Hadoop详解(02)Hadoop集群运行环境搭建
Hadoop详解(02)Hadoop集群运行环境搭建
虚拟机环境准备
虚拟机节点数:3台
操作系统版本:CentOS-7.6-x86-1810
虚拟机 内存4G,硬盘99G
IP地址分配
192.168.194.102 hadoop102
192.168.194.103 hadoop103
192.168.194.104 hadoop104
- 安装必要环境
yum install -y epel-release
yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
- 关闭防火墙,关闭防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld
- 创建普通用户(以hadoop用户),并修改用户的密码
[root@hadoop102 ~]# useradd hadoop
[root@hadoop102 ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
- 配置hadoop用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop102 ~]# vim /etc/sudoers
修改/etc/sudoers文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL
- 在/opt目录下创建文件夹,并修改所属主和所属组
(1)在/opt目录下创建module、software文件夹
[root@hadoop102 ~]# mkdir /opt/module
[root@hadoop102 ~]# mkdir /opt/software
(2)修改module、software文件夹的所有者和所属组均为hadoop用户
[root@hadoop102 ~]# chown hadoop:hadoop /opt/module
[root@hadoop102 ~]# chown hadoop:hadoop /opt/software
(3)修改module、software文件夹的权限
[root@hadoop102 opt]# cd /opt/
[root@hadoop102 opt]# chmod -R 777 module/ software/
(4)查看module、software文件夹的所有者和所属组
[root@hadoop102 opt]# ll
total 0
drwxrwxrwx. 2 hadoop hadoop 6 Nov 23 22:06 module
drwxrwxrwx. 2 hadoop hadoop 67 Nov 23 21:55 software
- 卸载虚拟机自带的open JDK
查询已安装Java软件
[root@hadoop102 opt]$ rpm -qa | grep java
卸载该JDK:
[root@hadoop102 opt]$ sudo rpm -e jdk的软件包名称
查询并卸载open JDK命令(将上述两个步骤和到一块)
rpm -qa | grep -i java | xargs -n1 rpm -e –nodeps
- 修改克隆机主机名
修改主机名称,两种方法二选一
方式一
[root@hadoop102 ~]# hostnamectl --static set-hostname hadoop102
方式二
修改/etc/hostname文件
[root@hadoop102 ~]# vi /etc/hostname
清空原来内容,添加如下内容,添加的内容即为主机名称
hadoop102
- 配置linux克隆机主机名称映射hosts文件
编辑/etc/hosts文件
[root@hadoop102 ~]# vi /etc/hosts
在文件中添加如下内容(Shift+g调到文件末尾,o 在本行下面添加一行)
192.168.194.102 hadoop102
192.168.194.103 hadoop103
192.168.194.104 hadoop104
使用ping 命令测试配置是否成功
[root@hadoop102 ~]# ping hadoop102
[root@hadoop102 ~]# ping hadoop103
[root@hadoop102 ~]# ping hadoop104
- 修改windows的主机映射文件(hosts文件)
修改windows上的hosts文件是为了能够在本地Windows物理机上通过主机名称访问集群,如果不配置只能通过ip的方式访问,在访问集群时跳转页面时可能会出现主机名的链接,这样就无法正常访问了
进入C:\Windows\System32\drivers\etc路径
打开hosts文件并添加如下内容,然后保存
192.168.194.102 hadoop102
192.168.194.103 hadoop103
192.168.194.104 hadoop104
- 将上面的所有操作分别在hadoop103、hadoop104两台机器上重复执行
注意在修改主机名称时调整hadoop103、hadoop104的主机名称
安装JDK
- 将jdk1.8安装包上传到服务器/opt/software目录下
[root@hadoop102 software]# cd /opt/software/
[root@hadoop102 software]# ls
jdk-8u212-linux-x64.tar.gz
- 解压JDK到/opt/module目录下
[root@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 配置JDK环境变量
修改/etc/profile文件
[root@hadoop102 software]# vi /etc/profile
在文件末尾添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
保存后退出
:wq
source一下/etc/profile文件,让新的环境变量PATH生效
[root@hadoop102 software]# source /etc/profile
- 测试JDK是否安装成功
