Pytorch从0开始实现YOLO V3指南 part1——理解YOLO的工作
本教程翻译自https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
视频展示:https://www.youtube.com/embed/8jfscFuP_9k(需要FQ)
深度学习的发展给目标检测任务带来了显著提升。近年来人们开发了许多用于目标检测的算法,包括YOLO、SSD、Mask RCNN和RetinaNet等。
在过去的几个月里,我一直在一个研究实验室致力于改进目标检测。这次经历中我最大的收获之一就是意识到学习目标检测最好的方法就是自己从头开始实现算法。这正是我们在本教程中要做的。
我们将使用PyTorch来实现一个基于YOLO v3的目标检测器,这是目前最快的目标检测算法之一。
本教程的代码设计为在Python 3.5和PyTorch 0.4上运行。你可以在Github repo上找到它的完整版本。本教程分为以下5个部分:
第1部分:理解YOLO的工作原理(本节)
第2部分:创建网络体系结构的层
第三部分:实现网络的前向传播
第4部分:目标评分阈值化和非极大值抑制
第5部分:输入和输出流程的设计
必备条件:
(1)您应该了解卷积神经网络是如何工作的,还有像残差块、跳层连接和上采样的知识。
(2)知道什么是目标检测、边界框回归、IoU和非极大值抑制。
(3)了解PyTorch的基本使用,能够轻松地创建简单的神经网络。
什么是YOLO:
YOLO字面意思就是你只看一次。它是一种基于深度卷积神经网络进行特征学习的目标检测器。在我们动手编写代码之前,我们必须了解YOLO是如何工作的。
全卷积神经网络:
YOLO只使用了卷积层,所以是一个全卷积网络(FCN)。它包含75个卷积层,以及跳层连接和上采样层。没有使用池化而使用一个步长为2的卷积层对特征图进行降采样来防止池化造成的特征丢失。作为一个FCN, YOLO本身不受输入图像大小的影响。然而,在实践中我们其实需要一个固定大小的输入尺寸。
这是因为我们想批量处理图像(批量图像可以由GPU并行处理,从而提高速度),就需要每一批中的图像维度一致。
网络通过卷积的步长对图像进行下采样。例如,如果网络的步长为32,那么大小为416 x 416的输入图像将产生大小为13 x 13的输出。
网络输出:
通常卷积层学习到的特征被送到最后的分类器/回归器上,分类器/回归器进行检测预测(边界框的坐标、类标签),在YOLO中,预测是通过使用1 x 1的卷积层来完成的。
首先要注意的是我们的输出是一个feature map。因为我们使用了1 x 1卷积,所以预测图的大小与之前的特征图的大小完全相同。在YOLO v3中,feature map的每个单元格可以预测固定数量的边界框。
虽然描述特征图中的一个单元的正确术语应该是神经元,但在我们的下文中,称它为细胞使它更直观。
Though the technically correct term to describe a unit in the feature map would be a neuron, calling it a cell makes it more intuitive in our context.
在深度上,我们在feature map中有 (B x (5 + C)) 维。B表示每个单元格可以预测的边界框数。根据这篇论文,B个边界框中的每一个可以都可以检测某个特殊物品。每个边界框都有5 + C 个属性,这些属性用于描述每个边界框的中心坐标、长宽、目标得分和C个物品类别置信度。YOLO v3中每个细胞预测3个标注框,也就是B=3。
如果目标的中心落在某个细胞的接受域内,则期望这个细胞通过它其中一个预测的边界框来预测对象。(接受域是细胞可见的输入图像区域。进一步说明请参考卷积神经网络的链接)。
这一设置这与YOLO的训练方式有关,也就是只有一个边界框负责检测给定的对象。为了做到这点,首先我们必须确定这个边界框属于哪个cell。
为此,我们将输入图像划分为与最终feature map相同维度的网格。
下面举例说明,如下输入图像是416 x 416,网络的步长是32。如前所述,feature map的尺寸为13 x 13。然后我们将输入图像分成13个x 13个单元格。

然后,选择包含对象真值边界框中心的单元格(在输入图像上)作为负责预测对象的单元格。上图中标记为红色的单元格包含ground truth框的中心(标记为黄色)。
