Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
ResponseProcessor是DataStreamer的一个内部类
DataNode接收到Packet后需要向客户端回复ACK,表示自己已经收到Packet了,而接收处理ACK的线程类就是ResponseProcessor。
对每一个块的传输都需要新建一个ResponseProcessor,当块传输完,客户端会通过endBlock方法间接地把当前ResponseProcessor销毁掉。下次传输新的Block的时候通过初始化传输环境方法initDataStreaming来间接地创建ResponseProcessor。
本文主要是研究ResponseProcessor的run方法是怎么接收处理DataNode发来的ACK的。
首先分析他的成员变量

1. responderCloserd代表自己是否关闭,可以发现这个变量是volatile的,说明是和其他线程共享的变量,并且根据happens-before原则和变量名的含义,这个变量应该是类似开关功能,其他线程通过此开关来对ResponseProcessor线程进行控制
2.targets,这个DataNodeInfo数组存储的是一组DataNode的信息,一般是流水线上的DataNode。也就是ResponseProcessor接收ACK的来源
3.isLastPacketInBlock,这个变量用来表示ResponseProcessor是否接收到了结尾Packet的ACK,一个完整的Block的组成为:数据Packet(若干个) + 结尾Packet(一般一个)。客户端需要收到这些Packet的ACK才知道自己发送的Packet被接收成功。

在run方法的开头就已经创建了一个代表ACK的类,用来表示接收到的DataNode的ACK。
