统计学习导论(ISLR)(三):线性回归(超详细介绍)
统计学习导论(ISLR)
参考资料:
The Elements of Statistical Learning
An Introduction to Statistical Learning
统计学习导论(ISLR)(二):统计学习概述
统计学习导论(ISLR)(三):线性回归
统计学习导论(ISLR)(四):分类
统计学习导论(ISLR)(五):重采样方法(交叉验证和boostrap)
ISLR统计学习导论之R语言应用(二):R语言基础
ISLR统计学习导论之R语言应用(三):线性回归R语言代码实战
ISLR统计学习导论之R语言应用(四):分类算法R语言代码实战
统计学习导论(ISLR) 第四章课后习题
文章目录
3 线性回归
线性回归是监督学习中非常简单的模型之一,特别在研究定量数据的问题中,它能分析变量之间的关系,并给出很好的解释。此外,它还是新方法的一个良好起点:许多有趣的统计学习方法可以被视为线性回归的推广或扩展。例如Lasso,岭回归,logistic regression
3.1 简单线性回归
简单线性回归就是一个一元线性回归,一个因变量和一个自变量,假设
X
X
X和
Y
Y
Y之间有线性回归,数学表现形式如下:
Y
≈
β
0
+
β
1
X
Y ≈ \beta_0+\beta_1X
Y≈β0+β1X
上式常常表述为Y对X的回归
在上式中,
β
0
\beta_0
β0和
β
1
\beta_1
β1是两个不知道的常数,分别表示截距和斜率,统称为模型的参数。一旦我们使用我们的训练数据集训练模型来估算模型系数
β
^
0
\hat\beta_0
β^0和
β
^
1
\hat\beta_1
β^1,我们就可以通过下式计算基于某一特定广告值的销售量:
y
^
=
β
^
0
+
β
^
1
x
\hat y = \hat \beta_0 + \hat \beta_1x
y^=β^0+β^1x
y
^
\hat y
y^表示当
X
=
x
X=x
X=x时,
Y
Y
Y的预测值,我们用^表示未知参数或系数的估计值,或表示
y
y
y的预测值
3.1.1参数估计
在实际中,
β
0
\beta_0
β0和
β
1
\beta_1
β1是两个未知的参数,我们需要通过训练数据进行估计,假设有n个观测数据
(
x
1
,
y
1
)
,
…
,
(
x
n
,
y
n
)
(x_1,y_1),…,(x_n,y_n)
(x1,y1),…,(xn,yn)
每一个观测数据都包含自变量
X
X
X和因变量
Y
Y
Y,我们的目的就是让估计的模型较好的拟合原始数据集,也就是说,要估计的线性模型尽可能的靠近每一个数据。最常用的方法就是最小二乘法(LS)。
假设
y
^
i
=
β
^
0
+
β
^
1
x
i
\hat y_i = \hat \beta_0 + \hat \beta_1x_i
y^i=β^0+β^1xi表示第
i
i
i个数据的预测值,
e
i
=
y
i
−
y
^
i
e_i = y_i-\hat y_i
ei=yi−y^i表示真实值与预测值的残差,如图3.1所示,红点到蓝色曲线的距离表示残差
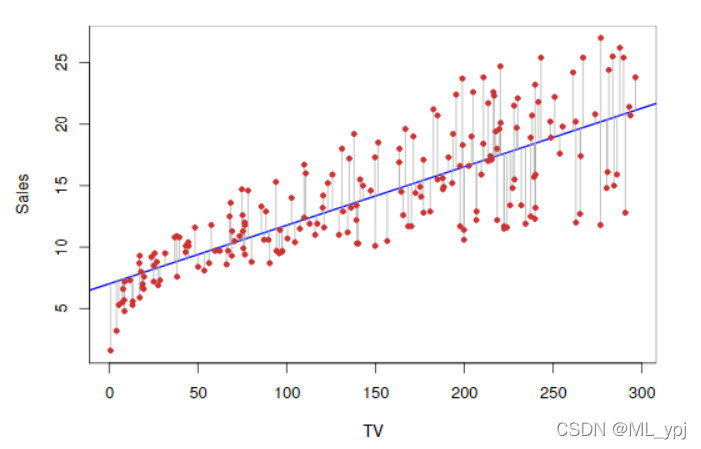
图3.1 广告数据集红点表示每个观测数据,蓝色的曲线是通过最小二乘法拟合得到的曲线。
根据拟合的曲线,我们定义残差平方和RSS为:
R
S
S
=
e
1
2
+
.
.
.
