简单ELK配置实现生产级别的日志采集和查询实践
概述
生产问题
- 集群规模如何规划?
- 集群中节点角色如何规划?
- 集群之脑裂问题如何避免?
- 索引分片如何规划?
- 分片副本如何规划?
集群规划
- 准备条件
- 先估算当前系统的数据量和数据增长趋势情况。
- 现有服务器的配置如CPU、内存、磁盘类型和容量的了解。
- 建议设置
- ElasticSearch推荐的最大JVM堆空间是30~32G,一般可以设置为30Gheap ,大概能处理的数据量 10 T。单个索引数据量建议不超过5T,如果有100T数据量可以部署20个节点。
- 官方建议:节点分片最好按照JVM内存来进行计算,每Gb内存可以为20个分片,假设我们的JVM设置为30G,那么分片数据量最大600个。如果分片数量就是非常多,那么整个集群分片数量最好不要超过10万。
- 集群规划满足当前数据规模+一定估算适量增长规模,后续再按需扩展即可。
- 业务场景
- 用于构建垂直领域的搜索的业务搜索功能,一般的数据量级几千万到数十亿量级,需要部署3-5台ES节点的规模。
- 用于大规模数据的实时OLAP(联机处理分析),经典的如ELK Stack,数据规模可能达到千亿或更多,这是可能需要几十到上百ES节点的规模。
集群角色
ES为了处理大型数据集,实现容错和高可用性,ES可运行多服务器组成分布式环境下也称为集群;集群内的节点的cluster.name相同,形成集群的每个服务器称为节点。ES 为分配不同的任务,定义了以下几个节点角色:Master,Data Node,Coordinating Node,Ingest Node:
主节点(Master Node):主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
- 主节点也可作为数据节点,但稳定的主节点对集群的健康是非常重要的,默认情况下任何一个集群中的节点都有可能被选为主节点,索引数据和搜索查询等操作会占用大量的cpu、内存、io资源,为了确保集群稳定,特别是非小型规模的集群(如10台以内)分离主节点和数据节点是推荐做法。
- 通过配置node.master:true(默认)使节点具有被选举为Master的资格。主节点全局唯一并从有资格成为Master的节点中选举。
# 设置如下,后续所有节点设置可以通过这三个切换配置
node.master: true
node.data: false
node.ingest: false
数据节点(Data Node):主要是存储索引数据的节点,执行数据相关操作:CRUD、搜索,聚合操作等。
- 数据节点对cpu,内存,I/O要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
- 通过配置node.data: true(默认来是一个节点成为数据节点)。
预处理节点(Ingest Node):预处理操作运行在索引文档之前,即写入数据之前,通过事先定义好的一系列processors(处理器)和pipeline(管道),对数据进行某种转换。
- processors和pipeline拦截bulk和index请求,在应用相关操作后将文档传回给index或bulk API。
- 如果想在某个节点上禁用ingest,则可以配置node.ingest: false。
协调节点(Coordinating Node):作为处理客户端请求的节点,只作为接收请求、转发请求到其他节点、汇总各个节点返回数据等功能的节点;客户端请求可以发送到集群的任何节点(每个节点都知道任意文档的位置),节点转发请求并收集数据返回给客户端。