[root@hadoop102 software]# java -version
如果能看到以下结果,则代表Java安装成功
[root@hadoop102 software]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
- Jdk拷贝到其他两台机器
拷贝jdk安装文件
[root@hadoop102 ~]# scp -r /opt/module/jdk1.8.0_212/ hadoop103:/opt/module/
[root@hadoop102 ~]# scp -r /opt/module/jdk1.8.0_212/ hadoop104:/opt/module/
拷贝/etc/profile文件
scp /etc/profile hadoop103:/etc/
scp /etc/profile hadoop104:/etc/
分别在另外两台机器执行命令重新加载环境变量
[root@hadoop103 opt]# source /etc/profile
[root@hadoop104 opt]# source /etc/profile
分别查看jdk的安装版本
[root@hadoop103 opt]# java -version
第一次使用scp命令分发文件时会出现
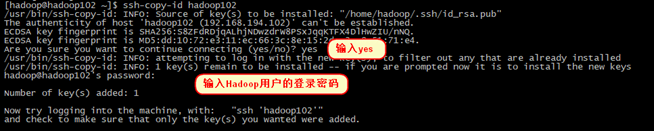
Are you sure you want to continue connecting (yes/no)? yes
输入yes,然后再输入登录密码,如果配置了ssh免密登录后就不用再每次拷贝文件时都要输入密码了
Hadoop安装
安装环境准备
- 切换用户
切换hadoop用户
注意:对hadoop的安装、管理等操作都使用普通用户,如果使用root用户需要还需要配置额外的参数
- 安装包下载
Hadoop安装包下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
- SSH无密登录配置
Hadoop需要通过SSH来启动salve列表中各台主机的守护进程,因此SSH也是必须安装的,即使是安装伪分布式版本(因为Hadoop并没有区分集群式和伪分布式),Hadoop会采用与集群相同的处理方式,即依次序启动文件conf/slaves中记载的主机上的进程,只不过伪分布式中salve为localhost(即为自身),所以对于伪分布式Hadoop,SSH一样是必须的。
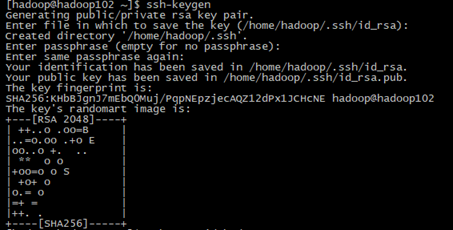
生成密匙
[hadoop@hadoop102 ~]$ ssh-keygen
执行ssh-keygen连按4个回车
拷贝密匙到所有服务器
[hadoop@hadoop102 ~]$ ssh-copy-id hadoop102
[hadoop@hadoop102 ~]$ ssh-copy-id hadoop103
[hadoop@hadoop102 ~]$ ssh-copy-id hadoop104
注意:ssh-copy-id拷贝密匙本机也需要拷贝,因为hadoop在启动集群时即便是启动本机上的进程时也是通过ssh操作的
测试ssh免密登录
[hadoop@hadoop102 hadoop]$ ssh hadoop102 date;
Wed Nov 24 19:25:47 CST 2021
[hadoop@hadoop102 hadoop]$ ssh hadoop103 date;
Wed Nov 24 19:25:52 CST 2021
[hadoop@hadoop102 hadoop]$ ssh hadoop104 date;
Wed Nov 24 19:25:56 CST 2021
执行ssh hadoop102 date;命令时能够正确的显示时间并不需要输入密码即配置成功
安装hadoop
- 上传文件
将hadoop-3.1.3.tar.gz上传到服务器的/opt/software文件夹下面
- 解压:
[hadoop@hadoop102 ~]$ cd /opt/software/
[hadoop@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
删除说明文档文件夹(可选)
删除/opt/module/hadoop-3.1.3/share/doc/hadoop目录,该目录是hadoop的说明文档,内有大量的小文件,删除该文件夹可更快的分发hadoop安装包到其他机器,不删除也不影响使用
[hadoop@hadoop102 doc]$ cd /opt/module/hadoop-3.1.3/share/doc/
[hadoop@hadoop102 doc]$ rm -rf hadoop/
- 查看Hadoop目录结构
- [hadoop@hadoop102 hadoop-3.1.3]$ ll
- total 176
- drwxr-xr-x. 2 hadoop hadoop 183 Sep 12 2019 bin
- drwxr-xr-x. 3 hadoop hadoop 20 Sep 12 2019 etc
- drwxr-xr-x. 2 hadoop hadoop 106 Sep 12 2019 include
- drwxr-xr-x. 3 hadoop hadoop 20 Sep 12 2019 lib
- drwxr-xr-x. 4 hadoop hadoop 288 Sep 12 2019 libexec
- -rw-rw-r--. 1 hadoop hadoop 147145 Sep 4 2019 LICENSE.txt
- -rw-rw-r--. 1 hadoop hadoop 21867 Sep 4 2019 NOTICE.txt
- -rw-rw-r--. 1 hadoop hadoop 1366 Sep 4 2019 README.txt
- drwxr-xr-x. 3 hadoop hadoop 4096 Sep 12 2019 sbin
- drwxr-xr-x. 4 hadoop hadoop 31 Sep 12 2019 share
重要目录说明
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