+
e
n
2
RSS = e_1^2+...+e_n^2
RSS=e12+...+en2
LS的基本思想就是通过最小化残差平方和估计参数:
β
^
1
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
β
^
0
=
y
ˉ
−
β
^
1
x
ˉ
\hat \beta_1 = \frac {\sum_{i=1}^n(x_i-\bar x)(y_i - \bar y)}{\sum_{i=1}^n(x_i-\bar x)^2} \\ \hat \beta_0 = \bar y -\hat \beta_1\bar x
β^1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)β^0=yˉ−β^1xˉ
图3.1就是通过最小二乘法得到的线性拟合曲线,
β
^
0
=
7.03
,
β
^
1
=
0.0475
\hat \beta_0=7.03, \hat \beta_1=0.0475
β^0=7.03,β^1=0.0475,

图3.2 RSS的等高线图和三维图以advertising数据集为案例,使用Sales作为Y,TV作为X。红色的点对应于给出的最小二乘估计值
β
^
0
\hat \beta_0
β^0和
β
^
1
\hat \beta_1
β^1可以看出不同的系数RSS不同,根据LS得到的参数使得RSS达到了最小
3.1.2评估参数的准确性
要评估参数的准确性,首先定义总体回归参数和样本回归参数。
假设
Y
Y
Y和
X
X
X之间的关系是线性的,我们可以写成:
Y
=
β
0
+
β
1
X
+
ϵ
Y = \beta_0 + \beta_1 X + \epsilon
Y=β0+β1X+ϵ
其中
β
0
\beta_0
β0表示截距,是当
X
=
0
X=0
X=0时
Y
Y
Y的值,
β
1
\beta_1
β1是斜率,表示
X
X
X每增加一个单位,
Y
Y
Y增加的值,
ϵ
\epsilon
ϵ是残差项,包含了所有缺失的信息,例如:模型可能不是线性的,有其他影响
Y
Y
Y的变量未包含等。我们假设残差项与X是相互独立的。
上述定义的是总体回归函数:表示被解释变量Y的平均状态(总体条件期望)随解释变量X变化的规律。
样本回归函数:
y
^
=
β
^
0
+
β
^
1
x
\hat y = \hat \beta_0 + \hat \beta_1x
y^=β^0+β^1x,表示根据实际抽样数据
y
y
y随着
x
x
x变化的规律
两者特点:
总体回归函数是唯一未知的,其参数是常数
样本回归函数是根据每一次抽样得到的,其参数是随机变量,会随着抽样数据变化而变化
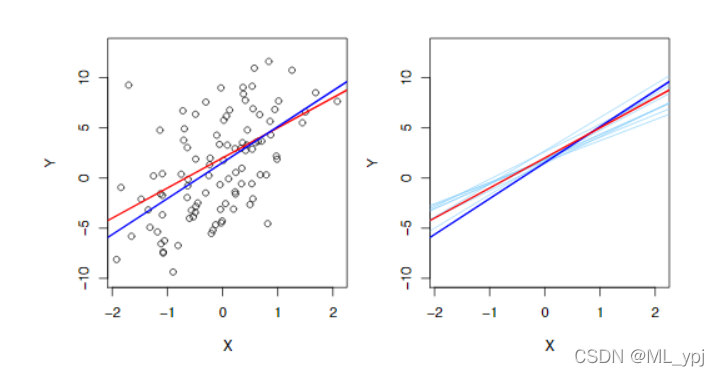
图 3.3 总体回归线和样本回归线。左图中,红色曲线表示总体回归线,蓝色曲线表示本次抽样得到的样本回归线;右图中显示了十条样本回归线和总体回归线。可以看出样本回归线在总体回归线附近震荡
从图3.3可以看出,随着数据集的不同,样本回归线也会发生相应变化,但总体回归线不变,这类似于统计学的中心极限定理,我们虽然不知道总体均值的分布,但是可以通过样本来推断总体。在回归中也一样,
β
0
和
β
1
\beta_0和\beta_1
β0和β1代表总体参数,
β
^
0
和
β
^
1
\hat \beta_0和\hat \beta_1
β^0和β^1代表样本参数,可以看做总体参数的估计量。
无偏估计:
首先,我们要判断
β
^
0
和
β
^
1
\hat \beta_0和\hat \beta_1
β^0和β^1是不是
β
0
和
β
1
\beta_0和\beta_1
β0和β1的无偏估计,从图3.3可以看出,当我们估计一次时样本回归参数不等于总体的回归参数,但当我们的数据集足够多,那么样本回归系数的平均值几乎等于总体回归系数
E
(
β
^
i
)
=
β
i
E(\hat \beta_i)=\beta_i
E(β^i)=βi
但是,单个估计可能会严重的高估会低估总体参数,因此,我们想知道估计参数的精确性如何,可以证明
S
E
(
β
^
0
)
2
=
σ
2
[
1
n
+
x
ˉ
2
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
]
S
E
(
β
^
1
)
2
=
σ
2
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
SE(\hat \beta_0)^2 = \sigma^2[\frac{1}{n}+\frac{\bar x^2}{\sum_{i=1}^{n}(x_i - \bar x)^2}] \\ SE(\hat \beta_1)^2 = \frac{\sigma^2}{\sum_{i=1}^{n}(x_i - \bar x)^2}
SE(β^0)2=σ2[n1+∑i=1n(xi−xˉ)2xˉ2]SE(β^1)2=∑i=1n(xi−xˉ)2σ2
其中
σ
2
=
v
a
r
(
ϵ
)
\sigma^2=var(\epsilon)
σ2=var(ϵ),为了使上述公式严格有效,我们需要假设每个观测值的误差
ϵ
\epsilon
ϵ 同方差且不相关。通过上述公式发现,当
x
i
x_i
xi越分散,
S
E
(
β
^
1
)
2
SE(\hat \beta_1)^2
SE(β^1)2越小,而且当
x
ˉ