- 协调节点将请求转发给保存数据的数据节点,每个数据节点则先在本地执行请求,并将结果返回给协调节点。协调节点收集完每个节点的数据后将结果合并为单个全局结果,在这过程中的结果收集和排序可能需要很多CPU和内存资源。
- 上述三个节点角色配置为false则为协调节点。
一个节点可以充当一个或多个角色,默认三个角色都有。
- 集群角色建议设置
- 小规模集群,基本不需严格区分。
- 中大规模集群(十个以上节点),应考虑单独的角色充当。特别并发查询量大,查询的合并量大,可以增加独立的协调节点。角色分开的好处是分工明确,互不影响。
脑裂问题
所谓脑裂问题,就是同一个集群中的不同节点,对于集群的状态有了不一样的理解,比如集群中存在两个master,正常情况下我们集群中只能有一个master节点。如果因为网络的故障,导致一个集群被划分成了两片,每片都有多个node,以及一个master,那么集群中就出现了两个master了。但是因为master是集群中非常重要的一个角色,主宰了集群状态的维护,以及shard的分配,因此如果有两个master,可能会导致数据异常
- 建议设置
- 至少配置3个节点为主节点。
- Master 和 dataNode 角色分开,配置奇数个master,如3 、5、7。
- 添加最小数量的主节点配置,在elasticsearch.yml中配置属性:discovery.zen.minimum_master_nodes,这个参数作用是告诉es直到有足够的master候选节点支持时,才可以选举出一个master,否则就不要选举出一个master。官方的推荐值公式为:master候选资格节点数量 / 2 + 1,并在所有有资格成为master的节点都需要加上这个配置。例如在3个节点,三台主节点通过在elasticsearch.yml中配置discovery.zen.minimum_master_nodes: 2,就可以避免脑裂问题的产生。
索引分片
分片数指定后不可变,除非重索引,分片对应的存储实体是索引,分片并不是越多越好,分片多浪费存储空间、占用资源、影响性能。
- 分片过多的影响:
- 每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源。
- 每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降。
- ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差。
- 建议设置
- 每个分片处理数据量建议在30G-50G,如果是商品类搜索场景推荐使用低值30G,然后再对分片数量做合理估算. 例如数据能达到200GB, 推荐分片最多分配5-7分片左右。
- 开始阶段也可先根据节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个。当性能下降时,增加节点,ES会平衡分片的放置。
- 对于基于日期的索引需求, 并且对索引数据的搜索场景非常少. 也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小. 对于这种类似场景, 建议只需要为索引分配1个分片。如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放的日志数据量就很少。
分片副本
副本数是可以随时调整的,副本的作用是备份数据保证高可用数据不丢失,高并发的时候参与数据查询。
- 建议设置
