K-means聚类算法
聚类分析(英语:Cluster analysis,亦称为群集分析)
K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般。最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用。看了Andrew Ng的这个讲义后才有些明白K-means后面包含的EM思想。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集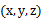 。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
在聚类问题中,给我们的训练样本是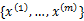 ,每个
,每个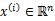 ,没有了y。
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
|
1、 随机选取k个聚类质心点(cluster centroids)为 2、 重复下面过程直到收敛 { 对于每一个样例i,计算其应该属于的类
对于每一个类j,重新计算该类的质心
} |
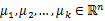 。
。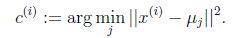
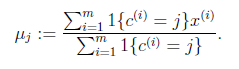
K是我们事先给定的聚类数, 代表样例i与k个类中距离最近的那个类,
代表样例i与k个类中距离最近的那个类, 的值是1到k中的一个。质心
的值是1到k中的一个。质心 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为
代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为 ,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心
,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心 (对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:

J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心 ,调整每个样例的所属的类别
,调整每个样例的所属的类别 来让J函数减少,同样,固定
来让J函数减少,同样,固定 ,调整每个类的质心
,调整每个类的质心 也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, 和c也同时收敛。(在理论上,可以有多组不同的
和c也同时收敛。(在理论上,可以有多组不同的 和c值能够使得J取得最小值,但这种现象实际上很少见)。
和c值能够使得J取得最小值,但这种现象实际上很少见)。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 和c输出。
和c输出。
下面累述一下K-means与EM的关系,首先回到初始问题,我们目的是将样本分成k个类,其实说白了就是求每个样例x的隐含类别y,然后利用隐含类别将x归类。由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎么评价假定的好不好呢?我们使用样本的极大似然估计来度量,这里是就是x和y的联合分布P(x,y)了。如果找到的y能够使P(x,y)最大,那么我们找到的y就是样例x的最佳类别了,x顺手就聚类了。但是我们第一次指定的y不一定会让P(x,y)最大,而且P(x,y)还依赖于其他未知参数,当然在给定y的情况下,我们可以调整其他参数让P(x,y)最大。但是调整完参数后,我们发现有更好的y可以指定,那么我们重新指定y,然后再计算P(x,y)最大时的参数,反复迭代直至没有更好的y可以指定。
这个过程有几个难点,第一怎么假定y?是每个样例硬指派一个y还是不同的y有不同的概率,概率如何度量。第二如何估计P(x,y),P(x,y)还可能依赖很多其他参数,如何调整里面的参数让P(x,y)最大。这些问题在以后的篇章里回答。
这里只是指出EM的思想,E步就是估计隐含类别y的期望值,M步调整其他参数使得在给定类别y的情况下,极大似然估计P(x,y)能够达到极大值。然后在其他参数确定的情况下,重新估计y,周而复始,直至收敛。
上面的阐述有点费解,对应于K-means来说就是我们一开始不知道每个样例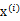 对应隐含变量也就是最佳类别
对应隐含变量也就是最佳类别 。最开始可以随便指定一个
。最开始可以随便指定一个 给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的
给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的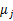 (前面提到的其他未知参数),然而此时发现,可以有更好的
(前面提到的其他未知参数),然而此时发现,可以有更好的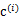 (质心与样例
(质心与样例 距离最小的类别)指定给样例
距离最小的类别)指定给样例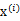 ,那么
,那么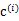 得到重新调整,上述过程就开始重复了,直到没有更好的
得到重新调整,上述过程就开始重复了,直到没有更好的 指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量
指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量 ,M步更新其他参数
,M步更新其他参数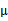 来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
标签: Machine Learning
K-means聚类算法的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- [聚类算法] K-means 算法
聚类 和 k-means简单概括. 聚类是一种 无监督学习 问题,它的目标就是基于 相似度 将相似的子集聚合在一起. k-means算法是聚类分析中使用最广泛的算法之一.它把n个对象根据它们的属性分为 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 转载 | Python AI 教学│k-means聚类算法及应用
关注我们的公众号哦!获取更多精彩哦! 1.问题导入 假如有这样一种情况,在一天你想去某个城市旅游,这个城市里你想去的有70个地方,现在你只有每一个地方的地址,这个地址列表很长,有70个位置.事先肯定要 ...
- FCM聚类算法介绍
FCM算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小.模糊C均值算法是普通C均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则 ...
随机推荐
- web前端交互性易用性说明
总结一下我们在web前端开发过程中总是强调交互性.易用性的情况分析说明.个人觉得web前端的易用交互也就是我们所说人性化操作.不外乎希望达到的效果为:界面风格简洁明了.重点突出:操作简单,直观可见.当 ...
- Blink, 通向哈里·波特的魔法世界
<哈里·波特>的故事里面,魔法界的新闻报纸都是动画的,配图带有动画效果.能够回放新闻的主要场景. 初次看到这个,感觉还挺新鲜的.不过现在,Blink 这样的 App 可以让这个魔法世界的幻 ...
- SharePoint 2013 图文开发系列之InfoPath入门
本文主要介绍SharePoint 2013中,简单发布InfoPath表单,并添加后台代码,示例比较简单,主要描述的是一个创建InfoPath的过程,而非多么深奥的后台代码,希望能够给初学者带来帮助. ...
- 用Kotlin开发Android应用(IV):定制视图和Android扩展
原文标题:Kotlin for Android (IV): Custom Views and Android Extensions 原文链接:http://antonioleiva.com/kotli ...
- Material Design 概念,环境和基本属性
Material Design 概念,环境和基本属性 Material Design是随Android 5.0推出的一种设计概念, 涉及到了跨平台和设备的视觉,动态,交互设计等方面. 设计概念 M ...
- UIView的几个layout方法
iOS layout的相关方法: 1,layoutSubviews 2,layoutIfNeeded 3,setNeedsLayout 4,setNeedsDisplay 5,drawRect 6,s ...
- # iOS 10 适配 # 适配刷新控件 以MJRefresh 为例
在iOS10中ScrollView 添加了一个refreshControl的东西 - - 不知道水果公司做了什么 导致原有的刷新控件类刷新后frame.y 向下偏移了20 起初以为是水果调整了sta ...
- 动态计算UITableViewCell高度
动态计算UITableViewCell高度 UILabel in UITableViewCell Auto Layout - UILabel的属性Lines设为了0表示显示多行.Auto Layout ...
- Objective-C语法之KVO使用
本文转自:http://blog.csdn.net/yuquan0821/article/details/6646400/ 一,概述 KVO,即:Key-Value Observing,它提供一种机制 ...
- 让我们来谈谈JDBC
1.JDBC 1)JDBC简介 - JDBC就是Java中连接数据库方式 - 我们可以通过JDBC来执行SQL语句. 2)获取数据库连接 - j ...