使用.NET7和C#11打造最快的序列化程序-以MemoryPack为例
译者注
本文是一篇不可多得的好文,MemoryPack 的作者 neuecc 大佬通过本文解释了他是如何将序列化程序性能提升到极致的;其中从很多方面(可变长度、字符串、集合等)解释了一些性能优化的技巧,值得每一个开发人员学习,特别是框架的开发人员的学习,一定能让大家获益匪浅。
简介
我发布了一个名为MemoryPack 的新序列化程序,这是一种特定于 C# 的新序列化程序,其执行速度比其他序列化程序快得多。
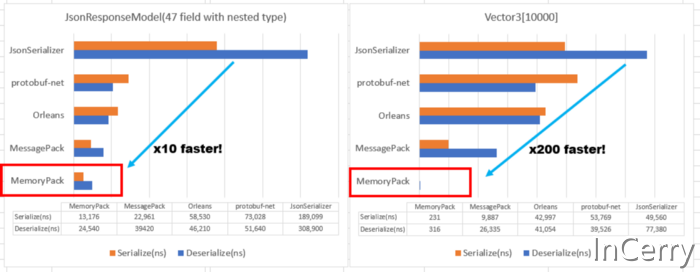
与MessagePack for C# (一个快速的二进制序列化程序)相比标准对象的序列化库性能快几倍,当数据最优时,性能甚至快 50~100 倍。最好的支持是.NET 7,但现在支持.NET Standard 2.1(.NET 5,6),Unity 甚至 TypeScript。它还支持多态性(Union),完整版本容错,循环引用和最新的现代 I/O API(IBufferWriter,ReadOnlySeqeunce,Pipelines)。
序列化程序的性能基于“数据格式规范”和“每种语言的实现”。例如,虽然二进制格式通常比文本格式(如 JSON)具有优势,但 JSON 序列化程序可能比二进制序列化程序更快(如Utf8Json 所示)。那么最快的序列化程序是什么?当你同时了解规范和实现时,真正最快的序列化程序就诞生了。
多年来,我一直在开发和维护 MessagePack for C#,而 MessagePack for C# 是 .NET 世界中非常成功的序列化程序,拥有超过 4000 颗 GitHub 星。它也已被微软标准产品采用,如 Visual Studio 2022,SignalR MessagePack Hub协议和 Blazor Server 协议(blazorpack)。
在过去的 5 年里,我还处理了近 1000 个问题。自 5 年前以来,我一直在使用 Roslyn 的代码生成器进行 AOT 支持,并对其进行了演示,尤其是在 Unity、AOT 环境 (IL2CPP) 以及许多使用它的 Unity 手机游戏中。
除了 MessagePack for C# 之外,我还创建了ZeroFormatter(自己的格式)和Utf8Json(JSON)等序列化程序,它们获得了许多 GitHub Star,所以我对不同格式的性能特征有深刻的理解。此外,我还参与了 RPC 框架MagicOnion,内存数据库MasterMemory,PubSub 客户端AlterNats以及几个游戏的客户端(Unity)/服务器实现的创建。
MemoryPack 的目标是成为终极的快速,实用和多功能的序列化程序。我想我做到了。
增量源生成器
MemoryPack 完全采用 .NET 6 中增强的增量源生成器。在用法方面,它与 C# 版 MessagePack 没有太大区别,只是将目标类型更改为部分类型。
using MemoryPack;// Source Generator makes serialize/deserialize code[MemoryPackable]public partial class Person{public int Age { get; set; }public string Name { get; set; }}// usagevar v = new Person { Age = 40, Name = "John" };var bin = MemoryPackSerializer.Serialize(v);var val = MemoryPackSerializer.Deserialize<Person>(bin);
源生成器的最大优点是它对 AOT 友好,无需反射即可为每种类型自动生成优化的序列化程序代码,而无需由 IL.Emit 动态生成代码,这是常规做法。这使得使用 Unity 的 IL2CPP 等可以安全地工作。初始启动速度也很快。
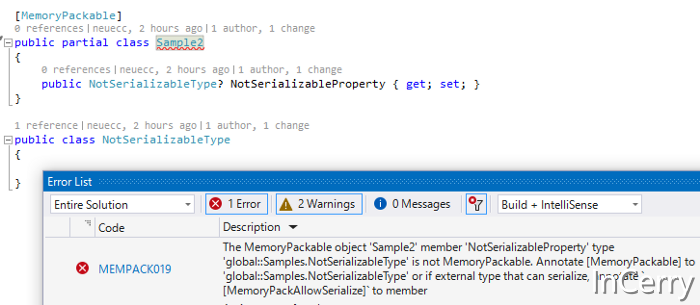
源生成器还用作分析器,因此它可以通过在编辑时发出编译错误来检测它是否可安全序列化。
请注意,由于语言/编译器版本原因,Unity 版本使用旧的源生成器而不是增量源生成器。
C# 的二进制规范
MemoryPack 的标语是“零编码”。这不是一个特例,例如,Rust 的主要二进制序列化器bincode 也有类似的规范。FlatBuffers还可以读取和写入类似于内存数据的内容,而无需解析实现。
但是,与 FlatBuffers 和其他产品不同,MemoryPack 是一种通用的序列化程序,不需要特殊类型,并且可以针对 POCO 进行序列化/反序列化。它还具有对架构成员添加和多态性支持 (Union) 的高容忍度的版本控制。
可变编码与固定编码
Int32 是 4 个字节,但在 JSON 中,例如,数字被编码为字符串,可变长度编码为 1~11 个字节(例如,1 或 -2147483648)。许多二进制格式还具有 1 到 5 字节的可变长度编码规范以节省大小。例如,Protocol-buffers 数字类型具有可变长度整数编码,该编码以 7 位存储值,并以 1 位 (varint) 存储是否存在以下的标志。这意味着数字越小,所需的字节就越少。相反,在最坏的情况下,该数字将增长到 5 个字节,大于原来的 4 个字节。MessagePack和CBOR类似地使用可变长度编码进行处理,小数字最小为 1 字节,大数字最大为 5 字节。
这意味着 varint 运行比固定长度情况额外的处理。让我们在具体代码中比较两者。可变长度是 protobuf 中使用的可变 + 之字折线编码(负数和正数组合)。
