elasticsearch多字段聚合实现方式
1、背景
我们知道在sql中是可以实现 group by 字段a,字段b,那么这种效果在elasticsearch中该如何实现呢?此处我们记录在elasticsearch中的3种方式来实现这个效果。
2、实现多字段聚合的思路
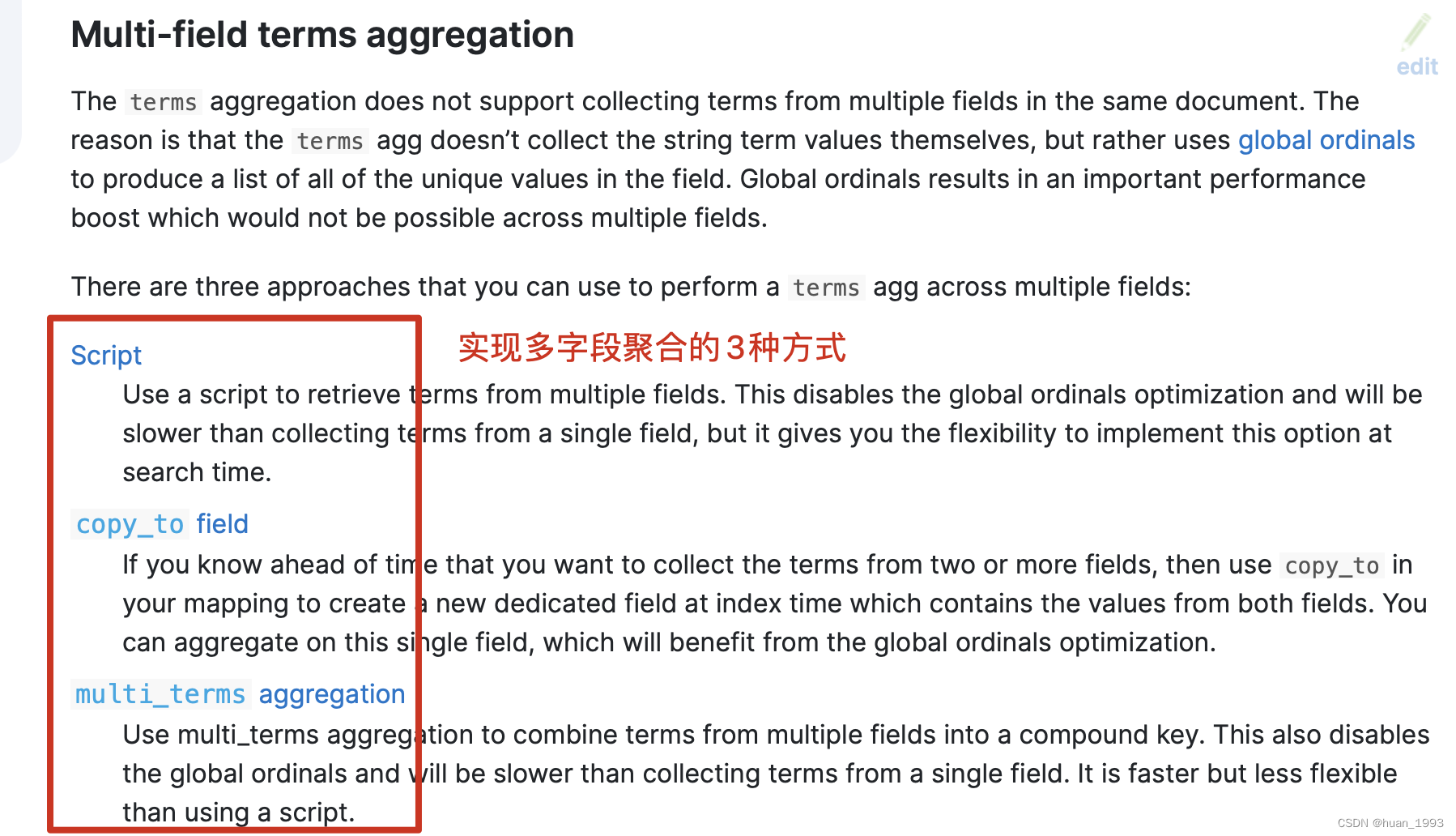
图片来源:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html
从上图中,我们可以知道,可以通过3种方式来实现 多字段的聚合操作。
3、需求
根据省(province)和性别(sex)来进行聚合,然后根据聚合后的每个桶的数据,在根据每个桶中的最大年龄(age)来进行倒序排序。
4、数据准备
4.1 创建索引
PUT /index_person
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
},
"province": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
4.2 准备数据
PUT /_bulk
{"create":{"_index":"index_person","_id":1}}
{"id":1,"name":"张三","sex":"男","age":20,"province":"湖北","address":"湖北省黄冈市罗田县匡河镇"}
{"create":{"_index":"index_person","_id":2}}
{"id":2,"name":"李四","sex":"男","age":19,"province":"江苏","address":"江苏省南京市"}
{"create":{"_index":"index_person","_id":3}}
{"id":3,"name":"王武","sex":"女","age":25,"province":"湖北","address":"湖北省武汉市江汉区"}
{"create":{"_index":"index_person","_id":4}}
{"id":4,"name":"赵六","sex":"女","age":30,"province":"北京","address":"北京市东城区"}
{"create":{"_index":"index_person","_id":5}}