- Hadoop添加到环境变量
获取Hadoop安装路径
[hadoop@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
打开/etc/profile文件
[hadoop@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile
在文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存后退出
:wq
让修改后的文件生效
[hadoop@hadoop102 hadoop-3.1.3]$ source /etc/profile
测试是否安装成功
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
Hadoop运行模式
- Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。详见Hadoop官方网站
- 本地运行模式(官方wordcount 了解,一般不会使用)
1)创建在hadoop-3.1.3文件下面创建一个wcinput文件夹
mkdir wcinput
2)在wcinput文件下创建一个word.txt文件
cd wcinput
3)编辑word.txt文件
vim word.txt
在文件中输入如下内容
hadoop yarn
hadoop mapreduce
hello
hello
保存退出::wq
4)回到Hadoop目录/opt/module/hadoop-3.1.3
5)执行程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
6)查看结果
cat wcoutput/part-r-00000
看到如下结果:
hadoop 2
hello 2
mapreduce 1
yarn 1
完全分布式运行模式
- 集群部署规划
hadoop102
hadoop103
hadoop104
HDFS
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN
ResourceManager
NodeManager
NodeManager
NodeManager
- 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
要获取的默认文件 文件存放在Hadoop的jar包中的位置
[core-default.xml] hadoop-common-3.1.3.jar/ core-default.xml
[hdfs-default.xml] hadoop-hdfs-3.1.3.jar/ hdfs-default.xml
[yarn-default.xml] hadoop-yarn-common-3.1.3.jar/ yarn-default.xml
[mapred-default.xml] hadoop-mapreduce-client-core-3.1.3.jar/ mapred-default.xml
自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,可以根据项目需求重新进行修改配置。
常用端口号说明
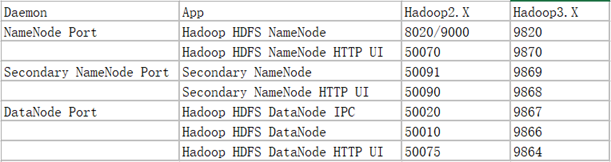
- 修改配置文件
配置core-site.xml
cd /opt/module/hadoop-3.1.3/etc/hadoop/
vi core-site.xml
文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<!-- 配置该hadoop(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<!-- 配置该hadoop(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<!-- 配置该hadoop(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
HDFS配置文件
vim hdfs-site.xml
文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
YARN配置文件
vim yarn-site.xml
文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
MapReduce配置文件
vim mapred-site.xml
文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置workers
vim workers
文件内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容前后不允许有空格,文件中不允许有空行。
修改hadoop-env.sh文件
vi hadoop-env.sh
找到已经注释了"export JAVA_HOME"的代码行,写入对应的JAVA_HOME变量值
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/opt/module/jdk1.8.0_212/
找到已经注释了" export HADOOP_PID_DIR "的代码行,写入对应的HADOOP_PID_DIR变量值
# Where pid files are stored. /tmp by default.
export HADOOP_PID_DIR=/opt/module/hadoop-3.1.3/tmp/pids
创建HADOOP_PID_DIR目录
[hadoop@hadoop102 hadoop]$ mkdir /opt/module/hadoop-3.1.3/tmp/
说明:
JAVA_HOME的路径一定要填写绝对路径
HADOOP_PID_DIR的值可以选择不修改,默认会在/tmp目录下,修改后需要创建对应的目录,只需要创建到tmp文件夹就行,pids会自动生成。一般最好放修改位hadoop安装目录下,方便拷贝到其他节点(虚拟机)上
- 配置注意项
- JAVA_HOME的路径一定要填写绝对路径!
