物无定味适口者珍,Python3并发场景(CPU密集/IO密集)任务的并发方式的场景抉择(多线程threading/多进程multiprocessing/协程asyncio)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_221
一般情况下,大家对Python原生的并发/并行工作方式:进程、线程和协程的关系与区别都能讲清楚。甚至具体的对象名称、内置方法都可以如数家珍,这显然是极好的,但我们其实都忽略了一个问题,就是具体应用场景,三者的使用目的是一样的,话句话说,使用结果是一样的,都可以提高程序运行的效率,但到底那种场景用那种方式更好一点?
这就好比,目前主流的汽车发动机变速箱无外乎三种:双离合、CVT以及传统AT。主机厂把它们搭载到不同的发动机和车型上,它们都是变速箱,都可以将发动机产生的动力作用到车轮上,但不同使用场景下到底该选择那种变速箱?这显然也是一个问题。
所谓“无场景,不功能”,本次我们来讨论一下,具体的并发编程场景有哪些,并且对应到具体场景,应该怎么选择并发手段和方式。
什么是并发和并行?
在讨论场景之前,我们需要将多任务执行的方式进行一下分类,那就是并发方式和并行方式。教科书上告诉我们:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。 在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,但在单处理机系统中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。
好像有那么一点抽象,好吧,让我们务实一点,由于GIL全局解释器锁的存在,在Python编程领域,我们可以简单粗暴地将并发和并行用程序通过能否使用多核CPU来区分,能使用多核CPU就是并行,不能使用多核CPU,只能单核处理的,就是并发。就这么简单,是的,Python的GIL全局解释器锁帮我们把问题简化了, 这是Python的大幸?还是不幸?
Python中并发任务实现方式包含:多线程threading和协程asyncio,它们的共同点都是交替执行,而区别是多线程threading是抢占式的,而协程asyncio是协作式的,原理也很简单,只有一颗CPU可以用,而一颗CPU一次只能做一件事,所以只能靠不停地切换才能完成并发任务。
Python中并行任务的实现方式是多进程multiprocessing,通过multiprocessing库,Python可以在程序主进程中创建新的子进程。这里的一个进程可以被认为是一个几乎完全不同的程序,尽管从技术上讲,它们通常被定义为资源集合,其中资源包括内存、文件句柄等。换一种说法是,每个子进程都拥有自己的Python解释器,因此,Python中的并行任务可以使用一颗以上的CPU,每一颗CPU都可以跑一个进程,是真正的同时运行,而不需要切换,如此Python就可以完成并行任务。