{"id":5,"name":"钱七","sex":"女","age":16,"province":"北京","address":"北京市西城区"}
{"create":{"_index":"index_person","_id":6}}
{"id":6,"name":"王八","sex":"女","age":45,"province":"北京","address":"北京市朝阳区"}
5、实现方式
5.1 multi_terms实现
5.1.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province_sex": {
"multi_terms": {
"size": 10,
"shard_size": 25,
"order":{
"max_age": "desc"
},
"terms": [
{
"field": "province",
"missing": "defaultProvince"
},
{
"field": "sex"
}
]
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
}
}
5.1.2 java 代码
@Test
@DisplayName("多term聚合-根据省和性别聚合,然后根据最大年龄倒序")
public void agg01() throws IOException {
SearchRequest searchRequest = new SearchRequest.Builder()
.size(0)
.index("index_person")
.aggregations("agg_province_sex", agg ->
agg.multiTerms(multiTerms ->
multiTerms.terms(term -> term.field("province"))
.terms(term -> term.field("sex"))
.order(new NamedValue<>("max_age", SortOrder.Desc))
)
.aggregations("max_age", ageAgg ->
ageAgg.max(max -> max.field("age")))
)
.build();
System.out.println(searchRequest);
SearchResponse<Object> response = client.search(searchRequest, Object.class);
System.out.println(response);
}
5.1.3 运行结果
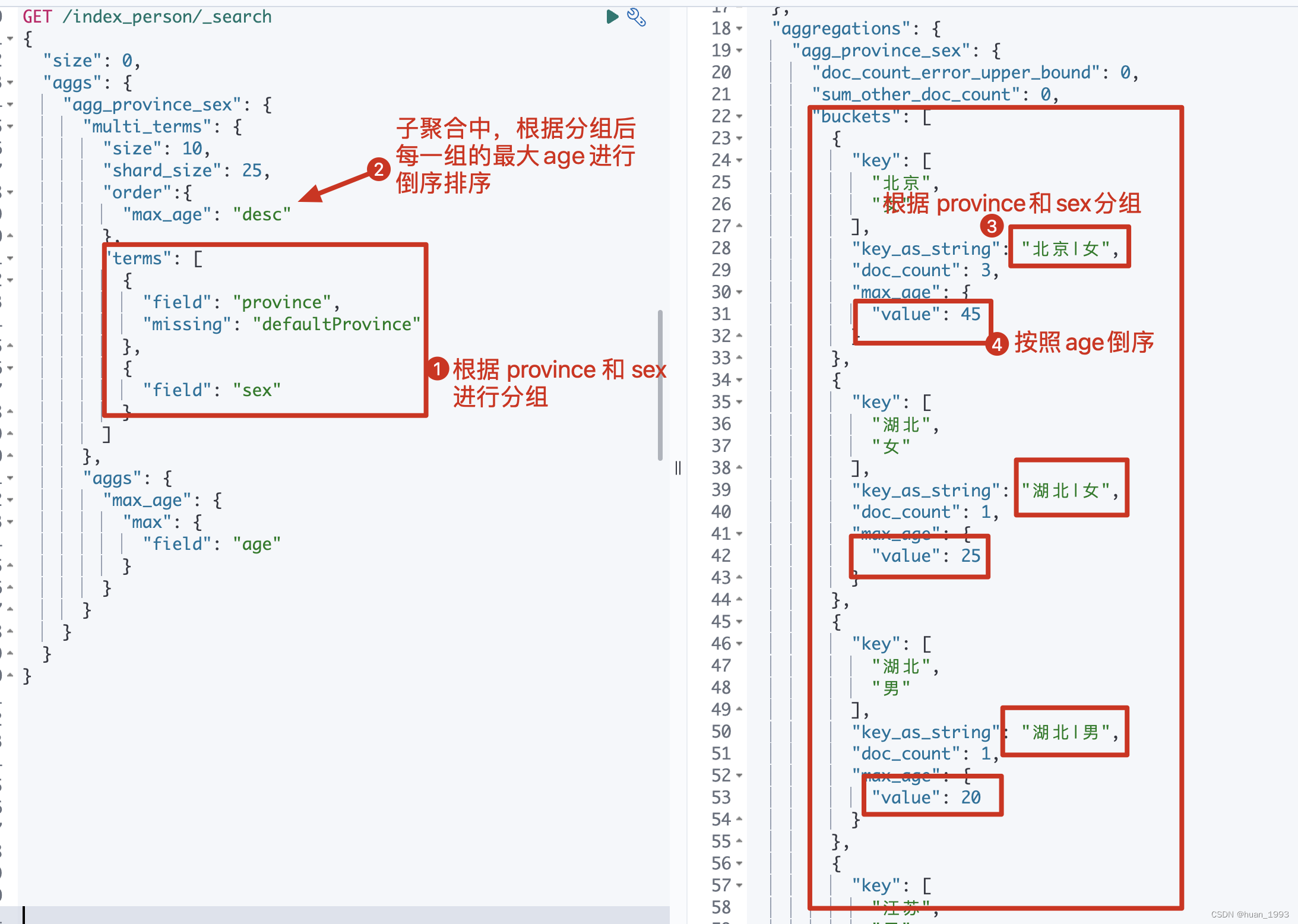
5.2 script实现
5.2.1 dsl
GET /index_person/_search
{
"size": 0,
"runtime_mappings": {
"runtime_province_sex": {
"type": "keyword",
"script": """
String province = doc['province'].value;
String sex = doc['sex'].value;
emit(province + '|' + sex);
"""
}
},
"aggs": {
"agg_province_sex": {
"terms": {
"field": "runtime_province_sex",
"size": 10,
"shard_size": 25,
"order": {
"max_age": "desc"
}
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
}
}
5.2.2 java代码
@Test
@DisplayName("多term聚合-根据省和性别聚合,然后根据最大年龄倒序")
public void agg02() throws IOException {
SearchRequest searchRequest = new SearchRequest.Builder()
.size(0)
.index("index_person")
.runtimeMappings("runtime_province_sex", field -> {
field.type(RuntimeFieldType.Keyword);
field.script(script -> script.inline(new InlineScript.Builder()
.lang(ScriptLanguage.Painless)
.source("String province = doc['province'].value;\n" +
" String sex = doc['sex'].value;\n" +
" emit(province + '|' + sex);")