\bar x
xˉ等于0时候,
S
E
(
β
^
0
)
2
SE(\hat \beta_0)^2
SE(β^0)2等于
S
E
(
y
)
2
SE(y)^2
SE(y)2。注意,
σ
2
\sigma^2
σ2往往是未知的,我们可以通过估计值近似,
σ
2
=
R
S
S
/
(
n
−
2
)
\sigma^2=RSS/(n-2)
σ2=RSS/(n−2),
R
S
E
=
R
S
S
/
(
n
−
2
)
RSE = \sqrt {RSS/(n-2)}
RSE=RSS/(n−2)
,根据上述分析可以得到估计参数的置信区间(置信水平=95%)
β
^
1
±
2
S
E
(
β
^
1
)
\hat \beta_1 \pm 2SE(\hat \beta_1)
β^1±2SE(β^1)
β
^
0
±
2
S
E
(
β
^
0
)
\hat \beta_0 \pm 2SE(\hat \beta_0)
β^0±2SE(β^0)
**注意:**置信区间不是随机变量,它表示的是估计100次参数,落在区间内的次数为95次
假设检验:当我们知道参数的标准差后,可以进一步进行假设检验
H
0
:
β
1
=
0
H
1
:
β
1
≠
0
H_0:\beta_1=0 \\H_1:\beta_1 \neq 0
H0:β1=0H1:β1=0
如果原假设成立,则说明X和Y之间没有关系,回归模型无效。为了检验
β
1
\beta_1
β1是否为0,我们引入t统计量
t
=
β
^
1
−
0
S
E
(
β
^
1
)
t = \frac{\hat \beta_1 - 0}{SE(\hat \beta_1)}
t=SE(β^1)β^1−0
t
t
t满足自由度为(n-2)的t分布,根据给定的显著性水平(通常取0.05)来判断是否拒绝原假设,如果
p
p
p>0.05,接受原假设;
p
<
0.05
p<0.05
p<0.05,拒绝原假设
表3.1
参数估计结果
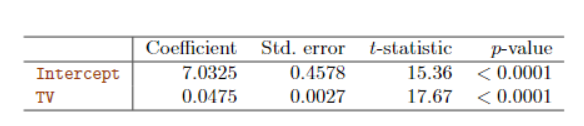
从表3.1可以看出两个回归系数的
p
p
p值均小于0.05,因此拒绝原假设,说明X和Y之间存在线性关系。
3.1.3 评估模型的准确性
评估模型的拟合好坏主要看两个统计量:RSE和
R
2
R^2
R2统计量
剩余标准误
根据回归形式,每一个观测值都有一个残差项
ϵ
\epsilon
ϵ,因此,即便是我们知道真实的
β
0
\beta_0
β0和
β
1
\beta_1
β1,依然无法完全准确的通过X预测Y。RSE是
s
d
(
ϵ
)
sd(\epsilon)
sd(ϵ)的估计值:
R
S
E
=
1
n
−
2
R
S
S
=
1
n
−
2
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
RSE = \sqrt {\frac{1}{n-2}RSS}=\sqrt{\frac{1}{n-2}\sum_{i=1}^n(y_i-\hat y_i)^2}
RSE=n−21RSS
=n−21i=1∑n(yi−y^i)2
表3.2 模型评估参数

RSE主要判断模型是否欠拟合,如果模型拟合的非常好,那么RSE会非常小,相反,如果RSE非常大,那么说明模型可能拟合的不好,可能存在欠拟合现象
R
2
R^2
R2统计量
虽然RSE是评估模型是否缺乏拟合的一个统计量,但是因为它会受到
Y
Y
Y自身大小的影响,因此不总是那么明确。而
R
2
R^2
R2是一个比例形式,方差解释的比例:
R
2
=
T
S
S
−
R
S
S
T
S
S
=
1
−
R
S
S
T
S
S
=
E
S
S
T
S
S
R^2 = \frac {TSS-RSS}{TSS}=1-\frac{RSS}{TSS}=\frac{ESS}{TSS}
R2=TSSTSS−RSS=1−TSSRSS=TSSESS
T
S
S
=
∑
(
y
i
−
y
ˉ
)
2
TSS=\sum(y_i-\bar y)^2
TSS=∑(yi−yˉ)2是总体平方和
E
S
S
=
∑
(
y
^
i
−
y
ˉ
)
ESS = \sum(\hat y_i-\bar y)
ESS=∑(y^i−yˉ)的解释平方和(回归平方和)
与RSE相比
R
2
R^2
R2更具有解释性,因为其总在0到1。但是如何评估
R
2
R^2
R2的好坏是一个比较困难的工作,在一些物理问题中,可能本身就存在一个线性关系,残差项很小,此时我们希望得到一个较大的
R
2
R^2
R2,相反,在一些社会科学领域,由于影响因素较多,用线性模型很难拟合的很好,此时一个较小的
R
2
R^2
R2更真实。
3.2多元回归
多元回归是一元回归的拓展,一个因变量对应着多个自变量,多元线性回归模型数学形式如下:
Y
=
β
0
+
β
1
X
1
+
β
2
X
2
+
.
.
.
+
β
p
X
p
+
ϵ
Y = \beta_0 + \beta_1 X_1 + \beta_2X_2+...+\beta_pX_p + \epsilon
Y=β0+β1X1+β2X2+...+βpXp+ϵ
X
j
X_j
Xj表示第
j
j
j个解释变量,
β
j
\beta_j
βj表示第
j
j
j个回归系数
表3.3 销售量对广播和报纸的一元回归结果

3.2.1参数估计
与一元回归同理,这些回归系数是未知的,需要通过训练集进行估计。对于估计得到的回归系数,可以用下列式子做预测
y
^
=
β
^
0
+
β
^
1
x
1
+
.
.
.
