详谈 MySQL 8.0 原子 DDL 原理
柯煜昌 青云科技研发顾问级工程师 目前从事 RadonDB 容器化研发,华中科技大学研究生毕业,有多年的数据库内核开发经验。
文章字数 3800+,阅读时间 15 分钟
背景
MySQL 5.7 的字典信息保存在非事务表中,并且存放在不同的文件中(.FRM,.PAR,.OPT,.TRN,.TRG 等)。所有 DDL 操作都不是 Crash Safe,而且对于组合 DDL(ALTER 多个表)会出现有的成功有的失败的情况,而不是总体失败。这样主从复制就出现了问题,也导致基于复制的高可用系统不再安全。
MySQL 8.0 推出新特性 - 原子 DDL,解决了以上的问题。
什么是原子 DDL?
DDL 是指数据定义语言(Data Definition Language),负责数据结构的定义与数据对象的定义。原子 DDL 是指一个 DDL 操作是不可分割的,要么全成功要么全失败。
有哪些限制?
MySQL 8.0 只有 InnoDB 存储引擎支持原子 DDL。
支持语句:数据库、表空间、表、索引的 CREATE、ALTER 以及 DROP 语句,以及 TRUNCATE TABLE 语句。
MySQL 8.0 系统表均以 InnoDB 存储引擎存储,涉及到字典对象的均支持原子 DDL。
支持的语句:存储过程、触发器、视图以及用户定义函数(UDF)的 CREATE 和 DROP 、ALTER 操作,用户和角色的 CREATE、ALTER、DROP 语句,以及适用的 RENAME 语句,以及 GRANT 和 REVOKE 语句。
不支持的语句:
- INSTALL PLUGIN、UNINSTALL PLUGIN
- INSTALL COMPONENT、UNINSTALL COMPONENT
- REATE SERVER、ALTER SERVER、DROP SERVER
实现原理是什么?
首先,8.0 将字典信息存放到事务引擎的系统表(InnoDB 存储引擎)中。这样 DDL 操作转变成一组对系统表的 DML 操作,从而失败后可以依据事务引擎自身的事务回滚保证系统表的原子性。
似乎 DDL 原子性就此就可以完成,但实际上并没有这么简单。首先字典信息不光是系统表,还有一组字典缓存,如:
- Table Share 缓存
- DD 缓存
- InnoDB 中的 dict
此外,字典信息只是数据库对象的元数据,DDL 操作不光要修改字典信息,还要实实在在的操作对象,以及对象本身在内存中缓存。
- 表空间
- Dynamic meta
- Btree
- ibd 文件
- buffer pool 中表空间的 page 页
此外,binlog 也要考虑 DDL 失败的情况。
因此,原子 DDL 在处理 DDL 失败的时候,不光是直接回滚系统表的数据,而且也要保证内存缓存,数据库对象也能回滚到一致状态。
实现细节
为了解决 DDL 失败情况中数据库对象的回滚,8.0 引入了系统表 DDL_LOG。该表在 mysql 库中。不可见,也不能人为操作。如果想了解该表的结果,先编译一个 debug 版的 MySQL:
SET SESSION debug='+d,skip_dd_table_access_check';
show create table mysql.innodb_ddl_log;
可以看到如下表结构:
CREATE TABLE `innodb_ddl_log` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`thread_id` bigint unsigned NOT NULL,
`type` int unsigned NOT NULL,
`space_id` int unsigned DEFAULT NULL,
`page_no` int unsigned DEFAULT NULL,
`index_id` bigint unsigned DEFAULT NULL,
`table_id` bigint unsigned DEFAULT NULL,
`old_file_path` varchar(512) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`new_file_path` varchar(512) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `thread_id` (`thread_id`)
) /*!50100 TABLESPACE `mysql` */ ENGINE=InnoDB AUTO_INCREMENT=48 DEFAULT CHARSET=utf8 COLLATE=utf8_bin STATS_PERSISTENT=0 ROW_FORMAT=DYNAMIC
在 8.0 中,这个表需要满足两个场景以及两个任务:
场景 1: 符合 DDL 失败的场景,需要回滚部分完成的 DDL。
场景 2:DDL 进行中,发生故障(掉电、软硬件故障等),重启机器需要完成部分 DDL。
两个任务:
任务 1:失败后回滚,执行反向操作。
任务 2:如果成功,则执行清理工作。
也许有人会问,为什么执行成功需要执行清理工作呢?