.build()));
return field;
})
.aggregations("agg_province_sex", agg ->
agg.terms(terms ->
terms.field("runtime_province_sex")
.size(10)
.shardSize(25)
.order(new NamedValue<>("max_age", SortOrder.Desc))
)
.aggregations("max_age", minAgg ->
minAgg.max(max -> max.field("age")))
)
.build();
System.out.println(searchRequest);
SearchResponse<Object> response = client.search(searchRequest, Object.class);
System.out.println(response);
}
5.2.3 运行结果
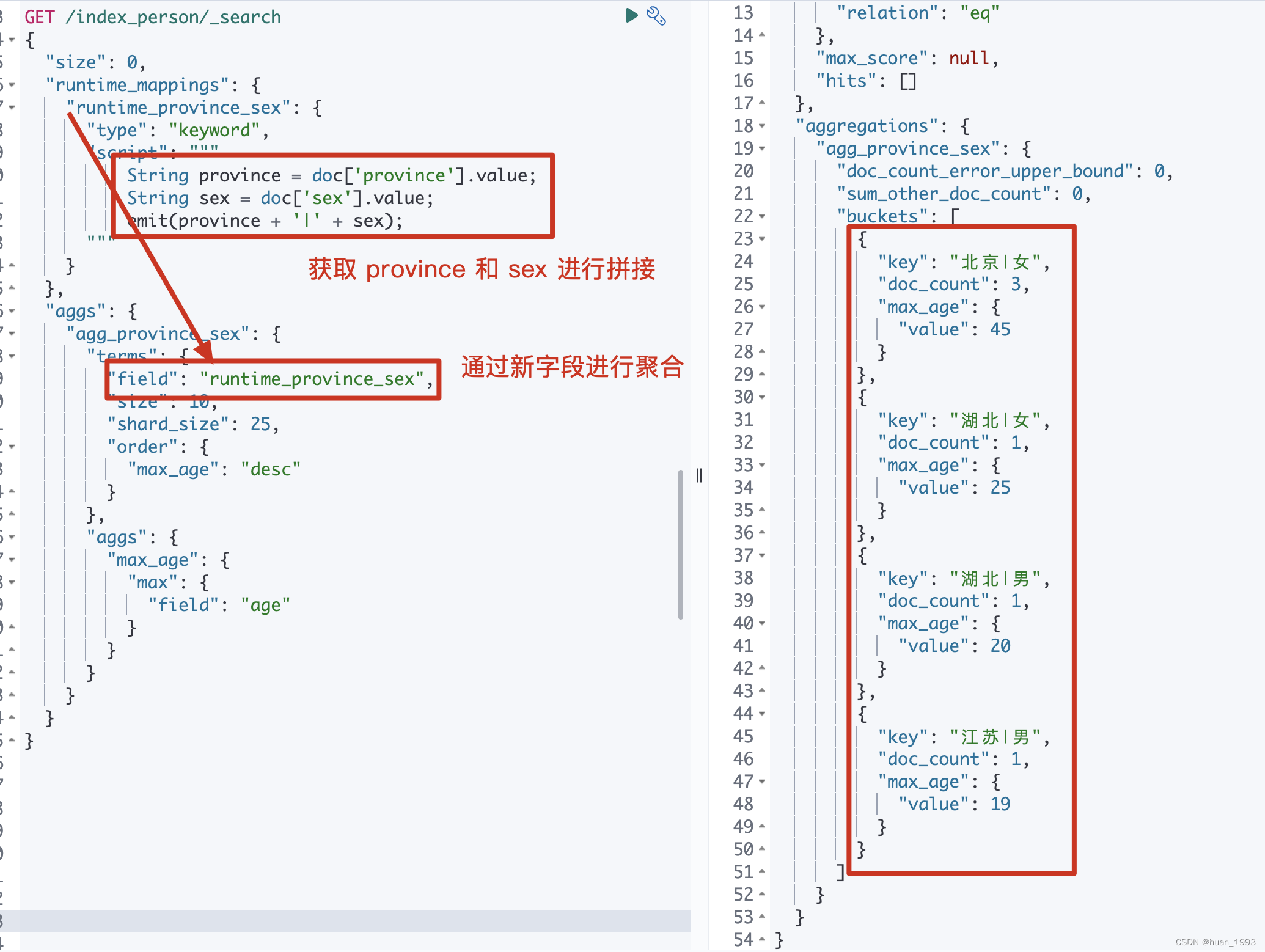
5.3 通过copyto实现
我本地测试过,通过copyto没实现,此处故先不考虑
5.5 通过pipeline来实现
实现思路:
创建mapping时,多创建一个字段pipeline_province_sex,该字段的值由创建数据时指定pipeline来生产。
5.4.1 创建mapping
PUT /index_person
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
},
"province": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"pipeline_province_sex":{
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
此处指定了一个字段pipeline_province_sex,该字段的值会由pipeline来处理。
5.4.2 创建pipeline
PUT _ingest/pipeline/pipeline_index_person_provice_sex
{
"description": "将provice和sex的值拼接起来",
"processors": [
{
"set": {
"field": "pipeline_province_sex",
