tensorflow识别验证码(2)-tensorflow 编写CNN 识别验证码
1. 导入依赖包
#coding:utf-8
from gen_captcha import gen_captcha_text_and_image
from gen_captcha import number
from gen_captcha import alphabet
from gen_captcha import ALPHABET
import numpy as np
import tensorflow as tf #tensorflow2.生成验证码用于训练模型
text, image = gen_captcha_text_and_image() #先生成验证码和文字测试模块是否完全
print("验证码图像channel:", image.shape) # (60, 160, 3)
# 图像大小
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
MAX_CAPTCHA = len(text)
print("验证码文本最长字符数", MAX_CAPTCHA) # 验证码最长4字符; 我全部固定为4,可以不固定. 如果验证码长度小于4,用'_'补齐
# 把彩色图像转为灰度图像(色彩对识别验证码没有什么用)
def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
# 上面的转法较快,正规转法如下
# r, g, b = img[:,:,0], img[:,:,1], img[:,:,2]
# gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
else:
return img
"""
cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。
np.pad(image【,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行
"""
# 文本转向量
char_set = number + alphabet + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐
CHAR_SET_LEN = len(char_set)
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('验证码最长4个字符')
vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
def char2pos(c):
if c =='_':
k = 62
return k
k = ord(c)-48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k
for i, c in enumerate(text):
idx = i * CHAR_SET_LEN + char2pos(c)
vector[idx] = 1
return vector
# 向量转回文本
def vec2text(vec):
char_pos = vec.nonzero()[0]
text=[]
for i, c in enumerate(char_pos):
char_at_pos = i #c/63
char_idx = c % CHAR_SET_LEN
if char_idx < 10:
char_code = char_idx + ord('0')
elif char_idx < 36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx- 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
return "".join(text)
"""
#向量(大小MAX_CAPTCHA*CHAR_SET_LEN)用0,1编码 每63个编码一个字符,这样顺利有,字符也有
vec = text2vec("F5Sd")
text = vec2text(vec)
print(text) # F5Sd
vec = text2vec("SFd5")
text = vec2text(vec)
print(text) # SFd5
"""
# 生成一个训练batch
def get_next_batch(batch_size=128):
batch_x = np.zeros([batch_size, IMAGE_HEIGHT*IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA*CHAR_SET_LEN])
# 有时生成图像大小不是(60, 160, 3)
def wrap_gen_captcha_text_and_image():
''' 获取一张图,判断其是否符合(60,160,3)的规格'''
while True:
text, image = gen_captcha_text_and_image()
if image.shape == (60, 160, 3):#此部分应该与开头部分图片宽高吻合
return text, image
for i in range(batch_size):
text, image = wrap_gen_captcha_text_and_image()
image = convert2gray(image)
# 将图片数组一维化 同时将文本也对应在两个二维组的同一行
batch_x[i,:] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0
batch_y[i,:] = text2vec(text)
