Kafka的优秀设计学习
一.Kafka基础
消息系统的作用
应该大部份小伙伴都清楚,用机油装箱举个例子
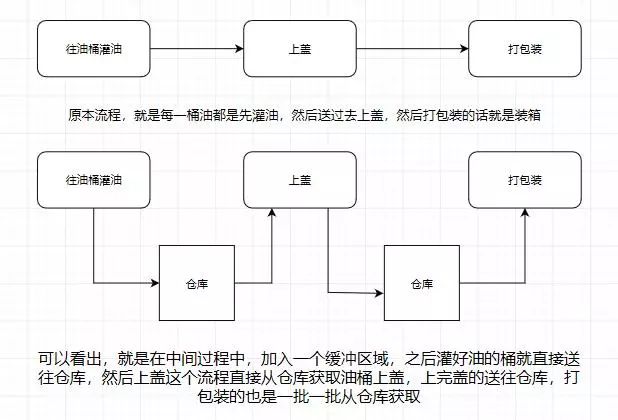
所以消息系统就是如上图我们所说的仓库,能在中间过程作为缓存,并且实现解耦合的作用。
引入一个场景,我们知道中国移动,中国联通,中国电信的日志处理,是交给外包去做大数据分析的,假设现在它们的日志都交给了你做的系统去做用户画像分析。
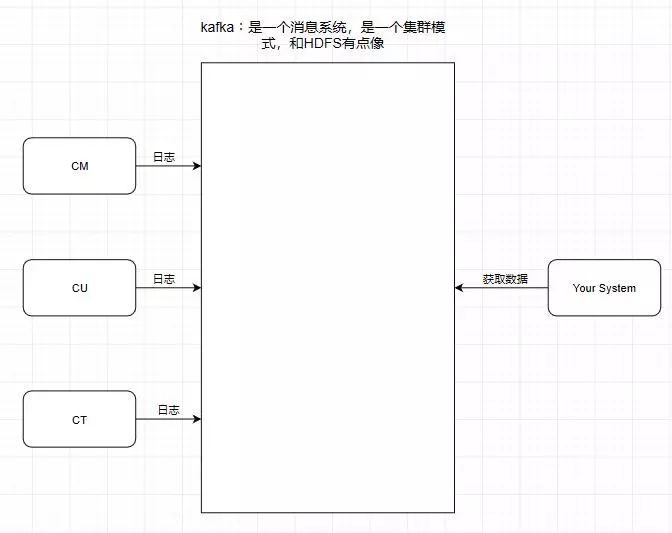
按照刚刚前面提到的消息系统的作用,我们知道了消息系统其实就是一个模拟缓存 ,且仅仅是起到了缓存的作用 而并不是真正的缓存,数据仍然是存储在磁盘上面而不是内存。
1.Topic 主题
kafka学习了数据库里面的设计,在里面设计了topic(主题),这个东西类似于关系型数据库的表
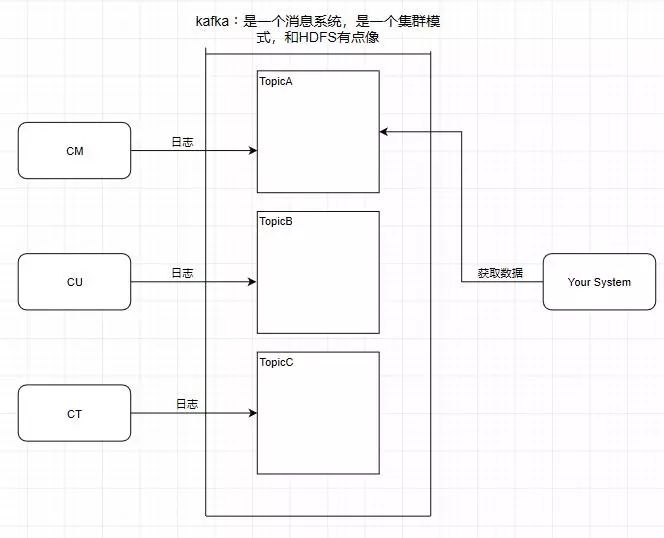
此时我需要获取中国移动的数据,那就直接监听TopicA即可
2.Partition 分区
kafka还有一个概念叫Partition(分区),分区具体在服务器上面表现起初就是一个目录,一个主题下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主机上建了不同的目录。
这些分区主要的信息就存在了.log文件里面。跟数据库里面的分区差不多,是为了提高性能。
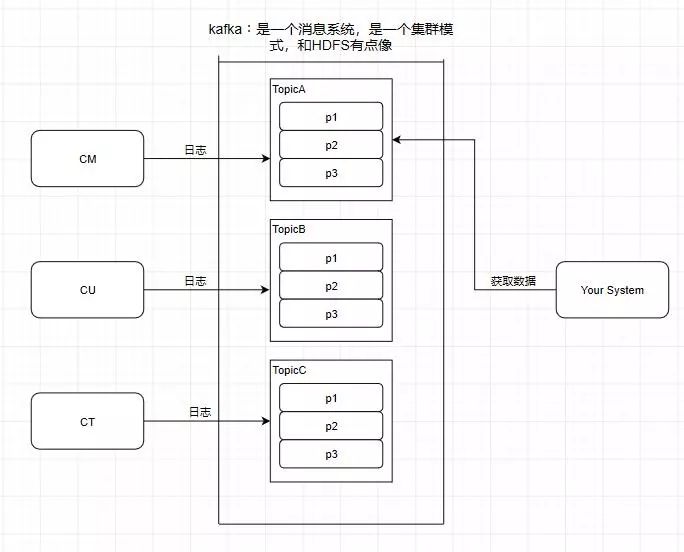
至于为什么提高了性能,很简单,多个分区多个线程,多个线程并行处理肯定会比单线程好得多