+
β
^
p
x
p
\hat y = \hat \beta_0 + \hat \beta_1x_1+...+\hat \beta_px_p
y^=β^0+β^1x1+...+β^pxp
参数估计方法仍然使用最小二乘法,选择让RSS最小的参数,多元回归最好使用矩阵表示,如今很多软件都能轻松实现,本文以R语言为例后续给出相应方法。
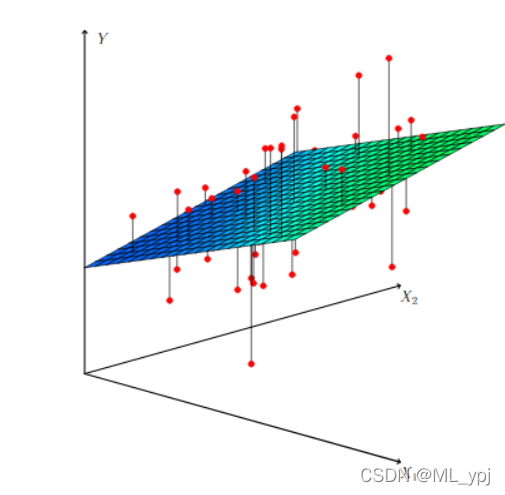
图3.4 二元回归平面图
表 3.4显示了电视、广播和报纸用于广告预算数据预测产品销售时的多元回归系数估计。
表3.4 回归系数结果图
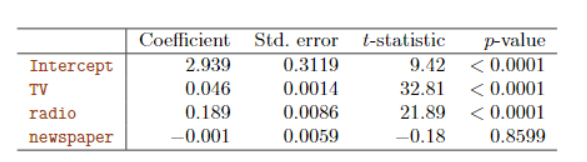
从表3.4可以看出,电视、广播和销售量之间具有显著的影响,报纸和销售量之间没有显著的影响。
表3.5 变量之间相关系数矩阵

从表3.5可以看出报纸和广播之间具有相关性,因此导致了即使报纸与销售量之间没有关系,但是在一元线性回归中,由于报纸和广播之间的关系导致了其与销售量之间也存在相关性。这种现象在现实生活中很常见。
例如,对给定海滩区域在一段时间内收集的数据进行鲨鱼袭击次数与冰淇淋销售量的回归分析,结果显示出一种积极的关系,类似于报纸和销售量之间的关系。当然没有人通吃禁止在海滩上吃冰淇淋,以减少鲨鱼的袭击。这是因为温度高导致人们去海滩,这反过来导致更多的冰淇淋销售和更多的鲨鱼袭击。对鲨鱼袭击次数和冰激凌销售、温度进行多元回归分析,正如直觉那样,冰激凌销售在增加温度后不再是一个显著的预测因素
3.2.2 一些重要的问题
1.是否至少有一个预测变量
X
1
,
.
.
.
,
X
p
X_1,...,X_p
X1,...,Xp与
Y
Y
Y具有显著的关系?
2.是否所有的预测变量都能解释
Y
Y
Y,还是只有一部分预测变量有用?
3.模型拟合的效果怎么样?
4.给定一组解释变量的值,被解释变量会是多少,预测的准确性有多高?
问题1:响应和预测变量之间有关系吗?
回想一元回归情景,为了判断解释变量与被解释变量是否具有关系时,我们对
β
1
=
0
\beta_1=0
β1=0进行了假设检验。同理,在多元回归中,有
p
p
p个解释变量,因此我们需要判断是否所有的解释变量的回归系数同时为0
原假设:
H
0
:
β
1
=
β
2
=
.
.
.
=
β
p
=
0
H_0:\beta_1=\beta_2=...=\beta_p=0
H0:β1=β2=...=βp=0
被择假设:
H
1
:
至
少
有
一
个
β
j
≠
0
H_1:至少有一个\beta_j\neq0
H1:至少有一个βj=0
检验统计量为
F
F
F统计量:
F
=
(
T
S
S
−
R
S
S
)
/
p
R
S
S
/
(
n
−
p
−
1
)
F = \frac{(TSS-RSS)/p}{RSS/(n-p-1)}
F=RSS/(n−p−1)(TSS−RSS)/p
表 3.6 F检验结果

表3.6是多元回归F检验的结果
和简单线性回归一样
T
S
S
=
∑
(
y
i
−
y
ˉ
)
2
TSS = \sum(y_i-\bar y)^2
TSS=∑(yi−yˉ)2,
R
S
S
=
∑
(
y
i
−
y
^
i
)
2
RSS=\sum(y_i-\hat y_i)^2
RSS=∑(yi−y^i)2,如果线性回归假设正确,则有
E
[
R
S
S
/
(
n
−
p
−
1
)
]
=
σ
2
E[RSS/(n-p-1)]=\sigma^2
E[RSS/(n−p−1)]=σ2
并且,如果原假设成立,则有
E
[
(
T
S
S
−
R
S
S
)
/
p
]
=
σ
2
E[(TSS-RSS)/p]=\sigma^2
E[(TSS−RSS)/p]=σ2
因此,如果解释变量与被解释变量没有关系,则
F
F
F统计量接近为0,相反,如果被择假设正确,则
E
[
(
T
S
S
−
R
S
S
)
/
p
]
E[(TSS-RSS)/p]
E[(TSS−RSS)/p]远远大于
σ
2
\sigma^2
σ2,从而
F
F
F统计量远远大于1
如表3.6所示,
F
F
F统计量为570,远远大于1,拒绝原假设,认为至少有一种广告方式与销售额有关系。在实际应用中,我们常常用
p
p
p值进行判断。
以上是对所有回归系数是否同时为0进行判断,有时我们想要判断是否其中一部分回归系数为0。
原假设设为:
H
0
:
β
p
−
q
+
1
=
β
p
−
q
+
2
=
.
.
.
=
β
p
=
0
H_0:\beta_{p-q+1}=\beta_{p-q+2}=...=\beta_p=0
H0:βp−q+1=βp−q+2=...=βp=0
为了方便表达,选取变量的最后几个作为判断是否存在冗余变量。假设该模型的残差平方和为
R
S
S
0
RSS_0
RSS0
则
F
F
F统计量为:
F
=
(
R
S
S
0
−
R
S
S
)
/
q
(
R
S
S
)
/
(
n
−
p
−
1
)
F = \frac{(RSS_0-RSS)/q}{(RSS)/(n-p-1)}
F=(RSS)/(n−p−1)(RSS0−RSS)/q
注意:根据表3.4,我们可以得到每个变量单独的P值,可以看出有两个变量的
p
p
p值远小于0.05,那为什么我们还需要做F检验呢?毕竟,任何一个变量通过了t检验,那么至少有一个预测因子与响应相关。然而,这种逻辑是有缺陷的,特别是当预测变量的数量很大时,会出现F检验不显著而t检验显著的情况。
例如:假设
p
=
100
p=100
p=100,
H
0
:
β
1
=
β
2
=
.
.
.
