java8 新特性学习笔记
Java8新特性 学习笔记
1主要内容
- Lambda 表达式
- 函数式接口
- 方法引用与构造器引用
- Stream API
- 接口中的默认方法与静态方法
- 新时间日期 API
- 其他新特性
2 简洁
- 速度更快 修改底层Hash列表的算法, HashMap ,HashSet (由以前的数组加列表->数组+列表/红黑树),加快除添加之外的速度,ConcurrentHashMap(CAS算法)
- 代码更加简洁 (Lambda表达式)
- 强大的StreamAPI (操作数据集合非常方便)
- 便于并行
- 最大化减少空指针Optional容器类类
3 Lambda 表达式
Lambda是一个匿名函数,可以把Lambda表达式理解为是一段可以传递的代码(将代码像数据一样进行传递)。可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升。
案例:
//原来的匿名内部类
public void test1(){
//比较器
Comparator<Integer> com=new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1, o2);
}
};
}
//使用 Lambda表达式
public void test2(){
//x,y为传入的参数 形参,Integer.compare(x,y) 为方法内内容
Comparator<Integer> com=(x,y)->Integer.compare(x,y);
}
如上所示,新的语法中,代码更加简洁, ->称为Lambda操作符,将Lambda分为左右两个部分:
左侧:指定了 Lambda 表达式需要的所有参数
右侧:指定了 Lambda 体,即 Lambda 表达式要执行 的功能
语法格式分为三种情况
语法格式一:无参,无返回值,Lambda 体只需一条语句
Runable run = ()->System.out.println("执行的语句")(创建一个线程任务)语法格式二:Lambda 需要一个参数
Comsumer com = (args)->System.out.println(args)如果只一个参数 括号可以不用
args->System.out.println(args)(Comsumer 为函数式编程接口,消费模式,接收一个参数,没有返回值)语法格式三:Lambda 需要两个参数,并且有返回值
语法格式三: Lambda 需要三个参数,
BinaryOperato bin =(x,y)->{ return x+y ;};(二元操作函数式接口,接收两个数,返回一个同样类型的数)如果执行体只有一条语句,可以省略 return 和大括号
BinaryOperato bin =(x,y)-> x+y
上面的形参括号中,都没有写参数的类型,这是因为编译器可以根据上下文,方法的泛型中,推断出类型,这就是所谓的"类型推断".
4 函数式接口
只包含一个抽象方法的接口,称为 函数式接口。
在上面的Lambda的语法规则中,右侧的表达式为实际的操作内容,是接口的实现,但若是接口有两个抽象类,那个这个操作内容,又该属于哪一个,所以, Lambda表达式,必须要有函数式接口的支持.