红色的细胞是网格上第7行第7个细胞。我们便将feature map的第7行中的第7个细胞 (feature map上对应的cell) 指定为负责检测狗的cell。前面提到每个cell可以预测三个边界框。哪一个才是对应了狗的呢? 为了理解这一点,我们必须围绕锚的概念展开讨论。
Note that the cell we're talking about here is a cell on the prediction feature map. We divide the input image into a grid just to determine which cell of the prediction feature map is responsible for prediction
锚盒:
在实践中,我们不会预测边界框的宽度和高度因为这会导致训练的不稳定,现阶段大多数目标检测器都是预测一个对数空间的转换。
之后将这些转换加到锚点上来获得锚盒作为预测结果。YOLO v3有三个锚盒,也就对应了每个cell预测的三个边界框。
回到我们之前的问题上,负责检测狗的cell中的那个锚盒是与真实框中IoU最高的那个。
预测:
下面的公式描述了如何转换网络输出以获得边界框预测(最后两个公式就是前面提到的对数空间转换)。
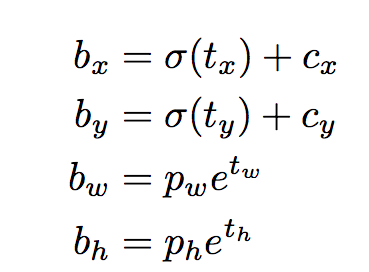
上式中bx, by, bw, bh分别对应预测的中心坐标,宽度和高度。tx, ty, tw, th是网络输出的值。cx和cy是网格的左上坐标。pw和ph是盒子的锚盒尺寸。下面对上式的含义以及cx,cy,pw,ph进行说明
中心坐标
我们通过一个sigmoid函数进行中心坐标预测,这是因为sigmoid能够迫使输出的值在0和1之间。可以看到YOLO没有预测边界框中心的绝对坐标,它预测的相对于检测目标的cell的左上角坐标(cx,cy)的偏移量,这一偏移量通过cell的尺寸大小标准化。
还是以上图狗为例。如果中心坐标的预测值为(0.4,0.7),则意味着实际中心位于13 x 13 feature map上的 (6.4,6.7) 。(因为红色cell的左上坐标是(6,6))。
如果预测的xy坐标大于1会发生什么?比如(1.2,0.7),这意味着中心在 (7.2,6.7) 处,那就到了第7行第8个cell。其实这是不可能的,因为如果我们假设红色cell负责预测狗,狗的中心就必须位于红色的cell中,这是yolo的规定。
边界框的尺寸
将预测的长宽(tw,th)经过对数空间变换,再与锚盒长宽(pw,ph)相乘来预测边界框的大小。
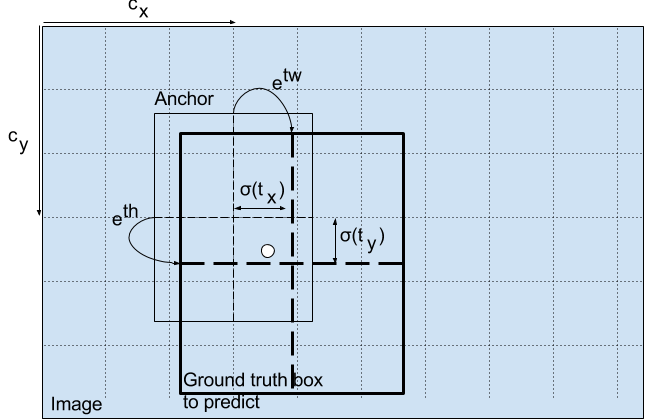
bw和bh也像cx,cy一样经过了标准化。因此包含狗的检测框的预测bw和bh为(0.3,0.8),那么在13x13 feature map上的实际宽度和高度为(13x0.3, 13x0.8)。
目标得分:
目标得分表示边界框包含目标的概率。对于红色和相邻的网格应该接近1,而对于角上的网格,应该接近0。
目标得分也经过sigmoid函数转换为一个概率。
类别置信度:
类别置信度表示被检测对象属于特定类(狗、猫、香蕉、汽车等)的概率。在v3之前,YOLO使用softmax计算类别置信度。
然而作者在v3中选择使用sigmoid,原因是softmax假定类是互斥的。简单地说,如果一个对象属于一个类,那么它就不能属于另一个类。这对于COCO数据库是正确的,但是当我们有像女人和人这样的类别时,这种假设可能就不成立了。这是作者避免使用Softmax激活的原因。
不同尺度的预测:
YOLO v3在三个不同的尺度上进行预测。检测层会对三种不同尺寸的特征图进行检测,它们的步长分别为32步、16步和8步。这意味着,在输入维度为416 x 416的情况下,我们会在13 x 13、26 x 26和52 x 52这几个尺寸上进行检测。
网络将输入图像下采样至第一个检测层,使用步长为32的层的特征图进行检测。之后将层向上采样2倍,并与具有相同特征映射大小的前一层特征映射连接起来,在这一步长为16的层上使用另一个检测器。重复同样的上采样过程,最后在步长为8的层进行检测。
在每个尺度上,每个cell使用3个锚盒预测3个边界框,所以每个cell的锚盒总数为9。

作者说这有助于YOLO v3更好地检测小目标,小目标丢失是早期版本YOLO经常遇到的问题。上采样可以帮助网络学习细粒度的特征,这些特征对于检测小对象非常有用。
输出处理:
对于大小为416 x 416的图像,YOLO预测了 ((52 x 52) + (26 x 26) + 13 x 13) x 3 = 10647 个边界框。然而我们的图像中只有一个目标就是一条狗。如何将检测从10647减少到1?
