品率.可设计性.外观质 ...
- IBM总裁郭士纳总结的四类人
IBM总裁郭士纳总结的四类人, 您属于哪一种呢-欢迎就此话题发表评论 积极采取行动促使事件发生的人 被动接受所发生事件的人 对事件持旁观者心态的人 什么事都不关心的人
- NLP+语义分析(四)︱中文语义分析研究现状(CIPS2016、角色标注、篇章分析)
摘录自:CIPS2016 中文信息处理报告<第二章 语义分析研究进展. 现状及趋势>P14 CIPS2016> 中文信息处理报告下载链接:http://cips-upload.bj. ...
- JAVA四类八种基本数据类型
boolean类型 Boolean在内存中占用一个字节. 当java编译器把java源代码编译为字节码时,会用int或byte来表示boolean.在java虚拟机中,用整数零来表示false,用任意 ...
随机推荐
- CentOS7安装 Redis5 单实例
1.下载redis下载地址在:redis.io比如把Redis安装到/usr/local/soft/ cd /usr/local/soft/ wget http://download.redis.io ...
- 关于 ubuntu 22 desktop 安装 网易云音乐无法启动解决办法
- 报错现象 /opt/netease/netease-cloud-music/netease-cloud-music: /opt/netease/netease-cloud-music/libs/l ...
- 使用 Transformers 在你自己的数据集上训练文本分类模型
最近实在是有点忙,没啥时间写博客了.趁着周末水一文,把最近用 huggingface transformers 训练文本分类模型时遇到的一个小问题说下. 背景 之前只闻 transformers 超厉 ...
- Java中的方法增强
A:在不影响业务情况下,增强一个方法有几种方法呢? B:3种! A:哪三种呀? 一.继承类来重写方法: 1.要可以获取这个类的构造: class Man{ public void run(){ Sys ...
- python pip安装三方库失败
Collecting pip WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None ...
- pandas加速读取数据记录csv大文件处理
def readf(file): t0 = time.time() data=pd.read_csv(file,low_memory=False,encoding='gbk' #,nrows=100 ...
- OSPF故障诊断
- Solon2 分布式事件总线的技术价值?
分布式事件总线在分布式开发(或微服务开发)时,是极为重要的架构手段.它可以分解响应时长,可以削峰,可以做最终一致性的分布式事务,可以做业务水平扩展. 1.分解响应时长 比如我们的一个接口处理分为四段代 ...
- Nacos的微服务与本地测试的问题
前提条件: 这里是微服务上的yml的配置: uri: base-svc-authcenter: 192.168.1.121:28002 base-svc-file: 192.168.1.121:280 ...
- 灵感宝盒新增「线上云展会」产品,「直播观赏联动」等你共建丨RTE NG-Lab 双周报
前言 哈喽各位开发者,「RTE NG-Lab 双周报」如期而至! 近两周,我们更新了一些新的实时互动场景和产品,也举办了代码实验室的第一次线下活动,与大家一起体验了声网最新的 4.0 SDK. 灵感宝 ...