RDD(弹性分布式数据集)及常用算子
RDD(弹性分布式数据集)及常用算子
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据
处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行
计算的集合。
弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD 封装了计算逻辑,并不保存数据
数据抽象:RDD 是一个抽象类,需要子类具体实现
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在
- 新的 RDD 里面封装计算逻辑
可分区、并行计算
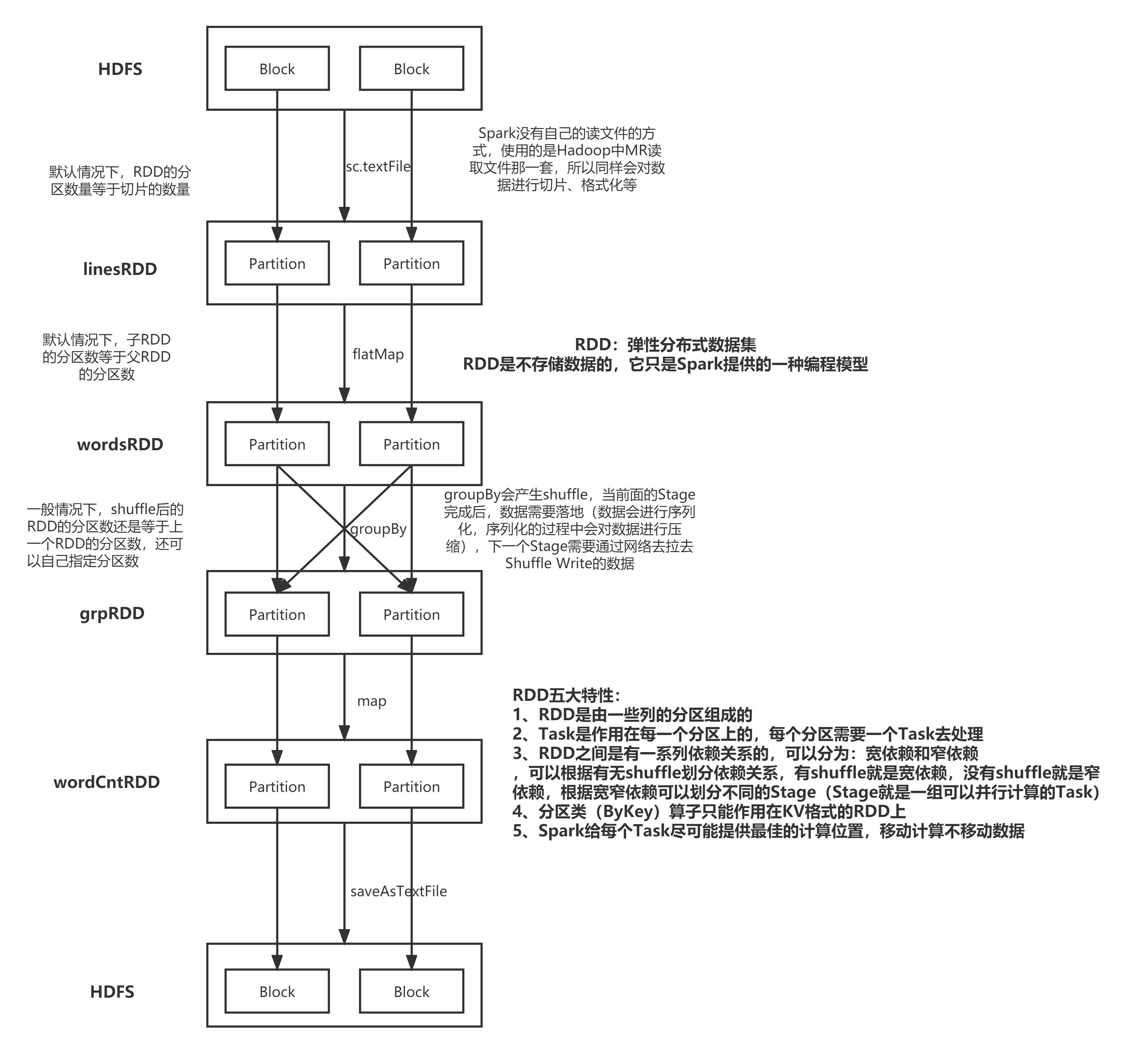
五大特性:
A list of partitions
A function for computing each split
A list of dependencies on other RDDs
Optionally, a Partitioner for key-value RDDs
Optionally, a list of preferred locations to compute each split on
基础编程
RDD 创建
从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD
val conf = new SparkConf()
.setMaster("local")
.setAppName("spark")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(
List(1,2,3,4)
)
val rdd2 = sc.makeRDD(
List(1,2,3,4)
)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sc.stop()
从外部存储(文件)创建 RDD
val conf = new SparkConf()
.setMaster("local")
.setAppName("spark")
val sc = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input")
fileRDD.collect().foreach(println)
sc.stop()
RDD 转换算子
RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value
类型
/**
* 在Spark所有的操作可以分为两类:
* 1、Transformation操作(算子)
* 2、Action操作(算子)
*
* 转换算子是懒执行的,需要由Action算子触发执行
* 每个Action算子会触发一个Job
*
* Spark的程序的层级划分:
* Application --> Job --> Stage --> Task
*
* 怎么区分Transformation算子和Action算子?
* 看算子的返回值是否还是RDD,如果是由一个RDD转换成另一个RDD,则该算子是转换算子
* 如果由一个RDD得到其他类型(非RDD类型或者没有返回值),则该算子是行为算子
*
* 在使用Spark处理数据时可以大体分为三个步骤:
* 1、加载数据并构建成RDD
* 2、对RDD进行各种各样的转换操作,即调用转换算子
* 3、使用Action算子触发Spark任务的执行
*/
map算子
/**
* map算子:转换算子
* 需要接受一个函数f
* 函数f:参数的个数只有一个,类型为RDD中数据的类型 => 返回值类型自己定义
* 可以将函数f作用在RDD中的每一条数据上,需要函数f必须有返回值,最终会得到一个新的RDD
* 传入一条数据得到一条数据
*/
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo03map")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("Spark/data/words.txt")
linesRDD.map(line => {
println("执行了map方法")
line
}).foreach(println)
linesRDD.map(line => {
println("执行了map方法")
line
}).foreach(println)
linesRDD.map(line => {
println("执行了map方法")
line
}).foreach(println)
linesRDD.map(line => {
println("执行了map方法")
line
}).foreach(println)
List(1,2,3,4).map(line=>{
println("List的map方法不需要什么Action算子触发")
line
})
}
flatMap:转换算子
def main(args: Array[String]): Unit = {
/**
* flatMap:转换算子
* 同map算子类似,只不过所接受的函数f需要返回一个可以遍历的类型
* 最终会将函数f的返回值进行展开(扁平化处理),得到一个新的RDD