"value": ["{{province}}", "{{sex}}"]
},
"join": {
"field": "pipeline_province_sex",
"separator": "|"
}
}
]
}
5.4.3 插入数据
PUT /_bulk?pipeline=pipeline_index_person_provice_sex
{"create":{"_index":"index_person","_id":1}}
{"id":1,"name":"张三","sex":"男","age":20,"province":"湖北","address":"湖北省黄冈市罗田县匡河镇"}
{"create":{"_index":"index_person","_id":2}}
{"id":2,"name":"李四","sex":"男","age":19,"province":"江苏","address":"江苏省南京市"}
{"create":{"_index":"index_person","_id":3}}
{"id":3,"name":"王武","sex":"女","age":25,"province":"湖北","address":"湖北省武汉市江汉区"}
{"create":{"_index":"index_person","_id":4}}
{"id":4,"name":"赵六","sex":"女","age":30,"province":"北京","address":"北京市东城区"}
{"create":{"_index":"index_person","_id":5}}
{"id":5,"name":"钱七","sex":"女","age":16,"province":"北京","address":"北京市西城区"}
{"create":{"_index":"index_person","_id":6}}
{"id":6,"name":"王八","sex":"女","age":45,"province":"北京","address":"北京市朝阳区"}
注意: 此处的插入需要指定上一步的pipeline
PUT /_bulk?pipeline=pipeline_index_person_provice_sex
5.4.4 聚合dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province_sex": {
