优化器Optimal
未完成!!!!!!
神经网络的训练主要是通过优化损失函数来更新参数,而面对庞大数量的参数的更新,优化函数的设计就显得尤为重要,下面介绍一下几种常用的优化器及其演变过程:
【先说明一下要用到符号的含义】:
损失函数里一般有两种参数,一种是控制输入信号量的权重(Weight, 简称$ w $),另一种是调整函数与真实值距离的偏差(Bias,简称$ b $),在这里我们将参数统一表示为$ \theta_t \in R^{d} $,损失函数为$J(\theta)$,学习率为$\eta$ 。损失函数关于当前参数的梯度:$g_t = \nabla J(\theta_t)$
损失函数用来衡量机器学习模型的精确度。一般来说,损失函数的值越小,模型的精确度就越高。想要使损失函数最小化,就要用到梯度的概念。梯度是指向变化最快的方向。知道了该往哪里走,接下来就是该走多长,这用学习率$\eta$来控制
【1】梯度下降
参数更新公式:$\theta_{t+1} = \theta_t - g_t $
原始梯度下降法在迭代每一次梯度下降的过程中,都对所有样本数据的梯度进行计算,理论上可以找到全局最优解。虽然最终得到的梯度下降的方向较为准确,但是运算会耗费过长的时间。两种改进方法为:
1.小批量样本梯度下降(Mini Batch GD)
小批量的意思就是算法在每次梯度下降的过程中,只选取一部分的样本数据进行计算梯度,可以明显地减少梯度计算的时间。
2. 随机梯度下降(Stochastic GD)
随机梯度下降算法只随机抽取一个样本进行梯度计算,每次都是往局部最优的方向下降,由于每次梯度下降迭代只计算一个样本的梯度,因此运算时间比小批量样本梯度下降算法还要少很多,但由于训练的数据量太小(只有一个),因此下降路径很容易受到训练数据自身噪音的影响。(只选取一个样本求梯度也能基本收敛的原因好像和期望有关)。
随着每次传入样本的不同,计算得到的梯度也会不同,这就造成了偏差,所以Mini Batch和SGD都不可避免会发生震荡
虽然梯度是指向变化最快的方向,但还是有优化空间的,主要是因为我们算的是每个点的梯度,而我们梯度的步长并不是无限小。而有了这个确定的步长,下降路径就不会和最优路径重合。
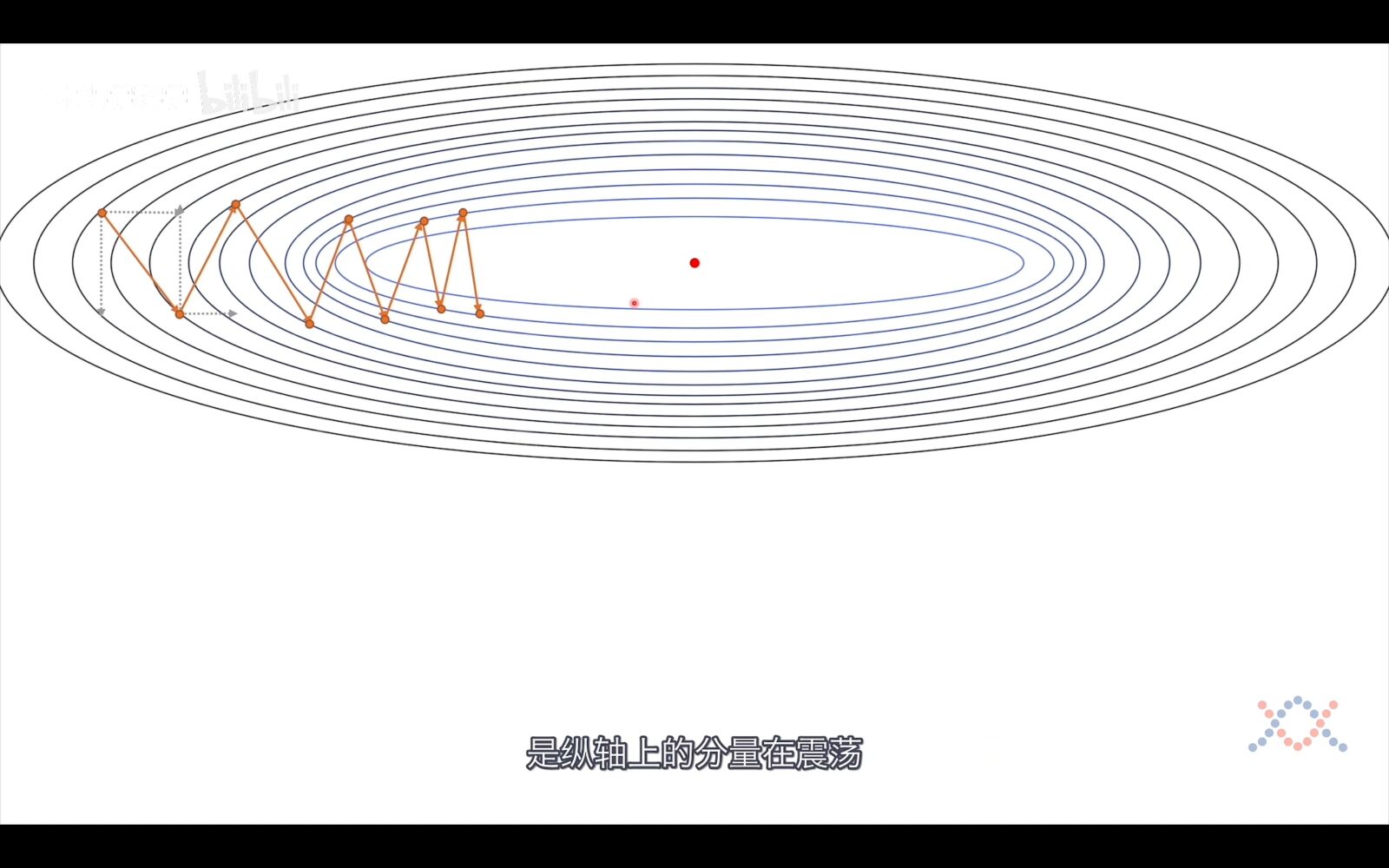
从上图我们可以看到,梯度的下降过程是震荡的,一次梯度的下降是横向向量和纵向向量的和,我们的目的是使梯度指向最优点的方向并增加步长,而这可以通过将横向向量变长,纵向向量变短来实现,而考虑到向量是有方向的,在垂直方向上,前后两个向量是反向的,相加后就可以实现纵向向量变短的目的,在水平方向上,前后两个向量是同向的,相加后就可以实现横向向量的变长,这正是接下来介绍的动量法的思想,将历史信息考虑进去。
【2】Momentum--动量法
Momentum认为梯度下降过程可以加入惯性,就是将历史梯度考虑进来:
参数更新公式如下:
$m_{t+1} = \beta m_t + \eta g_t $
$\theta_{t+1} = \theta_t - m_{t+1} $
如果将$m_{t+1} $写开来就是:$m_{t+1} = \eta\sum_{i=1}^t g_t $
此时$\theta_{t+1} = \theta_t -\eta\sum_{i=1}^t g_t $
【3】Nesterov Accelerated Gradient
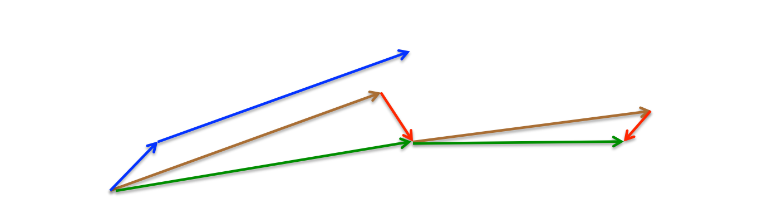
上述图片来自论文《An overview of gradient descent optimization algorithms》
Momentum首先计算当前的梯度(图3中的蓝色小矢量),然后向更新的累积梯度(蓝色大矢量)方向大跳,而NAG首先向之前的累积梯度(棕色矢量)方向大跳,测量梯度,然后进行校正(绿色矢量)。这种预见性的更新可以防止我们走得太快,并导致反应能力的提高。