- 一般一个分片有1-2个副本即可保证高可用,副本过多浪费存储空间、占用资源和影响性能。
- 要求集群至少要有3个节点,来分开存放主分片、副本。如发现并发量大时,查询性能会下降,可增加副本数,来提升并发查询能力;新增副本时主节点会自动协调,然后拷贝数据到新增的副本节点。
ElasticSearch部署
部署规划
这里我们部署一个3个节点组成的ES集群,因此也不单独分节点类型部署,三台服务器分别为192.168.5.52 es-node-01、192.168.5.53 es-node-02、192.168.12.27 es-node-03,操作系统版本为CentOS 7.8。
部署方式
官网支持二进制部署,也支持使用Docker和K8S部署方式,这里我们使用二进制部署方式,使用最新版本8.2.3
# 官方下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3-linux-x86_64.tar.gz
# 三台服务器都准备好安装包,进行解压
tar -xvf elasticsearch-8.2.3-linux-x86_64.tar.gz
# 进入ES目录,ES安装包已自带的JDK17,无需单独下载安装JDK
前置配置
在每一台服务器上先做下面环境设置
- 创建用户(基于安全考虑ES默认不能用root启动)
# 创建es用户
useradd es
# 授权es用户
chown -R es:es elasticsearch-8.2.3
- 调整进程最大打开文件数数量
vim /etc/security/limits.conf
# 直接末尾添加限制
es soft nofile 65536
es hard nofile 65536
- 调整进程最大虚拟内存区域数量
echo vm.max_map_count=262144>> /etc/sysctl.conf
sysctl -p
- 防火墙设置,我这里就简单停掉防火墙,线上环境则根据端口进行相应防火墙规则配置
systemctl stop firewalld
systemctl disable firewalld
- 添加服务器名解析
cat > /etc/hosts << EOF
192.168.5.52 es-node-01
192.168.5.53 es-node-02
192.168.12.27 es-node-03
EOF
配置文件
先创建logs和data目录;ES的集群名称配置一样es-cluster,三台ES节点的node.name分别为 es-node-01、es-node-02、es-node-03,network.host配置为各自本机的IP地址。修改配置文件信息为如下vi config/elasticsearch.yml
cluster.name: es-cluster
node.name: es-node-01
node.attr.rack: r1
path.data: /home/commons/elasticsearch-8.2.3/data
path.logs: /home/commons/elasticsearch-8.2.3/logs
network.host: 192.168.5.52
discovery.seed_hosts: ["192.168.5.52", "192.168.5.53", "192.168.12.27"]
cluster.initial_master_nodes: ["192.168.5.52", "192.168.5.53","192.168.12.27"]
xpack.security.enabled: false