Topic和partition像是HBASE里的table和region的概念,table只是一个逻辑上的概念,真正存储数据的是region,这些region会分布式地存储在各个服务器上面,对应于kafka,也是一样,Topic也是逻辑概念 ,而partition就是分布式存储单元。这个设计是保证了海量数据处理的基础。
我们可以对比一下,如果HDFS没有block的设计,一个100T的文件也只能单独放在一个服务器上面,那就直接占满整个服务器了,引入block后,大文件可以分散存储在不同的服务器上。
注意:1.分区会有单点故障问题,所以我们会为每个分区设置副本数
2.分区的编号是从0开始的
3.Producer - 生产者
往消息系统里面发送数据的就是生产者
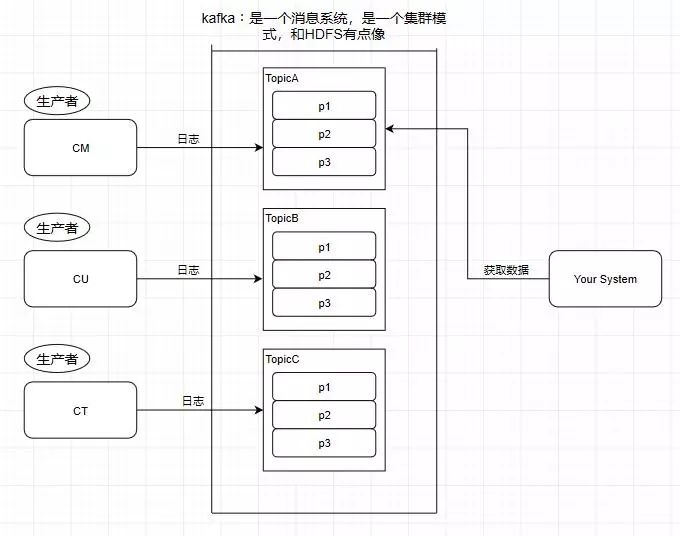
4.Consumer - 消费者
从kafka里读取数据的就是消费者
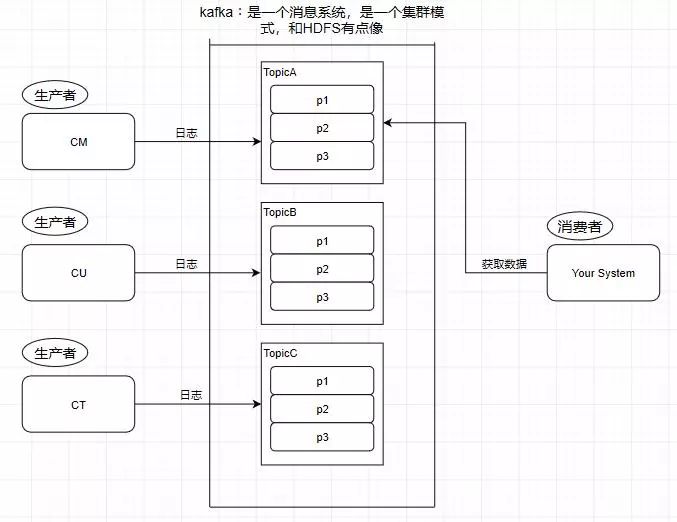
5.Message - 消息
kafka里面的我们处理的数据叫做消息
二.Kafka的集群架构
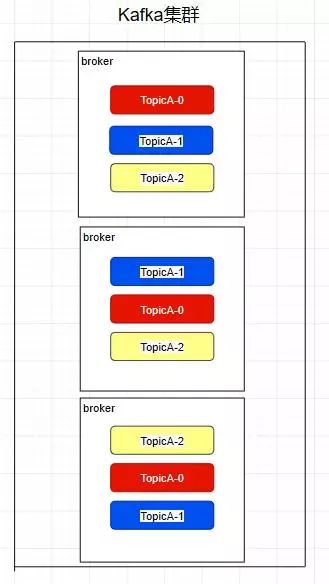
创建一个TopicA的主题,3个分区分别存储在不同的服务器,也就是broker下面。Topic是一个逻辑上的概念 ,并不能直接在图中把Topic的相关单元画出

需要注意:kafka在0.8版本以前是没有副本机制的,所以在面对服务器宕机的突发情况时会丢失数据,所以尽量避免使用这个版本之前的kafka
Replica - 副本
kafka中的partition为了保证数据安全,所以每个partition可以设置多个副本。
此时我们对分区0,1,2分别设置3个副本(其实设置两个副本是比较合适的)
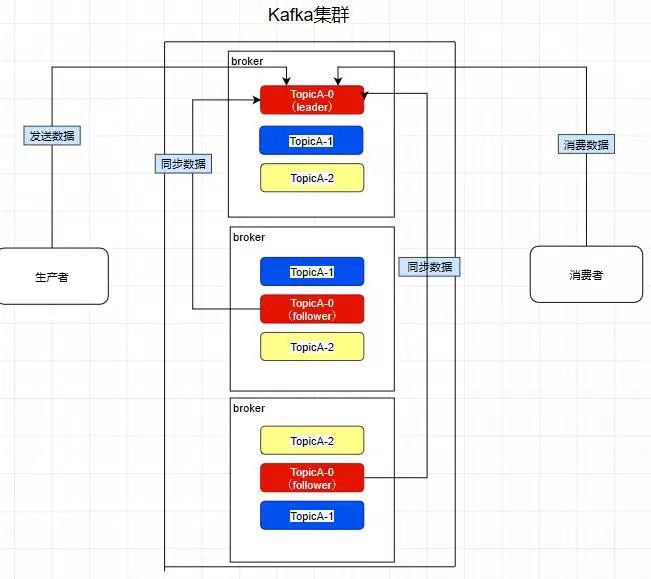