目标置信度阈值:
首先,我们根据边界框的得分对它们进行筛选。得分低于阈值的框将被忽略。
非极大值抑制(NMS):
NMS旨在解决同一幅图像的多重检测问题。例如,红色cell的3个边界框都可能检测到一个框,或者相邻的cell也可能检测到相同的目标。

我们的实现:
YOLO只能检测属于训练网络的数据集中存在类别的目标。我们将使用官方的权重文件作为我们的检测器。这些权值通过在COCO数据集上进行训练得到,所以可以检测到80个目标类别。
这是第一部分。本文对YOLO算法做了足够的解释,使您能够实现检测器。但是如果您想深入了解YOLO的工作原理、它是如何训练的以及与其他检测器相比它的性能如何,您可以阅读最初的论文,下面是我提供的链接。
这部分就讲到这里。在下一部分中,我们将实现组装检测器所需的各个层。
Further Reading
Pytorch从0开始实现YOLO V3指南 part1——理解YOLO的工作的更多相关文章
- Pytorch从0开始实现YOLO V3指南 part5——设计输入和输出的流程
本节翻译自:https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch ...
- Pytorch从0开始实现YOLO V3指南 part3——实现网络前向传播
本节翻译自:https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch ...
- Pytorch从0开始实现YOLO V3指南 part2——搭建网络结构层
本节翻译自:https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch ...
- Pytorch从0开始实现YOLO V3指南 part4——置信度阈值和非极大值抑制
本节翻译自:https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch ...
- YOLO v3
yolo为you only look once. 是一个全卷积神经网络(FCN),它有75层卷积层,包含跳跃式传递和降采样,没有池化层,当stide=2时用做降采样. yolo的输出是一个特征映射(f ...
- 一文看懂YOLO v3
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf论文:YOLOv3: An Incremental Improvement YOLO系列的 ...
- (转载)PyTorch代码规范最佳实践和样式指南
A PyTorch Tools, best practices & Styleguide 中文版:PyTorch代码规范最佳实践和样式指南 This is not an official st ...
- 深度学习笔记(十三)YOLO V3 (Tensorflow)
[代码剖析] 推荐阅读! SSD 学习笔记 之前看了一遍 YOLO V3 的论文,写的挺有意思的,尴尬的是,我这鱼的记忆,看完就忘了 于是只能借助于代码,再看一遍细节了. 源码目录总览 tens ...
- Yolo V3整体思路流程详解!
结合开源项目tensorflow-yolov3(https://link.zhihu.com/?target=https%3A//github.com/YunYang1994/tensorflow-y ...
随机推荐
- 看看JDK1.7与1.8的内存模型差异
JDK1.7与1.8的区别的内存模型差异? jsk1.7的内存模型: 堆分为初生代和老年代,大小比例为1:2,初生代又分为eden.from.to三个区域,大小比例为8:1:1 方法区:有代码区.常量 ...
- 攻防世界-MISC:stegano
这是攻防世界新手练习区的第五题,题目如下: 点击附件1下载,得到一个pdf文件,打开后内容如下: 把pdf文件里的内容复制到记事本上,发现一串A和B的字符串,不知道是什么(真让人头大) 参考一下WP, ...
- 【ACM程序设计】并查集
并查集 并查集(Union-find Sets)是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有:求连通子图.求最小生成树的Kruskal算法和求最近公共祖先( ...
- C#开发PACS医学影像三维重建(十三):基于人体CT值从皮肤渐变到骨骼的梯度透明思路
当我们将CT切片重建为三维体之后,通常会消除一些不必要的外部组织来观察内部病灶, 一般思路是根据人体常见CT值范围来使得部分组织透明来达到效果, 但这是非黑即白的,即,要么显示皮肤,要么显示神经,要么 ...
- NS2的LEACH仿真出来的nam文件拓扑的节点为什么x=0,且y=0
查看.tr文件和.nam发文件下所有的节点的x,y值都是(0,0),nam图像更没有运行出来 于是我将if { $opt(sc) == "" } {puts "*** N ...
- os、json、sys、subprocess模块
os模块 import os 1.创建目录(文件夹) os.mkdir(r'a') # 相对路径 只能创建单级目录 os.makedirs(r'a\b') # 可以创建单级和多及目录 2.删除目录 o ...
- JS运算符,流程控制,函数,内置对象,BOM与DOM
运算符 1.算数运算符 运算符 描述 + 加 - 减 * 乘 / 除 % 取余(保留整数) ++ 递加 - - 递减 ** 幂 var x=10; var res1=x++; '先赋值后自增1' 10 ...
- redis 基础1
1.redis是什么? redis是非关系型数据库key-value数据库,开源免费.是当下NoSQL技术之一 2.redis能干吗? (1)内存存储,可以持久化,redis存储在内存中,内存的话是断 ...
- SQL多表多字段比对方法
目录 表-表比较 整体思路 找出不同字段的明细 T1/T2两表ID相同的部分,是否存在不同NAME 两表的交集与差集:判断两表某些字段是否相同 两表的交集与差集:找出T2表独有的id 字段-字段比较 ...
- Spring Boot整合模板引擎jsp
jsp也算是一种模板引擎吧.整合jsp前,先说一下运行SpringBoot项目的几种方式 1. 运行SpringBoot项目的几种方式 1.1 使用内嵌Tomcat运行项目 在IDE中右键运行启动类, ...