- HADOOP_PID_DIR的值可以先填上去,后面再去创建,创建的时候最好放在hadoop安装目录下,而且只需要创建到tmp文件夹就行,pids会自动生成,方便拷贝到其他节点(虚拟机)上
将修改好配置文件后的hadoop安装文件夹 /opt/module/hadoop-3.1.3拷贝到另外两台机器
[hadoop@hadoop102 hadoop]$ scp -r /opt/module/hadoop-3.1.3/ hadoop103:/opt/module/
[hadoop@hadoop102 hadoop]$ scp -r /opt/module/hadoop-3.1.3/ hadoop104:/opt/module/
启动集群并测试
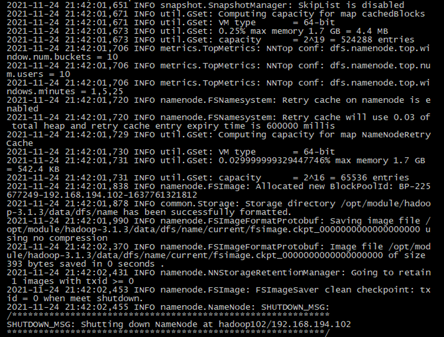
- 格式化NameNode
如果集群是第一次启动,需要在hadoop102节点(主节点)格式化NameNode。
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
格式化NameNode命令
[hadoop@hadoop102 hadoop]$ hdfs namenode -format
- 启动集群
启动HDFS
[hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
启动yarn
[hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-yarn.sh
Hdfs和yarn一块启动的命令:sbin/start-all.sh
- 查看是否启动成功
hdfs和yarn成功启动的完整日志
- [hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
- Starting namenodes on [hadoop102]
- Starting datanodes
- hadoop103: WARNING: /opt/module/hadoop3.1.3/tmp/pids does not exist. Creating.
- hadoop103: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
- hadoop104: WARNING: /opt/module/hadoop3.1.3/tmp/pids does not exist. Creating.
- hadoop104: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
- Starting secondary namenodes [hadoop104]
- [hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-yarn.sh
- Starting resourcemanager
- Starting nodemanagers
Jps查看进程,分别在三台机器上执行jps命令查看进程
- [hadoop@hadoop102 hadoop-3.1.3]$ jps
- 6900 Jps
- 6280 DataNode
- 6761 NodeManager
- 6652 ResourceManager
- 6174 NameNode
- [hadoop@hadoop103 hadoop-3.1.3]$ jps
- 2193 NodeManager
- 2277 Jps
- 2072 DataNode
- [hadoop@hadoop104 hadoop-3.1.3]$ jps
- 2129 NodeManager
- 2005 SecondaryNameNode
- 1928 DataNode
- 2217 Jps
Web页面查看
浏览器中输入http://hadoop102:9870/ 查看hdfs信息
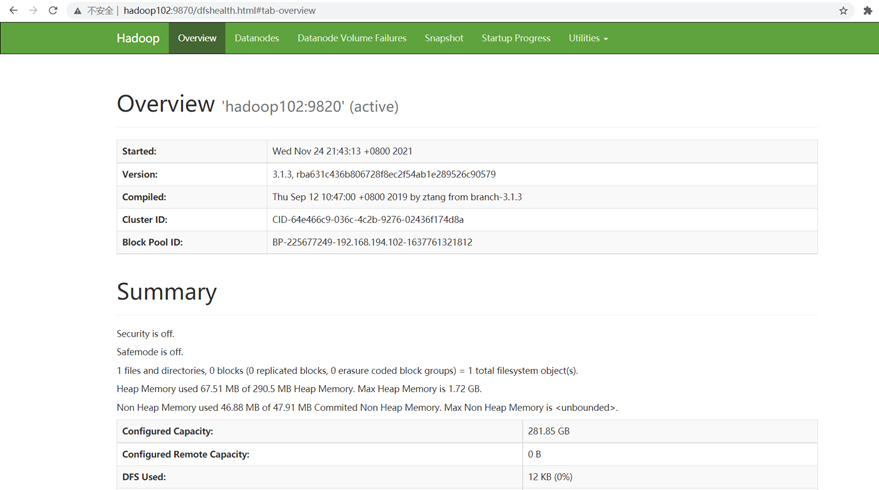
查看hdfs的节点信息:http://hadoop102:9870/dfshealth.html#tab-datanode
访问页面后网下滚动
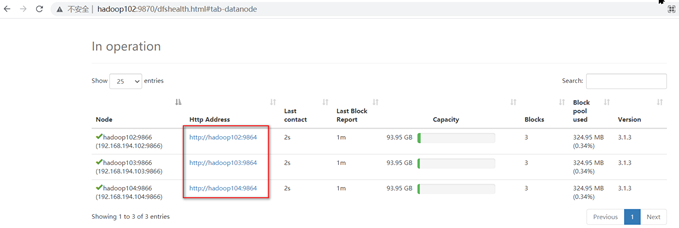
浏览器中输入 http://hadoop102:8088/ 查看yarn信息

查看节点信息
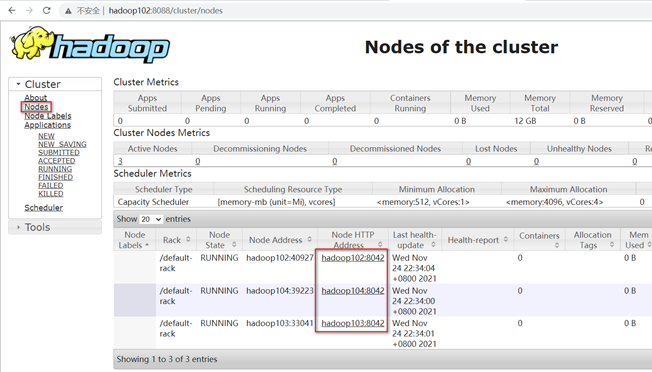
- 基准测试
上传文件