* 传入一条数据 会得到 多条数据
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo04flatMap")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 另一种构建RDD的方式:基于Scala本地的集合例如List
val intRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
intRDD.foreach(println)
val strRDD: RDD[String] = sc.parallelize(List("java,java,scala", "scala,scala,python", "python,python,python"))
strRDD.flatMap(_.split(",")).foreach(println)
}
filter:转换算子
def main(args: Array[String]): Unit = {
/**
* filter:转换算子
* 用于过滤数据,需要接受一个函数f
* 函数f:参数只有一个,类型为RDD中每一条数据的类型 => 返回值类型必须为Boolean
* 最终会基于函数f返回的Boolean值进行过滤,得到一个新的RDD
* 如果函数f返回的Boolean为true则保留数据
* 如果函数f返回的Boolean为false则过滤数据
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo05filter")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val seqRDD: RDD[Int] = sc.parallelize(1 to 100, 4)
println(seqRDD.getNumPartitions) // getNumPartitions并不是算子,它只是RDD的一个属性
// seqRDD.foreach(println)
// 将奇数过滤出来
seqRDD.filter(i => i % 2 == 1).foreach(println)
// 将偶数过滤出来
seqRDD.filter(i => i % 2 == 0).foreach(println)
}
sample:转换算子
def main(args: Array[String]): Unit = {
/**
* sample:转换算子
* 用于对数据进行取样
* 总共有三个参数:
* withReplacement:有无放回
* fraction:抽样的比例(这个比例并不是精确的,因为抽样是随机的)
* seed:随机数种子
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo06sample")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
stuRDD.sample(withReplacement = false, 0.1).foreach(println)
// 如果想让每次抽样的数据都一样,则可以将seed进行固定
stuRDD.sample(withReplacement = false, 0.01, 10).foreach(println)
}
mapValues:转换算子
def main(args: Array[String]): Unit = {
/**
* mapValues:转换算子
* 同map类似,只不过mapValues需要对KV格式的RDD的Value进行遍历处理
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo07mapValues")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val kvRDD: RDD[(String, Int)] = sc.parallelize(List("k1" -> 1, "k2" -> 2, "k3" -> 3))
// 对每个Key对应的Value进行平方
kvRDD.mapValues(i => i * i).foreach(println)
// 使用map方法实现
kvRDD.map(kv => (kv._1, kv._2 * kv._2)).foreach(println)
}
join:转换算子
def main(args: Array[String]): Unit = {
/**
* join:转换算子
* 需要作用在两个KV格式的RDD上,会将相同的Key的数据关联在一起
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo08join")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 加载学生数据,并转换成KV格式,以ID作为Key,其他数据作为Value
val stuKVRDD: RDD[(String, String)] = sc.textFile("Spark/data/students.txt").map(line => {
val id: String = line.split(",")(0)