什么时候使用并发?IO密集型任务
现在我们搞清楚了,Python里的并发运行方式就是多线程threading和协程asyncio,那么什么场景下使用它们?
一般情况下,任务场景,或者说的更准确一些,任务类型,无非两种:CPU密集型任务和IO密集型任务。
什么是IO密集型任务?IO就是Input-Output的缩写,说白了就是程序的输入和输出,想一想确实就是这样,您的电脑,它不就是这两种功能吗?用键盘、麦克风、摄像头输入数据,然后再用屏幕和音箱进行输出操作。
但输入和输出操作要比电脑中的CPU运行速度慢,换句话说,CPU得等着这些比它慢的输入和输出操作,说白了就是CPU运算一会,就得等这些IO操作,等IO操作完了,CPU才能继续运算一会,然后再等着IO操作,如图所示:
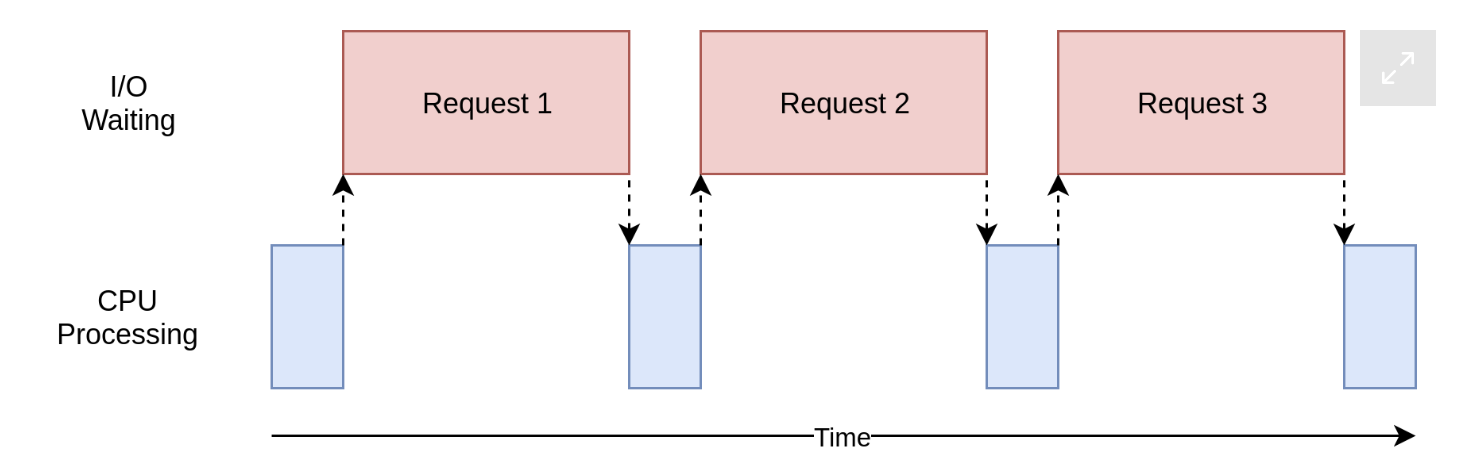
由此可知,并发适合这种IO操作密集和频繁的工作,因为就算CPU是苹果最新ARM架构的M2芯片,也没有用武之地。
另外,如果把IO密集型任务具象化,那就是我们经常操作的:硬盘读写(数据库读写)、网络请求、文件的打印等等。
并发方式的选择:多线程threading还是协程asyncio?
既然涉及硬盘读写(数据库读写)、网络请求、文件打印等任务都算并发任务,那我们就真正地实践一下,看看不同的并发方式到底能提升多少效率?
一个简单的小需求,对本站数据进行重复抓取操作,并计算首页数据文本的行数:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"下载了{len(response.content)}行数据")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
在不使用任何并发手段的前提下,程序返回:
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了76347行数据
下载了 50 次数据,执行了8.781155824661255秒
[Finished in 9.6s]
这里程序的每一步都是同步操作,也就是说当第一次抓取网站首页时,剩下的49次都在等待。
接着使用多线程threading来改造程序:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"下载了{len(response.content)}行数据")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
