tesseract ocr训练 pt验证码
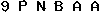

识别率有问题A大概率识别为n,因此需要训练,这里讲一下 如何训练
参考
java代码里边直接使用tess4j,是对tesseract的封装,但是如果要训练,还是需要在进行安装tesseract-ocr的
下载地址参考另一篇
然后还需要 下载jTessBoxEditorhttps://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
多搜集几张图片,进行二值化去噪点和裁切处理

双击运行

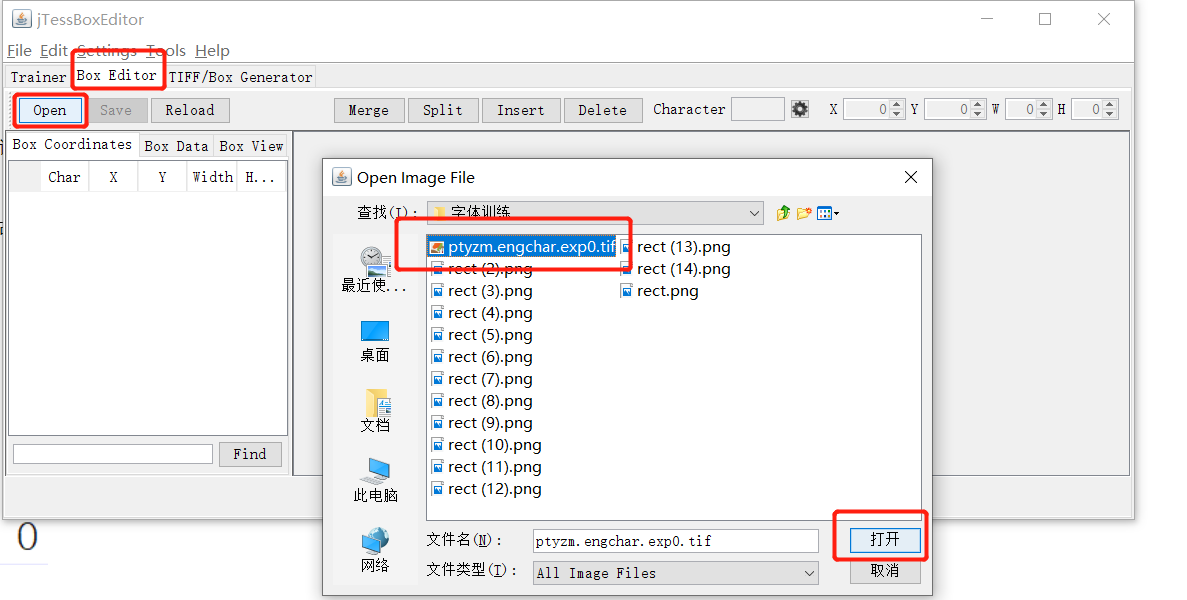
首先打开图片
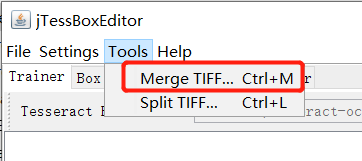
全选图片,应该可以自动拼接为一个大的tif,不过我测试发现,有问题,并不能拼
而且,最后一步,生成box的时候,几乎所有的字体都无法识别,还是需要手动添加box
所以还是手动处理一下
然后生成tif文件,命名格式包含语言类型和干吗用的字体就行了,比如我这个是英文字体,pt验证码
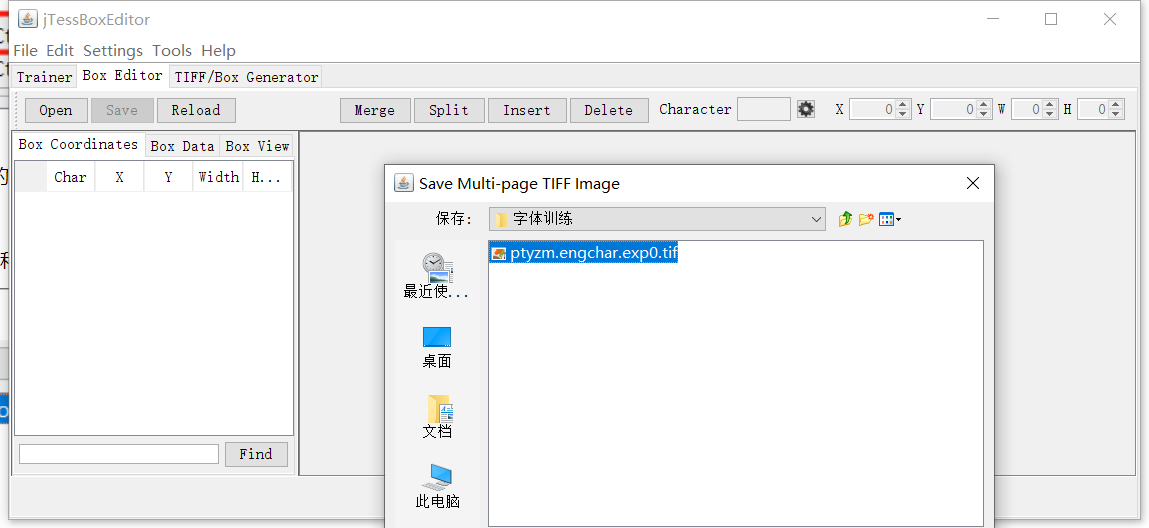
4、使用tesseract生成.box文件:
在当前文件夹运行cmd(定位到文件夹,然后在地址栏直接输入cmd,回车即可)
运行命令
tesseract ptyzm.engchar.exp0.tif ptyzm.engchar.exp0 -l eng -psm 7 batch.nochop makebox

