MySQL中遍历查询结果的常用API(c)
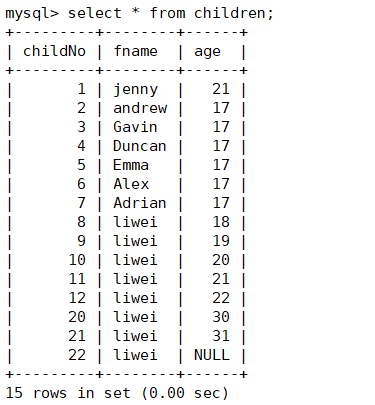
本中所使用的table:
MySQL中的错误处理函数
unsigned int mysql_errno(MYSQL *mysql)
const char *mysql_error(MYSQL *mysql)
说明:一个函数是返回错误号,一个返回错误信息,两者都以MYSQL*为参数,很直观。
第一步:进行查询操作
用到的函数:
int mysql_query(MYSQL *mysql, const char *stmt_str)
int mysql_real_query(MYSQL *mysql, const char *stmt_str, unsigned longlength)
返回值:成功则返回0,失败返回非零,如果失败的话,可以利用错误处理函数来获得错误信息。
这两个函数的区别:当查询语句使用的是二进制数据时,只能用后者。

第二步:保存查询结果(仅select语句具有查询结果,update、delete、insert是没有查询结果的)
用到的函数:
MYSQL_RES *mysql_store_result(MYSQL *mysql)
MYSQL_RES *mysql_use_result(MYSQL *mysql)
返回值:如果执行成功,返回一个非空的MYSQL_RES指针,否则,返回NULL。注意,只要执行select语句成功,就算没有与该select语句匹配的表项,该函数的返回值也不应为NULL。
两个函数的区别:mysql_store_result将整个result set放进client中存储,假若select的查询结果有一百个表项,则调用mysql_store_result会将这一百个表项全都存在了内存中,而mysql_use_result仅仅从result set中取出一个表项存在内存中,使用mysql_fetch_row()函数时才从server中的result set中取出下一个表项。因此mysql_use_result占用的内存更少执行速度也更快。但如果你需要在client端对result set的数据进行一些处理的话,那还是用mysql_store_set吧。
总结:mysql_store_result将select语句在server中的执行结果全都存到了client的内存中,而mysql_use_result仅当需要用到数据时才从server中取出下一条数据存到client的内存中。
注意:结果用完之后,要用mysql_free_result()释放内存。该函数的原型为 void mysql_free_result(MYSQL_RES *result)

第三步:遍历结果
遍历结果可分为两个步骤:首先取出result set中的一行数据,然后再遍历该行数据中的每列数据。
遍历行时用到的函数:
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result)
说明:它以上一步中的查询结果为参数,返回一个MYSQL_ROW结构体,这个结构体的内容为result set中的一行数据,可以理解为一个元素为字符指针的数组(char* row[elems]),当result set中的所有数据遍历完毕,该函数返回NULL。那么怎样使用这个结构体呢?首先得通过下面的函数(mysql_num_fields() / mysql_field_count())得到result set中的列数,然后从index从0开始,以(列数 - 1)结束,依此遍历就可以了。以col代指当前列,若当前列的值为NULL,MYSQL_ROW[col]的值也为NULL。
使用示例:
MYSQL_ROW row;
unsigned int cols = mysql_field_count(conn_ptr);
while ((row = mysql_fetch_row(res_ptr)) != NULL)
{
for (unsigned int i = ; i < cols; ++i)
{
printf("%s ", row[i]);
}
printf("\n");
}
输出结果如下:
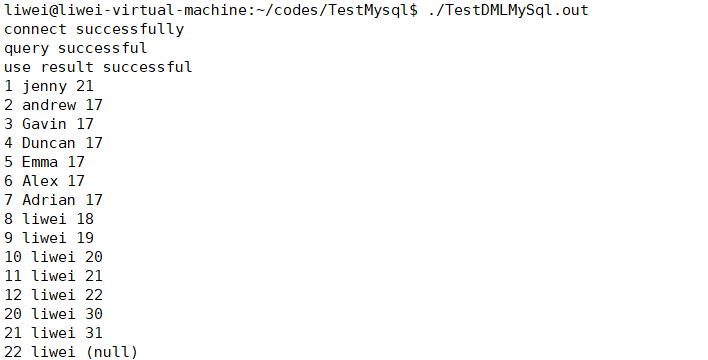
其实正常情况下应该对row[i]是否为NULL进行判断的,这里让我有点疑惑,为何row[i]在为空的情况下,也行正常printf出结果,而不产生段错误。
MYSQL_ROW row;
unsigned int cols = mysql_field_count(conn_ptr);
while((row = mysql_fetch_row(res_ptr)) != NULL)
{
for(unsigned int i = ;i < cols;++i)
{
if(row[i] == NULL)
printf("i am null");
else
printf("%s ",row[i]);
}