// split 指定分割符切分字符串得到Array
// mkString 指定拼接符将Array转换成字符串
val values: String = line.split(",").tail.mkString("|")
(id, values)
})
// 加载分数数据,并转换成KV格式,以ID作为Key,其他数据作为Value
val scoKVRDD: RDD[(String, String)] = sc.textFile("Spark/data/score.txt").map(line => {
val id: String = line.split(",")(0)
val values: String = line.split(",").tail.mkString("|")
(id, values)
})
// join : 内连接
val joinRDD1: RDD[(String, (String, String))] = stuKVRDD.join(scoKVRDD)
// joinRDD1.foreach(println)
// stuKVRDD.leftOuterJoin(scoKVRDD).foreach(println)
// stuKVRDD.rightOuterJoin(scoKVRDD).foreach(println)
stuKVRDD.fullOuterJoin(scoKVRDD).foreach(println)
}
union:转换算子,用于将两个相类型的RDD进行连接
def main(args: Array[String]): Unit = {
// union:转换算子,用于将两个相类型的RDD进行连接
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo09union")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
val sample01RDD: RDD[String] = stuRDD.sample(withReplacement = false, 0.01, 1)
val sample02RDD: RDD[String] = stuRDD.sample(withReplacement = false, 0.01, 1)
println(s"sample01RDD的分区数:${sample01RDD.getNumPartitions}")
println(s"sample02RDD的分区数:${sample02RDD.getNumPartitions}")
// union 操作最终得到的RDD的分区数等于两个RDD分区数之和
println(s"union后的分区数:${sample01RDD.union(sample02RDD).getNumPartitions}")
val intRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
// sample01RDD.union(intRDD) // 两个RDD的类型不一致无法进行union
// union 等同于SQL中的union all
sample01RDD.union(sample02RDD).foreach(println)
// 如果要进行去重 即等同于SQL中的union 则可以在 union后再进行distinct
sample01RDD.union(sample02RDD).distinct().foreach(println)
}
groupBy:按照某个字段进行分组
def main(args: Array[String]): Unit = {
/**
* groupBy:按照某个字段进行分组
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo10groupBy")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
// 统计班级人数
stuRDD.groupBy(s => s.split(",")(4)).map(kv => s"${kv._1},${kv._2.size}").foreach(println)
}
groupByKey:转换算子,需要作用在KV格式的RDD上
def main(args: Array[String]): Unit = {
/**
* groupByKey:转换算子,需要作用在KV格式的RDD上
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo11groupByKey")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
// 使用groupByKey统计班级人数
// 将学生数据变成KV格式的RDD,以班级作为Key,1作为Value
val clazzKVRDD: RDD[(String, Int)] = stuRDD.map(s => (s.split(",")(4), 1))
val grpRDD: RDD[(String, Iterable[Int])] = clazzKVRDD.groupByKey()
grpRDD.map(kv => s"${kv._1},${kv._2.size}").foreach(println)