// Fixed encodingstatic void WriteFixedInt32(Span<byte> buffer, int value){ref byte p = ref MemoryMarshal.GetReference(buffer);Unsafe.WriteUnaligned(ref p, value);}// Varint encodingstatic void WriteVarInt32(Span<byte> buffer, int value) => WriteVarInt64(buffer, (long)value);static void WriteVarInt64(Span<byte> buffer, long value){ref byte p = ref MemoryMarshal.GetReference(buffer);ulong n = (ulong)((value << 1) ^ (value >> 63));while ((n & ~0x7FUL) != 0){Unsafe.WriteUnaligned(ref p, (byte)((n & 0x7f) | 0x80));p = ref Unsafe.Add(ref p, 1);n >>= 7;}Unsafe.WriteUnaligned(ref p, (byte)n);}
换句话说,固定长度是按原样写出 C# 内存(零编码),很明显,固定长度更快。
当应用于数组时,这一点更加明显。
// https://sharplab.io/Inspect.Heap(new int[]{ 1, 2, 3, 4, 5 });

在 C# 中的结构数组中,数据按顺序排列。如果结构没有引用类型(非托管类型)则数据在内存中完全对齐;让我们将代码中的序列化过程与 MessagePack 和 MemoryPack 进行比较。
// Fixed-length(MemoryPack)void Serialize(int[] value){// Size can be calculated and allocate in advancevar size = (sizeof(int) * value.Length) + 4;EnsureCapacity(size);// MemoryCopy onceMemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);}// Variable-length(MessagePack)合void Serialize(int[] value){foreach (var item in value){// Unknown size, so check size each timesEnsureCapacity(); // if (buffer.Length < writeLength) Resize();// Variable length encoding per elementWriteVarInt32(item);}}
在固定长度的情况下,可以消除许多方法调用并且只有一个内存副本。
C# 中的数组不仅是像 int 这样的基元类型,对于具有多个基元的结构也是如此,例如,具有 (float x, float y, float z) 的 Vector3 数组将具有以下内存布局。

浮点数(4 字节)是 MessagePack 中 5 个字节的固定长度。额外的 1 个字节以标识符为前缀,指示值的类型(整数、浮点数、字符串...)。具体来说,[0xca, x, x, x, x, x, x].MemoryPack 格式没有标识符,因此 4 个字节按原样写入。
以 Vector3[10000] 为例,它比基准测试好 50 倍。
// these fields exists in type// byte[] buffer// int offsetvoid SerializeMemoryPack(Vector3[] value){// only do copy oncevar size = Unsafe.SizeOf<Vector3>() * value.Length;if ((buffer.Length - offset) < size){Array.Resize(ref buffer, buffer.Length * 2);}MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer.AsSpan(0, offset))}void SerializeMessagePack(Vector3[] value){// Repeat for array length x number of fieldsforeach (var item in value){// X{// EnsureCapacity// (Actually, create buffer-linked-list with bufferWriter.Advance, not Resize)if ((buffer.Length - offset) < 5){Array.Resize(ref buffer, buffer.Length * 2);}var p = MemoryMarshal.GetArrayDataReference(buffer);Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.X);offset += 5;}// Y{if ((buffer.Length - offset) < 5){Array.Resize(ref buffer, buffer.Length * 2);}var p = MemoryMarshal.GetArrayDataReference(buffer);Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.Y);offset += 5;}// Z{if ((buffer.Length - offset) < 5){Array.Resize(ref buffer, buffer.Length * 2);}var p = MemoryMarshal.GetArrayDataReference(buffer);Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.Z);offset += 5;}}}