之所以要执行清理工作,因为 ibd 文件和索引一旦删除就不能恢复。为了实现回滚,DDL 删除这些对象时候,并不是真正删除,而是先将它们备份一下,以备回滚时使用。所以只有确认 DDL 已经执行成功,这些备份对象不需要了,才执行清理工作。
举个例子
为了将这个原理将清楚,我们流程相对简单的 CREATE TABLE 讲起,管中窥豹,可见一斑。假设已经有编译好了 8.0 debug 版本,并且 innodb_file_per_table 为 on,先执行以下命令:
mysql> set global log_error_verbosity=3;
Query OK, 0 rows affected (0.00 sec)
mysql> set global innodb_print_ddl_logs = on;
Query OK, 0 rows affected (0.00 sec)
从而开启了ddl log的日志,然后创建表:
mysql> create table t2 (a int);
Query OK, 0 rows affected (25 min 26.42 sec)
可以看到如下日志:
XXXXX 8 [Note] [MY-012473] [InnoDB] DDL log insert : [DDL record: DELETE SPACE, id=20, thread_id=8, space_id=6, old_file_path=./test/t2.ibd]
XXXXX 8 [Note] [MY-012478] [InnoDB] DDL log delete : 20
XXXXX 8 [Note] [MY-012477] [InnoDB] DDL log insert : [DDL record: REMOVE CACHE, id=21, thread_id=8, table_id=1067, new_file_path=test/t2]
XXXXX 8 [Note] [MY-012478] [InnoDB] DDL log delete : 21
XXXXX 8 [Note] [MY-012472] [InnoDB] DDL log insert : [DDL record: FREE, id=22, thread_id=8, space_id=6, index_id=157, page_no=4]
XXXXX 8 [Note] [MY-012478] [InnoDB] DDL log delete : 22
XXXXX 8 [Note] [MY-012485] [InnoDB] DDL log post ddl : begin for thread id : 8
XXXXX 8 [Note] [MY-012486] [InnoDB] DDL log post ddl : end for thread id : 8
create table 的 DDL 只有反向操作日志记录,而无清理操作日志记录。细心的读者可能看到日志中插入某条 DDL log,随后又将其删除,会心生疑惑。但这正是 MySQL 原子 DDL 的秘密所在。我们选 DELETE SPACE 这个 DDL 日志写入函数Log_DDL::write_delete_space_log 来揭秘这个过程。
dberr_t Log_DDL::write_delete_space_log(trx_t *trx, const dict_table_t *table,
space_id_t space_id,
const char *file_path, bool is_drop,
bool dict_locked) {
ut_ad(trx == thd_to_trx(current_thd));
ut_ad(table == nullptr || dict_table_is_file_per_table(table));
if (skip(table, trx->mysql_thd)) {
return (DB_SUCCESS);
}
uint64_t id = next_id();
ulint thread_id = thd_get_thread_id(trx->mysql_thd);
dberr_t err;
trx->ddl_operation = true;
DBUG_INJECT_CRASH("ddl_log_crash_before_delete_space_log",
crash_before_delete_space_log_counter++);
if (is_drop) { //(1)
err = insert_delete_space_log(trx, id, thread_id, space_id, file_path,
dict_locked);
if (err != DB_SUCCESS) {
return err;
}
DBUG_INJECT_CRASH("ddl_log_crash_after_delete_space_log",
crash_after_delete_space_log_counter++);
} else { // (2)
err = insert_delete_space_log(nullptr, id, thread_id, space_id, file_path,
dict_locked);
if (err != DB_SUCCESS) {
return err;
}
DBUG_INJECT_CRASH("ddl_log_crash_after_delete_space_log",
crash_after_delete_space_log_counter++);
DBUG_EXECUTE_IF("DDL_Log_remove_inject_error_2",
srv_inject_too_many_concurrent_trxs = true;);
err = delete_by_id(trx, id, dict_locked); //(3)
ut_ad(err == DB_SUCCESS || err == DB_TOO_MANY_CONCURRENT_TRXS);
DBUG_EXECUTE_IF("DDL_Log_remove_inject_error_2",
srv_inject_too_many_concurrent_trxs = false;);
DBUG_INJECT_CRASH("ddl_log_crash_after_delete_space_delete",
crash_after_delete_space_delete_counter++);
}
return (err);
}
在create table 这个过程中调用write_delete_space_log,is_drop 为false,执行以上代码执行分支 (2) 和 (3) 。注意的是 insert_delete_space_log 第一个参数为空,这意味着会在创建一个后台事务(调用trx_allocate_for_background)插入DELETE_SPACE 记录到innodb_ddl_log 表中,然后提交该事务。注意到(3) 处delete_by_id 第一个参数为trx , 这里的trx 即本次 DDL 的事务,(3) 所做的动作是在本次事务中删除(2)插入的记录。
为什么是这样的逻辑呢?
