深度学习基础-基于Numpy的多层前馈神经网络(FFN)的构建和反向传播训练
本文是深度学习入门: 基于Python的实现、神经网络与深度学习(NNDL)以及花书的读书笔记。本文将以多分类任务为例,介绍多层的前馈神经网络(Feed Forward Networks,FFN)加上Softmax层和交叉熵CE(Cross Entropy)损失的前向传播和反向传播过程(重点)。本文较长。
一、概述
1.1 多层前馈神经网络
 多层的前馈神经网络又名多层感知机(Multi-Layer Perceptrons, MLP)。MLP只是经验叫法,但实际上FFN不等价于MLP,因为原始的MLP通常使用不可微的阶跃函数,而不是连续的非线性函数。
多层的前馈神经网络又名多层感知机(Multi-Layer Perceptrons, MLP)。MLP只是经验叫法,但实际上FFN不等价于MLP,因为原始的MLP通常使用不可微的阶跃函数,而不是连续的非线性函数。
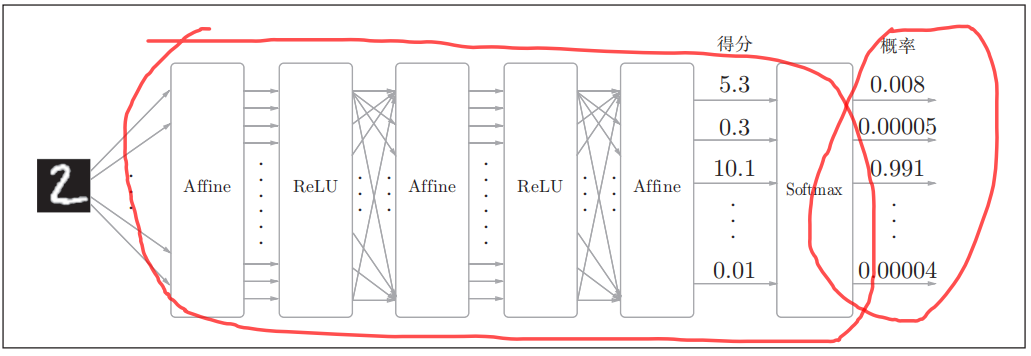
Figure 1 展示了单层的FFN。当多层的FFN堆叠起来,它就有了深度神经网络的万能近似能力。实际上,两层的FFN或MLP就具备强大的拟合能力。在数据足够多的时候,足够宽的(神经元足够多的)两层网络可以逼近任意连续函数。直观理解,两层的FFN有点类似于一个分段非线性函数, 或者是非线性函数的非线性组合,因而任何连续函数都可以被它表示(值得注意的是,能够表示不一定意味着可以学到这个函数。而且不一定是最优的)。
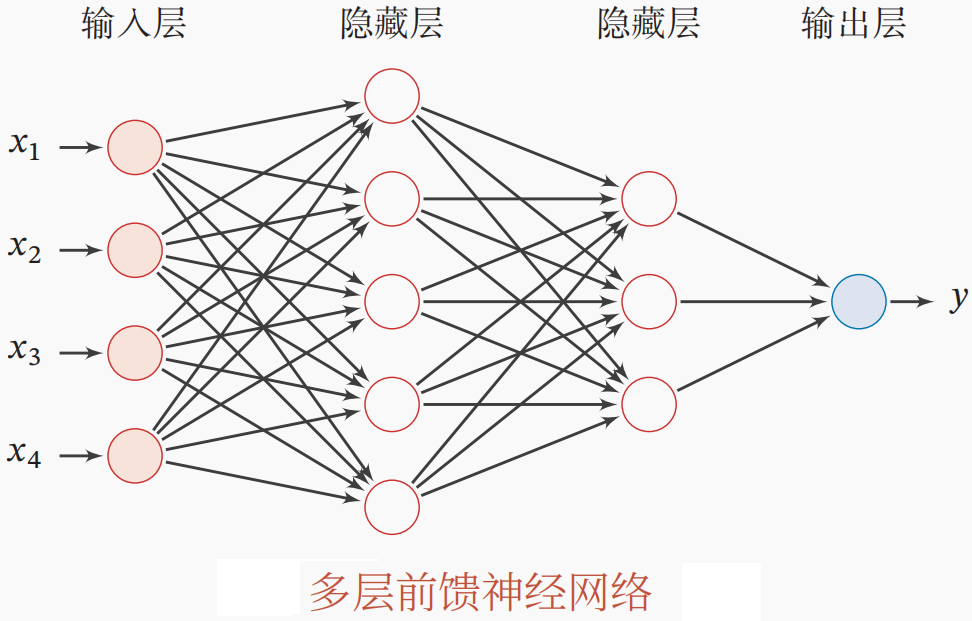
多层的前馈神经网络FFN的结构如上图所示。常用的FFN一般由2层或3层网络构成(不包括输入层)。

此外,单层网络的符号定义和公式如下图所示。一般FFN将采用Relu作为隐藏层的激活函数。

本文中没有给出多层FFN的手动反向传播推导过程。具体可查看NNDL 第93页。手动反向传播主要涉及矩阵求导(本质上是求多变量的偏导数)和链式法则。
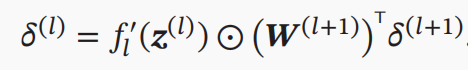
每层FFN中参数的梯度是由当前层的净输入(仿射变换的结果)关于激活函数的梯度、参数关于净输入的梯度(偏导数矩阵-即Jaccobian Matrix)以及上一层传过来的梯度(误差项)连乘所得。值得注意的是,对于深层网络而言,当选用sigmoid或tanh激活函数,由于其容易饱和使梯度较小,而层层的梯度回传会让梯度衰减甚至消失,导致网络难以训练。
多层FFN用于分类的优化目标如下:

1.2 计算图
对于较深的网络,手工推导每一层参数的梯度很繁琐也容易出错。尽管,基于数值微分的自动微分方法(利用泰勒Taylor公式一阶近似,以一阶差分近似微分)可以计算梯度,但此法需要对每一个参数都进行一次前向传播计算,因而十分耗时。在实际中,基于数值微分的梯度计算通常只用于梯度校验。这时就需要利用计算图,依赖链式法则来自动进行梯度反向传播,以求解各个参数的梯度。
计算图中每个输入节点表示变量(标量、向量、矩阵和张量),此外操作也可以表示为节点 (前向传播和反向传播),它详细描绘了每一步的计算过程。计算图可以有效地计算参数的提取,例如重用梯度矩阵。
1、手动实现各个模块的前向和反向计算过程(解耦合),然后把各个模块拼接起来。 缺点就是反向过程也需要手动实现。本文主要介绍此类方法。
2、基于自动计算图的自动微分,可以直接底层实现反向传播,更简便 (这时,可以只专注于网络的搭建)
接下来将,多层FFN和softmax层加loss进行拆分,分别介绍激活函数、仿射变换和softmax-with-loss的计算图,并实现其对应的前向和反向传播。这样,我们就可以将这些层拼接起来,搭建任意深度的神经网络。
1.2.1 激活函数
1)Sigmoid
Sigmoid激活函数及其计算图如下所示。Sigmoid函数的关于其输入x的梯度可以被简化为y(1-y)。
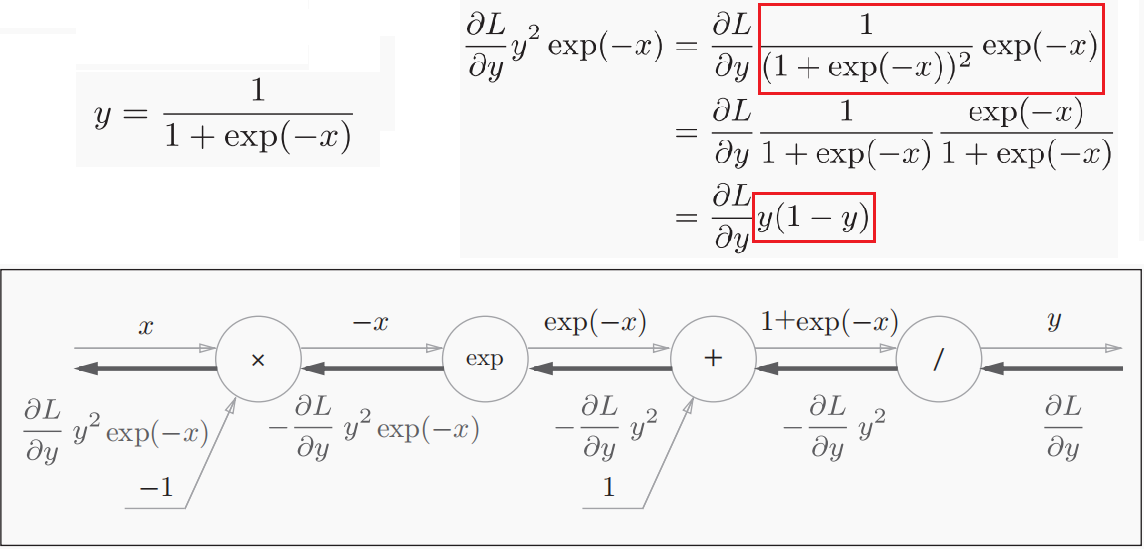