使用 MessagePack,它需要 30000 次方法调用。在该方法中,它会检查是否有足够的内存进行写入,并在每次完成写入时添加偏移量。
使用 MemoryPack,只有一个内存副本。这实际上会使处理时间改变一个数量级,这也是本文开头图中 50 倍~100 倍加速的原因。
当然,反序列化过程也是单个副本。
// Deserialize of MemoryPack, only copyVector3[] DeserializeMemoryPack(ReadOnlySpan<byte> buffer, int size){var dest = new Vector3[size];MemoryMarshal.Cast<byte, Vector3>(buffer).CopyTo(dest);return dest;}// Require read float many times in loopVector3[] DeserializeMessagePack(ReadOnlySpan<byte> buffer, int size){var dest = new Vector3[size];for (int i = 0; i < size; i++){var x = ReadSingle(buffer);buffer = buffer.Slice(5);var y = ReadSingle(buffer);buffer = buffer.Slice(5);var z = ReadSingle(buffer);buffer = buffer.Slice(5);dest[i] = new Vector3(x, y, z);}return dest;}
这是 MessagePack 格式本身的限制,只要遵循规范,速度的巨大差异就无法以任何方式逆转。但是,MessagePack 有一个名为“ext 格式系列”的规范,它允许将这些数组作为其自身规范的一部分进行特殊处理。事实上,MessagePack for C# 有一个特殊的 Unity 扩展选项,称为 UnsafeBlitResolver,它可以执行上述操作。
但是,大多数人可能不会使用它,也没有人会使用会使 MessagePack 不兼容的专有选项。
因此,对于 MemoryPack,我想要一个默认情况下能提供最佳性能的规范 C#。
字符串优化
MemoryPack 有两个字符串规范:UTF8 或 UTF16。由于 C# 字符串是 UTF16,因此将其序列化为 UTF16 可以节省编码/解码为 UTF8 的成本。
void EncodeUtf16(string value){var size = value.Length * 2;EnsureCapacity(size);// Span<char> -> Span<byte> -> CopyMemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);}string DecodeUtf16(ReadOnlySpan<byte> buffer, int length){ReadOnlySpan<char> src = MemoryMarshal.Cast<byte, char>(buffer).Slice(0, length);return new string(src);}
但是,MemoryPack 默认为 UTF8。这是因为有效负载大小问题;对于 UTF16,ASCII 字符的大小将是原来的两倍,因此选择了 UTF8。
但是,即使使用 UTF8,MemoryPack 也具有其他序列化程序所没有的一些优化。
// fastvoid WriteUtf8MemoryPack(string value){var source = value.AsSpan();var maxByteCount = (source.Length + 1) * 3;EnsureCapacity(maxByteCount);Utf8.FromUtf16(source, dest, out var _, out var bytesWritten, replaceInvalidSequences: false);}// slowvoid WriteUtf8StandardSerializer(string value){var maxByteCount = Encoding.UTF8.GetByteCount(value);EnsureCapacity(maxByteCount);Encoding.UTF8.GetBytes(value, dest);}
var bytes = Encoding.UTF8.GetBytes(value)是绝对的不允许的,字符串写入中不允许 byte[] 分配。许多序列化程序使用 Encoding.UTF8.GetByteCount,但也应该避免它,因为 UTF8 是一种可变长度编码,GetByteCount 完全遍历字符串以计算确切的编码后大小。也就是说,GetByteCount -> GetBytes 遍历字符串两次。
通常,允许序列化程序保留大量缓冲区。因此,MemoryPack 分配三倍的字符串长度,这是 UTF8 编码的最坏情况,以避免双重遍历。在解码的情况下,应用了进一步的特殊优化。