在Momentum的基础上将当前时刻的梯度$g_t$换成下一时刻的梯度$\nabla J(\theta_t - \beta m_{t-1})$
参数更新公式为:
$m_{t+1} = \beta m_t + \eta\nabla J(\theta_t - \beta m_{t-1}) $
$\theta_{t+1} = \theta_t - m_{t+1} $
【4】AdaGrad(Adaptive gradient algorithm 自适学习率应梯度下降)
Adagrad 算法解决的问题:算法不能根据参数的重要性而对不同的参数进行不同程度的更新的问题。
SGD及其变种均以同样的学习率更新每个纬度的参数,但深度神经网络往往包含大量的参数,这些参数并不是总会用得到。对于经常更新的参数,我们已经积累了大量关于它的只是,不希望受到单个样本太大的影响,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。因此,AdaGrad诞生了,它就是考虑了对不同维度的参数采用不同的学习率。
以前,一次性对所有参数$\theta$ 进行更新,因为每个参数$\theta_i $ 都使用相同的学习率$\eta$ 。由于Adagrad在每个时间步骤$t$对每个参数$\theta_i $使用不同的学习率,我们首先展示Adagrad的每个参数更新,然后将其矢量化。为简洁起见,定义$g_{t,i}$为目标函数的梯度,即在时间步长$t$时对参数$\theta_i $的梯度。
参数更新公式:
$ v_{t,i} = \sum_{i=1}^t{g_{t,i}^2} $
$V_t = diag(v_{t,1},v_{t,2},\cdots,v_{t,d}\in R^{d \times d}) $
$ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt V_t+\epsilon} $
另一种公式表示:
$ E[g^2]_t=E[g^2]_{t-1}+g_t^2$
$\theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{E[g^2]_t+\epsilon}}\times g_t$
特点:前期:较小的时候,分母较大,能够放大梯度。后期:较大的时候,分母较小,能够约束梯度。适合处理稀疏梯度 \\
缺点:因为所有梯度一直是累加的,故学习率会一直减小趋于0
【5】RMSprop
RMSprop和下一个提到的优化器都是要解决Adagrad的缺点提出的改进算法,既然Adagrad的缺点是梯度平方的累加,那我们就减少累加的梯度,具体使用指数衰减移动平均算法来实现。
参数更新:
$ v_{t,i} = \beta v_{t-1,i} + (1-\beta)g_{t,i}^2 $
$V_t = diag(v_{t,1},v_{t,2},\cdots,v_{t,d}\in R^{d \times d}) $
$ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt V_t+\epsilon} $
另一种公式表示:
$ E[g^2]_t=\beta E[g^2]_{t-1}+(1-\beta)g_t^2$
$\theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{E[g^2]_t+\epsilon}}\times g_t$
【6】Adadelta
RMSprop优化器虽然可以对不同的权重参数自适应的改变学习率,但仍要指定超参数$\eta$,AdaDelta优化器对RMSProp算法进一步优化:AdaDelta算法额外维护一个状态变量$\delta x_t$,并使用$RMS[\delta x]_t$代替RMSprop中的学习率参数$\eta$,使AdaDelta优化器不需要指定超参数.