你可以通过 Lambda 表达式来创建该接口的对象。(若 Lambda表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方法上进行声明)。
我们可以在任意函数式接口上使用 @FunctionalInterface 注解,这样做可以检查它是否是一个函数式接口,同时 javadoc 也会包含一条声明,说明这个接口是一个函数式接口。
作为参数传递 Lambda 表达式:为了将 Lambda 表达式作为参数传递,接收 Lambda 表达式的参数类型必须是与该 Lambda 表达式兼容的函数式接口的类型。
案例 : 定义一个自己的函数式接口
@FunctionalInterface
public interface MyFun {
public Integer getValue(Integer num);
}
案例 : 定义一个函数式接口,并用作方法的参数进行传递
//需求:对一个数进行运算
@Test
public void test6(){
//只一个函数式接口,就可以进行多种运算
Integer num=operation(100, (x)->x*x);
System.out.println(num);
System.out.println(operation(200, (y)->y+200));
}
public Integer operation(Integer num,MyFun mf){
return mf.getValue(num);
}
案例 : 调用Collections.sort()方法,通过定制排序比较两个Employee(先按年龄比,年龄相同按姓名比),使用Lambda作为参数传递。
List<Employee> employees=Arrays.asList(
new Employee("张三",18,9496.2),
new Employee("李四",52,2396.2),
new Employee("王五",56,996.2),
new Employee("赵六",8,94.2)
);
@Test
public void test1(){
//使用Lambda 可以轻松的定义比较规则,
Collections.sort(employees, (e1,e2)->{
if(e1.getAge()==e2.getAge()){
return e1.getName().compareTo(e2.getName());
}else{
return Integer.compare(e1.getAge(), e2.getAge());
}
});
}
为了方便我们使用Lambda 表达式, java给我们提供了内置的函数式接口,
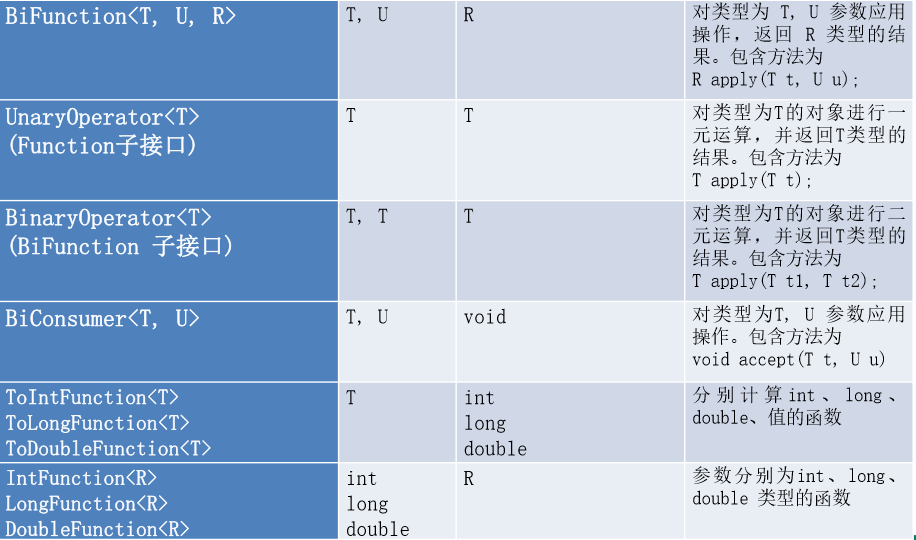
java内置四大函数式接口
Consumer :消费型接口
void accept(T t);
Supplier :供给型接口
T get();
Function<T,R> :函数型接口
R apply(T t);
Preicate :断言型接口
boolean test(T t);
其他接口:
5方法引用与构造器引用
方法引用主要有三种语法格式:
对象::实例方法名
类::静态方法名
类::实例方法名
注意:
1、Lambda体中调用方法的参数列表与返回值类型,要与函数式接口中抽象方法的函数列表和返回值类型保持一致!