// faststring ReadUtf8MemoryPack(int utf16Length, int utf8Length){unsafe{fixed (byte* p = &buffer){return string.Create(utf16Length, ((IntPtr)p, utf8Length), static (dest, state) =>{var src = MemoryMarshal.CreateSpan(ref Unsafe.AsRef<byte>((byte*)state.Item1), state.Item2);Utf8.ToUtf16(src, dest, out var bytesRead, out var charsWritten, replaceInvalidSequences: false);});}}}// slowstring ReadStandardSerialzier(int utf8Length){return Encoding.UTF8.GetString(buffer.AsSpan(0, utf8Length));}
通常,要从 byte[] 中获取字符串,我们使用Encoding.UTF8.GetString(buffer)。但同样,UTF8 是一种可变长度编码,我们不知道 UTF16 的长度。UTF8 也是如此。GetString我们需要计算长度为 UTF16 以将其转换为字符串,因此我们在内部扫描字符串两次。在伪代码中,它是这样的:
var length = CalcUtf16Length(utf8data);var str = String.Create(length);Encoding.Utf8.DecodeToString(utf8data, str);
典型序列化程序的字符串格式为 UTF8,它不能解码为 UTF16,因此即使您想要长度为 UTF16 以便作为 C# 字符串进行高效解码,它也不在数据中。
但是,MemoryPack 在标头中记录 UTF16 长度和 UTF8 长度。因此,String.Create<TState>(Int32, TState, SpanAction<Char,TState>) 和 Utf8.ToUtf16的组合为 C# String 提供了最有效的解码。
关于有效负载大小
与可变长度编码相比,整数的固定长度编码的大小可能会膨胀。然而,在现代,使用可变长度编码只是为了减小整数的小尺寸是一个缺点。
由于数据不仅仅是整数,如果真的想减小大小,应该考虑压缩(LZ4,ZStandard,Brotli等),如果压缩数据,可变长度编码几乎没有意义。如果你想更专业和更小,面向列的压缩会给你更大的结果(例如,Apache Parquet)。为了与 MemoryPack 实现集成的高效压缩,我目前有 BrotliEncode/Decode 的辅助类作为标准。我还有几个属性,可将特殊压缩应用于某些原始列,例如列压缩。
[MemoryPackable]public partial class Sample{public int Id { get; set; }[BitPackFormatter]public bool[] Data { get; set; }[BrotliFormatter]public byte[] Payload { get; set; }}
BitPackFormatter表示 bool[],bool 通常为 1 个字节,但由于它被视为 1 位,因此在一个字节中存储八个布尔值。因此,序列化后的大小为 1/8。BrotliFormatter直接应用压缩算法。这实际上比压缩整个文件的性能更好。
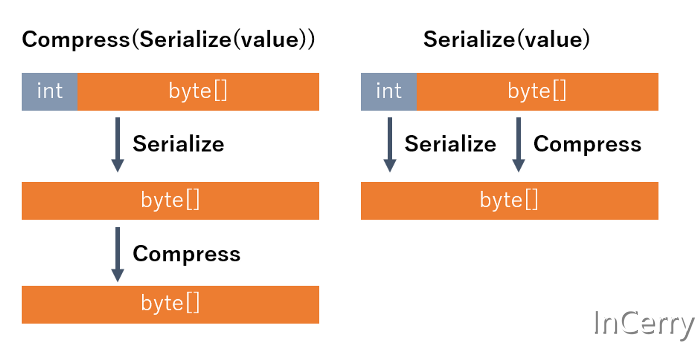
这是因为不需要中间副本,压缩过程可以直接应用于序列化数据。Uber 工程博客上的使用CLP 将日志记录成本降低两个数量级一文中详细介绍了通过根据数据以自定义方式应用处理而不是简单的整体压缩来提取性能和压缩率的方法。
使用 .NET7 和 C#11 新功能
MemoryPack 在 .NET Standard 2.1 的实现和 .NET 7 的实现中具有略有不同的方法签名。.NET 7 是一种更积极、面向性能的实现,它利用了最新的语言功能。
首先,序列化程序接口利用静态抽象成员,如下所示:
public interface IMemoryPackable<T>{// note: serialize parameter should be `ref readonly` but current lang spec can not.// see proposal https://github.com/dotnet/csharplang/issues/6010static abstract void Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref T? value)where TBufferWriter : IBufferWriter<byte>;static abstract void Deserialize(ref MemoryPackReader reader, scoped ref T? value);}
MemoryPack 采用源生成器,并要求目标类型为[MemoryPackable]public partial class Foo,因此最终的目标类型为
[MemortyPackable]partial class Foo : IMemoryPackable{static void IMemoryPackable<Foo>.Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref Foo? value){}static void IMemoryPackable<Foo>.Deserialize(ref MemoryPackReader reader, scoped ref Foo? value){}}