printf("\n");
}
结果:
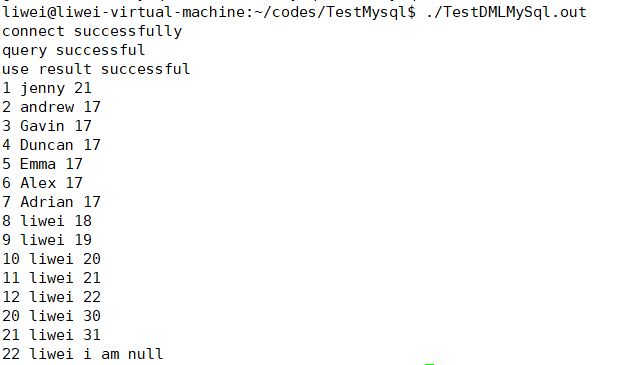
遍历列时用到的函数:
unsigned int mysql_num_fields(MYSQL_RES *result)
unsigned int mysql_field_count(MYSQL *mysql)
MYSQL_FIELD *mysql_fetch_field(MYSQL_RES *result)
对于前面两个函数,它们的参数不同,但是效果却是相同的,都是返回当前查询的result set中的列数。
通过第三个函数可以得到列的属性(包括列的name,列的type等信息),它的用法与mysql_fetch_col()差不多,也需要用while不停地循环。当返回值为空时,就代表没有下一列了。
使用示例:
MYSQL_RES* res_ptr = mysql_store_result(conn_ptr);
if(res_ptr)
{
printf("use result successful\n"); MYSQL_FIELD* field;
while((field = mysql_fetch_field(res_ptr)))
{
printf("%s ",field->name);
}
printf("\n"); }
结果:

全部代码
#include <mysql/mysql.h> #include <stdlib.h>
#include <stdio.h> int main()
{
//MYSQL* mysql_init(MYSQL *mysql)
MYSQL* conn_ptr = mysql_init(NULL);
if(conn_ptr == NULL)
{
fprintf(stderr,"mysql_init() failed\n");
return -;
}
//MYSQL* mysql_real_connect(MYSQL *mysql, const char *host,
//const char *user,const char *passwd, const char *db,
//unsigned int port, const char *unix_socket, unsigned long clientflag)
mysql_real_connect(conn_ptr,"localhost",
"rick","secretpassword","rick",
,NULL,);
if(conn_ptr)
{
printf("connect successfully\n");
int query_ret = mysql_query(conn_ptr,"SELECT * FROM children;");
if(query_ret == )
{
printf("query successful\n"); MYSQL_RES* res_ptr = mysql_store_result(conn_ptr);
if(res_ptr)
{
printf("use result successful\n"); MYSQL_FIELD* field;
while((field = mysql_fetch_field(res_ptr)))
{
printf("%s ",field->name);
}
printf("\n"); MYSQL_ROW row;
unsigned int cols = mysql_field_count(conn_ptr);
while((row = mysql_fetch_row(res_ptr)) != NULL)
{
for(unsigned int i = ;i < cols;++i)
{
printf("%s ",row[i]);
}
printf("\n");
}
}
else
{
fprintf(stderr,"use result failed %d : %s\n",mysql_errno(conn_ptr),mysql_error(conn_ptr));
}
mysql_free_result(res_ptr);
}
else
{
fprintf(stderr,"query failed %d : %s\n",mysql_errno(conn_ptr),mysql_error(conn_ptr));
} }
else
{
printf("connect failed\n");
}
//void mysql_close(MYSQL *sock)
mysql_close(conn_ptr);
return ;
}
MySQL中遍历查询结果的常用API(c)的更多相关文章
- 【原创】7. MYSQL++中的查询结果获取(各种Result类型)
在本节中,我将首先介绍MYSQL++中的查询的几个简单例子用法,然后看一下mysqlpp::Query中的几个与查询相关的方法原型(重点关注返回值),最后对几个关键类型进行解释. 1. MYSQL++ ...