xpack.security.transport.ssl.enabled: false
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Type,Content-Length
启动
# 依次启动三台服务器的ES服务
./bin/elasticsearch -d
访问3台服务器9200端口,http://192.168.5.52:9200/ ,如果都看到如下信息则代表ES启动成功
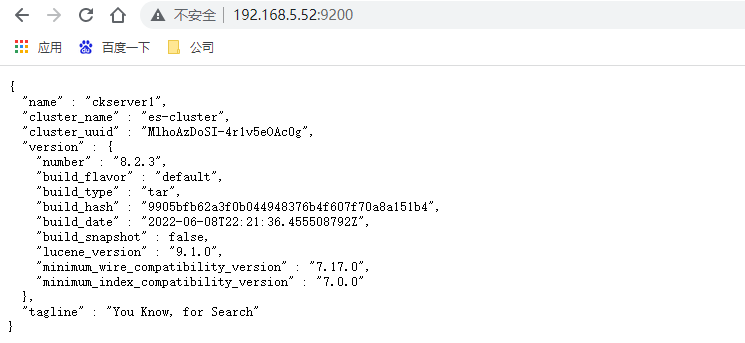
再次查看集群的健康状态,http://192.168.5.52:9200/_cat/health

Kibana部署
下载
Kibana的版本与ES版本保持一致,也是使用最新的8.2.3。我们在192.168.5.52上部署
# Kibana下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.2.3-linux-x86_64.tar.gz
# 解压文件
tar -xvf kibana-8.2.3-linux-x86_64.tar.gz
# 授权
chown -R es:es kibana-8.2.3
# 进入Kibana的目录
cd kibana-8.2.3
配置
vim config/kibana.yml
# 直接再末尾添加以下配置
# 服务器地址
server.host: "0.0.0.0"
# ES服务IP
elasticsearch.hosts: ["http://192.168.5.52:9200/"]
# 设置中文
i18n.locale: "zh-CN"
启动
# 后台启动kibana
nohup ./bin/kibana > logs/kibana.log 2>&1 &
访问Kibana控制台页面,http://192.168.5.52:5601/
部署IK分词器
默认分词器是不支持中文分词,我们可以安装IK分词器实现中文的分词
# IK分词器在GitHub上,下载最新版本8.2.0
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.2.0/elasticsearch-analysis-ik-8.2.0.zip
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.2.0/elasticsearch-analysis-ik-8.2.0.zip
# 解压到elasticsearch目录下的plugins/ik目录
unzip elasticsearch-analysis-ik-8.2.0.zip -d ./plugins/ik
由于ik的版本与ES版本不一致,修改解压目录到ik下的 plugin-descriptor.properties 文件中的
elasticsearch.version=8.2.3

如果版本一致也可以直接在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.2.0/elasticsearch-analysis-ik-8.2.0.zip
ES索引管理
索引声明周期策略
- ES可用于索引日志类数据,在此场景下,数据是源源不断地被写入到索引中。为了使索引的文档不会过多,查询的性能更好,我们希望索引可以根据大小、文档数量或索引已创建时长等指标进行自动回滚,可以自定义将超过一定时间的数据进行自动删除。ES为我们提供了索引的生命周期管理来帮助处理此场景下的问题。