=
β
p
=
0
H_0:\beta_1=\beta_2=...=\beta_p=0
H0:β1=β2=...=βp=0成立,没有解释变量与被解释变量相关,但是存在5%的变量因为偶然因素与
Y
Y
Y的一元回归中通过了t检验,换句话说,即使预测变量和响应之间没有任何真正的关联,我们也可能看到大约五个变量通过了t检验
因此,在多元回归中,即便单个变量通过了t检验,也不代表模型是显著的,首先做F检验,再看t检验。
拓展:当
p
>
n
p>n
p>n的情况下,不能使用最小二乘法进行估计,此时F检验也不能用,我们需要进行变量删选。例如逐步回归,或者一些其他处理高纬数据的方法,这在之后会进行讨论
第二:选择重要变量
有时候一个多元回归模型有很多因变量,但不是所有变量都对
Y
Y
Y有显著影响,因此需要对变量进行删选。有许多方法可以进行变量删选。这里首先介绍一个较为典型的方法
我们希望通过尝试许多不同的模型来进行变量选择,每个模型都包含不同的预测变量。例如,假设有两个自变量,可以考虑四个模型
(1)
Y
=
β
0
+
ϵ
Y=\beta_0+\epsilon
Y=β0+ϵ
(2)
Y
=
β
0
+
β
1
X
1
+
ϵ
Y=\beta_0+\beta_1X_1+\epsilon
Y=β0+β1X1+ϵ
(3)
Y
=
β
0
+
β
2
X
2
+
ϵ
Y=\beta_0+\beta_2X_2+\epsilon
Y=β0+β2X2+ϵ
(4)
Y
=
β
0
+
β
1
X
1
+
β
2
X
2
+
ϵ
Y=\beta_0+\beta_1X_1+\beta_2X_2+\epsilon
Y=β0+β1X1+β2X2+ϵ
然后,我们可以从我们考虑的所有模型中选择最好的模型。可以使用各种统计量判断模型的质量。例如**
M
a
l
l
o
w
′
s
C
p
Mallow's C_p
Mallow′sCp、
A
I
C
AIC
AIC信息准则、
B
I
C
BIC
BIC信息准则和调整后的**
R
2
R^2
R2。
但是,往往我们不能列举所有的模型来进行比较,可以发现
p
p
p个变量有
2
p
2^p
2p个模型,如果
p
=
10
p=10
p=10就有
2
10
=
1024
2^{10}=1024
210=1024个模型,这时考虑所有的模型是不切实际的。当
p
p
p较大时候,不采用上述方法,而是用以下三种方法:
- 向前选择 我们从一个零模型开始,零模型是一个截距但没有预测变量的模型。然后,我们拟合简单的线性回归,并向空模型中添加RSS最低的变量。然后,我们向该模型中添加一个变量,该变量是让新的两变量模型的最低RSS。不断迭代该方法
- 向后选择 我们从包含所有变量的模型开始,然后删除p值最大的变量,即统计意义最小的变量。不断重复上述方法,当所有剩余变量的p值低于某个阈值时,停止删选
- 混合选择 将上述两种方法结合。
如果P>n,则不能使用反向选择,而可以使用正向选择方法。前向选择是一种贪婪的方法,可能会在早期包含冗余的变量,然后这些变量就会变得多余。混合选择可以解决这个问题。
3.模型拟合效果
与简单线性回归一样,评估模型拟合效果的指标主要是RSE和
R
2
R^2
R2,不过注意,由于预测变量越多,则模型在训练集上的拟合效果就越好,
R
2
R^2
R2越大,此时我们需要对
R
2
R^2
R2进行调整:
R
ˉ
2
=
1
−
(
1
−
R
2
)
n
−
1
n
−
p
\bar R^2 = 1-(1-R^2)\frac {n-1}{n-p}
Rˉ2=1−(1−R2)n−pn−1
多元回归中我们使用调整后
R
2
R^2
R2来衡量模型的拟合效果
同时也可以根据图形来直观的看模型拟合的好坏,如图3.5

图 3.5 多元回归结果图
3.3其他回归模型
3.3.1 定性解释变量
在到目前为止的讨论中,我们假设线性回归模型中的所有变量都是定量的。但在实践中,情况并非如此;通常一些预测是定性的
只有两个水平的定性预测因子
假设我们希望调查拥有房子和没有房子的人之间信用卡余额的差异,暂时忽略其他变量。如果一个定性预测变量有两个水平,或可能的值,那么将其放入回归模型是非常简单的。我们只需创建一个指示符或哑变量(虚拟变量),它接受两个可能的数值,1,0例如,基于own变量,我们可以创建一个新变量,其形式为
x
i
=
{
1
if ith person owns a house
0
if ith person does not owns a house
x_i = \begin{cases} 1& \text{ if ith person owns a house}\\ 0& \text{ if ith person does not owns a house} \end{cases}
xi={10 if ith person owns a house if ith person does not owns a house
并将此变量用作回归方程中的预测值。这就是模型的结果
y
i
=
β
0
+
β
1
x
i
+
ϵ
i
=
{
β
0
+
β
1
+
ϵ
i
if ith person owns a house
β
0
+
ϵ
i
if ith per son does not
y_i = \beta_0 + \beta_1x_i+\epsilon_i = \begin{cases} \beta_0+\beta_1+\epsilon_i \quad\text{if ith person owns a house}\\ \beta_0+\epsilon_i \quad\quad\quad\text{ if ith per son does not} \end{cases}