参数更新公式:
$ E[g^2]_t = \beta E[g^2]_{t-1} + (1-\beta )g_t^2 $ \ 注:符号$E[]$表示期望
$E[\Delta x^2]_{t-1}=\beta \times E[\Delta x^2]_{t-2}+(1-\beta)\times \Delta x_{t-2}^2$
$RMS[g]_t=\sqrt{E[g^2]_t+\epsilon}$
$RMS[\Delta x]_{t-1}=\sqrt{E[\Delta x^2]_{t-1}+\epsilon}$
$\theta_{t+1} = \theta_t - \frac {RMS[\Delta x]_{t-1}}{RMS[g]_t} \otimes g_t$
【7】Adam
$ m_t = \beta_1 m_{t-1}+(1-\beta_1)g_t $
$ v_t = \beta_2 v_{t-1}+(1-\beta_2)g_t^2 $
$ \hat m_t = \frac{m_t}{1-\beta_1^t} $
$ \hat v_t = \frac{v_t}{1-\beta_2^t} $
$ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat v_t} +\epsilon} \hat m_t $
【8】AdaMaX
$ m_t = \beta_1 m_{t-1}+(1-\beta_1)g_t $
$ \begin{equation}\begin{split} u_t &= \beta_2^{\infty}v_{t-1} + (1-\beta_2^\infty)\vert g_t \vert^\infty \\ &=max(\beta_2 \cdot v_{t-1},\vert g_t \vert) \end{split}\end{equation} $
$ \theta_{t+1}=\theta_t - \frac{\eta}{u_t}\hat m_t $
【9】Nadam
$ m_t=\gamma m_{t-1}+\eta g_t $
Adam为:$ \theta_{t+1}=\theta-(\gamma m_{t-1}+\eta g_t) $
对Adam的改进为:$ \theta_{t+1}=\theta-(\gamma m_t+\eta g_t) $
$\theta_{t+1}=\theta_t - \frac{\eta}{\sqrt{\hat v_t} + \epsilon}(\beta_1 \hat m_t + \frac{(1-\beta_1)g_t}{1-\beta_1^t}) $
参考资料:
[https://zhuanlan.zhihu.com/p/110104333]([论文阅读] 综述梯度下降优化算法)
[https://zhuanlan.zhihu.com/p/68468520](梯度下降算法(Gradient Descent)的原理和实现步骤)
https://zhuanlan.zhihu.com/p/351134007
论文《An overview of gradient descent optimization algorithms》
优化器Optimal的更多相关文章
- 0104探究MySQL优化器对索引和JOIN顺序的选择
转自http://www.jb51.net/article/67007.htm,感谢博主 本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分" ...
- MongoDB 优化器MongoDB Database Profiler(12)
优化器profile 在MySQL 中,慢查询日志是经常作为我们优化数据库的依据,那在MongoDB 中是否有类似的功能呢?答案是肯定的,那就是MongoDB Database Profiler. 1 ...