这里通过with关键词开启线程池上下文管理器,并发8个线程进行下载,程序返回:
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76161行数据
下载了76424行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了 50次,执行了7.680492877960205秒
很明显,效率上有所提升,事实上,每个线程其实是在不停“切换”着运行,这就节省了单线程每次等待爬取结果的时间:
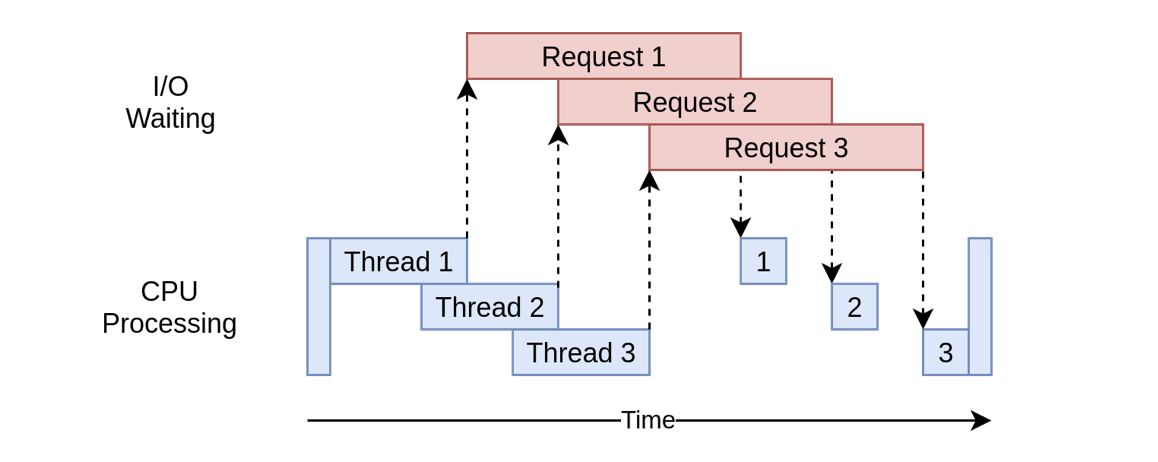
由此带来了另外一个问题:上下文切换的时间开销。
让我们继续改造,用协程来一试锋芒,首先安装异步web请求库aiohttp:
pip3 install aiohttp
改写逻辑:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print(f"下载了{response.content_length}行数据")
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
asyncio.run(download_all_sites(sites))
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
程序返回:
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76424行数据
下载了76161行数据
下载了76424行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了76161行数据
下载了 50次,执行了6.893810987472534秒
效率上百尺竿头更进一步,同样的使用with关键字操作上下文管理器,协程使用asyncio.ensure_future()创建任务列表,该列表还负责启动它们。创建所有任务后,使用asyncio.gather()来保持会话上下文的实例,直到所有爬取任务完成。和多线程threading的区别是,协程并不需要切换上下文,因此每个任务所需的资源和创建时间要少得多,因此创建和运行更多的任务效率更高:
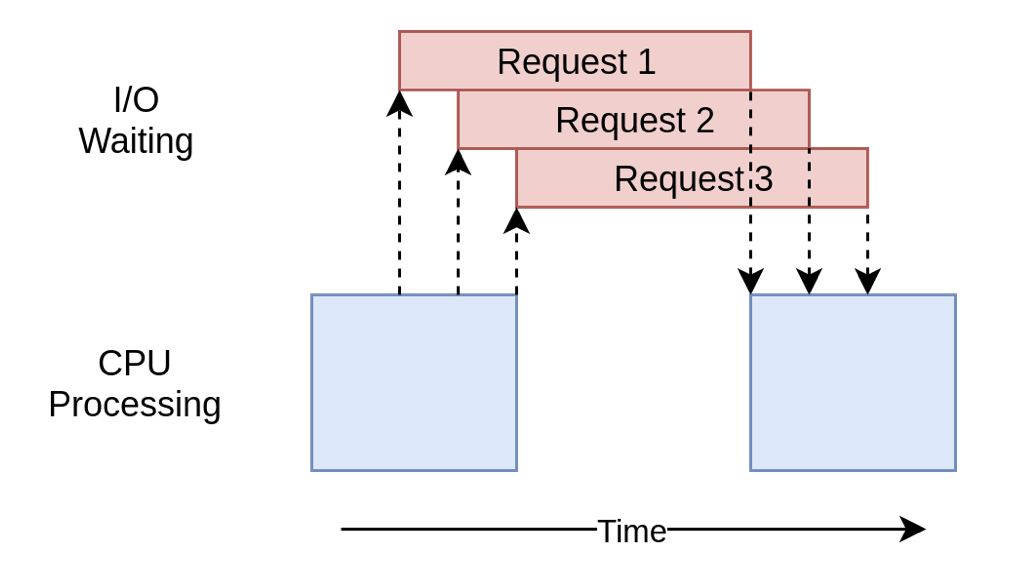
综上,并发逻辑归根结底是减少CPU等待的时间,也就是让CPU少等一会儿,而协程的工作方式显然让CPU等待的时间最少。
并行方式:多进程multiprocessing
再来试试多进程multiprocessing,并行能不能干并发的事?