yi=β0+β1xi+ϵi={β0+β1+ϵiif ith person owns a houseβ0+ϵi if ith per son does not
现在
β
0
\beta_0
β0 可以解释为那些不拥有自己房子的人的平均信用卡余额,
β
0
+
β
1
\beta_0+\beta_1
β0+β1是那些拥有自己房子的人的平均信用卡余额,
β
1
\beta_1
β1 是拥有者和非拥有者之间信用卡余额的平均差异。

图3.6信用数据集包含许多潜在客户的余额、年龄、卡、教育、收入、限额和评级等信息
表3.7显示了与上述模型相关的系数估计和其他信息。非所有者的平均信用卡债务估计为509.80美元,而所有者的额外债务估计为19.73美元,总额为509.80美元+19.73美元=529.53美元。但是,我们注意到虚拟变量的P值非常高。这表明没有统计证据表明基于房屋所有权的平均信用卡余额存在差异。
表3.7 与预测数据集中的平衡回归相关的最小二乘系数估计。

两个以上水平的定性预测因子
当定性预测值有两个以上的水平时,单个虚拟变量不能代表所有可能的值。在这种情况下,我们可以创建额外的虚拟变量。例如,对于区域变量,我们创建了两个虚拟变量。
x
i
1
=
{
1
if ith person is from south
0
if ith person is not from south
x_{i1} = \begin{cases} 1\quad\text{if ith person is from south}\\ 0\quad\text{if ith person is not from south} \end{cases}
xi1={1if ith person is from south0if ith person is not from south
x
i
2
=
{
1
if ith person is from west
0
if ith person is not from west
x_{i2} = \begin{cases}1\quad\text{if ith person is from west}\\0\quad\text{if ith person is not from west} \end{cases}
xi2={1if ith person is from west0if ith person is not from west
表3.8。
与预测数据集中区域平衡回归相关的最小二乘系数估计。

在结合定量和定性预测变量时,使用虚拟变量方法并不困难。例如,为了在定量变量(如incomean)和定性变量(如student)上实现平衡,我们必须简单地为student创建一个虚拟变量,然后使用incomean和虚拟变量变量作为信用卡余额的预测因子拟合多元回归模型。R语言在回归中会自动生成虚拟变量
3.3.2线性模型的扩展
标准线性回归模型提供了可解释的结果,并在许多实际问题上运行良好。然而,它做出了一些在实践中经常被违反的高度限制性假设。两个最重要的假设表明,预测因素和响应之间的关系是累加和线性的。可加性假设AdditiveLinear意味着预测器X和响应之间的关联不依赖于其他预测器的值。线性假设表明,响应的变化与一个单位的变化相关联xjis常数,与xj的值无关。在本书的后面几章中,我们将研究一些可以放松这两个假设的复杂方法。这里,我们简要地研究了一些扩展线性模型的常用经典方法。
非线性关系
如前所述,线性回归模型假设响应和预测值之间存在线性关系。但在某些情况下,反应和预测因子之间的真实关系可能是非线性的。在这里,我们提供了一种非常简单的方法,使用多项式回归直接扩展线性模型以适应非线性关系。在多项式回归后面的章节中,我们将介绍在更一般的环境中进行非线性拟合的更复杂的方法。以Auto数据集为例,二项式回归模型如下。图3.7给出了不同阶数多项式的拟合效果。
m
p
g
=
β
0
+
β
1
×
h
o
r
s
e
p
o
w
e
r
+
β
2
×
h
o
r
s
e
p
o
w
e
r
2
+
ϵ
mpg = \beta_0+\beta_1\times horsepower + \beta_2\times horsepower^2 + \epsilon
mpg=β0+β1×horsepower+β2×horsepower2+ϵ

图3.7 多项式回归
3.3.3潜在问题
当我们将线性回归模型拟合到特定的数据集时,可能会出现许多问题。其中最常见的是:
- 1.响应预测关系的非线性。
- 2.自相关
- 3.异方差
- 4.离群值
- 5.高杠杆点
- 6.多重共线性
在实践中,识别和克服这些问题既是一门艺术,也是一门科学。无数的书中有很多页都是关于这个话题的。由于线性回归模型不是我们在这里的主要关注点,大家可以参考计量经济学相关内容。
3.4线性回归与K近邻的比较
如第2章所讨论的,线性回归是一种参数估计方法,因为它假定f(X)为线性函数形式。参数化方法有几个优点。它们通常很容易拟合,因为只需要估计一小部分系数。在线性回归的情况下,系数有简单的解释,并且可以很容易地进行统计显著性检验。但参数化方法有一个缺点:通过构造,它们f(X)的形式做出了强有力的假设。如果指定的函数形式与事实相差较大,并且预测精度是我们的目标,那么参数化方法效果非常差。例如,如果我们假设两个变量之间存在线性关系,但真正的关系远不是线性的,那么最终的模型将与数据不匹配,由此得出的任何结论都将收到影响。
KNN
