Neighborhood Attention Transformer概述
0.前言
1.针对的问题
1.之前的视觉Transformer关于嵌入维数(不包括线性投影)是线性的,但相对于token的数量是二次的,而在视觉范围内,token的数量通常与图像分辨率呈线性相关。因此,在严格使用自注意力的模型(如ViT)中,较高的图像分辨率会导致复杂度和内存使用量的二次增长。
2.卷积受益于一些归纳偏置,如局部性,平移不变性和二维邻域结构,而点积自注意力操作是一维全局操作,虽然视觉转换器中的MLP层是局部的和平移等变的,但其余的归纳偏差必须通过大量数据或高级训练技术和增强来学习。
2.主要贡献
1.提出邻域注意(NA):一种简单而灵活的视觉注意机制,它将每个标记的接受域定位到其邻域。将该模块的复杂性和内存使用与自注意、窗口自注意和卷积进行了比较。
2.引入了邻域注意Transformer(NAT),这是一种新型的高效、准确、可扩展的分层Transformer。每一层之后都有一个下采样操作,将空间大小减少了一半。类似的设计也可以在最近许多基于注意力的模型中看到,比如Swin。与这些模型不同,NAT利用小核重叠卷积进行嵌入和下采样,而不是非重叠卷积。与Swin等现有技术相比,NAT还引入了一套更有效的架构配置。
3.证明了NAT在分类和下游视觉任务上的有效性,包括目标检测和语义分割。我们观察到,NAT不仅可以超越Swin,而且还可以超越新的卷积竞争者。NAT-Tiny仅使用4.3个GFLOPs和28M参数,在NmageNet上的准确率达到83.2%,在MS-COCO上的边界框mAP为51.4%,在ADE20k上的mIoU为48.4%
4.开放一个新的CUDA支持的PyTorch扩展,用于快速和高效地计算基于窗口的注意机制。除了支持2D邻域注意模块外,该扩展还将允许定制的padding值,strides和dilated neighborhoods,以及1D和3D数据。
3.方法
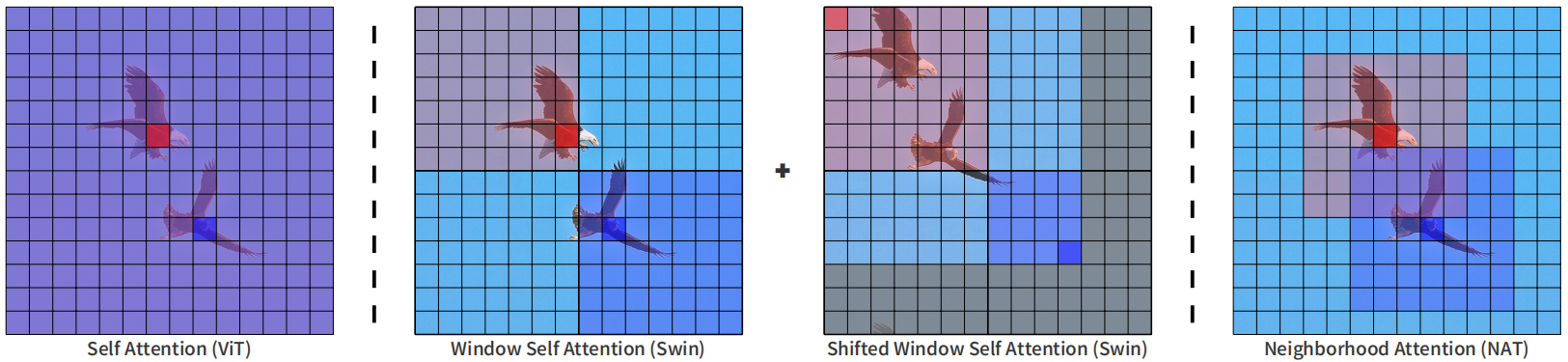
下面这个图展示了ViT,Swin和NAT的区别,标准VIT的attention计算是全局的,像第一图中红色的 token 和蓝色的 token 会全局的和所有的 token 进行计算。swin 是中间的两个图,第一步 token 的特征交互限制在局部窗口内。第二步窗口有shift,但 token 的特征交互仍然在局部的窗口内。最后一个图就是这个论文提出的 neighborhood attention transformer,NAT,所有 attention 的计算在7X7的邻域里进行。看起来和convolution一样,只是在一个 kernel 里面的范围内去做操作。但是和 convolution 不同的是,NAT里面是计算 attention,所以每一个 value 出来的权重是根据输入的这个值来决定的,而不是像卷积核里面那样训练好就固定的一个值。
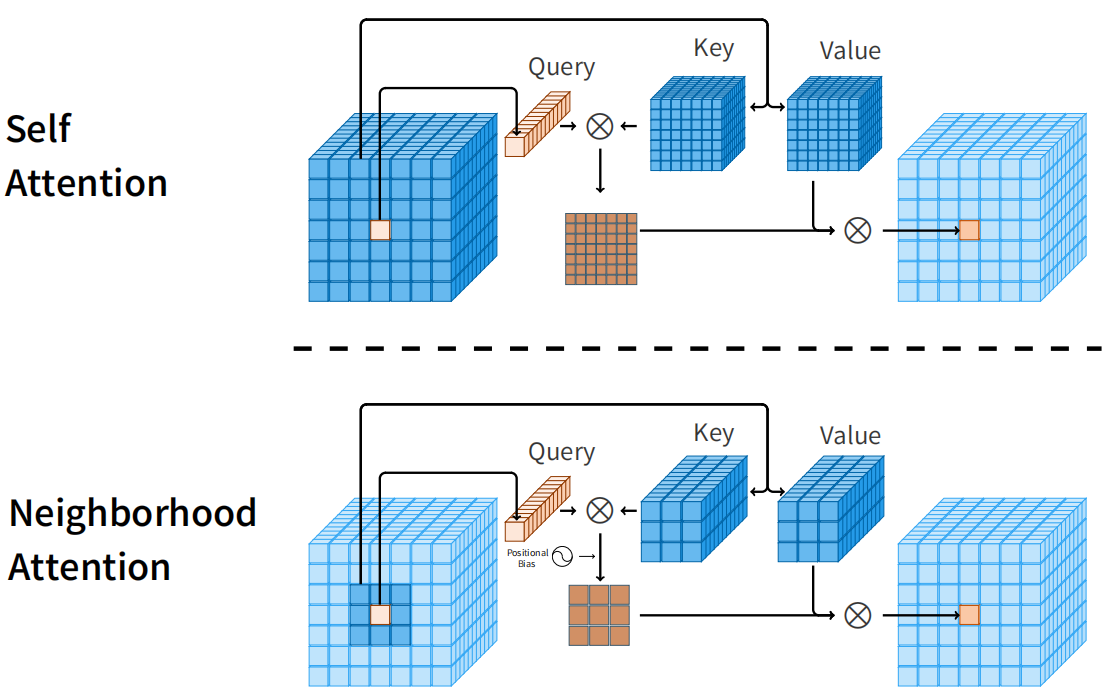