2、若Lambda参数列表中的第一个参数是 实例方法的调用者,而第二个参数是实例方法的参数时,
(x,y)->x.equals(y) 可以写成 Stringequals 可以使用ClassNamemethod
public class TestMethodRef {
//对象::实例方法名
@Test
public void test1(){
PrintStream ps1=System.out; //打印流对象
Consumer<String> con=(x)->ps1.println(x);
//可以写成下面的样子
PrintStream ps=System.out;
Consumer<String> con1=ps::println;//相当于上面,引用了ps对象的println()方法
Consumer<String> con2=System.out::println;
}
@Test
public void test2(){
final Employee emp=new Employee(); //匿名内部类中引用外部的对象,该对象必须为final
Supplier<String> sup=()->emp.getName();//代替匿名内部类 (jdk1.8后 引用的对象就算没有显式 的加final ,也可以正常使用了,但这个只是语法糖,其底层还是会自动加上final,如果后面对其改变,会 报错)
Supplier<Integer> sup2=emp::getAge; // 引用emp对象的方法,实现抽象方法,进行对外供给
Integer num=sup2.get();
}
//类::静态方法名
@Test
public void test3(){
Comparator<Integer> com=(x,y)->Integer.compare(x,y);
Comparator<Integer> com1=Integer::compare;//引用静态方法
}
//类::实例方法名
@Test
public void test4(){
BiPredicate<String,String> bp=(x,y)->x.equals(y);
BiPredicate<String, String> bp2=String::equals; //第一个参数是调用者,第二个参数是实参
}
构造器引用:
格式: ClassName::new
与函数式接口相结合,自动与函数式接口中方法兼容。 可以把构造器引用赋值给定义的方法,与构造器参数 列表要与接口中抽象方法的参数列表一致
//构造器引用
@Test
public void test5(){
Supplier<Employee> sup=()->new Employee();
//构造器引用方式
Supplier<Employee> sup2=Employee::new;//使用无参构造器
Employee emp=sup2.get(); //引用Employee构造器进行供给
//带参的构造器
Function<Integer,Employee> fun2=(x)->new Employee(x);
BiFunction<String,Integer,Employee> bf=Employee::new;//也这么写,抽象方法中的参数类型会自动 匹配相对应的构造器
}
数组引用:
引用数组的创造方式
//数组引用
@Test
public void test6(){
Function<Integer,String[]> fun=(x)->new String[x];
String[] strs=fun.apply(10);
System.out.println(strs.length);
Function<Integer,String[]> fun2=String[]::new;
String[] str2=fun2.apply(20);
System.out.println(str2.length);
}
}
6 Stream Api
Java8中有两大最为重要的改变。
第一个是 Lambda 表达式;
另外一 个则是 Stream API(java.util.stream.*)。
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作.
- Stream 自己不会存储元素。
- Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
- Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行(性能优越)
Stream的操作三步骤
- 创建Stream
一个数据源(如:集合、数组),获取一个流 - 中间操作
一个中间操作链,对数据源的数据进行处理 - 终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果
创建流
可以通过Collection 下的集合提供的stream()或parallelStream()方法
default Stream< E> stream() : 返回一个顺序流
default Stream< E> parallelStream() : 返回一个并行流通过 Arrays 工具类 中的静态方法stream()获取数组流
static < T> Stream< T> stream(T[] array): 接收任意类型的数组返回该类型的一个流
重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array)
public static LongStream stream(long[] array)
public static DoubleStream stream(double[] array)通过Stream 类中的静态方法of(),通过显示值创建一个流。它可以接收任意数量的参数。
public static< T> Stream< T> of(T… values) : 接收一个类型任意数量的值直接创建该类型的一个流
创建无限流
可以使用静态方法 Stream.iterate() 和Stream.generate(), 创建无限流。
迭代
public static< T> Stream< T> iterate(final T seed, final UnaryOperator< T> f)
生成
public static< T> Stream< T> generate(Supplier< T> s)
下面是案例:
//创建Stream
@Test
public void test1(){
//1.可以通过Collection 系列集合提供的stream()或parallelStream()
List<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
//2.通过 Arrays 中的静态方法stream()获取数组流
Employee[] emps=new Employee[10];