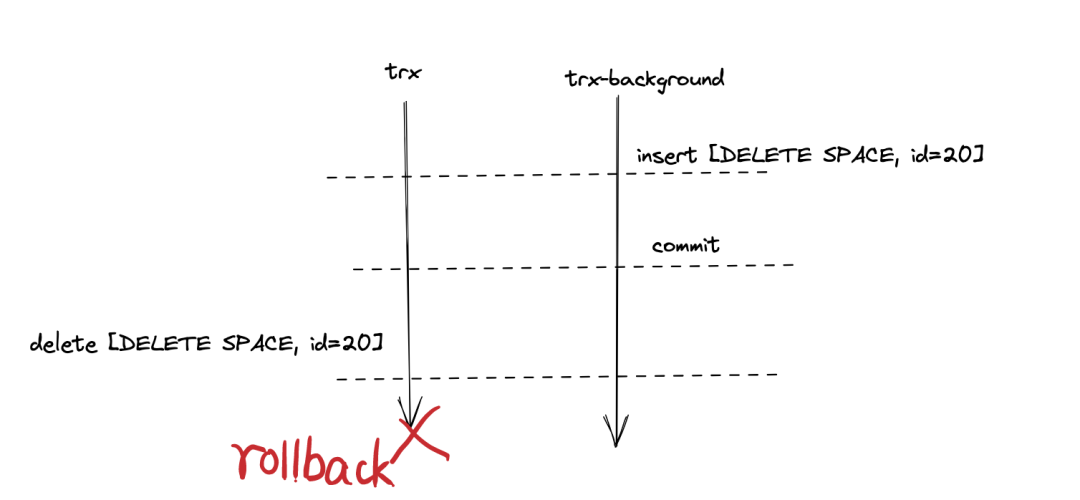
以下分两种情况来讨论,如上图所示:
- 如果插入 DDL log 之后,DDL 的各个步骤都成功执行,最后事务
trx成功提交,那么innodb_ddl_log并没有该 DDL 的记录,因此在后续的post_ddl中什么也不做(post_ddl 在后面会描述)。 - 如果插入 DDL log 之后,DDL 的某个步骤失败,则 DDL 所在的事务
trx会回滚。此时,上图中delete [DELETE SPACE, id=20]这个动作也会回滚。最后,innodb_ddl_log中就会存在DELETE SPACE这条记录,后续执行post_ddl进行 Replay(重演), 从而删除这次失败的create table的 DDL 已经创建的表空间。你可以发现,create table的 DDL 创建表空间,就一定会以这样的机制往innodb_ddl_log中插入一条相反的动作DELETE SPACE的日志记录,所以也被称为反向操作日志。
其它 DDL log 记录的操作如REMOVE CACHE 、FREE 日志记录的写入也是类似的逻辑。复杂的 DDL,不光是会插入反向操作日志记录,也会插入清理操作日志。比如TRUNCATE 表操作会将原有的表空间重命名为一个零时表空间,当 DDL 成功之后,需要通过post_ddl Replay DDL log 记录,将临时表空间删除。如果失败,又需要 post_ddl重演 DDL log,执行反向操作,将临时表空间重命名为原来的表空间。总之,如果是反向操作日志,则使用background trx 插入并提交,然后使用trx 删除;如果是清理日志,则使用trx 插入即可。
注意:
innodb_ddl_log表与其他 InnoDB 表一样,对该表所有操作 InnoDB 引擎都会产生 Redo 日志与 Undo 记录,所以不要将 DDL log 表中反向操作记录看作 Undo log,这两者不在同一个抽象层次上。而且反向操作在另一个事务中执行,而回滚时,Undo log 则是在原有同一个事务上执行。
需要探讨的几个问题
DDL 是否有必要日志刷盘?