}
reduceByKey:转换算子,需要作用在KV格式的RDD上,不仅能实现分组,还能实现聚合
def main(args: Array[String]): Unit = {
/**
* reduceByKey:转换算子,需要作用在KV格式的RDD上,不仅能实现分组,还能实现聚合
* 需要接受一个函数f
* 函数f:两个参数,参数的类型同RDD的Value的类型一致,最终需要返回同RDD的Value的类型一致值
* 实际上函数f可以看成一个聚合函数
* 常见的聚合函数(操作):max、min、sum、count、avg
* reduceByKey可以实现Map端的预聚合,类似MR中的Combiner
* 并不是所有的操作都能使用预聚合,例如avg就无法实现
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo11groupByKey")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
// 使用reduceByKey统计班级人数
// 将学生数据变成KV格式的RDD,以班级作为Key,1作为Value
val clazzKVRDD: RDD[(String, Int)] = stuRDD.map(s => (s.split(",")(4), 1))
clazzKVRDD.reduceByKey((i1: Int, i2: Int) => i1 + i2).foreach(println)
// 简写形式
clazzKVRDD.reduceByKey((i1, i2) => i1 + i2).foreach(println)
clazzKVRDD.reduceByKey(_ + _).foreach(println)
}
aggregateByKey:转换算子,可以实现将多个聚合方式放在一起实现,并且也能对Map进行预聚合
def main(args: Array[String]): Unit = {
/**
* aggregateByKey:转换算子,可以实现将多个聚合方式放在一起实现,并且也能对Map进行预聚合
* 可以弥补reduceByKey无法实现avg操作
*
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo13aggregateByKey")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
val ageKVRDD: RDD[(String, Int)] = stuRDD.map(s => (s.split(",")(4), s.split(",")(2).toInt))
val clazzCntKVRDD: RDD[(String, Int)] = stuRDD.map(s => (s.split(",")(4), 1))
// 统计每个班级年龄之和
val ageSumRDD: RDD[(String, Int)] = ageKVRDD.reduceByKey(_ + _)
// 统计每个班级人数
val clazzCntRDD: RDD[(String, Int)] = clazzCntKVRDD.reduceByKey(_ + _)
// 统计每个班级的平均年龄
ageSumRDD.join(clazzCntRDD).map {
case (clazz: String, (ageSum: Int, cnt: Int)) =>
(clazz, ageSum.toDouble / cnt)
}.foreach(println)
/**
* zeroValue:初始化的值,类型自定义,可以是数据容器
* seqOp:在组内(每个分区内部即每个Map任务)进行的操作,相当是Map端的预聚合操作
* combOp:在组之间(每个Reduce任务之间)进行的操作,相当于就是最终每个Reduce的操作
*/
// 使用aggregateByKey统计班级年龄之和
ageKVRDD.aggregateByKey(0)((age1: Int, age2: Int) => {
age1 + age2 // 预聚合
}, (map1AgeSum: Int, map2AgeSum: Int) => {
map1AgeSum + map2AgeSum // 聚合
}).foreach(println)
// 使用aggregateByKey统计班级人数
clazzCntKVRDD.aggregateByKey(0)((c1: Int, c2: Int) => {
c1 + 1 // 预聚合
}, (map1Cnt: Int, map2Cnt: Int) => {
map1Cnt + map2Cnt // 聚合
}).foreach(println)
// 使用aggregateByKey统计班级的平均年龄
ageKVRDD.aggregateByKey((0, 0))((t2: (Int, Int), age: Int) => {
val mapAgeSum: Int = t2._1 + age
val mapCnt: Int = t2._2 + 1
(mapAgeSum, mapCnt)
}, (map1U: (Int, Int), map2U: (Int, Int)) => {
val ageSum: Int = map1U._1 + map2U._1