并且通过一个while循环来维持ACK的接收,当. ResponseProcessor不被DataStreamer关闭,. 客户端正在运行,. 最后一个收到的ACK包不是针对结尾包的回复。
这样的话ResponseProcessor会持续地监听流水线,看看是否有ACK发过来。
接着,ResponseProcessor获取ACK的序号,关于

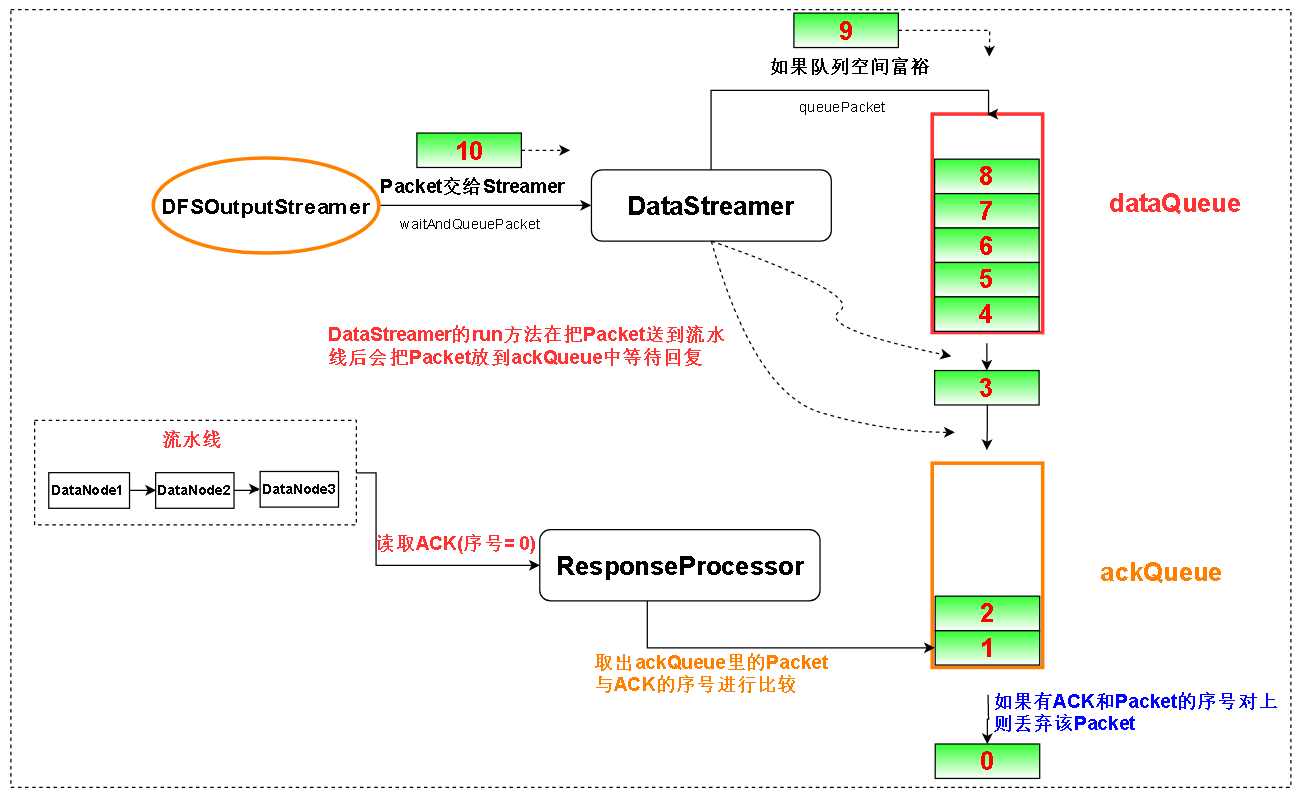
1框中表示的是ACK的序号,在客户端和DataNode的通信中,数据是以Packet为单位进行传输的,每个Packet都有一个独一无二的序号。第一个发送的Packet的序号是0,第二个是1,第三个是2......
所以每个Packet的序号都是独一无二的,因此ResponseProcessor可以根据ACK反馈的序号得知这个ACK对应哪个Packet,流水线Packet和ACK的序号一对一如图。
PacketX之后的Packet(X+1)不用等到ACKX收到了才发送,发送线程DataStreamer和接收线程ResponseProcessor是并行工作的。这样有助于提高效率(如果CPU只有一个核,那就是并发)
下图中SETUP RESPONSE是DataNode回应客户端架设流水线请求。
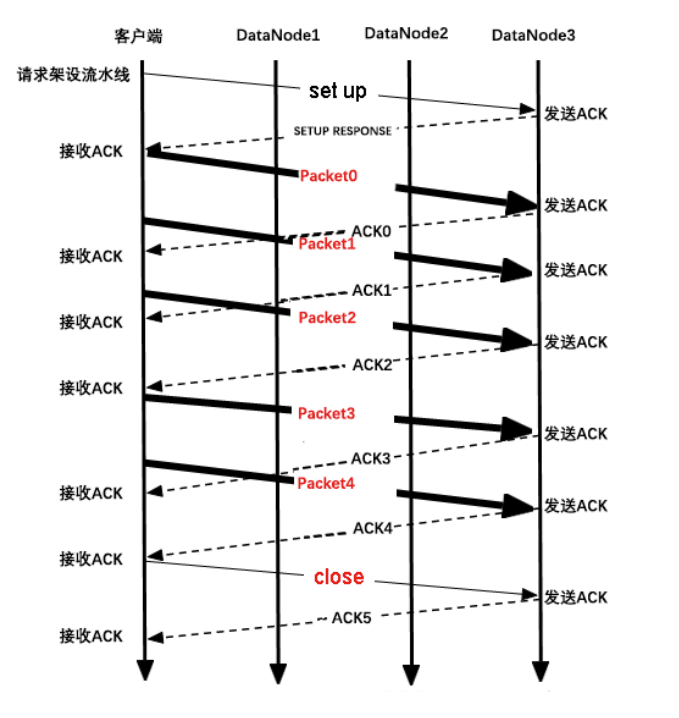
关于序号:
序号是从0开始计数的,序号为-1的Packet是心跳包,客户端用他来告诉DataNode客户端还活着。序号为-2的包为未知包,收到这个包需要抛出异常。
为了方便我们把上面那张图拉下来
序号2的框中,我们注意到congested这个词,这个词代表”拥堵“的,其实简单明了了,也就是代表2处的ArrayList是用来存储工作繁忙的DataNode(的相关信息)的。
那么是怎么判断哪些DataNode繁忙呢?是从我们的ack变量,也就是从DataNode发来的ACK里得知的。我们在框3处从ACK包的头信息里读取到DataNode的所有状态。
那么ack从哪里得到ACK的消息呢?ack通过读取流水线输入流来获取ACK信息。