下面是自注意力与邻域注意力的比较,自注意力允许每个tokens关注所有其他tokens,而邻域注意力将每个tokens的接受域定位到其周围的邻域。对于CHW的输入矩阵,Query 是某个位置一个 1XC的向量, key 是一个 3x3xC 的矩阵,两个矩阵逐元素相乘(尺寸不同进行 broadcast ),结果是 3x3xC,最后在 C 这个维度求和,得到3X3的相似度矩阵。用这个矩阵给 value 分配权重 ,最后合并为一个 1x1xC 的向量,就是 attention 的计算结果。
将(i,j)像素位置的邻域定义为ρ(i,j),每个像素的NA计算公式为
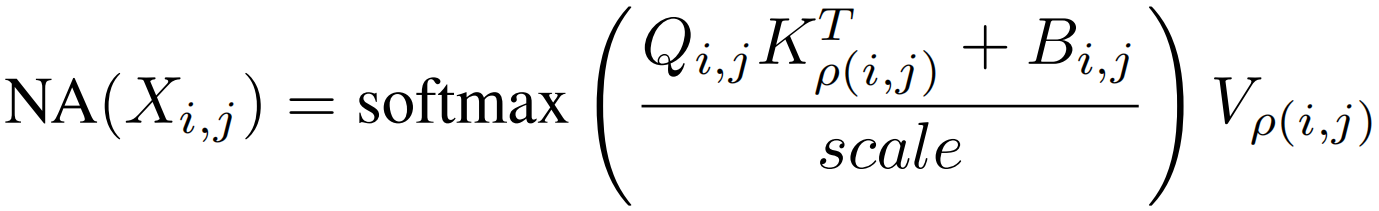
Q,K,V是X的线性投影,Bi,j表示相对位置偏差,当邻域超过输入大小时,就成了带额外位置偏差的自注意力。
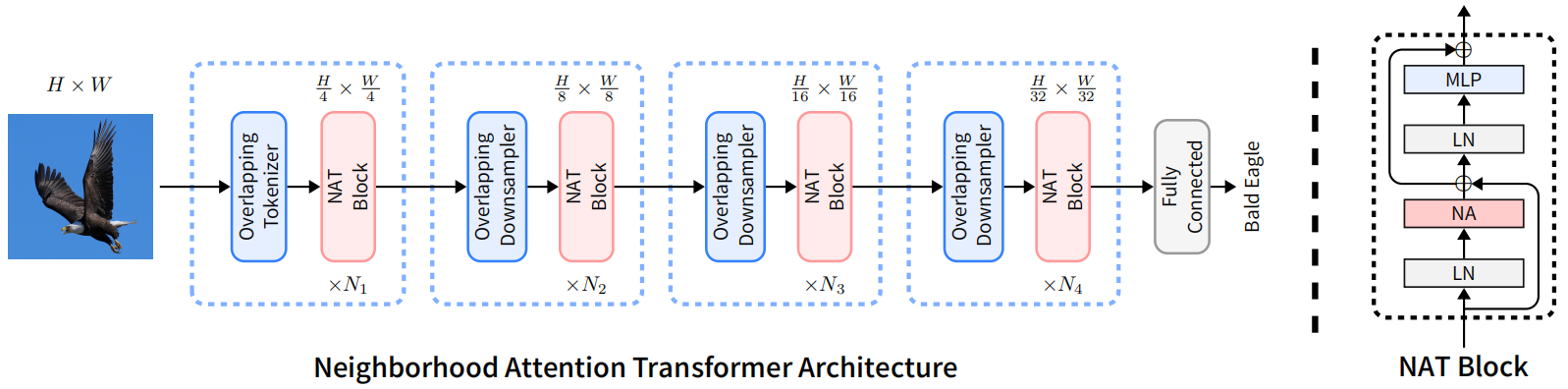
网络的整体架构和当前方法一样,都是4阶段。每个阶段分辨率降低一半。不过,降分辨率使用的是 步长为2的 3X3 卷积。第一步 overlapping tokenizer 使用的是2个3x3卷积,每个卷积的步长为2。
Neighborhood Attention Transformer概述的更多相关文章
- Attention & Transformer
Attention & Transformer seq2seq; attention; self-attention; transformer; 1 注意力机制在NLP上的发展 Seq2Seq ...
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- 深度学习之Attention Model(注意力模型)
1.Attention Model 概述 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观 ...
- [深度概念]·Attention Model(注意力模型)学习笔记
此文源自一个博客,笔者用黑体做了注释与解读,方便自己和大家深入理解Attention model,写的不对地方欢迎批评指正.. 1.Attention Model 概述 深度学习里的Attention ...
- 深入浅出Transformer
Transformer Transformer是NLP的颠覆者,它创造性地用非序列模型来处理序列化的数据,而且还获得了大成功.更重要的是,NLP真的可以"深度"学习了,各种基于tr ...
- [NLP] REFORMER: THE EFFICIENT TRANSFORMER
1.现状 (1) 模型层数加深 (2) 模型参数量变大 (3) 难以训练 (4) 难以fine-tune 2. 单层参数量和占用内存分析 层 参数设置 参数量与占用内存 1 layer 0.5Bill ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 关于NLP和深度学习,准备好好看看这个github,还有这篇介绍
这个github感觉很不错,把一些比较新的实现都尝试了: https://github.com/brightmart/text_classification fastText TextCNN Text ...
- BERT解析及文本分类应用