val cnt: Int = map1U._2 + map2U._2
(ageSum, cnt)
}).map {
case (clazz: String, (sumAge: Int, cnt: Int)) =>
(clazz, sumAge.toDouble / cnt)
}.foreach(println)
}
cartesian:转换算子,可以对两个RDD做笛卡尔积
def main(args: Array[String]): Unit = {
/**
* cartesian:转换算子,可以对两个RDD做笛卡尔积
*
* 当数据重复时 很容易触发笛卡尔积 造成数据的膨胀
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo14cartesian")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val idNameKVRDD: RDD[(String, String)] = sc.parallelize(List(("001", "zs"), ("002", "ls"), ("003", "ww")))
val genderAgeKVRDD: RDD[(String, Int)] = sc.parallelize(List(("男", 25), ("女", 20), ("男", 22)))
idNameKVRDD.cartesian(genderAgeKVRDD).foreach(println)
}
sortBy:转换算子 可以指定一个字段进行排序 默认升序
def main(args: Array[String]): Unit = {
/**
* sortBy:转换算子 可以指定一个字段进行排序 默认升序
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo15sortBy")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val intRDD: RDD[Int] = sc.parallelize(List(1, 3, 6, 5, 2, 4, 6, 8, 9, 7))
intRDD.sortBy(i => i).foreach(println) // 升序
intRDD.sortBy(i => -i).foreach(println) // 降序
intRDD.sortBy(i => i, ascending = false).foreach(println) // 降序
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
// 按照年龄进行降序
stuRDD.sortBy(s => -s.split(",")(2).toInt).foreach(println)
}
常见的Action算子
def main(args: Array[String]): Unit = {
/**
* 常见的Action算子:foreach、take、collect、count、reduce、save相关
* 每个Action算子都会触发一个job
*
*/
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo16Action")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("Spark/data/students.txt")
/**
* foreach:对每条数据进行处理,跟map算子的区别在于,foreach算子没有返回值
*/
stuRDD.foreach(println)
// 将stuRDD中的每条数据保存到MySQL中
/**
* 建表语句:
* CREATE TABLE `stu_rdd` (
* `id` int(10) NOT NULL AUTO_INCREMENT,
* `name` char(5) DEFAULT NULL,
* `age` int(11) DEFAULT NULL,
* `gender` char(2) DEFAULT NULL,
* `clazz` char(4) DEFAULT NULL,
* PRIMARY KEY (`id`)
* ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
// 每一条数据都会创建一次连接,频繁地创建销毁连接效率太低,不合适
// stuRDD.foreach(line => {
// val splits: Array[String] = line.split(",")
// // 1、建立连接
// val conn: Connection = DriverManager.getConnection("jdbc:mysql://master:3306/student?useSSL=false", "root", "123456")
// println("建立了一次连接")
// // 2、创建prepareStatement
// val pSt: PreparedStatement = conn.prepareStatement("insert into stu_rdd(id,name,age,gender,clazz) values(?,?,?,?,?)")