# 返回该训练批次
return batch_x, batch_y3.定义CNN
####################################################################
# 申请占位符 按照图片
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
# 定义CNN
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
# 将占位符 转换为 按照图片给的新样式
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
#w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) #
#w_c2_alpha = np.sqrt(2.0/(3*3*32))
#w_c3_alpha = np.sqrt(2.0/(3*3*64))
#w_d1_alpha = np.sqrt(2.0/(8*32*64))
#out_alpha = np.sqrt(2.0/1024)
# 3 conv layer
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32])) # 从正太分布输出随机值
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
w_c2 = tf.Variable(w_alpha*tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha*tf.random_normal([64]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
w_c3 = tf.Variable(w_alpha*tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha*tf.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
# Fully connected layer
w_d = tf.Variable(w_alpha*tf.random_normal([8*20*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, keep_prob)
w_out = tf.Variable(w_alpha*tf.random_normal([1024, MAX_CAPTCHA*CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha*tf.random_normal([MAX_CAPTCHA*CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
#out = tf.nn.softmax(out)
return out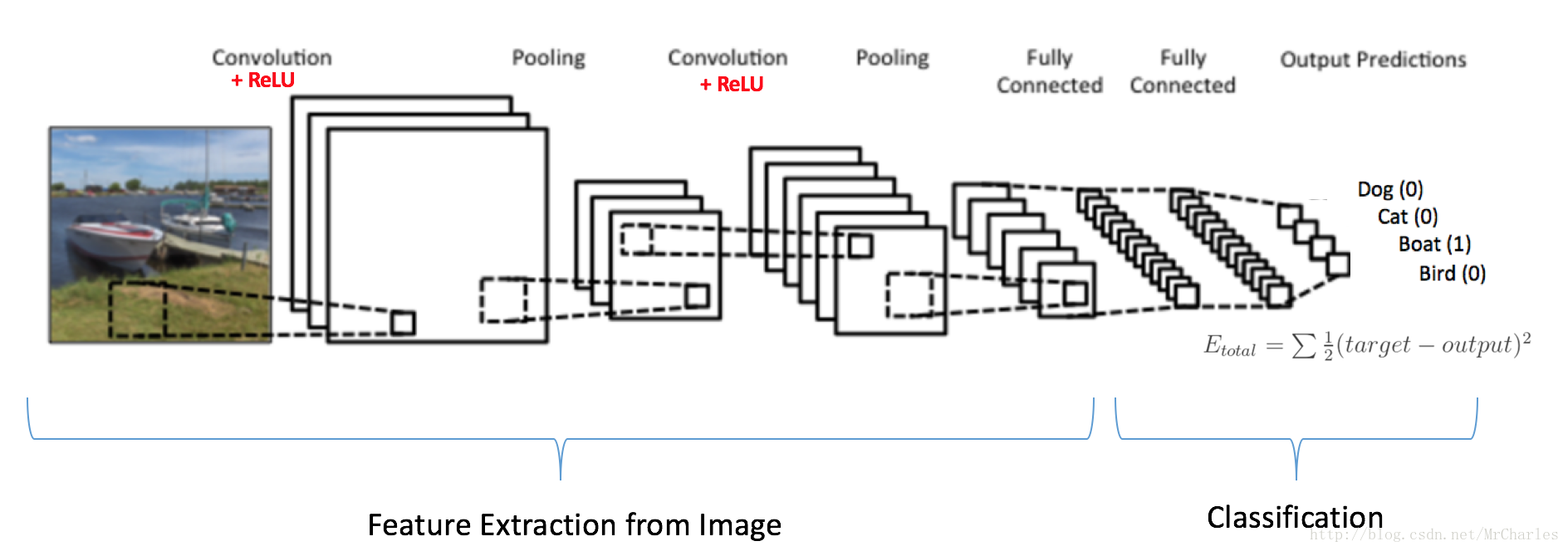

上图就是一个典型的CNN模型,但是只有两层卷积,我们这里有三层。
左边:
数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
中间:
- CONV:卷积计算层,线性乘积 求和。
- RELU:激励层,上文2.2节中有提到:ReLU是激活函数的一种。
- POOL:池化层,简言之,即取区域平均或最大。
右边:FC:全连接层
代码解释:
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32])) # 从正太分布输出随机值
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
权值初始化
为了建立模型,我们需要先创建一些权值(w)和偏置(b)等参数,这些参数的初始化过程中需要加入一小部分的噪声以破坏参数整体的对称性,同时避免梯度为0.由于我们使用ReLU激活函数,所以我们通常将这些参数初始化为很小的正值。
一般卷积层之后会跟一个池化层,所以我们将他们的组合看做一个整体。
这层卷积层总共设置32个神经元,也就是有32个卷积核去分别关注32个特征。窗口的大小是3×3,所以指向每个卷积层的权重也是3×3,因为图片是黑白色的,只有一个颜色通道,所以总共只有1个面,故每个卷积核都对应一组3*3 * 1的权重。
因此w权重的tensor大小应是[3,3,1,32]
b权重的tensor大小应是[ 32 ]
初始化这两个权重:
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32])) # 从正太分布输出随机值
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
卷积(Convolution)和池化(Pooling)
TensorFlow同样提供了方便的卷积和池化计算。怎样处理边界元素?怎样设置卷积窗口大小?在这个例子中,我们始终使用vanilla版本。这里的卷积操作仅使用了滑动步长为1的窗口,使用0进行填充,所以输出规模和输入的一致;而池化操作是在2 * 2的窗口内采用最大池化技术(max-pooling)。
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME') #使用了滑动步长为1的窗口,使用0进行填充,所以输出规模和输入的一致其中,padding='SAME'表示通过填充0,使得输入和输出的形状一致。
tf.nn.bias_add(conv2d......, b_c1) 对x_image进行卷积计算,加上bias,再应用到一个ReLU激活函数,最终采用最大池化。
tf.nn.relu(........)