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/software/hadoop-3.1.3.tar.gz /input
查看上传的文件
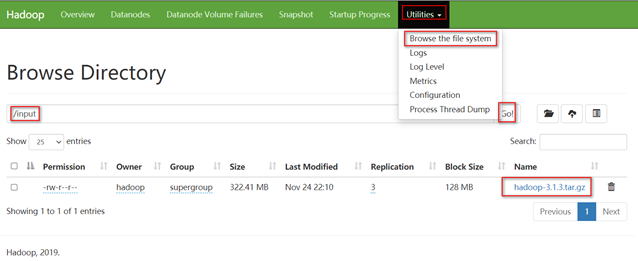
下载hdfs中的文件
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -get /input/hadoop-3.1.3.tar.gz ./
提交yarn任务
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 5 10
查看任务在yarn平台上运行,需要等待任务正式提交到了yanr平台上才能看到,
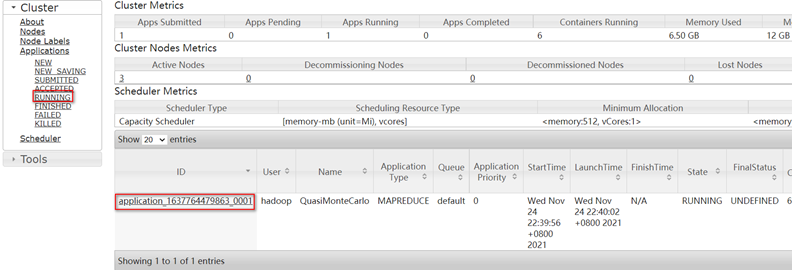
集群启动/停止方式总结
- 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
- 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
一次启动/停止整个集群
start-all.sh/stop-all.sh
配置历史服务器(可选)
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
- 配置mapred-site.xml
[hadoop@hadoop102 hadoop]$ vi mapred-site.xml
在该文件里面增加如下配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
分发配置文件
[hadoop@hadoop102 hadoop]$ scp mapred-site.xml hadoop103:/opt/module/hadoop-3.1.3/etc/hadoop/
[hadoop@hadoop102 hadoop]$ scp mapred-site.xml hadoop104:/opt/module/hadoop-3.1.3/etc/hadoop/
- 在hadoop102启动历史服务器
[hadoop@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
- 查看JobHistory
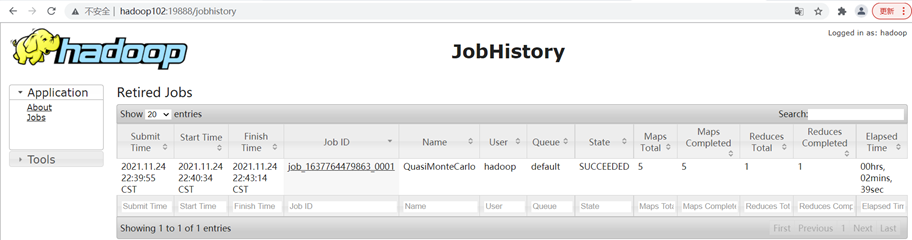
配置日志的聚集(可选)
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
- 配置yarn-site.xml
[hadoop@hadoop102 hadoop]$ vim yarn-site.xml
在该文件里面增加如下配置
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- 分发配置
[hadoop@hadoop102 hadoop]$ scp yarn-site.xml hadoop103:/opt/module/hadoop-3.1.3/etc/hadoop/
[hadoop@hadoop102 hadoop]$ scp yarn-site.xml hadoop104:/opt/module/hadoop-3.1.3/etc/hadoop/
- 重启NodeManager 、ResourceManager和HistoryServer
停止
[hadoop@hadoop102 hadoop-3.1.3]$ stop-yarn.sh
[hadoop@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver
启动
[hadoop@hadoop102 hadoop-3.1.3]$ start-yarn.sh
[hadoop@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
- 提交yarn任务
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 5 10
- 查看日志
http://hadoop102:19888/jobhistory
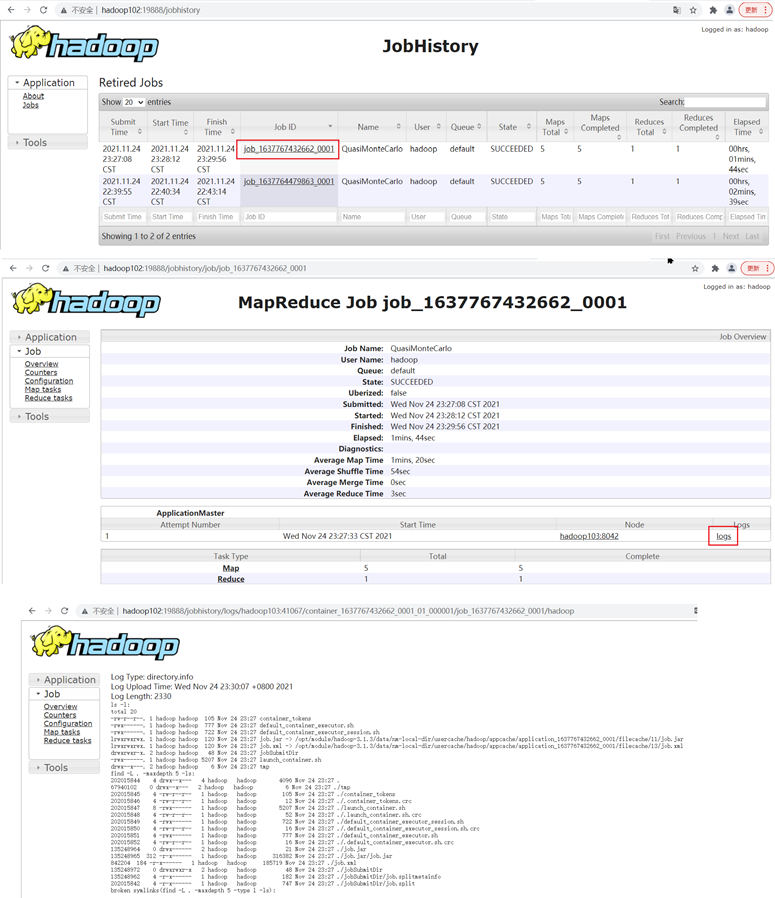
编写hadoop集群常用脚本
- 查看三台服务器java进程脚本:jpsall
[hadoop@hadoop102 ~]$ cd /home/hadoop/
[hadoop@hadoop102 ~]$ mkdir bin