- ORACLE优化器RBO与CBO介绍总结
RBO和CBO的基本概念 Oracle数据库中的优化器又叫查询优化器(Query Optimizer).它是SQL分析和执行的优化工具,它负责生成.制定SQL的执行计划.Oracle的优化器有两种,基 ...
- Oracle的优化器介绍
Oracle优化器介绍 本文讲述了Oracle优化器的概念.工作原理和使用方法,兼顾了Oracle8i.9i以及最新的10g三个版本.理解本文将有助于您更好的更有效的进行SQL优化工作. RBO优化器 ...
- MySQL追踪优化器小试
首先看一下MySQL追踪优化器的典型用法: 打开:SET optimizer_trace="enabled=on"; 查询优化器的信息:SELECT * FROM INFORMAT ...
- SQL Server优化器特性-动态检索
前段时间我写的文章SQL Server 隐式转换引发的躺枪死锁 中有的朋友评论回复说在SQL2008R2测试时并未出现死锁,自己一测果然如此,因此给大家带来的疑惑表示抱歉,这里我就解释下其原因. 回顾 ...
- SQL Server 优化器特性导致的内存授予相关BUG
我们有时会遇到一些坑,要不填平,要不绕过.这里为大家介绍一个相关SQL Server优化器方面的特性导致内存授予的相关BUG,及相关解决方式,也顺便回答下邹建同学的相关疑问. 问题描述 一个简单的查询 ...
- SQL Server优化器特性-隐式谓词
我们都知道,一条SQL语句提交给优化器会产生相应的执行计划然后执行输出结果,但他的执行计划是如何产生的呢?这可能是关系型数据库最复杂的部分了.这里我为大家介绍一个有关SQL Server优化器的特性- ...
- 手动purge优化器的统计信息与AWR快照,减少对sysaux表空间的占用
1.运行以下脚本,计算当前优化器统计信息和AWR快照表占用sysaux的空间 SQL> conn / as sysdba SQL> @?/rdbms/admin/awrinfo.sql 2 ...
随机推荐
- NC200211 装备合成
NC200211 装备合成 题目 题目描述 牛牛有 \({x}\) 件材料 \({a}\) 和 \({y}\) 件材料 \({b}\) ,用 \({2}\) 件材料 \({a}\) 和 \({3}\) ...
- NC16618 [NOIP2008]排座椅
NC16618 [NOIP2008]排座椅 题目 题目描述 上课的时候总有一些同学和前后左右的人交头接耳,这是令小学班主任十分头疼的一件事情.不过,班主任小雪发现了一些有趣的现象,当同学们的座次确定下 ...
- 如何用天气预警API接口进行快速开发
天气预警能够指导人们出行.同一种类的气象灾害预警信号级别不同,对应的防御措施也不尽相同,人们通过气象灾害预警信号,合理安排出行.公众要提高防范意识,养成接收和关注预警信息的习惯,了解预警信息背后的意义 ...
- Redis三种模式——主从复制,哨兵模式,集群
一.Redis主从复制作用 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式. 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复:实际上是一种服务的冗余. 负 ...
- Solution -「校内题」Xorequ
0x00 前置芝士 数位dp考试里出现的小神题?? 显然考场会选择打表找规律. 数位dp + 矩阵快速幂 0x01 题目描述 给定正整数 \(n\),现有如下方程 \(x \bigoplus 3x = ...
- 日志审计与分析实验三(rsyslog服务器端和客户端配置)(Linux日志收集)
Linux日志收集 一.实验目的: 1.掌握rsyslog配置方法 2.配置rsyslog服务收集其他Linux服务器日志: C/S架构:客户端将其日志上传到服务器端,通过对服务器端日志的查询,来实现 ...
- 造!又有新的生产力语言了「GitHub 热点速览 v.22.30」
作者:HelloGitHub-小鱼干 你还记得那些 PHP 开发都去哪了吗?转 Golang 了!移动端现在流行什么?Flutter 编程.现在谷歌带着新的生产力语言来了,Carbon,代号:C++ ...
- 枚举子集为什么是 O(3^n) 的
这是更新日志 \(2021/2/9\) 代数推导 \(2021/2/10\) 组合意义,构建 TOC 目录 枚举子集 复杂度证明 代数推导 组合意义 Summary 枚举子集 枚举子集为什么是 \(O ...
- Python logging日志管理
import logging logger = logging.getLogger("simple_example") logger.setLevel(logging.DEBUG) ...
- C#枚举器/迭代器
一.枚举器 1.为什么foreach可以顺序遍历数组? 因为foreach可以识别可枚举类型,通过访问数组提供的枚举器对象来识别数组中元素的位置从而获取元素的值并打印出来. 2.什么是枚举器?可枚举类 ...