- 索引的生命周期分为四个阶段:HOT->WARM->COLD->DELETE。
- Hot:索引可写入,也可查询。
- Warm:索引不可写入,但可查询。
- Cold:索引不可写入,但很少被查询,查询的慢点也可接受。
- Delete:索引可被安全的删除。
- 索引的每个生命周期阶段都可以配置不同的个阶段都可以配置不同的
转化行为(Action)。下面我们看下几个常用的Action:- Rollover 当写入索引达到了一定的大小,文档数量或创建时间时,Rollover可创建一个新的写入索引,将旧的写入索引的别名去掉,并把别名赋给新的写入索引。所以便可以通过切换
别名控制写入的索引是谁。它可用于Hot阶段。 - Shrink 减少一个索引的主分片数,可用于
Warm阶段。需要注意的是当shink完成后索引名会由原来的<origin-index-name>变为shrink-<origin-index-name>. - Force merge 可触发一个索引分片的segment merge,同时释放掉被删除文档的占用空间。用于
Warm阶段。 - Allocate 可指定一个索引的副本数,用于
warm, cold阶段。
- Rollover 当写入索引达到了一定的大小,文档数量或创建时间时,Rollover可创建一个新的写入索引,将旧的写入索引的别名去掉,并把别名赋给新的写入索引。所以便可以通过切换
- HOT为必须的阶段外,其他为非必须阶段,可以任意选择配置。在日志类场景下不需要WARN和COLD阶段,下文只配置了HOT与DELETE阶段。
设置索引生命周期策略和索引模板即可以通过Kibana可视化界面设置也可以通过ES提供的Rest API接口进行设置,我们先通过Kibaba页面来配置,首先通过点击左侧菜单的Management-Stack Management,然后左侧菜单再点击索引生命周期策略
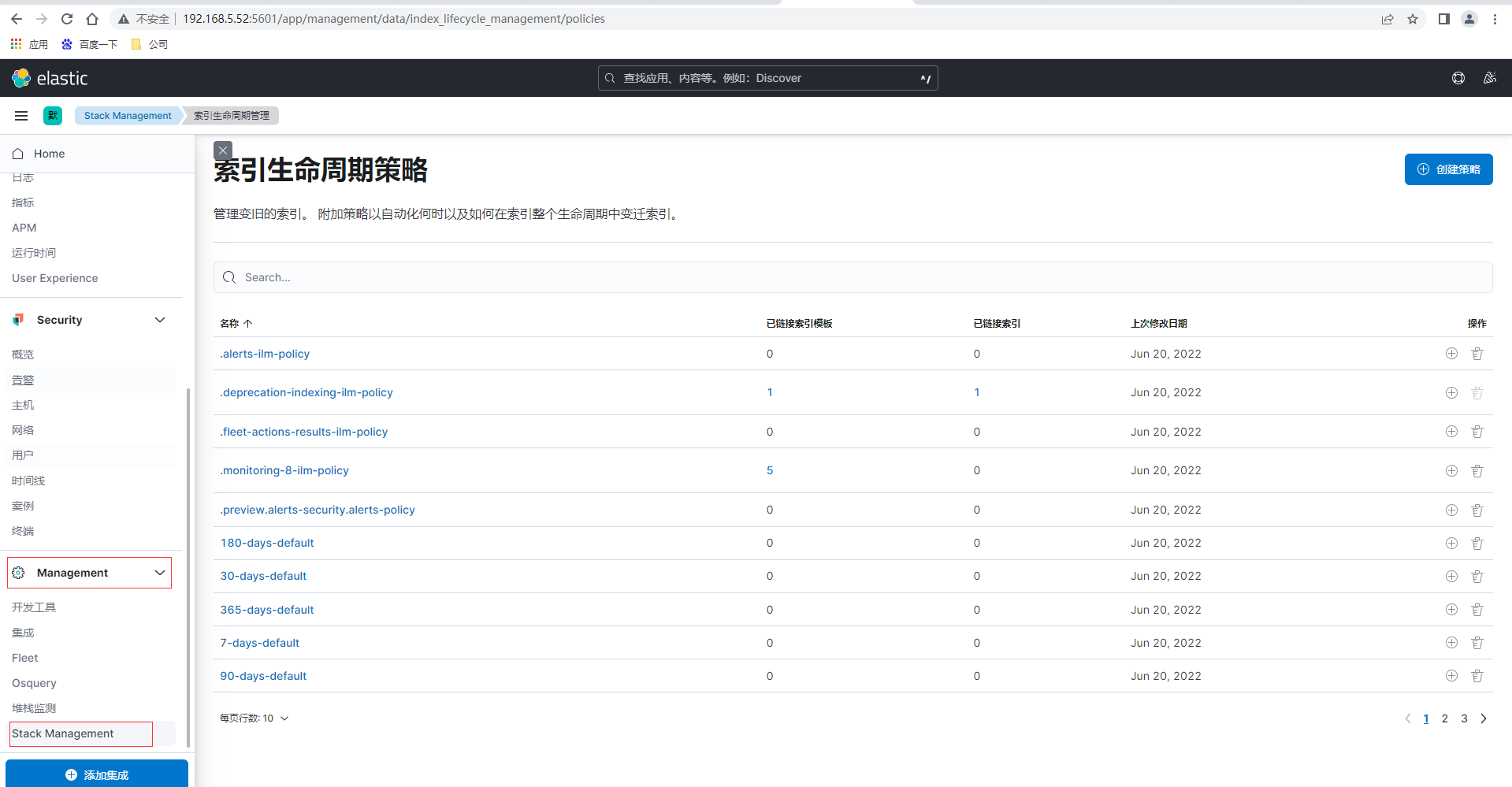
点击索引生命周期策略页面的右上角创建策略
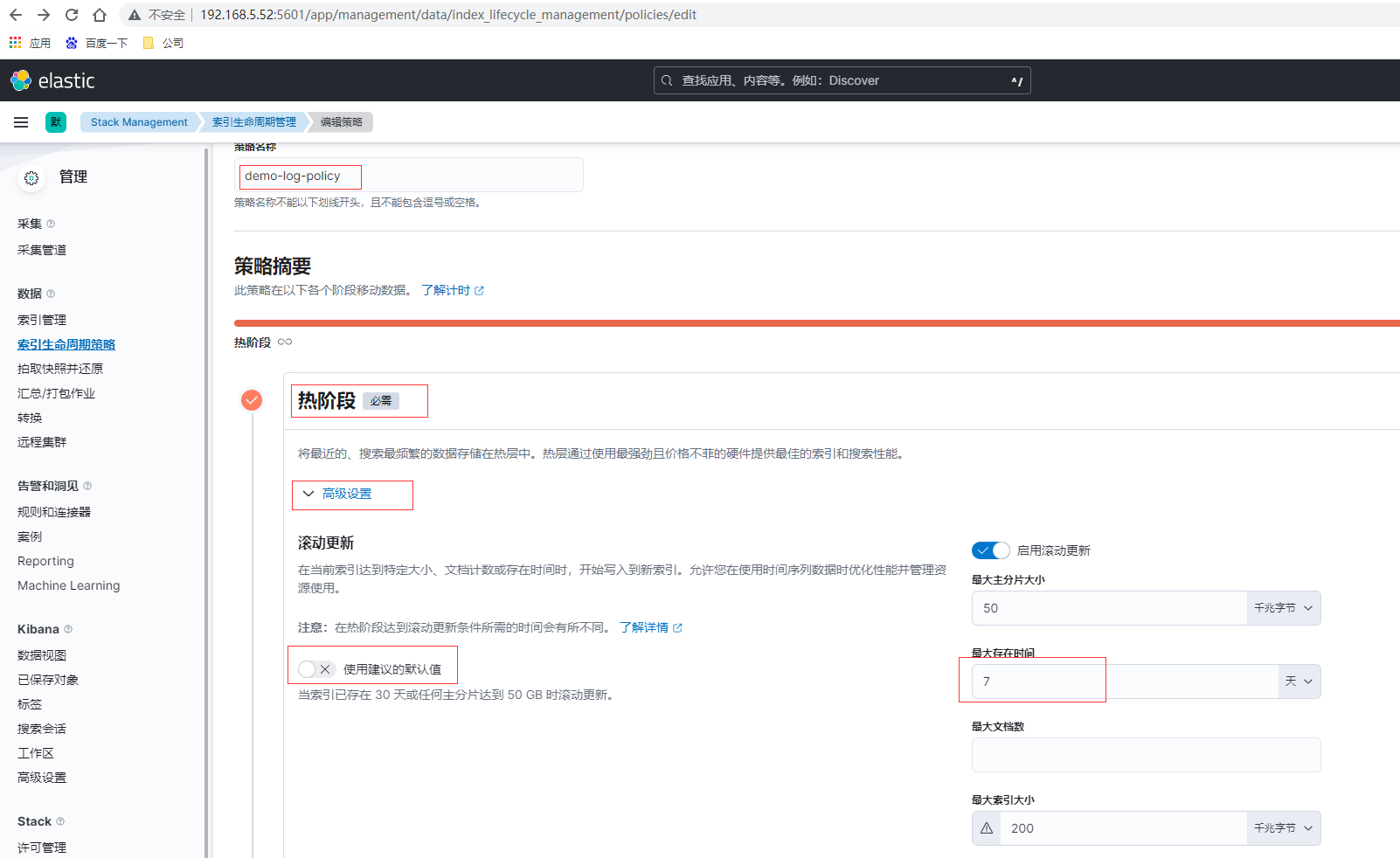
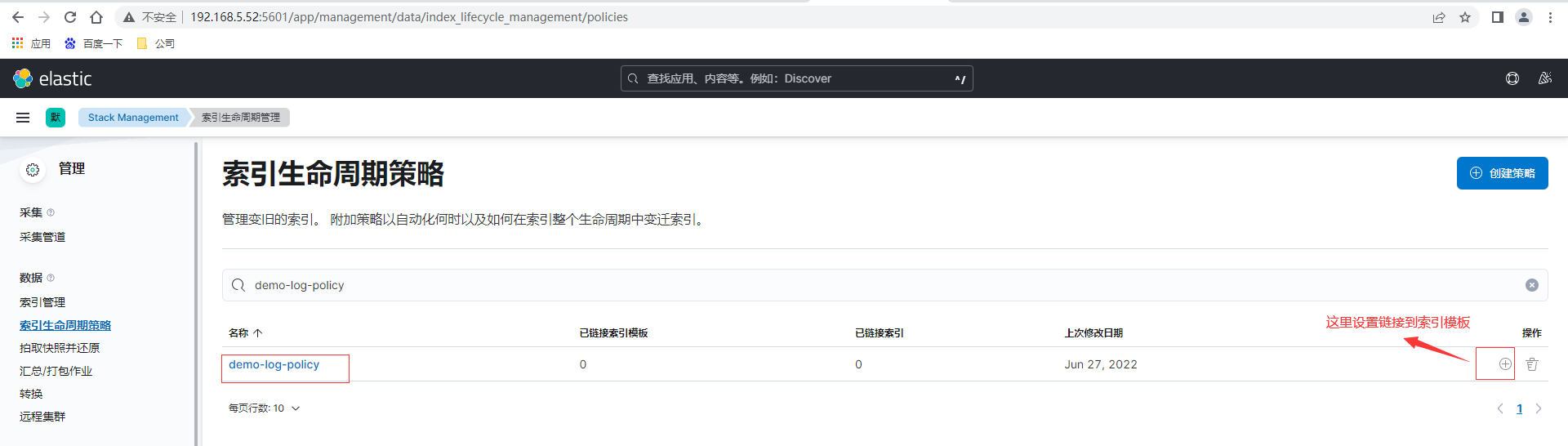
这里如果是测试可以将存在时间设置为分钟级别,便于观察,创建完毕后查看刚创建的demo-log-policy
也可以通过ES提供的Rest API接口进行设置,通过Kibana点击左侧菜单的Management-开发工具进入控制台tab页,然后输入如下生命周期设置策略,返回结果
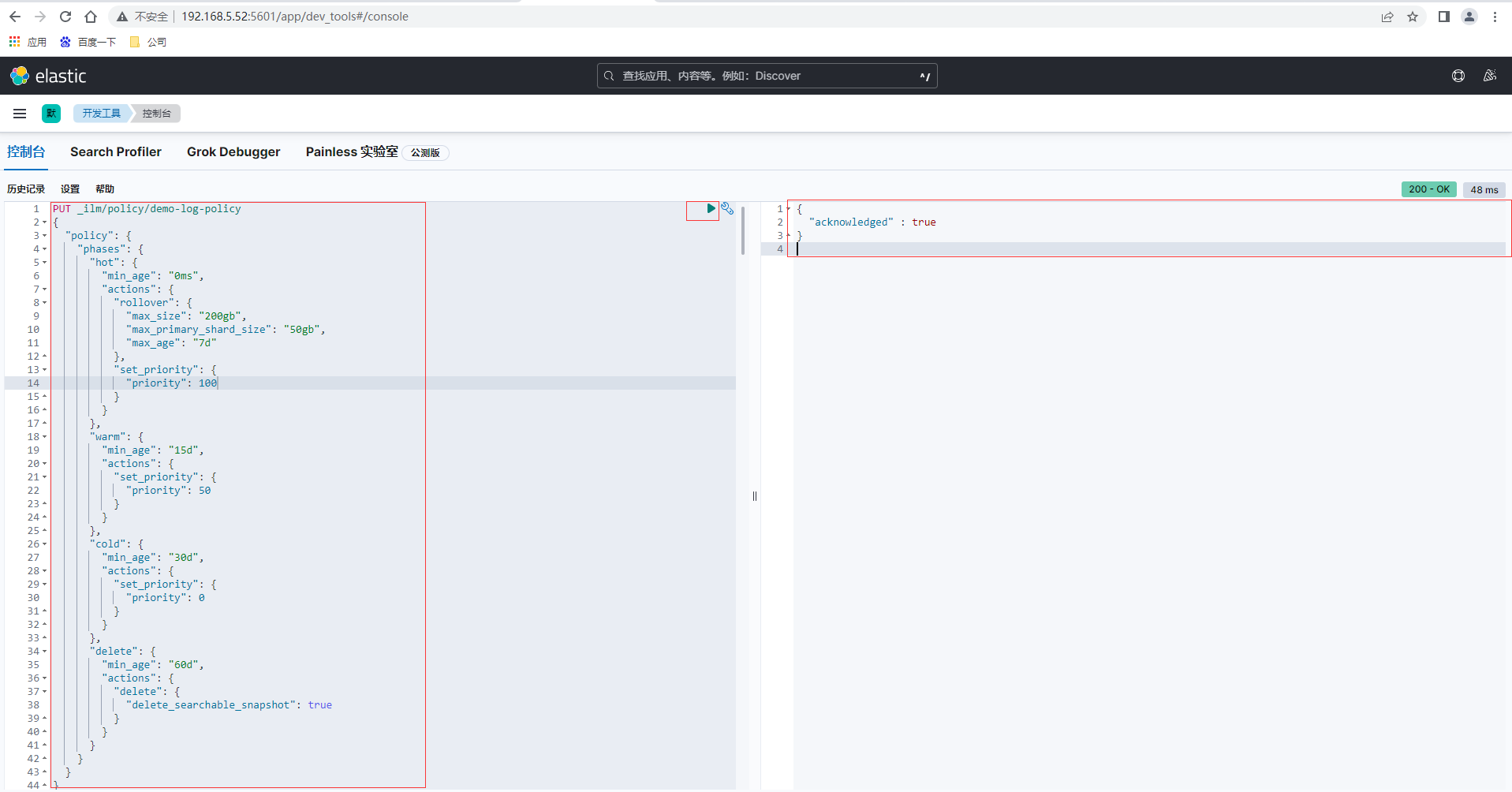
PUT _ilm/policy/demo-log-policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_size": "200gb",
"max_primary_shard_size": "50gb",
"max_age": "7d"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "15d",
"actions": {
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
索引模板
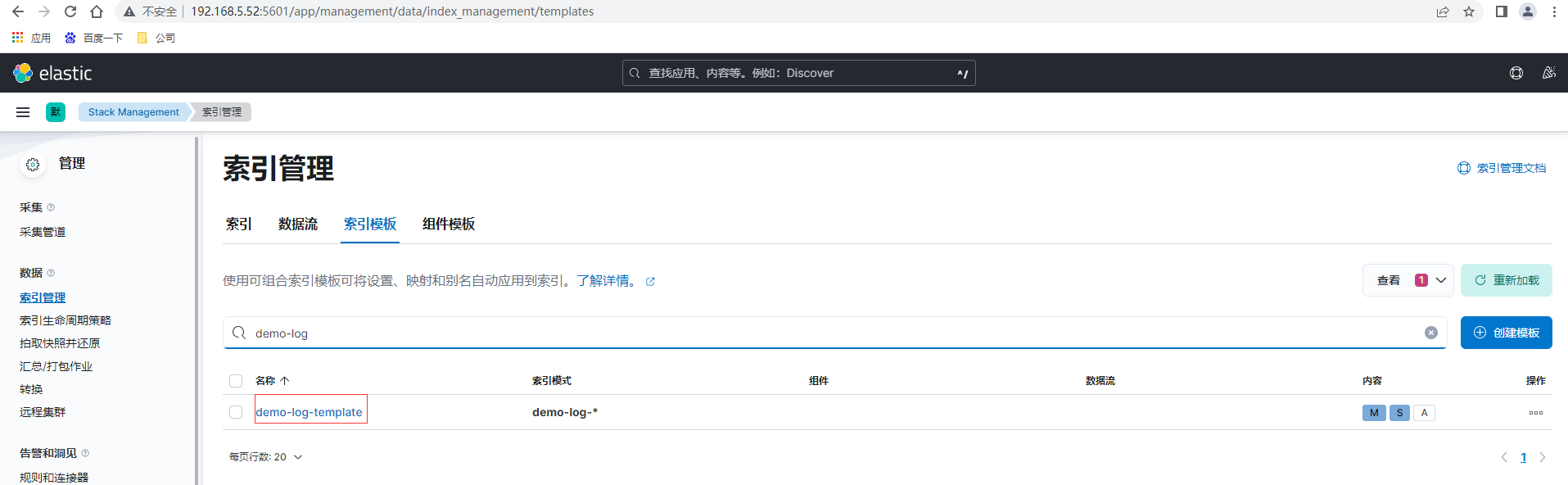
点击索引管理-索引模板,创建模板
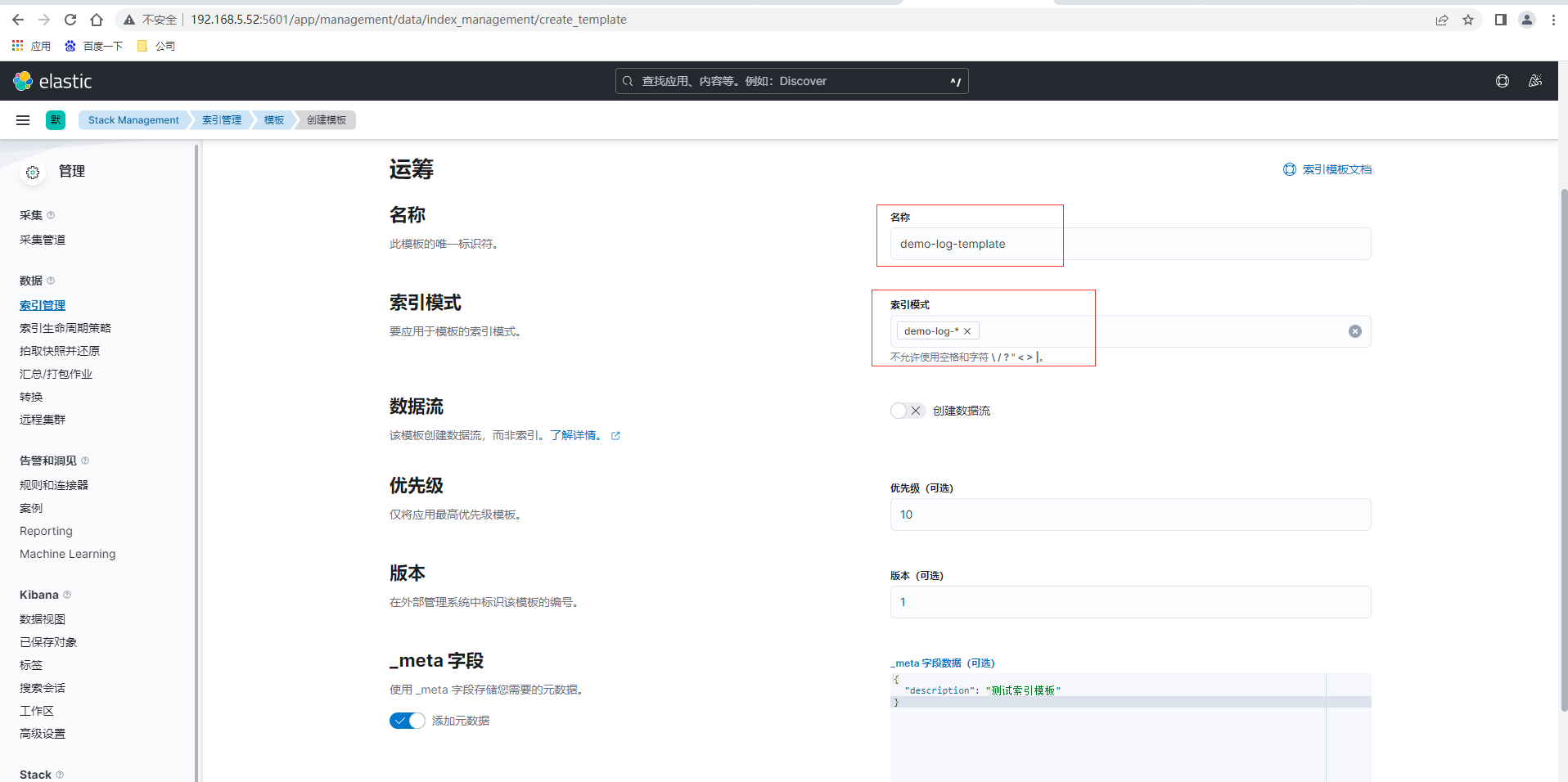