[hadoop@hadoop102 ~]$ cd bin/
[hadoop@hadoop102 bin]$ vi jpsall
添加如下内容
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps $@ | grep -v Jps
done
保存后退出,然后赋予脚本执行权限
[hadoop@hadoop102 bin]$ chmod +x jpsall
测试执行
[hadoop@hadoop102 bin]$ jpsall
=============== hadoop102 ===============
11364 NameNode
12726 ResourceManager
13110 JobHistoryServer
12840 NodeManager
11471 DataNode
=============== hadoop103 ===============
4386 NodeManager
4019 DataNode
=============== hadoop104 ===============
4147 NodeManager
3576 SecondaryNameNode
3497 DataNode
遇到错误及解决办法
如果执行jpsall脚本报如下错误
[hadoop@hadoop102 bin]$ jpsall
=============== hadoop102 ===============
bash: jps: command not found
=============== hadoop103 ===============
bash: jps: command not found
=============== hadoop104 ===============
bash: jps: command not fo
问题原因:
在配置JAVA_HOME的环境变量时,很多人习惯配置在/etc/profile文件中,而不是~/.bashrc文件中。在/etc/profile文件中设置系统环境参数,比如$PATH,是仅对系统内所有用户生效。而设置~/.bashrc文件中的环境变量是针对某一个特定的用户,因此环境变量的设置也只对该用户自己有效。在使用bash命令,只要以该用户身份运行命令行就会读取该文件。
解决方法
将java环境变量配置在~/.bashrc文件中然后 source ~/.bashrc
[hadoop@hadoop102 bin]$ vi ~/.bashrc
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
重新加载文件
[hadoop@hadoop102 bin]$ source ~/.bashrc
另外两台机器同样在~/.bashrc文件中配置java环境变量
再次执行jpsall脚本查看
[hadoop@hadoop102 bin]$ jpsall
=============== hadoop102 ===============
11364 NameNode
12726 ResourceManager
13110 JobHistoryServer
12840 NodeManager
11471 DataNode
=============== hadoop103 ===============
4386 NodeManager
4019 DataNode
=============== hadoop104 ===============
4147 NodeManager
3576 SecondaryNameNode
3497 DataNode
- hadoop集群启停脚本
包含hdfs,yarn,historyserver
[hadoop@hadoop102 bin]$ cd ~/bin/
[hadoop@hadoop102 bin]$ vi myhadoop.sh
添加如下内容
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
保存后退出,然后赋予脚本执行权限
[hadoop@hadoop102 bin]$ chmod +x myhadoop.sh
测试执行
启动集群
[hadoop@hadoop102 bin]$ myhadoop.sh start
停止集群
[hadoop@hadoop102 bin]$ myhadoop.sh stop
- 集群分发脚本xsync