Stream<Employee> stream2=Arrays.stream(emps);
//3.通过Stream 类中的静态方法of()
Stream<String> stream3=Stream.of("aa","bb","cc");
//4.创建无限流
//迭代
Stream<Integer> stream4=Stream.iterate(0, (x) -> x+2);
stream4.limit(10).forEach(System.out::println);
//生成
Stream.generate(() -> Math.random())
.limit(5)
.forEach(System.out::println);
}
中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性处理,成为“惰性求值”。
- 过滤和切片

//中间操作
List<Employee> employees=Arrays.asList(
new Employee("张三",18,9999.99),
new Employee("李四",58,5555.55),
new Employee("王五",26,3333.33),
new Employee("赵六",36,6666.66),
new Employee("田七",12,8888.88),
new Employee("田七",12,8888.88)
);
//Steam对象执行中间操作时,会返回Steam对象,实现链式调用
//内部迭代:迭代操作由 Stream API 完成
@Test
public void test1(){
//中间操作:不会执行任何操作(没有终止操作)
//过滤操作,过滤规则为传入的断言函数式接口来定义(本案例为年龄超过35岁的)
Stream<Employee> stream=employees.stream()
.filter((e) -> e.getAge()>35 );
//终止操作:一次性执行全部内容,即 惰性求值(执行这一句代码时,上面的中间操作才会执行)
stream.forEach(System.out::println);
}
//外部迭代
@Test
public void test2(){
Iterator<Employee> it=employees.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
@Test
//limit中间操作 在找到指定的条数数后,会自动切断流的迭代
public void test3(){//发现“短路”只输出了两次,说明只要找到 2 个 符合条件的就不再继续迭代
employees.stream()
.filter((e)->{
System.out.println("短路!");
return e.getSalary()>5000;
})
.limit(2)
.forEach(System.out::println);
}
@Test
public void test4(){
employees.stream()
.filter((e)->e.getSalary()>5000)
.skip(2)//跳过前两个
.distinct()//去重,注意:需要Employee重写hashCode 和 equals 方法
.forEach(System.out::println);
}
- 映射
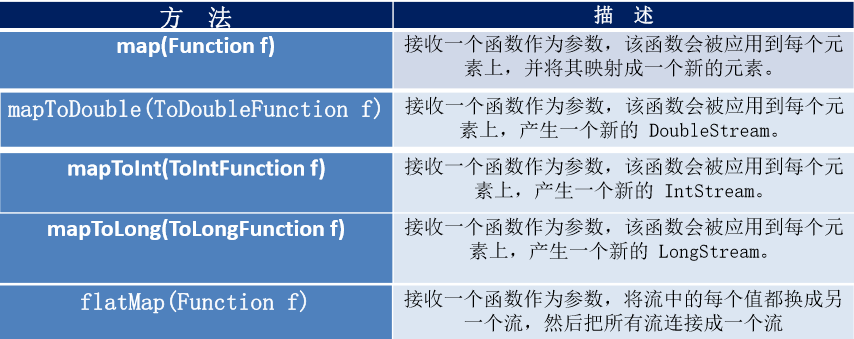
@Test
public void test5(){
List<String> list=Arrays.asList("aaa","bbb","ccc","ddd");
//将作用于其中每一个元素
list.stream()
.map((str)->str.toUpperCase())
.forEach(System.out::println);
employees.stream()
.map(Employee::getName)
.forEach(System.out::println);
//将其中的每个元素都映射成一个流(该案例为把每个字符串变成字符集合的流)
Stream<Stream<Character>> stream=list.stream()
.map(TestStreamAPI2::filterChatacter);
//遍历主流 ,取出其中每个流,再遍历每个流,得到每个字符
stream.forEach((sm)->{
sm.forEach(System.out::println);
});
System.out.println("------------------------");
//将其中每个元素变成一个流后,并合并这些流,变成一个流,所有的元素在一起
Stream<Character> sm=list.stream()
.flatMap(TestStreamAPI2::filterChatacter);
sm.forEach(System.out::println);
}
public static Stream<Character> filterChatacter(String str){
List<Character> list=new ArrayList<>();
for (Character ch : str.toCharArray()) {
list.add(ch);
}
return list.stream();
}
@Test
public void test6(){
//map和flatMap的关系 类似于 add(Object)和addAll(Collection coll)
List<String> list=Arrays.asList("aaa","bbb","ccc","ddd");
List list2=new ArrayList<>();
list2.add(11);
list2.add(22);
list2.addAll(list);
}
- 排序

```java
@Test
public void test7(){
//默认的自然排序
List list=Arrays.asList("ccc","bbb","aaa");
list.stream()
.sorted()
.forEach(System.out::println);
System.out.println("------------------------");
//按照自定义的排序规则
employees.stream()
.sorted((e1,e2)->{
if(e1.getAge().equals(e2.getAge())){
return e1.getName().compareTo(e2.getName());
}else{
return e1.getAge().compareTo(e2.getAge());
}
}).forEach(System.out::println);
}
```
终止操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的 值,例如:List、Integer,甚至是 void