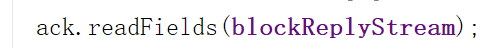
再到框4查看是否有工作繁忙的DataNode,有的话就加到ArrayList里。
再看一下是否有正在重启的DataNode,如果有,让记录错误状态的对象errorState把这个DataNode在nodes数组里的

我们在他的官方注释里看到,只有本地节点,也就是和客户端在同一主机上的DataNode,或者是流水线上只有他一个节点的DataNode才能被区别对待。
什么是区别对待?虽然说下面的代码总是会抛出异常,不管是否是本地(Local)节点还是远程(Remote)节点。
但是打开initRestarting方法看下,会发现如果我们的shouldWait传进去的如果是true,那么将会把将当前传进来的节点标记为正在重启的节点
并且为他设置重启时限,把BadNode记录清除掉(这时的BadNode一般是流水线上第一个DataNode,BadNode指的是工作过程发生错误或者无法联系上的DataNode)
否则直接将表示现在是否在等待DataNode重启的waitForRestart标志设置为false,表示没有在等待任何DataNode重启。
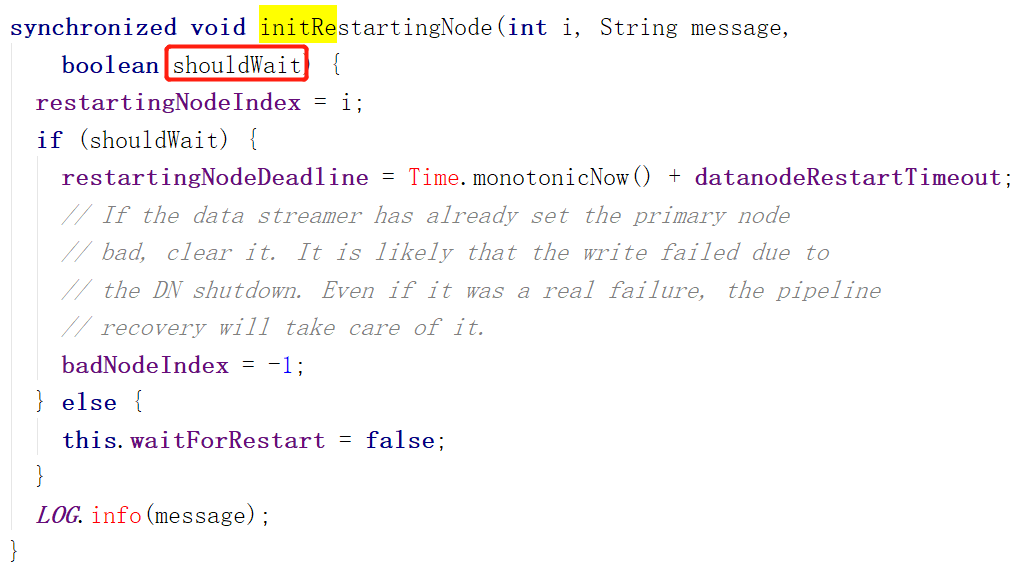
解读一下官方注释:如果我们把流水线上第一个节点标记为BadNode的话,那么取消对他的标记。流水线之所以发生错误可能是因为某个DataNode正在重启,于是我们试图等待他重启。
就算不是因为正在重启,而是因为宕机等错误让流水线失败,在流水线恢复的时候,客户端也会注意排除掉BadNode的。
再往下看,ResponseProcessor检查ACK的回应是否是SUCCESS,如果不是,表示对应的DataNode没有正常接收Packet,那么将把该DataNode标记为BadNode。