服务器之间拷贝文件时一般会使用scp或rsync工具手动对待拷贝的文件或文件夹进行分发使用时需要对每台服务器都需要执行一次scp命令,如果服务器数量很多就会很不方便。
编写集群分发脚本xsync可以更方便在各个服务器之间拷贝文件,具体操作如下:
[hadoop@hadoop102 bin]$ cd ~/bin/
[hadoop@hadoop102 bin]$ vim xsync
添加如下内容
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
保存后退出,然后赋予脚本执行权限
[hadoop@hadoop102 bin]$ chmod +x xsync
测试执行分发/home/hadoop/bin目录
- [hadoop@hadoop102 ~]$ xsync /home/hadoop/bin/xsync
- ==================== hadoop102 ====================
- sending incremental file list
- sent 59 bytes received 12 bytes 47.33 bytes/sec
- total size is 624 speedup is 8.79
- ==================== hadoop103 ====================
- sending incremental file list
- sent 59 bytes received 12 bytes 47.33 bytes/sec
- total size is 624 speedup is 8.79
- ==================== hadoop104 ====================
- sending incremental file list
- sent 59 bytes received 12 bytes 47.33 bytes/sec
- total size is 624 speedup is 8.79
- 分发/home/atguigu/bin目录(可选)
分发/home/atguigu/bin目录保证自定义脚本在三台机器上都可以使用,但是还需要在hadoop103、hadoop104两台服务器上做ssh免密登录
常见错误及解决方案
防火墙没关闭、或者没有启动YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
2)主机名称配置错误
3)IP地址配置错误
4)ssh没有配置好
5)root用户和atguigu两个用户启动集群不统一
6)配置文件修改不细心
7)未编译源码
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
8)不识别主机名称
java.net.UnknownHostException: hadoop102: hadoop102
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解决办法:
(1)在/etc/hosts文件中添加192.168.1.102 hadoop102
(2)主机名称不要起hadoop hadoop000等特殊名称
9)DataNode和NameNode进程同时只能工作一个
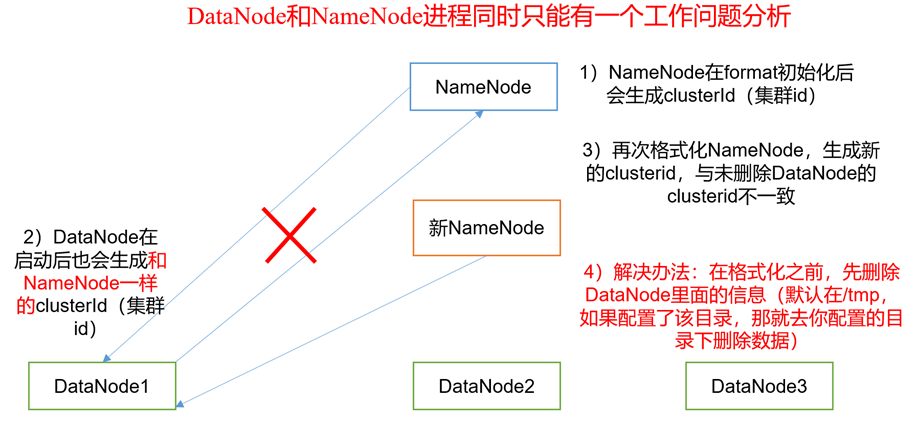
10)执行命令不生效,粘贴word中命令时,遇到-和长–没区分开。导致命令失效
解决办法:尽量不要粘贴word中代码。
11)jps发现进程已经没有,但是重新启动集群,提示进程已经开启。原因是在linux的根目录下/tmp目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
12)jps不生效。
原因:全局变量hadoop java没有生效。解决办法:需要source /etc/profile文件。
13)8088端口连接不上
[atguigu@hadoop102 桌面]$ cat /etc/hosts
注释掉如下代码
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 hadoop102
Hadoop详解(02)Hadoop集群运行环境搭建的更多相关文章
- 详解Redis Cluster集群
Redis Cluster是Redis的分布式解决方案,在Redis 3.0版本正式推出的,有效解决了Redis分布式方面的需求.当遇到单机内存.并发.流量等瓶颈时,可以采用Cluster架构达到负载 ...