这避免了通过虚拟方法调用的成本。
public void WritePackable<T>(scoped in T? value)where T : IMemoryPackable<T>{// If T is IMemoryPackable, call static method directlyT.Serialize(ref this, ref Unsafe.AsRef(value));}//public void WriteValue<T>(scoped in T? value){// call Serialize from interface virtual methodIMemoryPackFormatter<T> formatter = MemoryPackFormatterProvider.GetFormatter<T>();formatter.Serialize(ref this, ref Unsafe.AsRef(value));}
MemoryPackWriter/MemoryPackReader使用 ref字段。
public ref struct MemoryPackWriter<TBufferWriter>where TBufferWriter : IBufferWriter<byte>{ref TBufferWriter bufferWriter;ref byte bufferReference;int bufferLength;
换句话说,ref byte bufferReference,int bufferLength的组合是Span<byte>的内联。此外,通过接受 TBufferWriter 作为 ref TBufferWriter,现在可以安全地接受和调用可变结构 TBufferWriter:IBufferWrite<byte>。
// internally MemoryPack uses some struct buffer-writersstruct BrotliCompressor : IBufferWriter<byte>struct FixedArrayBufferWriter : IBufferWriter<byte>
针对所有类型的类型进行优化
例如,对于通用实现,集合可以序列化/反序列化为 IEnumerable<T>,但 MemoryPack 为所有类型的提供单独的实现。为简单起见,List<T> 可以处理为:
public void Serialize(ref MemoryPackWriter writer, IEnumerable<T> value){foreach(var item in source){writer.WriteValue(item);}}public void Serialize(ref MemoryPackWriter writer, List<T> value){foreach(var item in source){writer.WriteValue(item);}}
这两个代码看起来相同,但执行完全不同:foreach to IEnumerable<T> 检索IEnumerator<T>,而 foreach to List<T>检索结构List<T>.Enumerator,y 一个优化的专用结构。
但是,MemoryPack 进一步优化了它。
public sealed class ListFormatter<T> : MemoryPackFormatter<List<T?>>{public override void Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref List<T?>? value){if (value == null){writer.WriteNullCollectionHeader();return;}writer.WriteSpan(CollectionsMarshal.AsSpan(value));}}// MemoryPackWriter.WriteSpan[MethodImpl(MethodImplOptions.AggressiveInlining)]public void WriteSpan<T>(scoped Span<T?> value){if (!RuntimeHelpers.IsReferenceOrContainsReferences<T>()){DangerousWriteUnmanagedSpan(value);return;}var formatter = GetFormatter<T>();WriteCollectionHeader(value.Length);for (int i = 0; i < value.Length; i++){formatter.Serialize(ref this, ref value[i]);}}// MemoryPackWriter.DangerousWriteUnmanagedSpan[MethodImpl(MethodImplOptions.AggressiveInlining)]public void DangerousWriteUnmanagedSpan<T>(scoped Span<T> value){if (value.Length == 0){WriteCollectionHeader(0);return;}var srcLength = Unsafe.SizeOf<T>() * value.Length;var allocSize = srcLength + 4;ref var dest = ref GetSpanReference(allocSize);ref var src = ref Unsafe.As<T, byte>(ref MemoryMarshal.GetReference(value));Unsafe.WriteUnaligned(ref dest, value.Length);Unsafe.CopyBlockUnaligned(ref Unsafe.Add(ref dest, 4), ref src, (uint)srcLength);Advance(allocSize);}