行完之后会生成ptyzm.engchar.exp0.box文件。
可以看到生成了box文件

5、使用jTessBoxEditor矫正.box文件的错误:
会自动关联box文件
因为图像分辨率问题,识别效果不是很好
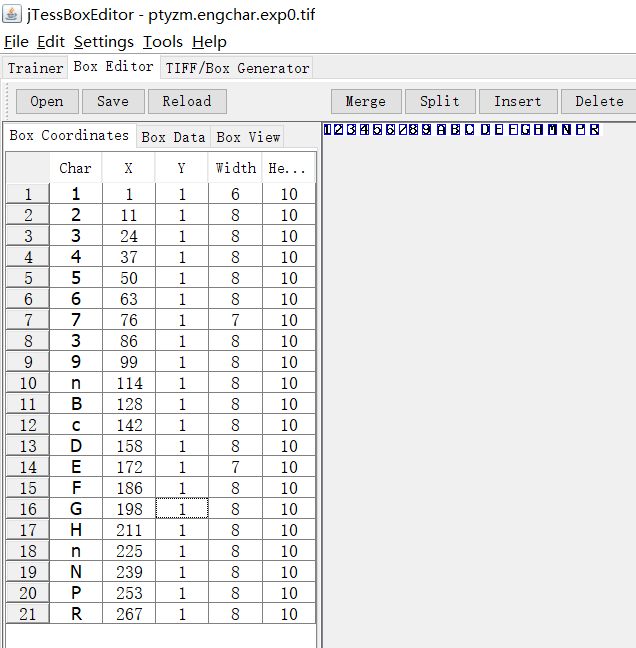
识别错误的,修改之后 点击save
6、生成font_properties文件:(该文件没有后缀名)
(1)执行命令,执行完之后,会在当前目录生成font_properties文件
然后执行命令,0表示字体test的粗体、倾斜等共计5个属性。也可以直接手动创建这个文件
echo engchar 0 0 0 0 0 >font_properties
执行完之后,会在当前目录生成font_properties文件
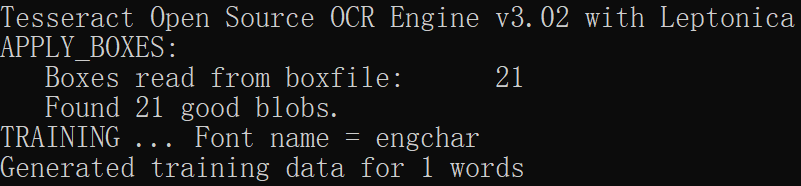
7、使用tesseract生成.tr训练文件:
执行下面命令,执行完之后,会在当前目录生成ptyzm.engchart.exp0.tr文件。
tesseract ptyzm.engchar.exp0.tif ptyzm.engchar.exp0 nobatch box.train

8、生成字符集文件:
执行下面命令:执行完之后会在当前目录生成一个名为“unicharset”的文件。
unicharset_extractor ptyzm.engchar.exp0.box