- centos 8 集群Linux环境搭建
一.集群Linux环境搭建 1. 注意事项 1.1 windows系统确认所有的关于VmWare的服务都已经启动 打开任务管理器->服务,查看五个VM选项是否打开. 1.2 确认好VmWare生 ...
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- Hadoop入门(五) Hadoop2.7.5集群分布式环境搭建
本文接上文内容继续: server01 192.168.8.118 jdk.www.fengshen157.com/ hadoop NameNode.DFSZKFailoverController(z ...
- 【图文详解】Zookeeper集群搭建(CentOs6.3)
Zookeeper简介: Zookeeper是一个分布式协调服务,就是为用户的分布式应用程序提供协调服务的. A.zookeeper是为别的分布式程序服务的 B.Zookeeper本身就是一个分布式程 ...
- Dream------spark--spark集群的环境搭建
1.下载安装scala http://www.scala-lang.org/download/2.11.6.html 2.解压下载后的文件,配置环境变量:编辑/etc/profile文件,添加如下 ...
- 部署k8s集群之环境搭建和etcd单节点安装
环境搭建以及etcd 单节点安装过程 安装之前的环境搭建 在进行k8s安装之前先把虚拟机准备好,这里准备的是三台虚拟机 主机名 ip地址 角色 master 172.16.163.131 master ...
- 性能测试:k8s集群监控环境搭建(kube-prometheus)
选择kube-prometheus版本 k8s集群版本是1.22.x 5个节点 说明:如果你电脑配置低,也可以1个master节点,2个node节点 3个节点 Kube-Prometheus地址:ht ...
- MQ集群测试环境搭建(多节点负载均衡,共享一个kahaDB文件(nas方式))
1. os ubuntu12.04 基础环境准备 干掉不好用的vim重新装 sudo apt-get remove vim-common sudo apt-get install vim 如果需要使用 ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
随机推荐
- 研一入坑Go 文件操作
1 package main 2 3 import ( 4 "fmt" 5 "os" 6 "path" 7 "path/filep ...
- 洛谷P6060 [加油武汉]传染病研究
一道不错的数学题 Solution 看到约数个数就想到枚举约数,但对于每个询问都枚举显然不现实,但是我们可以将大致的方向锁定在这方面,是否可以预处理出一定的东西,然后低复杂度询问呢? 我们想到预处理出 ...
- 提高工作效率的神器:基于前端表格实现Chrome Excel扩展插件
Chrome插件,官方名称extensions(扩展程序):为了方便理解,以下都称为插件. 我们开发的插件需要在浏览器里面运行,打开浏览器,通过右上角的三个点(自定义及控制)-更多工具-拓展程序-打开 ...
- 14.-F对象和Q对象
一.F对象 一个F对象代表数据库中某条记录的字段的信息 作用 通常是对数据库中的字段值在不获取的情况下进行操作 用于属性(字段)之间的比较 语法: from django.db.models im ...
- 记录一次sshd服务启动失败
记录一次sshd服务启动失败 问题描述: 服务器开机之后发现无法通过远程连接服务器终端,但是服务器并未宕机,于是考虑到sshd服务出现异常 解决思路: 查看服务器sshd服务运行情况 [root@ha ...
- pod(八):pod的调度——将 Pod 指派给节点
目录 一.系统环境 二.前言 三.pod的调度 3.1 pod的调度概述 3.2 pod自动调度 3.2.1 创建3个主机端口为80的pod 3.3 使用nodeName 字段指定pod运行在哪个节点 ...
- mysql 子查询 联结 组合查询
子查询 SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id='T ...
- select中DISTINCT的应用-过滤表中重复数据
在表中,一个列可能会包含多个重复值,有时也许希望仅仅列出不同(distinct)的值. DISTINCT 关键词用于返回唯一不同的值. SQL SELECT DISTINCT 语法 SELECT DI ...
- Go语言核心36讲44
今天,我们来讲另一个与I/O操作强相关的代码包bufio.bufio是"buffered I/O"的缩写.顾名思义,这个代码包中的程序实体实现的I/O操作都内置了缓冲区. bufi ...
- Pairs of Numbers 辗转相除
# 42. Pairs of Numbershttps://blog.csdn.net/qq_43521140/article/details/107853492- 出题人:OJ- 标签:[" ...