来自 .NET 5 的 CollectionsMarshal.AsSpan 是枚举 List<T> 的最佳方式。此外,如果可以获得 Span<T>,则只能在 List<int>或 List<Vector3>的情况下通过复制来处理。
在反序列化的情况下,也有一些有趣的优化。首先,MemoryPack 的反序列化接受引用 T?值,如果值为 null,则如果传递该值,它将覆盖内部生成的对象(就像普通序列化程序一样)。这允许在反序列化期间零分配新对象创建。在List<T> 的情况下,也可以通过调用 Clear() 来重用集合。
然后,通过进行特殊的 Span 调用,它全部作为 Span 处理,避免了List<T>.Add的额外开销。
public sealed class ListFormatter<T> : MemoryPackFormatter<List<T?>>{public override void Deserialize(ref MemoryPackReader reader, scoped ref List<T?>? value){if (!reader.TryReadCollectionHeader(out var length)){value = null;return;}if (value == null){value = new List<T?>(length);}else if (value.Count == length){value.Clear();}var span = CollectionsMarshalEx.CreateSpan(value, length);reader.ReadSpanWithoutReadLengthHeader(length, ref span);}}internal static class CollectionsMarshalEx{/// <summary>/// similar as AsSpan but modify size to create fixed-size span./// </summary>public static Span<T?> CreateSpan<T>(List<T?> list, int length){list.EnsureCapacity(length);ref var view = ref Unsafe.As<List<T?>, ListView<T?>>(ref list);view._size = length;return view._items.AsSpan(0, length);}// NOTE: These structure depndent on .NET 7, if changed, require to keep same structure.internal sealed class ListView<T>{public T[] _items;public int _size;public int _version;}}// MemoryPackReader.ReadSpanWithoutReadLengthHeaderpublic void ReadSpanWithoutReadLengthHeader<T>(int length, scoped ref Span<T?> value){if (length == 0){value = Array.Empty<T>();return;}if (!RuntimeHelpers.IsReferenceOrContainsReferences<T>()){if (value.Length != length){value = AllocateUninitializedArray<T>(length);}var byteCount = length * Unsafe.SizeOf<T>();ref var src = ref GetSpanReference(byteCount);ref var dest = ref Unsafe.As<T, byte>(ref MemoryMarshal.GetReference(value)!);Unsafe.CopyBlockUnaligned(ref dest, ref src, (uint)byteCount);Advance(byteCount);}else{if (value.Length != length){value = new T[length];}var formatter = GetFormatter<T>();for (int i = 0; i < length; i++){formatter.Deserialize(ref this, ref value[i]);}}}
EnsurceCapacity(capacity),可以预先扩展保存 List<T> 的内部数组的大小。这避免了每次都需要内部放大/复制。
但是 CollectionsMarshal.AsSpan,您将获得长度为 0 的 Span,因为内部大小不会更改。如果我们有 CollectionMarshals.AsMemory,我们可以使用 MemoryMarshal.TryGetArray 组合从那里获取原始数组,但不幸的是,没有办法从 Span 获取原始数组。因此,我强制类型结构与 Unsafe.As 匹配并更改List<T>._size,我能够获得扩展的内部数组。