- mysql中模糊查询的四种用法介绍
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
- mysql 中合并查询结果union用法 or、in与union all 的查询效率
mysql 中合并查询结果union用法 or.in与union all 的查询效率 (2016-05-09 11:18:23) 转载▼ 标签: mysql union or in 分类: mysql ...
- 下面介绍mysql中模糊查询的四种用法:
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
- mysql中如何查询最近24小时、top n查询
MySQL中如何查询最近24小时. where visittime >= NOW() - interval 1 hour; 昨天. where visittime between CURDATE ...
- Mysql中分页查询两个方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下 1 2 3 SELECT COUNT(*) FROM foo WHERE b = 1; SELECT a FROM ...
- mysql中in查询中排序
mysql中in查询条件的时候,很多时候排序是不规则的,如何按照in里面的条件进行排序呢? mysql中给出了办法,在in后面加order by field,order by field的首个条件是按 ...
- 【面经】面试官:如何以最高的效率从MySQL中随机查询一条记录?
写在前面 MySQL数据库在互联网行业使用的比较多,有些小伙伴可能会认为MySQL数据库比较小,存储不了很多的数据.其实,这些小伙伴是真的不了解MySQL.MySQL的小不是说使用MySQL存储的数据 ...
- MySQL中的查询事务问题
之前帮同学做个app的后台,使用了MySQL+MyBatis,遇到了一个查询提交的问题,卡了很久,现在有时间了来复盘下 环境情况 假设有学生表: USE test; CREATE TABLE `stu ...
随机推荐
- ACM北大暑期课培训第一天
今天是ACM北大暑期课开课的第一天,很幸运能参加这次暑期课,接下来的几天我将会每天写博客来总结我每天所学的内容.好吧下面开始进入正题: 今天第一节课,郭炜老师给我们讲了二分分治贪心和动态规划. 1.二 ...
- FUTABA舵机参数大全
S9150 Digital servo 尺寸:47.5X27X25.3mm 重量:53g 速度:0.18sec/60"(4.8V) 扭力:5.8kg:cm(4.8V) ——————————— ...
- ENS 域名注册表智能合约(ENSRegistry.sol)解析
ENS 注册表合约是 ENS 系统中的核心合约,了解这个合约可以敲开我们理解 ENS 域名系统的大门. 打开下面的折叠区域可以查看用 Solidity 语言编写的详细代码.当前部署在以太坊中的 ENS ...
- Could not find iPhone 6 simulator
最近原来的老项目有点问题需要处理一下,运行启动命令,就报了如下错误,提示找不到iPhone 6 模拟器. react-native run-ios Owaiss-Mac:pdm owaisahmed$ ...
- Thinkpad S440 I/O接口配置
HDMI 视频接口 SS USB3.0接口 电源接口 音频接口 网络接口 没有com口可以用USB口,然后安装一个USB转com口的驱动.
- 如何使用F4的IRAM2内存
在使用KEIL做F4的项目的时候发现RAM区有片上IRAM2选项,查了datesheet后发现这块是CCM内存区 CCM内存是在地址0x1000000映射的64KB块,只提供CPU通过数据D总线进行访 ...
- 开发环境Vue访问后端接口教程(前后端分离开发,端口不同下跨域访问)
原理:开发环境下的跨域:在node.js上实现请求转发,vue前端通过axios请求到node.js上,node.js将请求转发到后端,反之.响应也是,先到node.js上,然后转发vue-cil项目 ...
- JAVA中值传递,引用传递
刚在写一个用例,需要在方法中改变传递的参数的值,可是java中只有传值调用,没有传址调用.所以在java方法中改变参数的值是行不通的.但是可以改变引用变量的属性值. 可以仔细理解一下下面几句话: 1. ...
- BZOJ 2648 世界树
题目传送门 分析: 喜 闻 乐 见 的虚树 但是建好虚树后的DP也非常的恶心 我们先考虑每个关键点的归哪个点管 先DFS一次计算儿子节点归属父亲 再DFS一次计算父亲节点归属儿子 然后然后我们对于虚树 ...
- 安装 Xen
安装 Xen 安装支持 Xen 的相关工具: $ sudo apt-get install ubuntu-xen-server 下载和安装支持 Xen 的 Linux 内核: http://secur ...