非参数方法没有明确地假定f(X)的准度量形式,因此为执行回归提供了另一种更灵活的方法。我们将讨论各种非参数方法。在这里,我们考虑一个最简单的非参数方法,K-近邻回归,回归方法与KNN分类器密切相关。
KNN分类时,首先确定k值,然后找到k个与输入实例x最近的实例,这k个实例的多数属于某个类,就把该输入实例分为该类。而KNN回归时,首先得到他给定一个k值和一个预测点
x
0
x_0
x0,KNN回归首先确定最接近
x
0
x_0
x0 的k个训练集,用
N
0
\N_0
N0表示。然后使用所有训练集的响应的平均值来估计
f
(
x
)
f(x)
f(x)。具体公式如下:
f
^
(
x
0
)
=
1
K
∑
x
i
∈
N
0
y
i
\hat f(x_0) = \frac{1}{K}\sum_{x_i \in \N_0}y_i
f^(x0)=K1xi∈N0∑yi

图3.8。在64个观测值(橙色点)的二维数据集上使用KNN回归绘制f(X)。左:K=1结果为阶跃函数拟合。右图:K=9更平滑
如何选择K值
一般来说,k的最优值取决于偏差-方差权衡,这是我们在第2章中介绍的。K越小偏差小但方差大。这种差异是由于一个给定区域的预测完全依赖于一个观测。相比之下,k值越大,拟合越平滑,方差越少;一个区域的预测是几个点的平均值,因此改变一个观测值的影响较小。后续我们会给出更多的方法选择K值
3.4.1线性关系下两者之间的权衡
在什么情况下,参数化方法(如最小二乘线性回归)会优于非参数方法(如KNN回归)?答案很简单:如果选择的参数化形式接近真实形式,那么参数化方法将优于非参数化方法。图3.9提供了一个一维线性回归模型生成的数据示例。黑色实线代表f(X),而蓝色曲线对应于K=1和K=9的KNN拟合。在这种情况下,K=1的预测变量太大,而k=9的拟合更接近于f(X)。然而,由于x和y之间的真实关系是线性的,因此非参数方法效果比线性回归要差:非参数方法会产生方差成本,而方差成本不会被偏差的减少所抵消。图3.10左侧面板中的蓝色虚线表示线性回归拟合,几乎完全拟合。图3.10的右侧面板显示,对于这些数据,线性回归优于KNN,黑色曲线表示线性回归的MSE,绿色曲线代表KNN的MSE。可以看出K越小,MSE越大,拟合效果越差。

图3.9 KNN拟合结果图,其中黑色曲线是数据的真实值。左:蓝色曲线对应K=1。右图:蓝色曲线对应K=9,表示更平滑的拟合
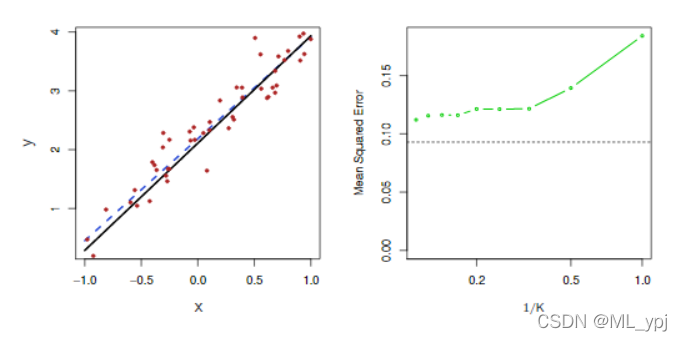
图3.10。对图3.9所示的相同数据集进行了进一步研究。左:蓝色虚线是数据的最小二乘拟合。由于f(X)实际上是线性的(显示为黑线),最小二乘回归线提供了对f(x)的很好估计。右:水平虚线代表线性回归的测试集MSE,而绿色实线对应于KNN的MSE,作为1/K的函数(在对数刻度上)。与KNN回归相比,线性回归实现了更低的测试MSE,因为f(x)实际上是线性的。对于KNN回归,最佳结果出现在K值非常大的情况下,对应于1/K的最小值。
3.4.2非线性情况下两者关系的权衡
在实践中,x和y之间的关系很少是完全线性相关的,图3.11检验了在X和Y之间的关系中,随着非线性程度的增加,最小二乘回归和KNN的相对性能。在上面一行,x和y真正的关系接近线性的。在这种情况下,我们看到线性回归的测试MSE仍然优于低K值的KNN。然而,当k≥4(
1
K
≤
0.25
\frac{1}{K}\leq0.25
K1≤0.25)、KNN的线性回归性能优于线性回归。第二行x和y的数据几乎不是线性的。在这种情况下,对于K的所有值,KNN都大大优于线性回归。注意,随着非线性程度的增加,非参数KNN方法的测试集MSE几乎没有变化,但线性回归的测试集MSE有很大增加。
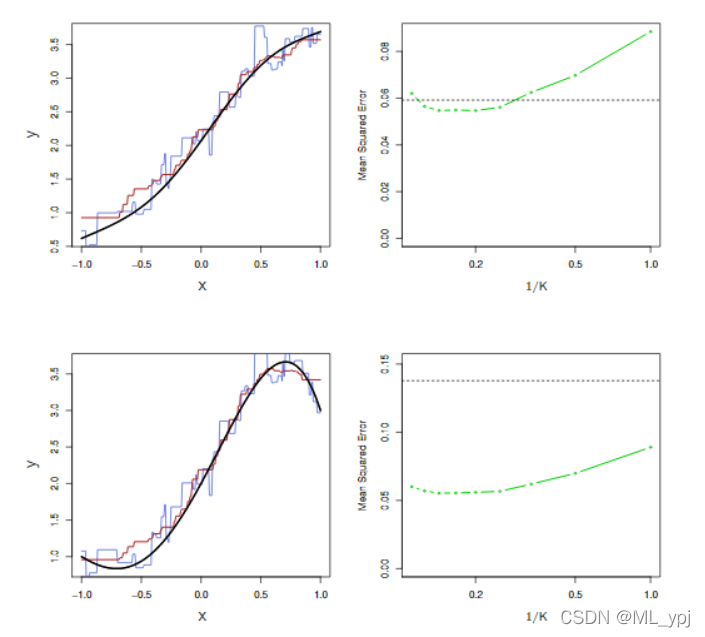
图11 左上角:在X和Y(黑色实线)之间有轻微非线性关系的设置中,显示K=1(蓝色)和K=9(红色)的KNN拟合。右上:对于轻微非线性的数据,最小二乘回归(水平黑色)的测试集MSE和1/K各种值(绿色)的KNN。左下角和右下角:与顶部面板相同,但两者之间存在强烈的非线性关系
3.4.3多元线性回归和KNN的权衡
图3.12考虑了与图3.11第二行相同的强非线性情况,但我们添加了与响应无关的额外噪声预测器。当P=1或P=2时,KNN优于线性回归。但是对于p=3,结果是混合的,而对于p≥4线性回归优于KNN。事实上,纬度的增加只导致线性回归测试集MSE的轻微变化,而导致KNN测试集MSE变化很大。对于KNN来说,随着维数的增加,性能下降是一个常见的问题,这是因为在更高的维数中,有效地减少了样本量。在这个数据集中有50个训练观察;当p=1时,这提供了足够的信息来准确估计f(X)。然而,将50个观测值分散到20维以上,可能会导致一个给定的观察数据没有任何邻近点。这时会导致维数灾难。也就是说,当p较大时,距离给定测试观测值最近的训练观测值在p维空间会距离非常远。导致非常差的预测值f(x0),因此KNN拟合较差。一般来说,当每个预测器有少量观测值时,参数方法往往优于非参数方法。即使维度很小,从可解释性的角度来看,我们可能更喜欢线性回归。如果KNN的测试均方误差仅略低于线性回归的测试均方误差,我们可能愿意为一个简单的模型而放弃一点预测精度,该模型可以仅用几个系数来描述,并且P值是可用的。

图3.12。不同纬度p下,线性回归(黑色虚线)和KNN(绿色曲线)的MSE。y和x真正的关系是第一个变量中是非线性的,如图3.11中的左下图所示,不依赖于其他变量。当存在这些额外的噪声变量时,线性回归的性能下降得很慢,而KNN的性能下降得更快。
统计学习导论(ISLR)(三):线性回归(超详细介绍)的更多相关文章