- 查找与匹配


List<Employee> employees=Arrays.asList(
new Employee("张三",18,9999.99,Status.FREE),
new Employee("李四",58,5555.55,Status.BUSY),
new Employee("王五",26,3333.33,Status.VOCATION),
new Employee("赵六",36,6666.66,Status.FREE),
new Employee("田七",12,8888.88,Status.BUSY)
);
/*
* 查找与匹配
*
*/
@Test
public void test1(){
boolean b1=employees.stream()//allMatch-检查是否匹配所有元素(状态都为BUSY的)
.allMatch((e)->e.getStatus().equals(Status.BUSY));
System.out.println(b1);//false
boolean b2=employees.stream()//anyMatch-检查是否至少匹配一个元素(至少有一个是BUSY的)
.anyMatch((e)->e.getStatus().equals(Status.BUSY));
System.out.println(b2);//true
boolean b3=employees.stream()//noneMatch-检查是否没有匹配所有元素(一个都不是)
.noneMatch((e)->e.getStatus().equals(Status.BUSY));
System.out.println(b3);//false
//findFirst-返回第一个元素//Optional是Java8中避免空指针异常的容器类
Optional<Employee> op=employees.stream()
.sorted((e1,e2)->Double.compare(e1.getSalary(), e2.getSalary()))
.findFirst();
System.out.println(op.get());//Employee [name=王五, age=26, salary=3333.33, Status=VOCATION]
Optional<Employee> op2=employees.parallelStream()//findAny-返回当前流中的任意元素
.filter((e)->e.getStatus().equals(Status.FREE))
.findAny();
System.out.println(op2.get());//Employee [name=赵六, age=36, salary=6666.66, Status=FREE]
Long count=employees.stream()//count-返回流中元素的总个数
.count();
System.out.println(count);//5
Optional<Employee> op3=employees.stream()//max-返回流中最大值(比较规则可以定义,倒过来放)
.max((e1,e2)->Double.compare(e1.getSalary(), e2.getSalary()));
System.out.println(op3.get());//Employee [name=张三, age=18, salary=9999.99, Status=FREE]
Optional<Double> op4=employees.stream()//min-返回流中最小值
.map(Employee::getSalary)
.min(Double::compare);
System.out.println(op4.get());//3333.33
}
- 规约

可
/*
* 归约(可以和map相结合使用)
* reduce(T identity,BinaryOperator b) / reduce(BinaryOperator b)-可以将流中元素反复结合起来,得到一个值。
*/
@Test
public void test3(){
List<Integer> list=Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum=list.stream()//reduce(T identity,BinaryOperator b)
.reduce(0, (x,y)->x+y);//0为起始值
System.out.println(sum);
System.out.println("--------------------------");
Optional<Double> op=employees.stream()//reduce(BinaryOperator b)//没有起始值,map返回可能为空,所以返回Optional类型
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println(op.get());
}
收集
Collector接口中方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)。但是Collectors实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:



/*
* 收集
* collect-将流转换为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法。
*/
@Test
public void test4(){
List<String> list=employees.stream()
.map(Employee::getName)
.collect(Collectors.toList());
list.forEach(System.out::println);
System.out.println("----------------------------");
Set<String> set=employees.stream()
.map(Employee::getName)
.collect(Collectors.toSet());
set.forEach(System.out::println);
System.out.println("----------------------------");
HashSet<String> hs=employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));
hs.forEach(System.out::println);
System.out.println("----------------------------");
//总和