我们知道 MySQL 有一个 innodb_flush_log_at_trx_commit 参数,当设置为 0 时,提交时并不会立刻将 Redo log 刷入持久存储中。虽然能提高性能,但在掉电或者停机时会有一定概率丢失已经提交的事务。对于 DML 操作来说,这样仅仅是丢失事务,但对于 DDL 来说,丢失 DDL 的事务,就会导致数据库元数据与其他数据不一致,以至数据库系统无法正常工作。
所以,在trx_commit 会根据该事务是否为 DDL 操作,进行特殊处理:
无论innodb_flush_log_at_trx_commit参数如何设置,与 DDL 有关的事务,提交时必须日志刷盘!
DDL log 的写入时机
在理解了 DDL log 的机制之后,笔者问大家一个问题,对于create table 来说,是先执行write_delete_space_log 还是先创建表空间呢?
我们先假设是先创建表空间(A 动作),再写反向操作日志(B 动作)。如果 A 执行结束后出现掉的情况,此时 B 还未执行,此时create table 动作并没有完成,而innodb_ddl_log 不存在DELETE SPACE 这样的 DDL 反向日志记录,数据库崩溃恢复后,数据库系统会将系统表数据回滚,但是 A 创建的表空间却没有删除,由于存在中间状态,此时create table 就不是原子DDL 了。
所以,在 DDL 中每个步骤中,先写入该步骤的反向操作日志记录到innodb_ddl_log ,再执行该步骤。也就是说 DDL Log 写入时机在执行步骤之前。如果create table 已经写入了 DDL log, 但是没有创建表空间就出现掉电情况呢? 这并不要紧,在 post_ddl 做 Replay 的时候,会进行处理。
Replay 的调用逻辑
在 DDL 操作完成之后,无论 DDL 的事务提交还是回滚,都会调用post_ddl 函数,post_ddl 则会调用replay函数进行 Replay。此外,MySQL 8.0 数据库崩溃恢复过程中,与 MySQL 5.7 相比,也多了ha_post_recover的过程,它会调用log_ddl->recover 将 innodb_ddl_log 所有的日志记录进行 Replay。
在post_ddl调用的是replay_by_thread_id,崩溃恢复中ha_post_recover 调用的是replay_all,其逻辑如下描述:
- 依据传入的
thread_id为索引(thread_id与trx是可以一一对应的),以逆序方式将所有记录获取出来,然后根据记录的内容,依次执行 Replay 动作,最后删除已经重演的记录。 replay_all将innodb_ddl_log所有记录逆序方式获取出来,依次执行 Replay 动作,最后删除已经重演的记录。
可以看到,以上两个函数都有将记录逆序的获取的过程,为什么要逆序呢?