9、生成shape文件:
执行下面命令,执行完之后,会生成 shapetable 和engchar.unicharset 两个文件。
shapeclustering -F font_properties -U unicharset -O engchar.unicharset ptyzm.engchar.exp0.tr

。
。
。

生成的文件


10、生成聚字符特征文件:
执行下面命令,会生成 inttemp、pffmtable、shapetable和zwp.unicharset四个文件。
mftraining -F font_properties -U unicharset -O ptyzm.engchar ptyzm.engchar.exp0.tr
11、生成字符正常化特征文件:
执行下面命令,会生成 normproto 文件。
cntraining ptyzm.engchar.exp0.tr


12、文件重命名:
重新命名inttemp、pffmtable、shapetable和normproto这四个文件的名字为[lang].xxx。
这里修改为zwp.inttemp、zwp.pffmtable、zwp.shapetable和zwp.normproto
执行下面命令:
rename normproto engchar.normproto
rename inttemp engchar.inttemp
rename pffmtable engchar.pffmtable
rename shapetable engchar.shapetable
13、合并训练文件:
执行下面命令,会生成zwp.traineddata文件。
combine_tessdata engchar.

生成了训练文件

改个名字,就可以用啦

还是刚才的图片

tesseract ocr训练 pt验证码的更多相关文章
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
- tesseract 字体训练资料篇
tesseract 字体训练资料篇 1.制作.box档案文件. tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] ...
- Python&selenium&tesseract自动化测试随机码、验证码(Captcha)的OCR识别解决方案参考
在自动化测试或者安全渗透测试中,Captcha验证码的问题经常困扰我们,还好现在OCR和AI逐渐发展起来,在这块解决上越来越支撑到位. 我推荐的几种方式,一种是对于简单的验证码,用开源的一些OCR图片 ...
- 使用Tesseract OCR识别验证码
1.下载Tessrac OCR,默认安装 2.把验证码code.jpg图片放在D盘 3.打开cmd,进入D盘,输入:tesseract code.jpg result 4.进入D盘,生成了resul ...
随机推荐
- UVA - 11327
UVA - 11327https://vjudge.net/problem/28358/origin求欧拉函数的前缀和,二分查找到那个位置,再从它开始暴力gcd找 #include <iostr ...
- 【转载】objective-c强引用与弱引用
形象比喻蛮好玩的^_^ __weak 和 __strong 会出现在声明中 默认情况下,一个指针都会使用 __strong 属性,表明这是一个强引用.这意味着,只要引用存在,对象就不能被销毁 ...
- laravel框架中使用QueryList插件采集数据
laravel框架中使用queryList 采集数据 采集数据对我们来说真家常便饭,那么苦苦的写正则采集那么一点点东西,花费了自己大把的时间和精力而且没有一点技术含量,这个时候就是使用我们的好搭档Qu ...
- System.Web.Mvc.JsonResult.cs
ylbtech-System.Web.Mvc.JsonResult.cs 1.程序集 System.Web.Mvc, Version=5.2.3.0, Culture=neutral, PublicK ...
- linux 最新化安装后安卓 KDE 桌面
yum -y install epel-releaseyum -y groupinstall "X Window System"yum -y groupinstall " ...
- C++给组合框控件(Combo box)加变量后不能运行
是一个BUG,找出你程序存储的位置,打开一个Debug的文件夹,将除.res文件之外的所有文件删除,然后运行,就可以了!!
- hbase master一直报启动不起来问题(region空洞和region卡在spilt)
数据不重要或者一直卡着的情况下,可以切换hdfs用户到hbase的wal目录下对spilting的数据进行重命名.具体步骤如下 1.关闭hbase集群 2.切换hdfs用户 3.到hbasewal目录 ...
- 新手redis集群搭建
redis集群搭建在开始redis集群搭建之前,我们先简单回顾一下redis单机版的搭建过程 下载redis压缩包,然后解压压缩文件:进入到解压缩后的redis文件目录(此时可以看到Makefile文 ...
- 初学C#的简单编程题合集(更新)
一 编写一个控制台应用程序,要求完成下列功能. 1) 接收一个整数 n. 2) 如果接收的值 n 为正数,输出 1 到 n 间的全部整数. 3) 如果接收的值为负值,用 break 或者 ...
- [转]WPF的Presenter(ContentPresenter)
这是2年前写了一篇文章 http://www.cnblogs.com/Clingingboy/archive/2008/07/03/wpfcustomcontrolpart-1.html 我们先来看M ...