验证模板后提交查看已创建的模板,创建完成后可以通过在索引声明周期绑定模板,也可以直接在模板里增加绑定语句设置
当然也可以通过ES提供的Rest API接口进行设置
PUT _index_template/demo-log-template
{
"version": 1,
"priority": 10,
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "demo-log-policy",
"rollover_alias": "demo-log"
},
"number_of_shards": "2",
"number_of_replicas": "1"
}
},
"mappings": {
"_source": {
"excludes": [],
"includes": [],
"enabled": true
},
"_routing": {
"required": false
},
"dynamic": true,
"numeric_detection": false,
"date_detection": true,
"dynamic_date_formats": [
"strict_date_optional_time",
"yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"
],
"dynamic_templates": []
}
},
"index_patterns": [
"demo-log-*"
],
"_meta": {
"description": "测试索引模板"
}
}
索引
先创建初始索引
PUT demo-log-000001
{
"aliases": {
"demo-log": {
"is_write_index": true
}
}
}
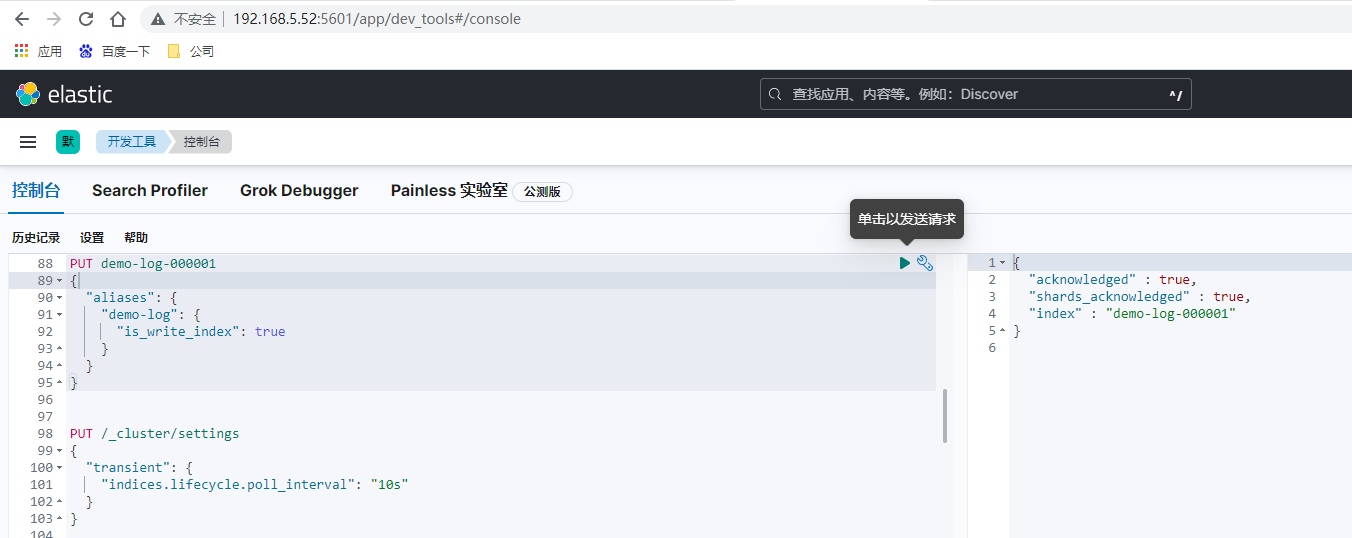
如果前面索引生命周期模板的各个周期保留时间设置较短如为分钟,手动提交日志到索引和查看,需要实时查看其效果则可以增加如下设置和演示操作
PUT /_cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "10s"
}
}
POST /demo-log/_doc
{
"message":"world2"
}
GET /demo-log/_search
{
"query": {
"match_all": {}
}
}
Logstash
修改配置和启动,vi config/logstash.conf
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://192.168.5.52:9200","http://192.168.5.53:9200","http://192.168.12.27:9200"]
index => "%{app_id}"
}
}
FileBeat
FileBeat和Logstash部署和配置可以详细查看前面的文章《数仓选型必列入考虑的OLAP列式数据库ClickHouse(中)》,修改配置和启动, parsers.multiline实现多行合并一行配置,比如Java异常堆栈日志打印合并在一行。
vi filebeat.yml
filebeat.inputs:
- type: filestream
id: demo-log
enabled: true
paths:
# Filebeat处理文件的绝对路径
- /home/itxs/demo/logs/*.log