而且其实每个副本都是有角色之分的,它们会选取一个副本作为leader,而其余的作为follower,我们的生产者在发送数据的时候,是直接发送到leader partition里面 ,然后follower partition会去leader那里自行同步数据,消费者消费数据的时候,也是从leader那去消费数据的 。
Consumer Group - 消费者组
我们在消费数据时会在代码里面指定一个group.id,这个id代表的是消费组的名字,而且这个group.id就算不设置,系统也会默认设置
conf.setProperty("group.id","tellYourDream")
我们所熟知的一些消息系统一般来说会这样设计,就是只要有一个消费者去消费了消息系统里面的数据,那么其余所有的消费者都不能再去消费这个数据。可是kafka并不是这样,比如现在consumerA去消费了一个topicA里面的数据。
consumerA:
group.id = a
consumerB:
group.id = a
consumerC:
group.id = b
consumerD:
group.id = b
再让consumerB也去消费TopicA的数据,它是消费不到了,但是我们在consumerC中重新指定一个另外的group.id,consumerC是可以消费到topicA的数据的。而consumerD也是消费不到的,所以在kafka中,不同组可有唯一的一个消费者去消费同一主题的数据。
所以消费者组就是让多个消费者并行消费信息而存在的,而且它们不会消费到同一个消息,如下,consumerA,B,C是不会互相干扰的
consumer group:a
consumerA
consumerB
consumerC

如图,因为前面提到过了消费者会直接和leader建立联系,所以它们分别消费了三个leader,所以一个分区不会让消费者组里面的多个消费者去消费 ,但是在消费者不饱和的情况下,一个消费者是可以去消费多个分区的数据的 。