这样,我们可以以仅复制的方式优化非托管类型,并避免 List<T>.Add(每次检查数组大小),并通过Span<T>[index] 打包值,这比传统序列化、反序列化程序性能要高得多。。
虽然对List<T>的优化具有代表性,但要介绍的还有太多其他类型,所有类型都经过仔细审查,并且对每种类型都应用了最佳优化。
Serialize 接受 IBufferWriter<byte> 作为其本机结构,反序列化接受 ReadOnlySpan<byte> 和 ReadOnlySequence<byte>。
这是因为System.IO.Pipelines 需要这些类型。换句话说,由于它是 ASP .NET Core 的服务器 (Kestrel) 的基础,因此通过直接连接到它,您可以期待更高性能的序列化。
IBufferWriter<byte> 特别重要,因为它可以直接写入缓冲区,从而在序列化过程中实现零拷贝。对 IBufferWriter<byte> 的支持是现代序列化程序的先决条件,因为它提供比使用 byte[] 或 Stream 更高的性能。开头图表中的序列化程序(System.Text.Json,protobuf-net,Microsoft.Orleans.Serialization,MessagePack for C#和 MemoryPack)支持它。
MessagePack 与 MemoryPack
MessagePack for C# 非常易于使用,并且具有出色的性能。特别是,以下几点比 MemoryPack 更好
- 出色的跨语言兼容性
- JSON 兼容性(尤其是字符串键)和人类可读性
- 默认完美版本容错
- 对象和匿名类型的序列化
- 动态反序列化
- 嵌入式 LZ4 压缩
- 久经考验的稳定性
MemoryPack 默认为有限版本容错,完整版容错选项的性能略低。此外,因为它是原始格式,所以唯一支持的其他语言是 TypeScript。此外,二进制文件本身不会告诉它是什么数据,因为它需要 C# 架构。
但是,它在以下方面优于 MessagePack。
- 性能,尤其是对于非托管类型数组
- 易于使用的 AOT 支持
- 扩展多态性(联合)构造方法
- 支持循环引用
- 覆盖反序列化
- 打字稿代码生成
- 灵活的基于属性的自定义格式化程序
在我个人看来,如果你在只有 C#的环境中,我会选择 MemoryPack。但是,有限版本容错有其怪癖,应该事先理解它。MessagePack for C# 仍然是一个不错的选择,因为它简单易用。
MemoryPack 不是一个只关注性能的实验性序列化程序,而且还旨在成为一个实用的序列化程序。为此,我还以 MessagePack for C# 的经验为基础,提供了许多功能。
- 支持现代 I/O API(
IBufferWriter<byte>,ReadOnlySpan<byte>,ReadOnlySequence<byte>) - 基于本机 AOT 友好的源生成器的代码生成,没有动态代码生成(IL.Emit)
- 无反射非泛型 API
- 反序列化到现有实例
- 多态性(联合)序列化
- 有限的版本容限(快速/默认)和完整的版本容错支持
- 循环引用序列化
- 基于管道写入器/读取器的流式序列化
- TypeScript 代码生成和核心格式化程序 ASP.NET
- Unity(2021.3) 通过 .NET 源生成器支持 IL2CPP
我们计划进一步扩展可用功能的范围,例如对MasterMemory 的 MemoryPack支持和对 MagicOnion的序列化程序更改支持等。我们将自己定位为Cysharp C# 库生态系统的核心。我们将付出很多努力来种下这一棵树,所以对于初学者来说,请尝试一下我们的库!
版权信息
已获得原作者授权
原文版权:neuecc
翻译版权:InCerry
.NET性能优化交流群
相信大家在开发中经常会遇到一些性能问题,苦于没有有效的工具去发现性能瓶颈,或者是发现瓶颈以后不知道该如何优化。之前一直有读者朋友询问有没有技术交流群,但是由于各种原因一直都没创建,现在很高兴的在这里宣布,我创建了一个专门交流.NET性能优化经验的群组,主题包括但不限于:
- 如何找到.NET性能瓶颈,如使用APM、dotnet tools等工具
- .NET框架底层原理的实现,如垃圾回收器、JIT等等
- 如何编写高性能的.NET代码,哪些地方存在性能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET性能问题和宝贵的性能分析优化经验。由于已经达到200人,可以加我微信,我拉你进群: ls1075
使用.NET7和C#11打造最快的序列化程序-以MemoryPack为例的更多相关文章
- CSharpGL(11)用C#直接编写GLSL程序
CSharpGL(11)用C#直接编写GLSL程序 +BIT祝威+悄悄在此留下版了个权的信息说: 2016-08-13 由于CSharpGL一直在更新,现在这个教程已经不适用最新的代码了.CSharp ...
- 玩玩小程序:使用 WebApi 交互打造原生的微信小程序 - 图灵小书架
使用 WebApi 交互打造原生的微信小程序 - 图灵小书架 目录 介绍 源码地址 扫一扫体验 代码分析 其它相关信息(互联网搜集) 介绍 定时抓取图灵社区官网的首页.最热.推荐和最新等栏目的相关图书 ...
- Windows Phone 8初学者开发—第11部分:设置SounBoard应用程序
原文 Windows Phone 8初学者开发—第11部分:设置SounBoard应用程序 原文地址: http://channel9.msdn.com/Series/Windows-Phone-8- ...