# 使用 fields 模块添加字段
fields:
app_id: demo-log
# 将新增的字段放在顶级
fields_under_root: true
parsers:
- multiline:
type: pattern
pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
processors:
- drop_fields:
fields: ["log","input","agent","ecs"]
output.logstash:
hosts: ["192.168.12.28:5044"]
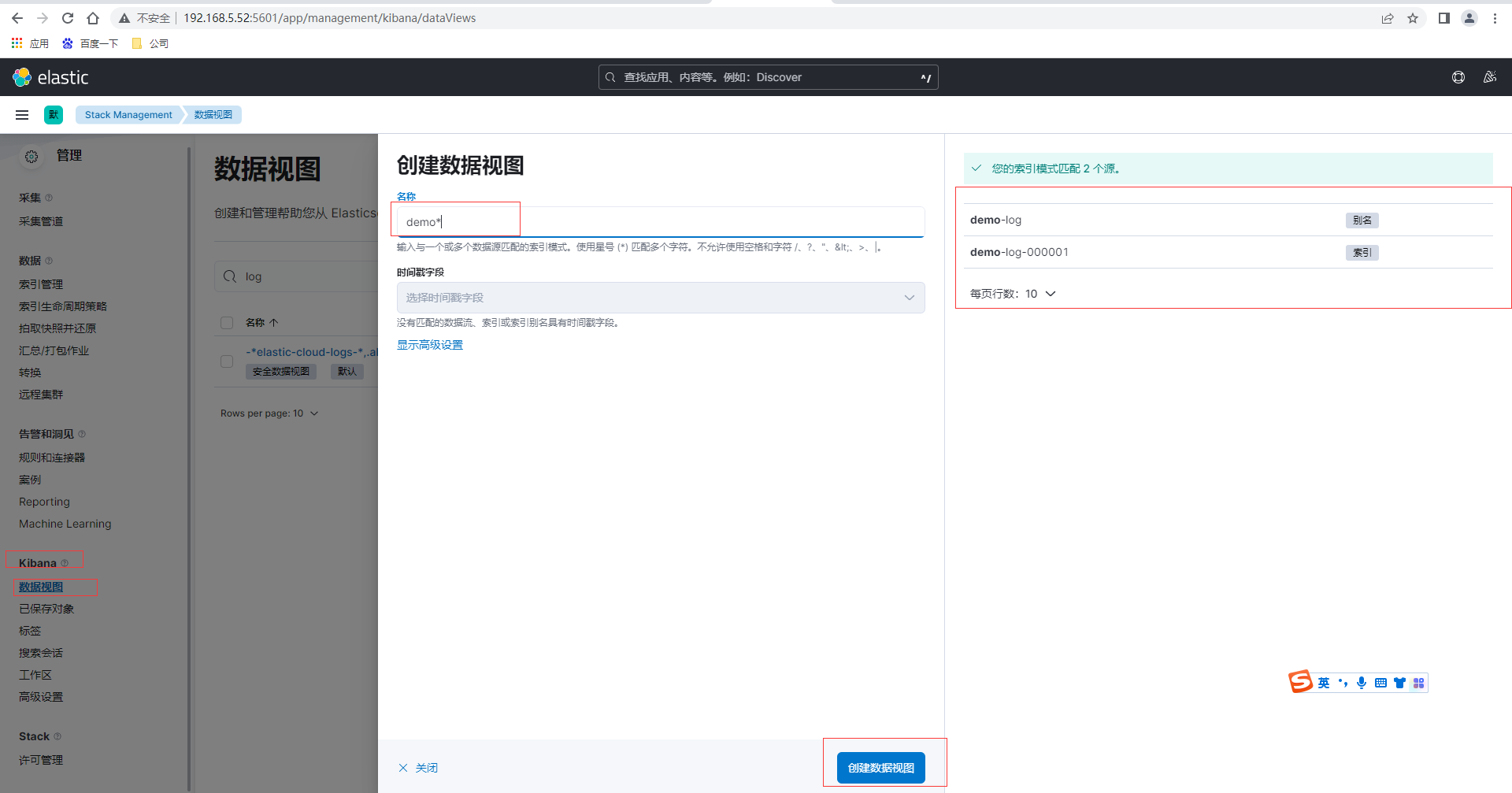
采集/home/itxs/demo/logs/目录的数据,由App产生日志,然后通过Kibana的数据视图-创建数据视图,匹配我们前面创建的索引和别名
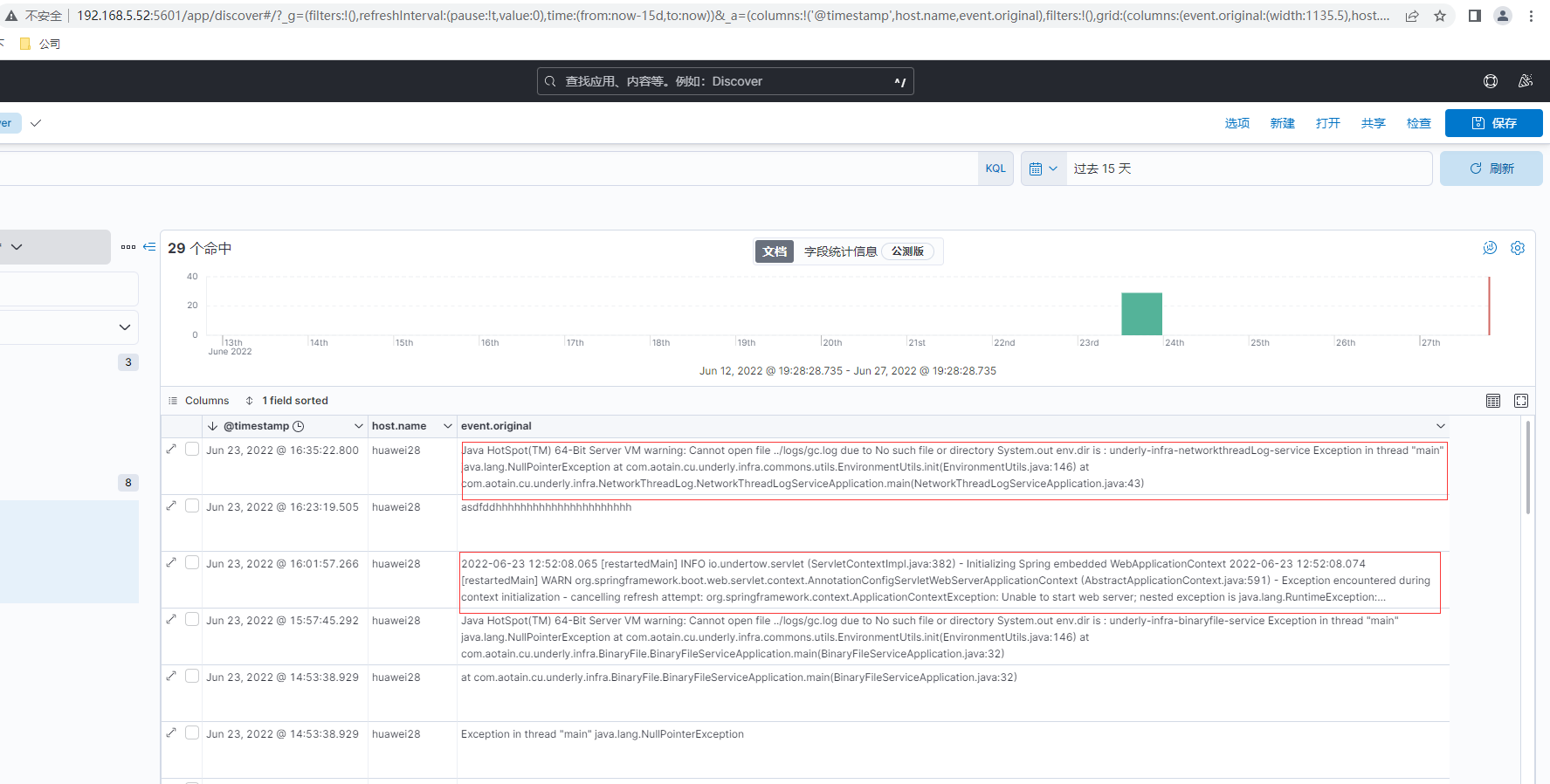
最后通过Kibana左侧菜单的Analytics-Discover选择demo视图然后可以搜索日志,最后日志查询结果如下
**本人博客网站 **IT小神 www.itxiaoshen.com
简单ELK配置实现生产级别的日志采集和查询实践的更多相关文章
- ELK太重?试试KFC日志采集
写在前面 ELK三剑客(ElasticSearch,Logstash,Kibana)基本上可以满足日志采集.信息处理.统计分析.可视化报表等一些日志分析的工作,但是对我们来说--太重了,并且技术栈不是 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 使用日志服务进行Kubernetes日志采集
阿里云容器服务Kubernetes集群集成了日志服务(SLS),您可在创建集群时启用日志服务,快速采集Kubernetes 集群的容器日志,包括容器的标准输出以及容器内的文本文件. 新建 Kubern ...
- Docker笔记(十三):容器日志采集实践
日志是服务运行过程中的一个关键环节,借助日志,我们可以排查定位问题,也可以借助集中化的日志管理平台(如ELK)来做一些必要的数据统计分析.在Docker环境中,日志的采集比传统环境更为复杂,因此了解D ...
- flink---实时项目--day02-----1. 解析参数工具类 2. Flink工具类封装 3. 日志采集架构图 4. 测流输出 5. 将kafka中数据写入HDFS 6 KafkaProducer的使用 7 练习
1. 解析参数工具类(ParameterTool) 该类提供了从不同数据源读取和解析程序参数的简单实用方法,其解析args时,只能支持单只参数. 用来解析main方法传入参数的工具类 public c ...
- 日志分析工具ELK配置详解
日志分析工具ELK配置详解 一.ELK介绍 1.1 elasticsearch 1.1.1 elasticsearch介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分 ...
- NET Core微服务之路:简单谈谈对ELK,Splunk,Exceptionless统一日志收集中心的心得体会
前言 日志,一直以来都是开发人员和运维人员最关心的问题.开发人员可通过日志记录来协助问题定位,运维人员可通过日志发现系统隐患,故障等定位问题.如果你的系统中没有日志,就像一个断了线的风筝,你永远不知道 ...
- Log4j按级别输出日志到不同文件配置分析 (转:projava)