熟知一个规律:在大数据分布式文件系统里面,95%的都是主从式的架构,个别是对等式的架构,比如ElasticSearch。
kafka也是主从式的架构,主节点就叫controller,其余的为从节点,controller是需要和zookeeper进行配合管理整个kafka集群。
kafka和zookeeper如何配合工作
kafka严重依赖于zookeeper集群(所以之前的zookeeper文章还是有点用的)。所有的broker在启动的时候都会往zookeeper进行注册,目的就是选举出一个controller,这个选举过程非常简单粗暴,就是一个谁先谁当的过程,不涉及什么算法问题。
那成为controller之后要做啥呢,它会监听zookeeper里面的多个目录。
例如有一个目录/brokers/,其他从节点往这个目录上注册(就是往这个目录上创建属于自己的子目录而已) 自己,这时命名规则一般是它们的id编号,比如/brokers/0,1,2注册时各个节点必定会暴露自己的主机名,端口号等等的信息,此时controller就要去读取注册上来的从节点的数据(通过监听机制),生成集群的元数据信息,之后把这些信息都分发给其他的服务器,让其他服务器能感知到集群中其它成员的存在 。
此时模拟一个场景,我们创建一个主题(其实就是在zookeeper上/topics/topicA这样创建一个目录而已),kafka会把分区方案生成在这个目录中,此时controller就监听到了这一改变,它会去同步这个目录的元信息,然后同样下放给它的从节点,通过这个方法让整个集群都得知这个分区方案,此时从节点就各自创建好目录等待创建分区副本即可。这也是整个集群的管理机制。
加餐时间
1.Kafka性能好在什么地方?