Long count=employees.stream()
.collect(Collectors.counting());
System.out.println(count);
//平均值
Double avg=employees.stream()
.collect(Collectors.averagingDouble(Employee::getSalary));
System.out.println(avg);
//总和
Double sum=employees.stream()
.collect(Collectors.summingDouble(Employee::getSalary));
System.out.println(sum);
//最大值
Optional<Employee> max=employees.stream()
.collect(Collectors.maxBy((e1,e2)->Double.compare(e1.getSalary(), e2.getSalary())));
System.out.println(max.get());
//最小值
Optional<Double> min=employees.stream()
.map(Employee::getSalary)
.collect(Collectors.minBy(Double::compare));
System.out.println(min.get());
System.out.println("----------------------------");
//分组
Map<Status,List<Employee>> map=employees.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
System.out.println(map);//{FREE=[Employee [name=张三, age=18, salary=9999.99, Status=FREE], Employee [name=赵六, age=36, salary=6666.66, Status=FREE]], VOCATION=[Employee [name=王五, age=26, salary=3333.33, Status=VOCATION]], BUSY=[Employee [name=李四, age=58, salary=5555.55, Status=BUSY], Employee [name=田七, age=12, salary=8888.88, Status=BUSY]]}
//多级分组
Map<Status,Map<String,List<Employee>>> map2=employees.stream()
.collect( Collectors.groupingBy( Employee::getStatus,Collectors.groupingBy((e)->{
if(e.getAge()<=35){
return "青年";
}else if(e.getAge()<=50){
return "中年";
}else{
return "老年";
}
}) ) );
System.out.println(map2);//{FREE={青年=[Employee [name=张三, age=18, salary=9999.99, Status=FREE]], 中年=[Employee [name=赵六, age=36, salary=6666.66, Status=FREE]]}, VOCATION={青年=[Employee [name=王五, age=26, salary=3333.33, Status=VOCATION]]}, BUSY={青年=[Employee [name=田七, age=12, salary=8888.88, Status=BUSY]], 老年=[Employee [name=李四, age=58, salary=5555.55, Status=BUSY]]}}
//分区
Map<Boolean,List<Employee>> map3=employees.stream()
.collect(Collectors.partitioningBy((e)->e.getSalary()>8000));
System.out.println(map3);//{false=[Employee [name=李四, age=58, salary=5555.55, Status=BUSY], Employee [name=王五, age=26, salary=3333.33, Status=VOCATION], Employee [name=赵六, age=36, salary=6666.66, Status=FREE]], true=[Employee [name=张三, age=18, salary=9999.99, Status=FREE], Employee [name=田七, age=12, salary=8888.88, Status=BUSY]]}
System.out.println("--------------------------------");
DoubleSummaryStatistics dss=employees.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary));
System.out.println(dss.getSum());
System.out.println(dss.getAverage());
System.out.println(dss.getMax());
System.out.println("--------------------------------");
String strr=employees.stream()
.map(Employee::getName)
.collect(Collectors.joining(","));
System.out.println(strr);//张三李四王五赵六田七
}
java8 新特性学习笔记的更多相关文章
- java8新特性学习笔记(二) 使用流(各种API)
筛选和切片 用谓词筛选,筛选出各个不相同的元素,忽略流中的头几个元素,或将流截断至指定长度 用谓词筛选 Stream接口支持filter方法,该操作接受一个谓词(返回一个boolean的函数) 作为参 ...
- java8新特性学习笔记(二) 流的相关思想
流是什么 流是Java API的新成员,他允许你以声明的方式处理数据集合,就现在来说,可以把他们看成遍历数据集合的高级迭代器.此外,流还可以透明地并行处理,你无须写任何多线程代码. 下面例子是新老AP ...
- Java8新特性学习笔记(一) Lambda表达式
没有用Lambda表达式的写法: Comparator<Transaction> byYear = new Comparator<Transaction>() { @Overr ...