要注意的是,setBadNodeIndex是在for循环里的,而for循环是对ACK中每一个DataNode的回应进行检查。ack变量读到的是流水线上所有DataNode的ACK(注意大小写ACK,ack是不同的。大写表示
DataNode的Acknowledge,而小写指的是收集了流水线上所有ACK的一个对象)
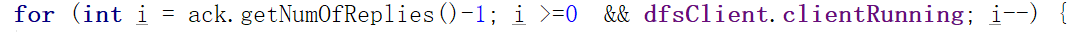
我们发现这个for循环是从数组下标大到小遍历的。也就是说,如果流水线上许多DataNode有错误,那么最后是离客户端最近的DataNode被设置为BadNode(nodes数组是DataStreamer的成员变量,用来存储流水线上DataNode的信息,0下标DataNode是流水线上第一个节点1下标DataNode是第二个节点,依次类推)(这里的数组下标其实最后会用到nodes数组上,因为errorState是DataStreamer的成员变量)
也就解释了上面initRestarting,为什么一般是第一个DataNode是BadNode。到此,对ack中各个DataNode的回复检查结束。
(左图)再下一步是将上面得到的繁忙节点加入到DataStreamer的成员变量congestedNodes中,这个变量用来标记所有繁忙节点,以便输出日志(DataStreamer的backIfNecessary)的时候观察哪些节点繁忙。
(右图)右图首先判断这个发来的ACK是否是一个心跳包,如果是就直接继续下一次ack对流水线的读取。这样做是因为,往下的步骤是针对数据包的工作,是心跳包则不用执行。

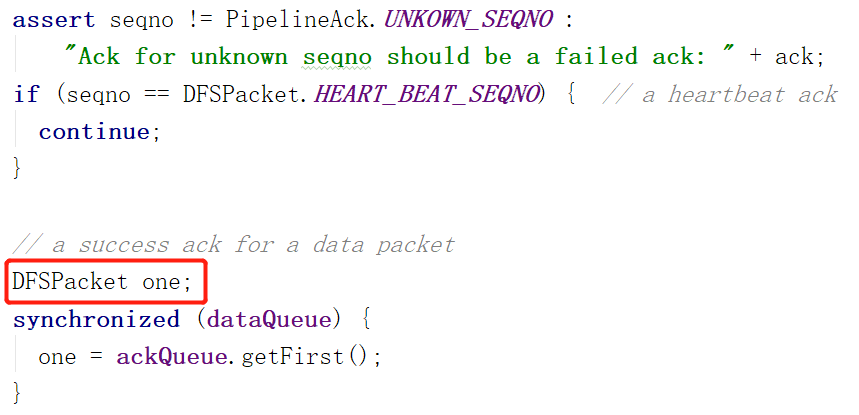
上右图中,声明了变量one,这是一个DFSPacket,也就是数据包,再往下看,one是从ackQueue队列中取出来的。为什么是ackQueue呢?这不是ACK队列的意思吗?装的应该是ACK啊,而
为什么能取出数据Packet?这是因为DataStreamer的恢复机制:

ackQueue里确实是数据包,只是等待确认的数据包。如果数据包发出去之后流水线失败,得不到确认。数据包可以从ackQueue恢复,不至于以前的Packet丢失。

首先看一下,收到的ACK的序号和ackQueue队头元素的序号一不一样,如果不一样,说明可能收发乱序了。Packet的收发是有顺序的,比如两个Packet,序号为0和1。
0先发出去,1后发。那么收到的ACK的顺序应该也是0,1。不然的话可能是网络或其他原因,导致收发乱序。
下一步,当前Block发送出去的数据量增加了,应该设置一下。getLastByteOffsetBlock其实就是最后一个包的结尾相对Block起始位置的偏移量。也就是现在写了的数据量。
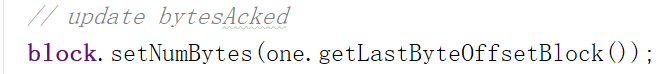
接下来就是一些状态设置。其中比较重要的是:
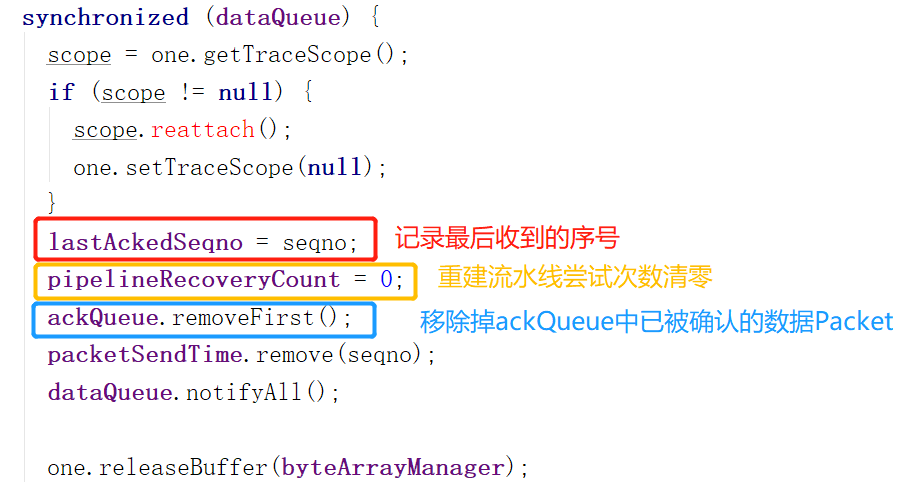
pipelineRecoveryCount这个变量在DataStreamer的processDatanodeOrExternalError方法里有用到,这个方法在流水线有错误的时候调用,记录重新架设流水线的重试次数。
如果这个变量超过了5,那么就会停止重试,并且抛出异常,关闭DataStreamer,表示流水线架设失败,数据传输终止。
上图设置成0,表示流水线通畅了,能正常接收ACK了,于是设置成0。
接下来,我们看看ResponseProcessor的错误处理
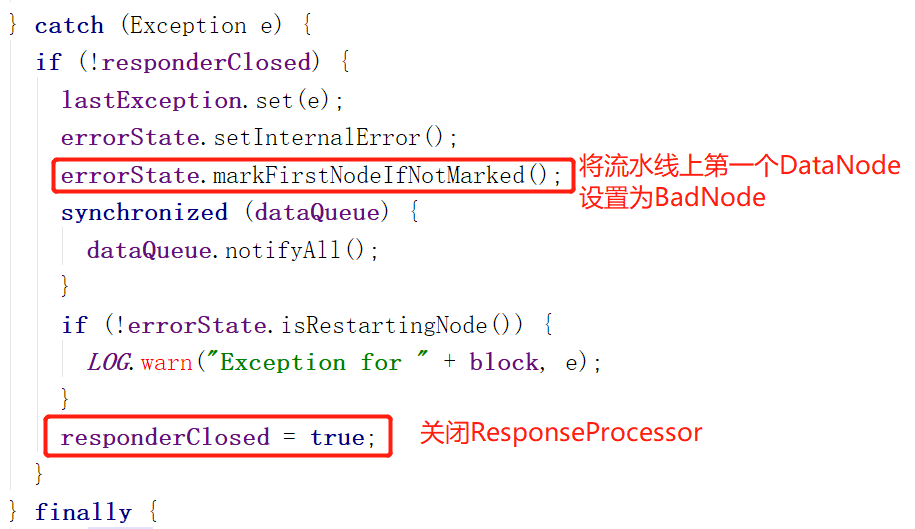
其中比较有意思的是 markFirstNodeIfNotMarked 这个方法。

我们来看看他的官方注释:
这个方法在数据传输过程中遇到不明错误的时候调用,为什么要把第一个DataNode设置为BadNode呢?因为客户端是直接和第一个DataNode通信的,所以他嫌疑最大。
所以说就算不是第一个DataNode的错误,第一个DataNode也躺枪......