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"读了{len(response.content)}行")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = ["https://v3u.cn"] * 50
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"下载了 {len(sites)}次,执行了{duration}秒")
这里我们依然使用上下文管理器开启进程池,默认进程数匹配当前计算机的CPU核心数,也就是有几核就开启几个进程,程序返回:
读了76000行
读了76241行
读了76044行
读了75894行
读了76290行
读了76312行
读了76419行
读了76753行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
读了76290行
下载了 50次,执行了8.195281982421875秒
虽然比同步程序要快,但无疑的,效率上要低于多线程和协程。为什么?因为多进程不适合IO密集型任务,虽然可以利用多核资源,但没有任何意义:
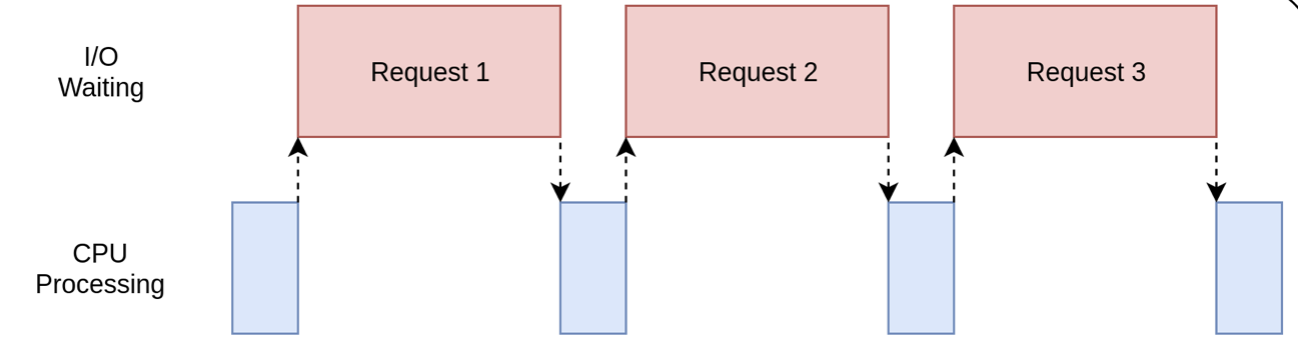
无论开多少进程,CPU都没有用武之地,多数情况下CPU都在等待IO操作,也就是说,多核反而拖累了IO程序的执行。
并行方式的选择:CPU密集型任务
什么是CPU密集型任务?这里我们可以使用逆定理:所有不涉及硬盘读写(数据库读写)、网络请求、文件打印等任务都算CPU密集型任务任务,说白了就是,计算型任务。
以求平方和为例子:
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
同步执行20次,需要花费多少时间?
4.466595888137817秒
再来试试并行方式:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
八核处理器,开八个进程开始跑:
1.1755797863006592秒
不言而喻,并行方式有效提高了计算效率。
最后,既然之前用并行方式运行了IO密集型任务,我们就再来试试用并发的方式运行CPU密集型任务:
import concurrent.futures
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
executor.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"{duration}秒")
单进程开8个线程,走起:
4.452666759490967秒
如何?和并行方式运行IO密集型任务一样,可以运行,但是没有任何意义。为什么?因为没有任何IO操作了,CPU不需要等待了,CPU只要全力运算即可,所以你上多线程或者协程,无非就是画蛇添足、多此一举。
结语
有经验的汽修师傅会告诉你,想省油就选CVT和双离合,想质量稳定就选AT,经常高速上激烈驾驶就选双离合,经常市区内堵车就选CVT;同样地,作为经验丰富的后台研发,你也可以告诉汽修师傅,任何不需要CPU等待的任务就选择并行(multiprocessing)的处理方式,而需要CPU等待时间过长的任务,选择并发(threading/asyncio)。反过来,我就想用CVT在高速上飙车,用双离合在市区堵车,行不行?行,但没有意义,或者说的更准确一些,没有任何额外的收益;而用并发方式执行CPU密集型任务,用并行方式执行IO密集型任务行不行?也行,但依然没有任何额外的收益, 无他,唯物无定味,适口者珍矣。
原文转载自「刘悦的技术博客」 https://v3u.cn/a_id_221
物无定味适口者珍,Python3并发场景(CPU密集/IO密集)任务的并发方式的场景抉择(多线程threading/多进程multiprocessing/协程asyncio)的更多相关文章
- 并发异步编程之争:协程(asyncio)到底需不需要加锁?(线程/协程安全/挂起/主动切换)Python3
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_208 协程与线程向来焦孟不离,但事实上是,线程更被我们所熟知,在Python编程领域,单核同时间内只能有一个线程运行,这并不是什么 ...
- 运筹帷幄决胜千里,Python3.10原生协程asyncio工业级真实协程异步消费任务调度实践
我们一直都相信这样一种说法:协程是比多线程更高效的一种并发工作方式,它完全由程序本身所控制,也就是在用户态执行,协程避免了像线程切换那样产生的上下文切换,在性能方面得到了很大的提升.毫无疑问,这是颠扑 ...