- java8新特性学习笔记链接
https://blog.csdn.net/yitian_66/article/details/81010434
- Java8 新特性学习 Lambda表达式 和 Stream 用法案例
Java8 新特性学习 Lambda表达式 和 Stream 用法案例 学习参考文章: https://www.cnblogs.com/coprince/p/8692972.html 1.使用lamb ...
- java8新特性学习:函数式接口
本文概要 什么是函数式接口? 如何定义函数式接口? 常用的函数式接口 函数式接口语法注意事项 总结 1. 什么是函数式接口? 函数式接口其实本质上还是一个接口,但是它是一种特殊的接口:SAM类型的接口 ...
- java8新特性学习1
java8增加了不少新特性,下面就一些常见的新特性进行学习... 1.接口中的方法 2.函数式接口 3.Lambda表达式 4.java8内置的四大核心函数式接口 5.方法引用和构造器引用 6.Str ...
- java8新特性学习:stream与lambda
Streams api 对 Stream 的使用就是实现一个 filter-map-reduce 过程,产生一个最终结果,或者导致一个副作用(side effect). 流的操作类型分为两种: Int ...
- Java8 新特性学习
摘自:https://blog.csdn.net/shuaicihai/article/details/72615495 Lambda 表达式 Lambda 是一个匿名函数,我们可以把 Lambda ...
随机推荐
- Python语法学习记录之tuple该如何使用?
一.介绍 dict 的用法比较简单,它可以存储任意值,并允许是不同类型的值,下面实例来说明: 下面例子中 a 是整数, b 是字符串, c 是数组,这个例子充分说明哈希数组的适用性. 每一个元素是pa ...
- win10 快速访问存在 2345Downloads 删除解决方案
有时候重装新系后统会发有很多自己不喜欢的捆绑程序,比如2345辣鸡浏览器 这个时候很多人会选择卸载,然后把文件夹位置删除 但是删除后会发现有一个地方一直还在那就是现快速访问的位置里面 这个位置由于卸载 ...
- thinkphp 应用模式
应用模式提供了对核心框架进行改造的机会,可以让你的应用适应更多的环境和不同的要求. 每个应用模式有自己的模式定义文件,用于配置当前模式需要加载的核心文件和配置文件,以及别名定义.行为扩展定义等等.根据 ...
- sql语句创建表
create table `search_custom_mall` ( `id` ) NOT NULL PRIMARY KEY AUTO_INCREMENT, `uid` ) NOT NULL, `n ...
- Openstack Nova 源码分析 — RPC 远程调用过程
目录 目录 Nova Project Services Project 的程序入口 setuppy Nova中RPC远程过程调用 nova-compute RPC API的实现 novacompute ...
- JVM内核-原理、诊断与优化学习笔记(九):锁
文章目录 线程安全 多线程网站统计访问人数 多线程访问ArrayList 对象头Mark Mark Word,对象头的标记,32位 描述对象的hash.锁信息,垃圾回收标记,年龄 偏向锁 轻量级锁 B ...
- (转)在Source Insight中看Python代码
http://blog.csdn.net/lvming404/archive/2009/03/18/4000394.aspx SI是个很强大的代码查看修改工具,以前用来看C,C++都是相当happy的 ...
- kubernetes session and 容器root权限
session保持 如何在service内部实现session保持呢?当然是在service的yaml里进行设置啦. 在service的yaml的sepc里加入以下代码: sessionAffinit ...
- Jsoup 学习笔记
这里写自定义目录标题 Jsoup 学习笔记 解析 HTML 的字符串解析 URL 解析 本地文件解析 解析数据 DOM 解析 使用选择器解析 选择器概述 选择器组合用法 过滤用法 修改数据 HTML ...
- <爬虫实战>糗事百科
1.糗事百科段子.py # 目标:爬取糗事百科段子信息(文字) # 信息包括:作者头像,作者名字,作者等级,段子内容,好笑数目,评论数目 # 解析用学过的几种方法都实验一下①正则表达式.②Beauti ...