"terms": {
"field": "pipeline_province_sex",
"size": 10,
"shard_size": 25,
"order": {
"max_age": "desc"
}
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
}
}
5.4.5 运行结果
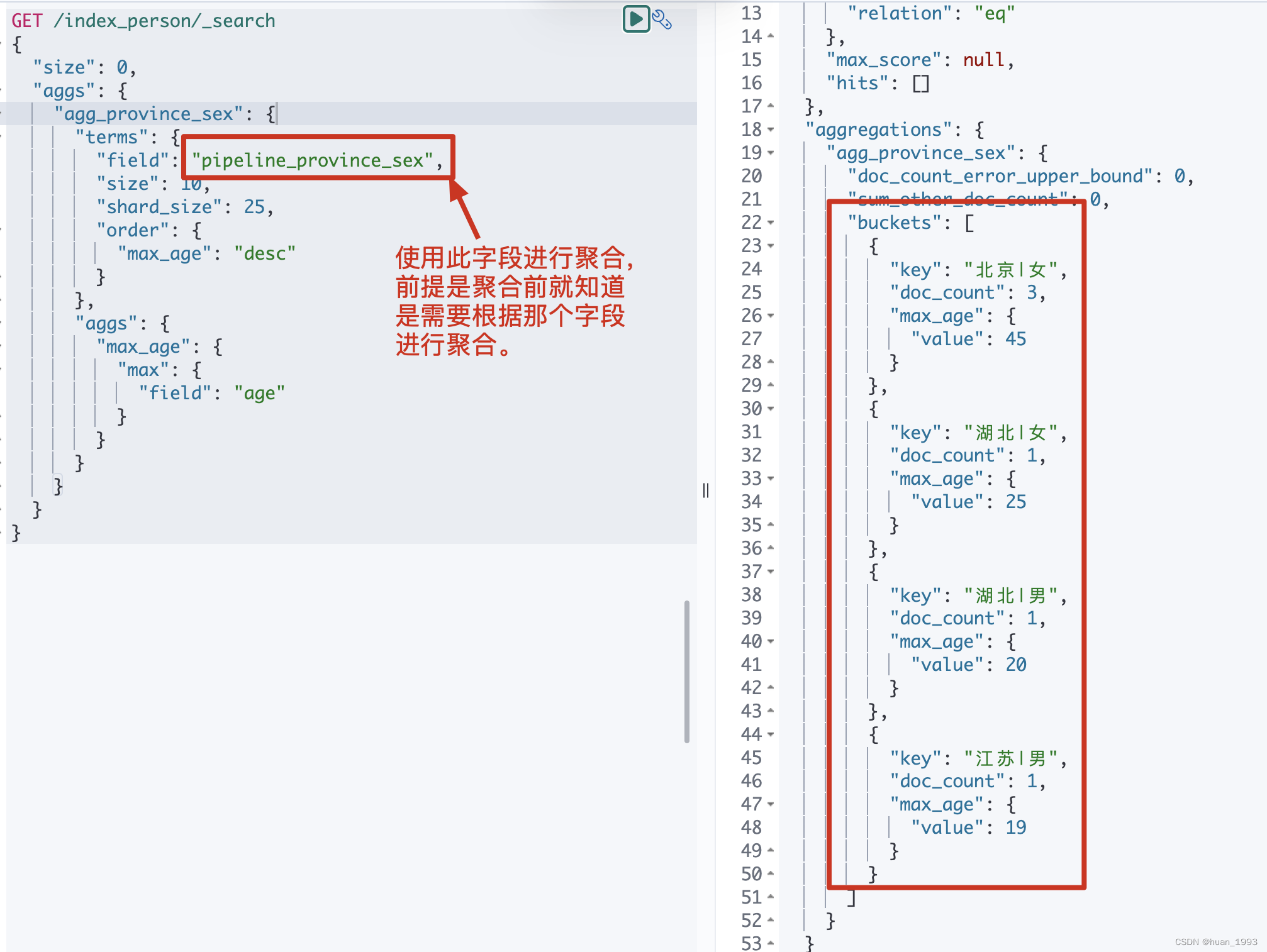
6、实现代码
7、参考文档
elasticsearch多字段聚合实现方式的更多相关文章
- elasticsearch 多字段聚合或者对字段子串聚合
以下是字段子串聚合,截取 'your_field' 前八位进行聚合的 Script script = new Script("doc['your_field'].getValue().sub ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- ElasticSearch6.0 高级应用之 多字段聚合Aggregation(二)
ElasticSearch6.0 多字段聚合网上完整的资料很少 ,所以作者经过查阅资料,编写了聚合高级使用例子 例子是根据电商搜索实际场景模拟出来的 希望给大家带来帮助! 下面我们开始吧! 1. 创建 ...
- 跟我一起学extjs5(17--Grid金额字段单位MVVM方式的选择)
跟我一起学extjs5(17--Grid金额字段单位MVVM方式的选择) 这一节来完毕Grid中的金额字段的金额单位的转换.转换旰使用MVVM特性,整体上和控制菜单的几种模式类似.首先 ...
- Dynamics CRM 通过Odata创建及更新记录各类型字段的赋值方式
CRM中通过Odata方式去创建或者更新记录时,各种类型的字段的赋值方式各不相同,这里转载一篇博文很详细的列出了各类型字段赋值方式,以供后期如有遗忘再次查询使用. http://luoyong0201 ...
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- 修改MySQL数据库中表和表中字段的编码方式的方法
今天向MySQL数据库中的一张表添加含有中文的数据,可是老是出异常,检查程序并没有发现错误,无奈呀,后来重新检查这张表发现表的编码方式为latin1并且原想可以插入中文的字段的编码方式也是latin1 ...