① 顺序写
操作系统每次从磁盘读写数据的时候,需要先寻址,也就是先要找到数据在磁盘上的物理位置,然后再进行数据读写,如果是机械硬盘,寻址就需要较长的时间。
kafka的设计中,数据其实是存储在磁盘上面,一般来说,会把数据存储在内存上面性能才会好。但是kafka用的是顺序写,追加数据是追加到末尾,磁盘顺序写的性能极高,在磁盘个数一定,转数达到一定的情况下,基本和内存速度一致
随机写的话是在文件的某个位置修改数据,性能会较低。
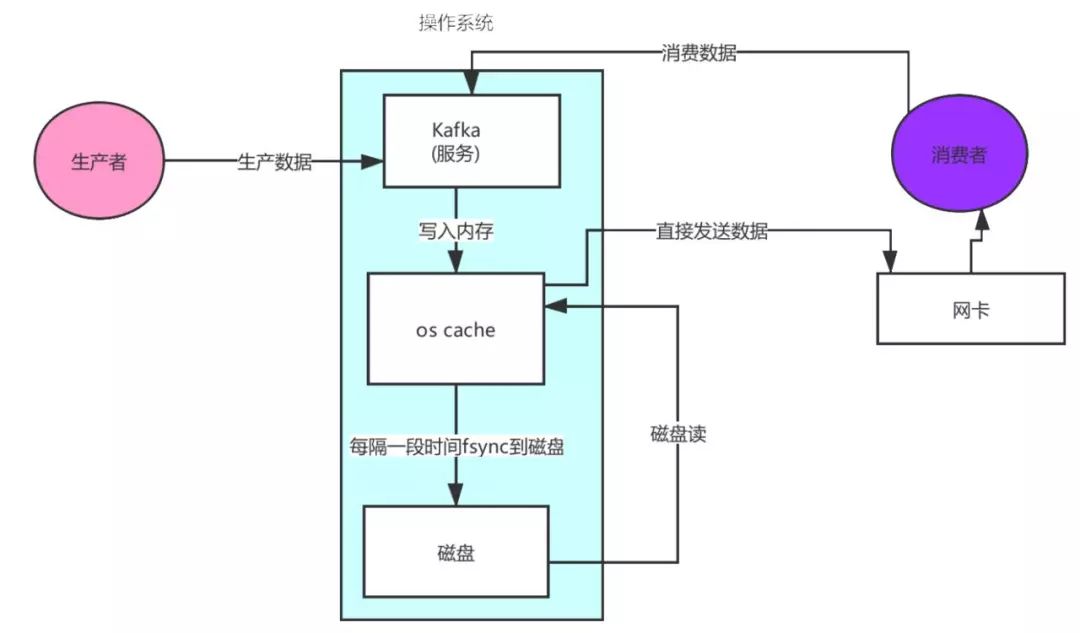
② 零拷贝
先来看看非零拷贝的情况

可以看到数据的拷贝从内存拷贝到kafka服务进程那块,又拷贝到socket缓存那块,整个过程耗费的时间比较高,kafka利用了Linux的sendFile技术(NIO),省去了进程切换和一次数据拷贝,让性能变得更好。
2.日志分段存储
Kafka规定了一个分区内的.log文件最大为1G,做这个限制目的是为了方便把.log加载到内存去操作
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindex
这个9936472之类的数字,就是代表了这个日志段文件里包含的起始offset,也就说明这个分区里至少都写入了接近1000万条数据了。
Kafka broker有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是1GB,一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做log rolling,正在被写入的那个日志段文件,叫做active log segment。
如果大家有看前面的两篇有关于HDFS的文章时,就会发现NameNode的edits log也会做出限制,所以这些框架都是会考虑到这些问题。
3.Kafka的网络设计
kafka的网络设计和Kafka的调优有关,这也是为什么它能支持高并发的原因

首先客户端发送请求全部会先发送给一个Acceptor,broker里面会存在3个线程(默认是3个),这3个线程都是叫做processor,Acceptor不会对客户端的请求做任何的处理,直接封装成一个个socketChannel发送给这些processor形成一个队列,发送的方式是轮询,就是先给第一个processor发送,然后再给第二个,第三个,然后又回到第一个。消费者线程去消费这些socketChannel时,会获取一个个request请求,这些request请求中就会伴随着数据。
线程池里面默认有8个线程,这些线程是用来处理request的,解析请求,如果request是写请求,就写到磁盘里。读的话返回结果。processor会从response中读取响应数据,然后再返回给客户端。这就是Kafka的网络三层架构。
所以如果我们需要对kafka进行增强调优,增加processor并增加线程池里面的处理线程,就可以达到效果。request和response那一块部分其实就是起到了一个缓存的效果,是考虑到processor们生成请求太快,线程数不够不能及时处理的问题。
所以这就是一个加强版的reactor网络线程模型。
Kafka的优秀设计学习的更多相关文章
- Kafka Schema Registry | 学习Avro Schema
1.目标 在这个Kafka Schema Registry教程中,我们将了解Schema Registry是什么以及为什么我们应该将它与Apache Kafka一起使用.此外,我们将看到Avro架构演 ...