Sigmoid层的代码实现如下。
class Sigmoid:
def __init__(self):
self.out = None def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
2)Relu

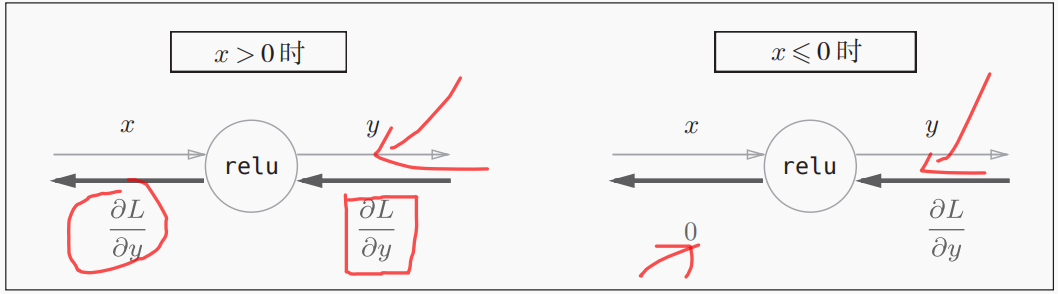
ReLU层的代码实现如下。Relu类有实例变量mask。这个变量mask是由True/False构成的NumPy数组,它会把正向传播时的输入x的元素中小于等于0的地方保存为True,其他地方(大于0的元素)保存为False。dout是上层回传的梯度。
class Relu:
def __init__(self):
self.mask = None def forward(self, x):
self.mask = (x <= 0) # Numpy, True/False
out = x.copy()
out[self.mask] = 0
return out def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
1.2.2 仿射变换
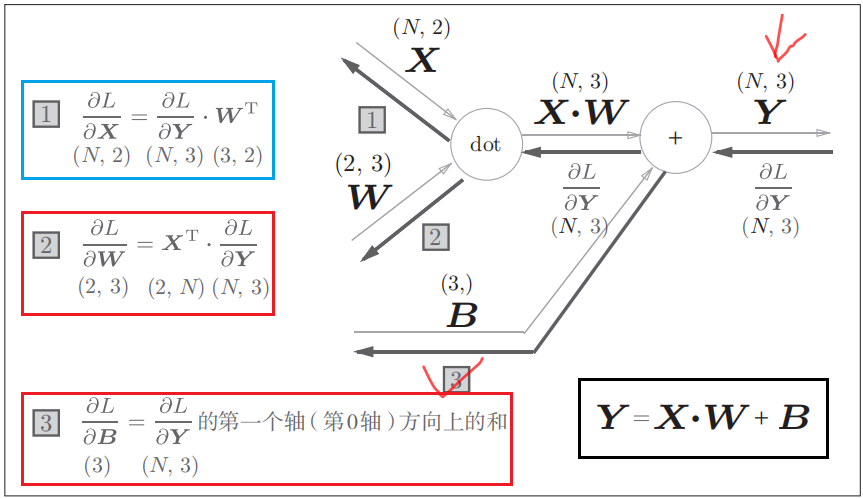
这里我们假设输入是N个样例构成的一个batch。我们可以根据计算图得出仿射变换中关于参数W和偏置B(实际计算中,会对每一个输入加相同的偏置向量,由此构成偏置矩阵。在计算其梯度时,需将每一项梯度求和)。仿射变换层的代码实现如下。
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.original_x_shape = None
self.dW = None # 权重和偏置参数的梯度
self.db = None def forward(self, x):
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b # Numpy自动广播
return out def backward(self, dout):
dx = np.dot(dout, self.W.T) # dout is ∂L/∂Y即上一层的梯度
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 还原输入数据的形状(对应张量)
return dx # 根据计算图,将当前层的梯度dx向前回传
1.2.3 softmax-with-loss
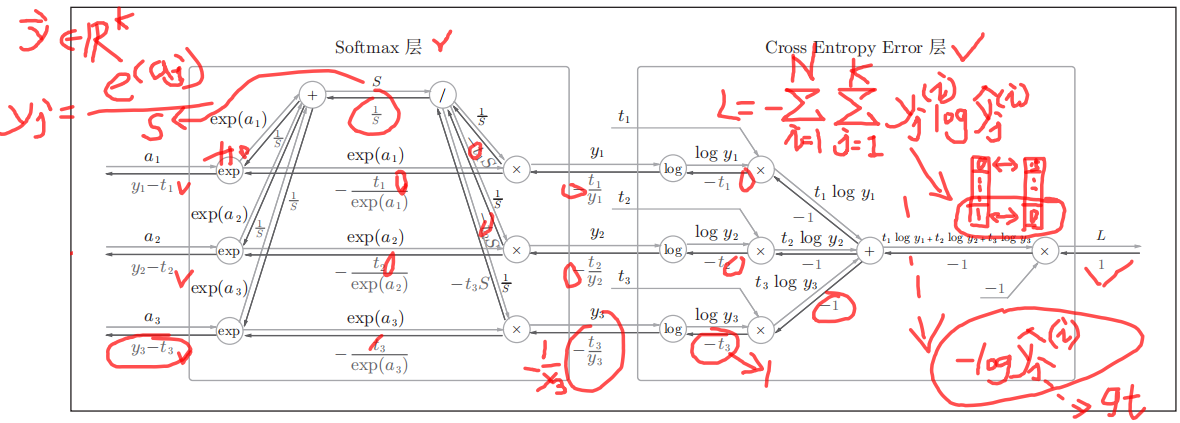
可以看到Softmax层的反向传播得到了(y1 − t1, y2 − t2, y3 − t3)这样“漂亮”的结果。由于(y1, y2, y3)是Softmax层的输出,(t1, t2, t3)是监督数据,所以(y1 − t1, y2 − t2, y3 − t3)是Softmax层的输出和真实标签的差值。神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性质。
在多分类中,ground truth label是一个one-hot编码,这意味着真实标签向量中仅有一维为1,而其余维都为0。假设t3为1,而t1、t2皆为0。在基于交叉熵损失优化网络参数时,误差项将以(y1, y2, y3 − 1)反向传播,以调整网络参数。 由上图可知,尽管在实际计算交叉熵损失时,只会计算真实标签向量中真正类别对应维的负对数似然,但是这个损失在反向传播中也会引导网络去调整其他层的参数。
softmax-with-loss层的代码实现如下。
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T x = x - np.max(x) # 应对数值溢出的对策,输出与原式等价