目录 前言 BERT模型概览 Seq2Seq Attention Transformer encoder部分 Decoder部分 BERT Embedding 预训练 文本分类试验 参考文献 前言 在 ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
随机推荐
- day05-功能实现04
家居网购项目实现04 以下皆为部分代码,详见 https://github.com/liyuelian/furniture_mall.git 10.功能09-后台管理 删除家居 10.1需求分析/图解 ...
- Dubbo架构设计与源码解析(三)责任链模式
作者:周可强 一.责任链模式简介 1.责任链模式定义 责任链(Chain of Responsibility)模式的定义:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者通过前一对 ...
- Java进阶篇——springboot2源码探究
1.@EnableAutoConfiguration 除了元注解之外,EnableAutoConfiguration包含了两大重要部分: 1)@AutoConfigurationPackage注解 该 ...
- [Leetcode]环形链表 II
题目 代码 /** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * Li ...
- AtCoder Beginner Contest 285 解题报告
AtCoder Beginner Contest 285 解题报告 \(\text{DaiRuiChen007}\) Contest Link A. Edge Checker 2 假设 \(a\ge ...
- [阿里云]Datahub测试使用记录
由于需要测试阿里云Datahub功能,因此测了一下Datahub的一些功能 DATAHUB: 简介: 阿里云的流式数据(streaming)处理平台 对流式数据的发布(publish)订阅(subsc ...
- C語言成績分析系統
C語言成績分析系統,可以實現七個功能.(使用的編譯器是 code::blocks) 主要實現對於學生信息的輸入 顯示輸入學生的信息 根據期末成績來進行排名. 查找某個學生的信息 刪除某個學生的信息 修 ...
- 複合語句塊——關於while循環的
看這兩個小段代碼: /*code1.*/ index=0; while(index<10) sam = 10*index+2; printf("sam=%d\n",sam); ...
- cordova完整版本创建、修改自定义插件重新调试步骤带截图
创建第三方插件 npx plugman create --name myplugin --plugin_id xiao.jin.plugin --plugin_version 1.0.0 添加平台支持 ...
- three.js一步一步来--如何画出一个逃跑的圆柱体
代码如下 <template> <div style="width:1000px; height:800px"> <p>逃跑的圆柱体</p ...