关于LOG4J 按照级别输出日志,并按照级别输出到不同文件中的说法有很多, 网上贴的最多的log4j.properties的设置是这样的 log4j.rootLogger=info,stdout,in ...
- Log4j按级别输出日志到不同文件配置分析
关于LOG4J 按照级别输出日志,并按照级别输出到不同文件中的说法有很多, 网上贴的最多的log4j.properties的设置是这样的 log4j.rootLogger=info,stdout,in ...
随机推荐
- this的指向问题及改变this指向
概念: this是运行环境下的一个系统变量, 由于this在不同的执行环境下有不同的值, 所以在使用this时,多加注意 (使用this之前,先打印) 1,在全局作用域下,this默认指向window ...
- java class 文件格式解析
前言 大约5年前,想研究javaassistant,cglib等字节码操作的相关类库,来对class进行增强,当要到要操作字节码的时候,发现无法继续下去了,只能放弃. 学习jvm字码,需要理解clas ...
- linux脚本执行jar包运行
以下为linux下运行jar包的脚本(只需替换jar包名称): #!/bin/bash #这里可替换为你自己的执行程序,其他代码无需更改 APP_NAME=ruoyi-admin.jar cd `di ...
- Python 函数进阶-高阶函数
高阶函数 什么是高阶函数 高阶函数就是能够把函数当成参数传递的函数就是高阶函数,换句话说如果一个函数的参数是函数,那么这个函数就是一个高阶函数. 高阶函数可以是你使用def关键字自定义的函数,也有Py ...
- 忘记VMware vcenter的Administrator@vsphere.local密码
忘记VMware vcenter的Administrator@vsphere.local密码的解决办法一. 重置密码:ssh root@192.168.230.100Connecting to 192 ...
- 新华三Gen10服务器ILO 5 安装中文语言包
ILO 5 安装中文语言包 在官网下载语言包文件,并解压 选择firmware&OS software,点击右侧的update firmware 选择本地文件,浏览到语言包里面的lpk文件,点 ...
- typeScript类型总结
1.对象类型 {} 用来指定对象中可以包含哪些属性,在属性名后加?表示属性是可选的 语法:{属性名:属性值类型,属性名:属性值类型} 示例: let a:{name:string,age?:numbe ...
- ansible的介绍与安装
ansible是在远程主机上批量执行命令或者脚本的一个工具 epel源:一个第三方的yum源(阿里巴巴开源镜像站:https://opsx.alibaba.com/mirror?lang=zh-CN) ...
- 用crash tool观察ARM64 Linux地址转换
初学者学习Linux系统地址转换时,如果只是学习理论,又或者研读代码,那可能感觉比较枯燥.此时如果可以利用某些工具实际观察一下地址转换的过程,那可能会给枯燥的内核学习带来些微的乐趣.crash too ...
- Golang:将日志以Json格式输出到Kafka
在上一篇文章中我实现了一个支持Debug.Info.Error等多个级别的日志库,并将日志写到了磁盘文件中,代码比较简单,适合练手.有兴趣的可以通过这个链接前往:https://github.com/ ...