return np.exp(x) / np.sum(np.exp(x)) def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size) # 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1) batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size class SoftmaxWithLoss:
""" Softmax Layer With Cross Entropy Loss """
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据 def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size return dx
二、模型构建和训练
依据第一节的实现的激活函数、仿射变换层以及损失,3层FFN的分类模型的前向传播以及反向传播计算梯度的可由如下代码实现。这里可以尝试将Relu替换为Sigmoid函数来查看模型的效果。
import numpy as np
from collections import OrderedDict class ThreeLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
print("Build Net") # 初始化权重
mid_size = hidden_size // 2
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, mid_size)
self.params['b2'] = np.zeros(mid_size)
self.params['W3'] = weight_init_std * np.random.randn(mid_size, output_size)
self.params['b3'] = np.zeros(output_size) # 生成层
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine3'] = Affine(self.params['W3'], self.params['b3']) self.lastLayer = SoftmaxWithLoss() def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x) return x def loss(self, x, t):
# x:输入数据, t:监督数据
y = self.predict(x)
return self.lastLayer.forward(y, t) def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1) accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy def gradient(self, x, t):
self.loss(x, t) # forward dout = 1 # backward
dout = self.lastLayer.backward(dout) layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout) grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
grads['W3'], grads['b3'] = self.layers['Affine3'].dW, self.layers['Affine3'].db
return grads
加载MNIST数据集。
# coding: utf-8
try:
import urllib.request
except ImportError:
raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as np url_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {
'train_img':'train-images-idx3-ubyte.gz',
'train_label':'train-labels-idx1-ubyte.gz',
'test_img':'t10k-images-idx3-ubyte.gz',
'test_label':'t10k-labels-idx1-ubyte.gz'
} dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl" train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784 def _download(file_name):
file_path = dataset_dir + "/" + file_name if os.path.exists(file_path):
return print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done") def download_mnist():
for v in key_file.values():
_download(v) def _load_label(file_name):
file_path = dataset_dir + "/" + file_name print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done") return labels def _load_img(file_name):
file_path = dataset_dir + "/" + file_name print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done") return data def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label']) return dataset def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!") def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1 return T def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集 Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组 Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist() with open(save_file, 'rb') as f:
dataset = pickle.load(f) if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0 if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label']) if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28) return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label']) if __name__ == '__main__':
init_mnist()
基于SGD对模型进行训练。
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist # 读入并划分数据
ratio = 0.1
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = x_train.shape[0]
valid_size = int(train_size * ratio)
train_size = train_size - valid_size
x_valid = x_train[:valid_size]
t_valid = t_train[:valid_size]
x_train = x_train[valid_size:]
t_train = t_train[valid_size:] # 构建网络
network = ThreeLayerNet(input_size=784, hidden_size=64, output_size=10)
learning_rate = 0.01 class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key] # 不同参数W1, ..., Wk有相同学习率 optimizer = SGD(lr=learning_rate) # 训练和验证
batch_size = 200
iters_num = 5000 # 适当设定循环的次数
iter_per_epoch = max(train_size / batch_size, 1)
train_loss_list, train_acc_list, valid_acc_list = [], [], []
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grad = network.gradient(x_batch, t_batch) # grad = network.numerical_gradient(x_batch, t_batch)
optimizer.update(network.params, grad) # 更新参数 loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
valid_acc = network.accuracy(x_valid, t_valid)
train_acc_list.append(train_acc)
valid_acc_list.append(valid_acc)
print("train acc, valid acc | " + str(train_acc) + ", " + str(valid_acc)) # 绘制图形 (Train, test)
markers = {'train': 'o', 'valid': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, valid_acc_list, label='valid acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show() # 测试
test_acc = network.accuracy(x_test, t_test)
print("test acc | " + str(test_acc))
值得注意的是,可以很容易将上述代码修改为任意深度的前馈神经网络FFN(其代码可参考此处),当然越深并不意味着效果越好。
此外,训练深度神经网络有很多值得注意的Trick,包括初始化网络参数、对激活值进行归一化、正则化、学习率调节、选择合适的优化算法以及设计更好的网络结构(残差连接或跳连接)。
深度学习基础-基于Numpy的多层前馈神经网络(FFN)的构建和反向传播训练的更多相关文章
- 深度学习基础-基于Numpy的卷积神经网络(CNN)实现
本文是深度学习入门: 基于Python的实现.神经网络与深度学习(NNDL)以及动手学深度学习的读书笔记.本文将介绍基于Numpy的卷积神经网络(Convolutional Networks,CNN) ...