- Flume-ng+Kafka+storm的学习笔记
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- kafka消息深入学习
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域. 1 快写 快读 看下面的图: 传统应用是 硬件到缓存,到应用 再socket进行传输,再进行网络传输,再到用 ...
- Kafka超详细学习笔记【概念理解,安装配置】
目录 本篇要点 Kafka介绍 作为流处理平台的三种特性 主要应用 四个核心API 基本术语 快速开始 安装配置Zookeeper 下载kafka 配置文件 Windows的命令 启动Zookeepe ...
- Kafka学习(三)-------- Kafka核心之Cosumer
了解了什么是kafka( https://www.cnblogs.com/tree1123/p/11226880.html)以后 学习核心api之消费者,kafka的消费者经过几次版本变化,特别容易混 ...
- Kafka笔记
最近做的一个项目需要跟Kafka打交道,学习了很多相关知识,就到这里来汇总一下. kafka是一个传递消息的系统,原本是用来快速记录海量log的,现在也经常用作消息队列.它主要由三个部分组成,prod ...
- Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- 干货满满,腾讯云+社区技术沙龙 Kafka Meetup 深圳站圆满结束
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 云+导语:4月22日,由腾讯云和 Kafka 社区主办.开源中国协办的腾讯云+社区技术沙龙 Kafka Meetup 深圳站在腾讯大厦举行, ...
- [转]Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 1 2 1 2 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商 ...
随机推荐
- 国外很便宜的服务器 一年 2核2G 一年20美元
今年 服务器 //=====================================一下是去年的================================= 优惠码:zhujicepin ...
- Spring 初始化流程
开始 在SpringIOC中,前面讲述了如何配置BeanDefinition和如何注册BeanDefinition,但是这些知识容器初始化的一部分,在AbstractApplicationContex ...
- ☆☆如何学习MATLAB☆☆
大多数朋友第一次接触MATLAB一般都是在大学里面开设的MATLAB课程,第一次真正使用MATLAB是在自己的毕业论文中用到.所以对于MATLAB可以说是既爱又恨.爱,是因为使用MATLAB几乎可以实 ...
- 原来VIM还可以这样玩
文章目录 配置文件vimrc vim 状态栏 状态栏配置内容 状态栏常用信息 显示状态栏 终端安全色 vimrc 配置文件 推荐 vi/vim命令大全 vim参阅 配置文件vimrc 在vim文件中执 ...
- c++ 程序编译后运行时的内存分配
程序编译后运行时的内存分配 太好的文章了,看到不得不转,转自:http://blog.sina.com.cn/s/blog_5420e0000101a0w1.html 一.编译时与运行时的内存情况 1 ...
- 一、Mybatis初体验
本文章中所有操作均在idea2019中实现. 快速入门步骤: 1)添加Mybatis包 2)创建实体类User(对应数据库操作提前已准备,参考随笔tip1) 3)编写映射文件UserMapper.xm ...
- Java超全大纲.jpg
Java超全大纲.jpg
- DHCPv4 Relay场景测试—信而泰网络测试仪实操
一.测试说明 本文主要介绍DHCPv4 Relay场景的测试仪配置方法以及需要注意的事项. DHCPv4 Relay原理: DHCP中继代理,就是在DHCP服务器和客户端之间转发DHCP数据包.当DH ...
- 企业BI应用解决方案主要包括哪些方面?
BI的地位 在实际的BI应用过程中,很多企业对数据分析的概念仅为雏形,且业务人员往往难以了解自身数据分析的需求.这就造成很多BI需求调研在和业务人员沟通的环节,业务人员难以明确需求,这使得BI沦为一个 ...
- git子模块的使用
1. 在项目中添加子模块 命令: git submodule add <url> 例子: git submodule add https://github.com/chaconinc/Db ...