- [Elasticsearch] 多字段搜索 (六) - 自定义_all字段,跨域查询及精确值字段
自定义_all字段 在元数据:_all字段中,我们解释了特殊的_all字段会将其它所有字段中的值作为一个大字符串进行索引.尽管将所有字段的值作为一个字段进行索引并不是非常灵活.如果有一个自定义的_al ...
- ElasticSearch 6.2 Mapping参数说明及text类型字段聚合查询配置
背景: 由于本人使用的是6.0以上的版本es,在使用发现很多中文博客对于mapping参数的说明已过时.ES6.0以后有很多参数变化. 现我根据官网总结mapping最新的参数,希望能对大家有用处. ...
- 【转】elasticsearch中字段类型默认显示{ "foo": { "type": "text", "fields": { "keyword": {"type": "keyword", "ignore_above": 256} }
官方原文链接:https://www.elastic.co/cn/blog/strings-are-dead-long-live-strings 转载原文连接:https://segmentfault ...
随机推荐
- 使用 Mypy 检查 30 万行 Python 代码,总结出 3 大痛点与 6 个技巧!
作者:Charlie Marsh 译者:豌豆花下猫@Python猫 英文:Using Mypy in production at Spring (https://notes.crmarsh.com/u ...
- 【读书笔记】C#高级编程 第八章 委托、lambda表达式和事件
(一)引用方法 委托是寻址方法的.NET版本.委托是类型安全的类,它定义了返回类型和参数的类型.委托不仅包含对方法的引用,也可以包含对多个方法的引用. Lambda表达式与委托直接相关.当参数是委托类 ...
- 【SQLServer】max worker threads参数配置
查看和设置max worker threads USE master; //选中你想设置max worker threads的数据库.master表示在实例级别进行设置 GO EXEC sp_conf ...
- jenkins流水线部署springboot应用到k8s集群(k3s+jenkins+gitee+maven+docker)(2)
前言:上篇已介绍了jenkins在k3s环境部署,本篇继续上篇讲述流水线构建部署流程 1.从gitlab上拉取代码步骤 在jenkins中,新建一个凭证:Manage Jenkins -> Ma ...
- 国产CPLD(AGM1280)试用记录——做个SPI接口的任意波形DDS [原创www.cnblogs.com/helesheng]
我之前用过的CPLD有Altera公司的MAX和MAX-II系列,主要有两个优点:1.程序存储在片上Flash,上电即行,保密性高.2.CPLD器件规模小,成本和功耗低,时序不收敛情况也不容易出现.缺 ...
- windows下 Rust 环境配置
搭建 Visual Studio Code 开发环境 首先,需要安装最新版的 Rust 编译工具和 Visual Studio Code. Rust 编译工具:https://www.rust-lan ...
- 认识RocketMQ4.x架构设计
消息模型 单体的消息模型 RocketMQ消息模型跟其他的消息队列一样 都是 producer - > topic->consumer producer 生产消息 也就是发送者 topic ...
- ES 7.13版本设置索引模板和索引生命周期管理
第一步:索引管理中查看都有哪些索引文件,然后添加索引模式(后面的日期用*表示) 第二步:索引生命周期管理 自带的有一个log,就使用这个,不用再新建了,根据需求修改里面的配置就行了 第三步:添加索引模 ...
- SkyWalking简要介绍
什么是 SkyWalking 分布式系统的应用程序性能监视工具,专为微服务.云原生架构和基于容器(Docker.K8s.Mesos)架构而设计.提供分布式追踪.服务网格遥测分析.度量聚合和可视化一体化 ...
- Kibana仪表盘(Dashboard)详解
Kibana 仪表板(Dashboard) 展示保存的可视化结果集合. 在编辑模式下,您可以根据需要安排和调整可视化结果集,并保存仪表板,以便重新加载和共享. 创建一个仪表板 如何创建一个仪表板: 点 ...