- 深度学习基础-基于Numpy的感知机Perception构建和训练
1. 感知机模型 感知机Perception是一个线性的分类器,其只适用于线性可分的数据. f(x) = sign(w.x + b) 其试图在所有线性可分超平面构成的假设空间中找 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- AI炼丹 - 深度学习必备库 numpy
目录 深度学习必备库 - Numpy 1. 基础数据结构ndarray数组 1.1 为什么引入ndarray数组 1.2 如何创建ndarray数组 1.3 ndarray 数组的基本运算 1.4 n ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- 机器学习&深度学习基础(目录)
从业这么久了,做了很多项目,一直对机器学习的基础课程鄙视已久,现在回头看来,系统的基础知识整理对我现在思路的整理很有利,写完这个基础篇,开始把AI+cv的也总结完,然后把这么多年做的项目再写好总结. ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- TensorFlow深度学习基础与应用实战高清视频教程
TensorFlow深度学习基础与应用实战高清视频教程,适合Python C++ C#视觉应用开发者,基于TensorFlow深度学习框架,讲解TensorFlow基础.图像分类.目标检测训练与测试以 ...
随机推荐
- Bugku CTF练习题---加密---ok
Bugku CTF练习题---加密---ok flag:flag{ok-ctf-1234-admin} 解题步骤: 1.观察题目,发现规律 2.发现所有内容都是ook写的, 直接上网搜索一下原因,发现 ...
- xpath & csv文件读写
原理:拿到网页源代码并且进行分析 关键词:etree .xpath a[@href="dapao"] a/@href text() impo ...
- Mysql 连续时间分组
该方案:不限于本例的时间连续,也可适用于其他按连续分组. 连续条件 分组这问题困扰了很久,之前觉得在SQL上很难处理,都是在程序上做处理.后面实在有太多这需求了,所以只能想办法在SQL上处理了. 如下 ...
- Azure Service Fabric 踩坑日志
近期项目上面用到了Azure Service Fabric这个服务,它是用来做微服务架构的,由于这套代码和架构都是以前同学留下来的,缺少文档,项目组在折腾时也曾遇到几个问题,这里整理如下,以供参考. ...
- fxksmdb.exe 是什么进程?
今天打开电脑应用进程发现fxksmdb.exe.fxksmpl.exe.fxksmW.exe三个进程,经过查看文件路径发现原来是施乐打印机的驱动程序自带的应用,平时都没注意到这个,这下放心了. 我这里 ...
- 多线程05:unique_lock详解
unique_lock详解 一.unique_lock取代lock_guard unique_lock是个类模板,实际应用中,一般lock_guard(推荐使用):lock_guard取代了mutex ...
- 下篇:技术 Leader 的思考方式
作者: 朱春茂(知明) 技术 Leader 是一个对综合素质要求非常高的岗位,不仅要有解具体技术问题的架构能力,还要具备团队管理的能力,更需要引领方向带领团队/平台穿越迷茫进阶到下一个境界的能力.所以 ...
- 清明欢乐赛(USACO选题)
总传送门 T1. [USACO19JAN] Redistricting P luogu P5202 思路: 这种每次选出段长有个上限\(k\)的常常是和单调队列有关. 这里是单调队列优化dp 不过一开 ...
- 抽象类与接口——JavaSE基础
抽象类与接口 抽象类 抽象类既包含规范又包含具体实现 抽象类可以包含实现的方法 和 未实现的用abstract修饰的抽象方法 抽象类不可以有实例化(不能使用new实例化),只能通过子类继承,然后对子类 ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...