- 【Python】【容器 | 迭代对象 | 迭代器 | 生成器 | 生成器表达式 | 协程 | 期物 | 任务】
Python 的 asyncio 类似于 C++ 的 Boost.Asio. 所谓「异步 IO」,就是你发起一个 IO 操作,却不用等它结束,你可以继续做其他事情,当它结束时,你会得到通知. Asyn ...
- Python3 与 C# 并发编程之~ 协程篇
3.协程篇¶ 去年微信公众号就陆陆续续发布了,我一直以为博客也汇总同步了,这几天有朋友说一直没找到,遂发现,的确是漏了,所以补上一篇 在线预览:https://github.lesschina.c ...
- python3之协程
1.协程的概念 协程,又称微线程,纤程.英文名Coroutine. 线程是系统级别的它们由操作系统调度,而协程则是程序级别的由程序根据需要自己调度.在一个线程中会有很多函数,我们把这些函数称为子程序, ...
- 11.python3标准库--使用进程、线程和协程提供并发性
''' python提供了一些复杂的工具用于管理使用进程和线程的并发操作. 通过应用这些计数,使用这些模块并发地运行作业的各个部分,即便是一些相当简单的程序也可以更快的运行 subprocess提供了 ...
- 搞定python多线程和多进程
1 概念梳理: 1.1 线程 1.1.1 什么是线程 线程是操作系统能够进行运算调度的最小单位.它被包含在进程之中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发 ...
- python3通过gevent.pool限制协程并发数量
协程虽然是轻量级的线程,但到达一定数量后,仍然会造成服务器崩溃出错.最好的方法通过限制协程并发数量来解决此类问题. server代码: #!/usr/bin/env python # -*- codi ...
- python3 多线程和多进程
一.线程和进程 1.操作系统中,线程是CPU调度和分派的基本单位,线程依存于程序中 2.操作系统中,进程是系统进行资源分配和调度的一个基本单位,一个程序至少有一个进程 3.一个进程由至少一个线程组成, ...
随机推荐
- 力扣算法:LC 704-二分查找,LC 27-移除元素--js
LC 704-二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1. 示例 ...
- Vulnhub-napping
1.信息收集 先用arp-scan探测出靶机地址 arps-scan -l 显然靶机地址 10.1.1.106,然后利用nmap进行详细信息收集 nmap -A 10.1.1.106 可以看到,目标的 ...
- 技术分享 | 云原生多模型 NoSQL 概述
作者 朱建平,TEG/云架构平台部/块与表格存储中心副总监.08年加入腾讯后,承担过对象存储.键值存储,先后负责过KV存储-TSSD.对象存储-TFS等多个存储平台. NoSQL 技术和行业背景 No ...
- linux篇-linux LAMP yum版安装
LAMP(linux.apache.mysql.php),是四个套件的合成,简单讲就是要把php运行在linux上,需要依赖apache和mysql数据库. 1 准备好一个linux系统(centos ...
- vue ui 创建vue项目 没反应的解决办法 2021
1.升级vue 脚手架 即可 2.再 vue ui 创建项目 cnpm i -g @vue/cli
- 亿信BI——维度转换组件使用
功能模块: 用户点击"维度转换"模块进行维度转换操作,维度转换页面的顶部导航栏包括基本属性和转换设置两部分. 基础属性: 在基本属性模块部分,编号.标题和类型是必填项且系统已经默认 ...
- Flask表单验证
学习内容:①判断请求方式(request.method) from flask import Flask,render_template,request app = Flask(__name__) @ ...
- iOS全埋点解决方案-数据存储
前言 SDK 需要把事件数据缓冲到本地,待符合一定策略再去同步数据. 一.数据存储策略 在 iOS 应用程序中,从 "数据缓冲在哪里" 这个纬度看,缓冲一般分两种类型. 内 ...
- 基于 GraphQL 的 BFF 实践
随着软件工程的发展,系统架构越来越复杂,分层越来越多,分工也越来越细化.我们知道,互联网是离用户最近的行业,前端页面可以说无时无刻不在变化.前端本质上还是用户交互和数据展示,页面的高频变化意味着对数据 ...
- 手把手教你 Docker搭建mysql并配置远程访问
一.使用docker部署mysql 1.在docker中搜索要安装的mysql docker search mysql (这步其实可以跳过O(∩_∩)O哈哈~) 2.拉取mysql镜像 docker ...