逆函数
1、反向操作
我们如果将 DDL 中每个步骤看做一个函数,参数为数据库系统。假设第 i 个步骤函数为oi,那么n个步骤就是 n 个函数的复合函数:
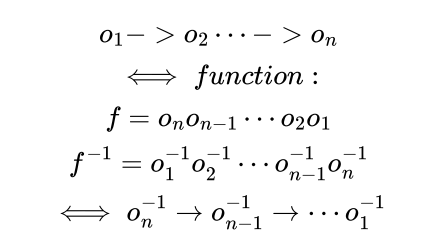
也即,复合函数的逆时所有步骤逆函数的反向复合。所以反向操作需要将 DDL log 逆序进行处理。
2、清理操作
DDL 的清理动作往往没有顺序要求,逆向操作与正向操作效果往往是一样的,所以统一进行逆序处理也没有问题。
幂等性
与 Redo、Undo 类似,每个类型的日志重演均要考虑其幂等性。
所谓幂等性,就是执行多次和执行一次的效果是一样的。特别是在崩溃恢复的时候,在重演反向操作的时候,尚未完成时发生掉电故障,重新进行崩溃恢复。此时某项重演操作可能发生多次。
因此,MySQL 8.0 实现这些重演操作,必须要考虑幂等性。最典型是重演一些删除操作,必须先判断数据库对象是否存在。如果存在,才进行删除,否则什么都不做。
Tips:说到这里,笔者推荐一本书《具体数学:计算机科学中的一块基石》此书讲解了许多计算机科学中用到的数学知识及技巧,并特别著墨于算法分析方面。
Server 层的动作
- DDL 开始更新,无论失败与否,table share 都要进行缓存更新,tdc_remove_table;
- DDL 成功之后,执行事务提交,否则执行事务回滚;
- 无论事务提交还是回滚,都要调用
post_ddl,post_ddl作用在前面已经描述,用以r Replay 系统表innodb_ddl_log记录的日志; - 崩溃恢复时候,除了执行 Redo 日志,回滚未提交的事务之后,还需要执执行
ha_post_recover,而 InnoDB 的ha_post_recover就是调用post_ddl执行 DDL 的反向操作; - binglog 处理只有一个原则,就是 DDL 事务成功。并且提交之后,才调用
write_bin_log写 binlog。
注意事项
MySQL 8.0 支持原子 DDL,并不意味着 DDL 可以通过 SQL 语句命令进行回滚。实际上除了 SQLServer 外,几乎所有的数据库系统不支持 DDL 的 SQL 命令进行回滚,DDL 回滚引入的问题远远多于其带来的好处。
MySQL 8.0 只承诺单个 DDL 语句的原子性,并不能保证多个 DDL 组合也能保持原子性。某大厂为了实现
Truncate table flashback,仅仅在 MySQL 的 Server 层将truncate table动作转换为rename table动作,flashback 的时候将表、索引、约束重新以 RENAME DDL 组合执行来实现 flashback,这个是及其危险的,不保证其原子性。笔者也完成过此功能,并没有如此取巧,而是老老实实的从 Server 层、InnoDB 存储引擎、binlog 各方面进行改造,完整保证其原子性。MySQL 8.0 用这种方法实现原子 DDL,并不意味着其它数据库也是这种方式实现原子DDL。
参考
- https://dev.mysql.com/doc/refman/8.0/en/atomic-ddl.html
- https://www.slideshare.net/StleDeraas/dd-and-atomic-ddl-pl17-dublin
- https://dev.mysql.com/blog-archive/atomic-ddl-in-mysql-8-0/
详谈 MySQL 8.0 原子 DDL 原理的更多相关文章
- MySQL8.0 原子DDL
Edit MySQL8.0 原子DDL 简介 MySQL8.0 开始支持原子 DDL(atomic DDL),数据字典的更新,存储引擎操作,写二进制日志结合成了一个事务.在没有原子DDL之前,DROP ...
- MySQL 8.0支持DDL原子化
在MySQL 5.5/5.6/5.7版本中,DDL操作是非原子型操作,在执行过程中遇到实例故障重启,可能导致DDL没有完成也没有回滚.如 1.执行DROP TABLE T1,T2操作,实例重启恢复后, ...
- MySQL8新特性(1)--原子DDL
mysql 8支持原子ddl.一个原子DDL语句包含数据字典更新.存储引擎操作.二进制日志写,事务要么被提交,应用修改被持持久化到数据字典.存储引擎和二进制日志,或者被回滚. 原子ddl是随着mysq ...
- MySQL 8.0新特性之原子DDL
文章来源:爱可生云数据库 简介 MySQL8.0 开始支持原⼦ DDL(atomic DDL),数据字典的更新,存储引擎操作,写⼆进制日志结合成了一个事务.在没有原⼦DDL之前,DROP TABLE ...