//
// // 3、传入参数
// pSt.setInt(1, splits(0).toInt)
// pSt.setString(2, splits(1))
// pSt.setInt(3, splits(2).toInt)
// pSt.setString(4, splits(3))
// pSt.setString(5, splits(4))
//
// // 4、执行SQL
// pSt.execute()
//
// // 5、关闭连接
// conn.close()
//
// })
/**
* take : Action算子,可以将指定条数的数据转换成Scala中的Array
*
*/
// 这里的foreach是Array的方法,不是算子
stuRDD.take(5).foreach(println)
/**
* collect : Action算子,可以将RDD中所有的数据转换成Scala中的Array
*/
// 这里的foreach是Array的方法,不是算子
stuRDD.collect().foreach(println)
/**
* count : Action算子,统计RDD中数据的条数
*/
println(stuRDD.count())
/**
* reduce : Action算子,将所有的数据作为一组进行聚合操作
*/
// 统计所有学生的年龄之和
println(stuRDD.map(_.split(",")(2).toInt).reduce(_ + _))
/**
* save相关:
* saveAsTextFile、saveAsObjectFile
*/
}
RDD(弹性分布式数据集)及常用算子的更多相关文章
- RDD弹性分布式数据集的基本操作
RDD的中文解释是弹性分布式数据集.构造的数据集的时候用的是List(链表)或者Array数组类型/* 使用makeRDD创建RDD */ /* List */ val rdd01 = sc.make ...
- 2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第二部分是讲RDD.RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外乎创建RDD.转化已有RDD以及 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
- 【Spark】Spark核心之弹性分布式数据集RDD
1. RDD概述 1.1 什么是RDD (1) RDD(Resilient Distributed Dataset)弹性分布式数据集,它是Spark的基本数据抽象,它代表一个不可变.可分区.里面的元素 ...
- 弹性分布式数据集(RDD)
spark围绕弹性分布式数据集(RDD)的概念展开的,RDD是一个可以并行操作的容错集合. 创建RDD的方法: 1.并行化集合(并行化驱动程序中现有的集合) 调用SparkContext的parall ...
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- 弹性分布式数据集RDD概述
[Spark]弹性分布式数据集RDD概述 弹性分布数据集RDD RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作 ...
随机推荐
- redis淘汰策略和过期策略
淘汰策略 https://blog.csdn.net/qq_55961709/article/details/124568269 LRU算法和LFU算法的区别: LRU:最近最少使用,淘汰时间长没有使 ...
- 【Java】学习路径58-TCP聊天-双向发送实现
这一章内容比较复杂(乱) 重点在于解决利用TCP协议实现双向传输. 其余的细节(比如end)等,不需要太在意. 但是我也把折腾经历写出来了,如果大家和我遇到了类似的问题,下文可以提供一个参考. 目标: ...
- rh358 002 fact变量获取 ansible配置网络 service_facts
通过ansible 获取网络信息 1.如何获取fact事实变量 方式1: ansible servera -m servera 方式2: 剧本 [root@workstation ansible]# ...
- 【Maven】Maven的安装和配置
1.Maven的下载 方式一: 官网:Maven – Welcome to Apache Maven 尽量下载3.5版本,我个人3.8版本从来没用配置成功过. 方式二: 我用的是3.5版本,下载3. ...
- 华为云计算灾备产品BCManager 及eBackup的组网方式
BCManager的作用 OceanStor BCManager是面向企业数据中心存储容灾业务的管理软件,实现容灾.双活.两地三中心等容灾环境的管理,具备多种数据库应用与虚拟化环境的容灾管理功能,简单 ...
- ubuntu生成ssh_key
ssh-keygen cat ~/.ssh/id_rsa.pub
- KingbaseES ALTER TABLE 中 USING 子句的用法
using子句用于在修改表字段类型的时候,进行显示的转换类型. 1.建表 create table t(id integer); 2.插入数据 insert into t select generat ...
- Linux_tail总结
tail 命令用法 功能从尾部显示文件若干行 语法: tail [ +/- num ][参数] 文件名 使用tail命令的-f选项可以方便的查阅正在改变的日志文件,tail -f filename会把 ...
- 004-GoingDeeperConvolutions2014(googLeNet)
Going Deeper with Convolutions #paper 1. paper-info 1.1 Metadata Author:: [[Christian Szegedy]], [[W ...
- Windows Server体验之管理
安装了只有命令行界面的Windows Server之后怎么去管理,对于传统的Windows管理员来说确实是比较棘手的.因为没有了图形化的管理界面,需要更多的去依赖Powershell或者cmd命令去做 ...