上述就是ResponseProcessor的工作流程。
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)的更多相关文章
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立) 我们提到, ...
- Hadoop3.1.1源码Client详解 : 入队前数据写入
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇: Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立 先给出 ...
- Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 关于RPC(Remote Procedure Call),如果没有概念,可以参考一下RMI(Remot ...
- Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
一.设计原理 1.Hadoop架构: 流水线(PipeLine) 2.Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS 3.Hadoop架构: 关于Recovery (Lease ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- Nop--NopCommerce源码架构详解专题目录
最近在研究外国优秀的ASP.NET mvc电子商务网站系统NopCommerce源码架构.这个系统无论是代码组织结构.思想及分层都值得我们学习.对于没有一定开发经验的人要完全搞懂这个源码还是有一定的难 ...
- vue项目打包后使用reverse-sourcemap反编译到源码(详解版)
首先得说一下,vue项目中productionSourceMap这个属性.该属性对应的值为true|false. 当productionSourceMap: true,时: 1.打包后能看到xxx ...
- linux 基础入门(8) 软件安装 rpm、yum与源码安装详解
8.软件 RPM包安装 8.1rpm安装 rpm[选项]软件包名称 主选项 -i 安装 -e卸载 -U升级 -q查找 辅助选项 -ⅴ显示过程 -h --hash 查询 -a-all查询所有安装的包 - ...
随机推荐
- 1米(m)=10分米(dm)=10^2厘米(cm)=10^3毫米(mm) =10^6微米(um)=10^9纳米(nm)=10^10埃米(A)=10^12皮米(pm)
millimeter 毫米 micrometer 微米 nanometer 纳米 square meter 平方米
- 野路子码农(5)Python中的装饰器,可能是最通俗的解说
装饰器这个名词一听就充满了高级感,而且很多情况下确实也不常用.但装饰器有装饰器的好处,至少了解这个对装逼还是颇有益处的.网上有很多关于装饰器的解说,但通常都太过“循序渐进”,有的还会讲一些“闭包”之类 ...
- 在电脑上用chrome浏览器调试android手机里的网页代码时,无法看到本地加载的js文件
在需要调试的js文件最顶部加上代码就可以看到了: console.log('haha'); debugger;
- 解决sql server2008数据库安装之后,web程序80端口被占用问题(终极方案)
解决sql server2008数据库安装之后,web程序80端口被占用问题(终极方案) 前言:原来电脑上的Apache一直使用正常,在安装sql server2008后,突然发现Apache无法启动 ...
- python之路正则补充模块
match(从头匹配) 无分组 有分组=====================有括号 ======================================================= ...
- 使用API进行文件读写——CreateFile,ReadFile,WriteFile等
看了这个帖子: http://www.vbgood.com/thread-99249-1-1.html 就写了一个使用API读写文件的简单类,苦力活. 演示代码在附件里. '********* ...
- 09 部署nginx web服务器(转发uwsgi请求)
1 配置nginx转发 $ whereis nginx $ cd /usr/local/nginx/conf $ vi nginx.conf 注释掉原来的html请求,增加uwsgi请求. locat ...
- AST抽象语法树——最基础的javascript重点知识,99%的人根本不了解
AST抽象语法树——最基础的javascript重点知识,99%的人根本不了解 javascriptvue-clicommonjswebpackast 阅读约 27 分钟 抽象语法树(AST),是一 ...
- Vue开发重点基础知识
1.Vuejs组件 vuejs构建组件使用 Vue.component('componentName',{ /*component*/ }): 这里注意一点,组件要先注册再使用,也就是说: Vue.c ...
- Lombok(浅看,自用)
Lombok 首先是几个常用的注解(最常用到的方法,超简单的用) @Data @AllArgsConstructor @NoArgsConstructor public class Trial_Pro ...