- 怎么样ubuntu 64 11.04 在执行32位程序
上网一查非常多的信息,头发上的今天ubuntu 64 11.04 在执行32位程序安装ia32-libs包,可执行例如,下面的命令.但提示无法安装 apt-get install ia32-libs ...
- 如果你不知道这11款常见的Web应用程序框架 就说明你out了
本文推荐了11款常见的Web应用程序框架,并列出了相关的学习资料和下载文档.如果对这些项目还不熟悉,就赶紧学起来吧~ Rails Rails是Ruby on Rails的简称,是一款开源的Web应用框 ...
- 最快的序列化组件protobuf的.net版本protobuf.net
Protobuf是google开源的一个项目,用户数据序列化反序列化,google声称google的数据通信都是用该序列化方法.它比xml格式要少的多,甚至比二进制数据格式也小的多. Prot ...
- Qt5.11.2 VS2015编译activemq发送程序 _ITERATOR_DEBUG_LEVEL错误和崩溃解决
1.问题描述: 运行环境是 win10 64位系统,开发环境是VS2015 ,Qt 5.11.2.开发activemq发送程序,遇到问题 (1)Qt5AxContainer.lib error LNK ...
- (原创)用c++11打造好用的variant
variant类似于union,它能代表定义的多种类型,允许将不同类型的值赋给它.它的具体类型是在初始化赋值时确定.boost中的variant的基本用法: typedef variant<in ...
- 用c++11打造类似于python的range
python中的range函数表示一个连续的有序序列,range使用起来很方便,因为在定义时就隐含了初始化过程,因为只需要给begin()和end()或者仅仅一个end(),就能表示一个连续的序列.还 ...
- (原创)用c++11打造好用的any
上一篇博文用c++11实现了variant,有童鞋说何不把any也实现一把,我正有此意,它的兄弟variant已经实现了,any也顺便打包实现了吧.其实boost.any已经挺好了,就是转换异常时,看 ...
随机推荐
- C语言大作业---学生信息管理系统
xxxx信息管理系统 简介 因为大作业规定的踩分项就那么多,为了不浪费时间 + 得分,就写成这样.现在看看,命名不规范,书写风格糟糕,全塞在一个源代码中······ 不过,应付大作业是没问题的 实验报 ...
- ELK基于ElastAlert实现日志的微信报警
文章转载自:https://mp.weixin.qq.com/s/W9b28CFBEmxBPz5bGd1-hw 教程pdf文件下载地址 https://files.cnblogs.com/files/ ...
- 使用Prometheus和Grafana监控nacos集群
官方文档:https://nacos.io/zh-cn/docs/monitor-guide.html 按照部署文档搭建好Nacos集群 配置application.properties文件,暴露me ...
- MongoDB集群搭建---副本和分片(伪集群)
参考地址:https://blog.csdn.net/weixin_43622131/article/details/105984032 已配置好的所有的配置文件下载地址:https://files. ...
- windows C++ 异常调用栈简析
楔子 以win11 + vs2022运行VC++ 编译观察的结果. 如果安装了Visual Studio 2022,比如安装在D盘,则路径: D:\Visual Studio\IDE\VC\Tools ...
- Request保存作用域
Request保存作用域,作用范围是在当前请求中有效. 1.客户端重定向 2.服务器内部转发
- 『现学现忘』Git分支 — 38、Git分支介绍
目录 1.Git分支简介 2.Git分支与SVN分支的区别 3.工作中为什么要使用分支 4.Git分支管理的好处 1.Git分支简介 几乎所有的版本控制系统都以某种形式支持分支. 使用分支意味着,你可 ...
- .NET周报【10月第3期 2022-10-25】
国内文章 聊一聊被 .NET程序员 遗忘的 COM 组件 https://www.cnblogs.com/huangxincheng/p/16799234.html 将Windows编程中经典的COM ...
- SpringCloud微服务实战——搭建企业级开发框架(四十七):【移动开发】整合uni-app搭建移动端快速开发框架-添加Axios并实现登录功能
uni-app自带uni.request用于网络请求,因为我们需要自定义拦截器等功能,也是为了和我们后台管理保持统一,这里我们使用比较流行且功能更强大的axios来实现网络请求. Axios ...
- 狂神说mysql笔记
1.mysql 基本操作 Windows-->Mysql5.7打开 输入用户名和密码 查看数据库 :show databases:查询所有数据库,记住一定要加分号结尾 这里必须全部为 英文空格 ...