- MySQL8.0新特性——支持原子DDL语句
MySQL 8.0开始支持原子数据定义语言(DDL)语句.此功能称为原子DDL.原子DDL语句将与DDL操作关联的数据字典更新,存储引擎操作和二进制日志写入组合到单个原子事务中.即使服务器在操作期间暂 ...
- 详谈 MySQL Online DDL
作为一名DBA,对数据库进行DDL操作非常多,如添加索引,添加字段等等.对于MySQL数据库,DDL支持的并不是很好,一不留心就导致了全表被锁,经常搞得刚入门小伙伴很郁闷又无辜,不是说MySQL支持O ...
- MySQL主从同步的延迟原理
1. MySQL数据库主从同步延迟原理. 答:谈到MySQL数据库主从同步延迟原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlo ...
- MYSQL主从不同步延迟原理
1. MySQL数据库主从同步延迟原理. 要说延时原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作, 主库对所有DDL和DML产生binlog,binlog是 ...
- CentOS 7.x下安装部署MySQL 8.0实施手册
MySQL 8 正式版 8.0.11 已发布,官方表示 MySQL 8 要比 MySQL 5.7 快 2 倍,还带来了大量的改进和更快的性能! 一. Mysql8.0版本相比之前版本的一些特性 1) ...
随机推荐
- Java已知图片路径下载图片到本地
public static void main(String[] args) { FileOutputStream fos = null; BufferedInputStream bis = null ...
- NC25136 [USACO 2006 Ope B]Cows on a Leash
NC25136 [USACO 2006 Ope B]Cows on a Leash 题目 题目描述 给定如图所示的若干个长条.你可以在某一行的任意两个数之间作一条竖线,从而把这个长条切开,并可能切开其 ...
- 当mysql表从压缩表变成普通表会发生什么
前言 本文章做了把mysql表从压缩表过渡到普通表的实验过程,看看压缩表变成普通表会发生什么?本文针对mysql5.7和mysql8分别进行了实验. 1.什么是表压缩 在介绍压缩表变成普通表前,首先给 ...
- IDEA快捷键之晨讲篇
IDEA之html快捷键 快捷键 释义 ! 生成HTML的初始格式 ---- ---- 标签名*n 生成n个相同的标签 ---- ---- 标签>标签 生成父子级标签(包含) ---- ---- ...
- Note -「模拟退火」
随机化算法属于省选芝士体系 0x01 前置芝士 你只需要会 rand 就可以啦! 当然如果你想理解的更透彻也可以先看看 爬山算法 0x02 关于退火 退火是一种金属热处理工艺,指的是将金属缓慢加热到一 ...
- Hive优化(面试宝典)(详细的九个优化)
Hive优化(面试宝典) 1.1 hive的随机抓取策略 理论上来说,Hive中的所有sql都需要进行mapreduce,但是hive的抓取策略帮我们 省略掉了这个过程,把切片split的过程提前帮我 ...
- 超小体积单键/1路1感应通道触摸触控检测IC-VKD233HS DFN6 2*2mm,常用于TWS蓝牙耳机入耳检测、运动手环等小体积单键触摸产品
产品品牌:永嘉微电/VINKA 产品型号:VKD233HS 封装形式:DFN6 产品年份:新年份 概述: VKD233HS DFN6具有1个触摸按键,可用来检测外部触摸按键上人手的触摸动作.该芯片具 ...
- 枚举子集为什么是 O(3^n) 的
这是更新日志 \(2021/2/9\) 代数推导 \(2021/2/10\) 组合意义,构建 TOC 目录 枚举子集 复杂度证明 代数推导 组合意义 Summary 枚举子集 枚举子集为什么是 \(O ...
- 在DELL服务器上安装windows2012 r2服务器系统
主要过程: 1.准备安装光盘,开启服务器,当出现画面按F10进入服务器自带光盘系统安装向导.(若没有系统光盘,可以用软蝶通刻一个服务系统到+R的光盘).进入后选择设置和安装系统. 2.开始安装前,提示 ...
- 技术分享 | 为什么MGR一致性模式不推荐AFTER
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 1.引子 2.AFTER 的写一致性 3.AFTER 的读一致性 4.AFTER 执行流程 5.BEFORE 执行流程 6 ...