- 统计学习导论:基于R应用——第二章习题
目前在看统计学习导论:基于R应用,觉得这本书非常适合入门,打算把课后习题全部做一遍,记录在此博客中. 第二章习题 1. (a) 当样本量n非常大,预测变量数p很小时,这样容易欠拟合,所以一个光滑度更高 ...
- 统计学习导论:基于R应用——第三章习题
第三章习题 部分证明题未给出答案 1. 表3.4中,零假设是指三种形式的广告对TV的销量没什么影响.而电视广告和收音机广告的P值小说明,原假设是错的,也就是电视广告和收音机广告均对TV的销量有影响:报 ...
- 统计学习导论:基于R应用——第五章习题
第五章习题 1. 我们主要用到下面三个公式: 根据上述公式,我们将式子化简为 对求导即可得到得到公式5-6. 2. (a) 1 - 1/n (b) 自助法是有有放回的,所以第二个的概率还是1 - 1/ ...
- 统计学习导论:基于R应用——第四章习题
第四章习题,部分题目未给出答案 1. 这个题比较简单,有高中生推导水平的应该不难. 2~3证明题,略 4. (a) 这个问题问我略困惑,答案怎么直接写出来了,难道不是10%么 (b) 这个答案是(0. ...
- 【转】HBase 超详细介绍
---恢复内容开始--- http://blog.csdn.net/frankiewang008/article/details/41965543 1-HBase的安装 HBase是什么? HBase ...
- HBase 超详细介绍
1-HBase的安装 HBase是什么? HBase是Apache Hadoop中的一个子项目,Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到 ...
- Python 并行分布式框架:Celery 超详细介绍
本博客摘自:http://blog.csdn.net/liuxiaochen123/article/details/47981111 先来一张图,这是在网上最多的一张Celery的图了,确实描述的非常 ...
- 1:C#的三种异步的详细介绍及实现
一.介绍异步的前世今生: 异步编程模型 (APM,Asynchronous Programming Model) 模式(也称 IAsyncResult 模式),在此模式中异步操作需要 Begin 和 ...
- [原创]java WEB学习笔记100:Spring学习---Spring Bean配置:SpEL详细介绍及代码演示
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- C# 写入XML文档三种方法详细介绍
三个类将同样的xml内容写入文档,介绍了如何使用XmlDocument类对XML进行操作,以及如何使用LINQ to XML对XML进行操作. 它们分别使用了XmlDocument类和XDocum ...
随机推荐
- python之利用logging模块封装python日志类
利用python自带的logging模块封装一个日志类,便于单元测试时调用该模块打印日志 说明: 日志,即记录程序在运行过程中的操作记录和出现的问题 日志调试信息分类等级,由低到高分别为:DEBUG ...
- CSS控制背景图片100%自适应填充布局
原文地址:http://blog.csdn.net/wd4java/article/details/50537562 .personal_head { width: 100%; height: 35% ...
- 【个人笔记】CentOS 安装 Docker CE
要在 CentOS 上开始使用 Docker CE,请确保 满足先决条件,然后 安装Docker. 1. 卸载旧版本 sudo yum remove docker docker-client dock ...
- 对前三次PTA作业的总结
一.前言 通过对前三次PTA作业的总结,其中蕴含着不少知识点.它让真正开始接触Java的我一点一点的渗入其中.其包含的知识点有Java代码的大体结构,例如: public class Main{ pu ...
- kuangbin学习
是有针对性的对于算法的训练 我试试QAQ
- 【ubuntu20】解压文件
第一类处理 *** .zip或 ***.rar 时,需要先下载相对应的unzip和unrar,可在终端,执行 sudo apt-get install unzipsudo apt-get instal ...
- CCF-CSP准备
dfs序,unique vector sort(que+1,que+1+cnt); len = unique(que+1,que+cnt+1)-que-1; for(int i = 1;i <= ...
- java中indexOf()获取指定次数的下标
indexOf() :指定字符在此实例中的第一个匹配项的索引.搜索从指定字符位置开始,并检查指定数量的字符位置 Java中提供了四中查找方法: int indexOf(String str) 返回第一 ...
- 普罗米修斯-docker安装
1.只有一台服务器,所以使用docker来进行试验 #安装dockercurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyu ...
- VsCode——修改左侧目录缩进
https://code84.com/741691.html https://blog.csdn.net/qq812457115/article/details/124445657