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')

全连接层
w_d = tf.Variable(w_alpha*tf.random_normal([8*20*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
Dropout
# 训练
def train_crack_captcha_cnn():
output = crack_captcha_cnn()
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y))
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y))
# 最后一层用来分类的softmax和sigmoid有什么不同?
# optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
max_idx_p = tf.argmax(predict, 2)
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 0
while True:
batch_x, batch_y = get_next_batch(64)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
print(step, loss_)
# 每100 step计算一次准确率
if step % 100 == 0:
batch_x_test, batch_y_test = get_next_batch(100)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print(step, acc)
# 如果准确率大于50%,保存模型,完成训练
if acc > 0.5:
saver.save(sess, "crack_capcha.model", global_step=step)
break
step += 1
train_crack_captcha_cnn()执行脚本,报错,
File "C:\Program File\Python\Python35-02\lib\site-packages\tensorflow\python\platform\self_check.py", line 82, in preload_check
% (build_info.cudart_dll_name, build_info.cuda_version_number))
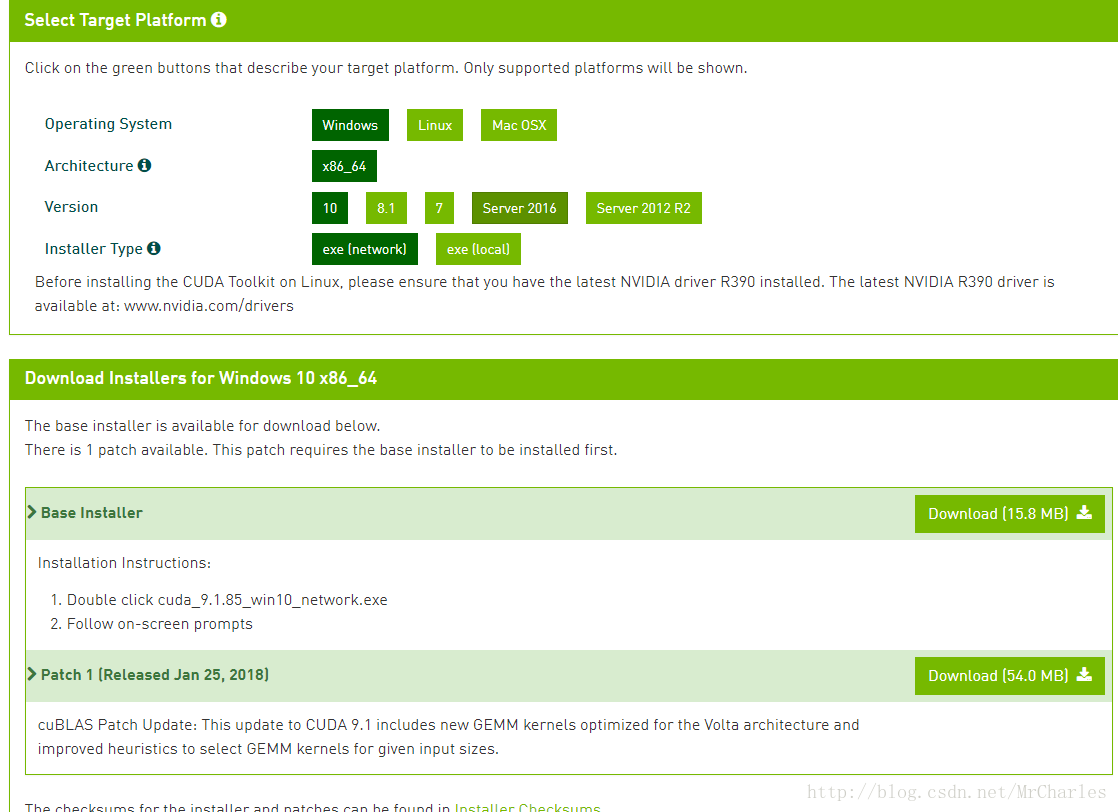
ImportError: Could not find 'cudart64_90.dll'. TensorFlow requires that this DLL be installed in a directory that is named in your %PATH% environment variable. Download and install CUDA 9.0 from this URL: https://developer.nvidia.com/cuda-toolkit
CUDA缺失,这告诉我们,没有GPU驱动,安装驱动即可。到这个地址下载驱动https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exenetwork
http://www.laurencemoroney.com/installing-tensorflow-with-gpu-on-windows-10/ 这个文章详细介绍了GPU驱动
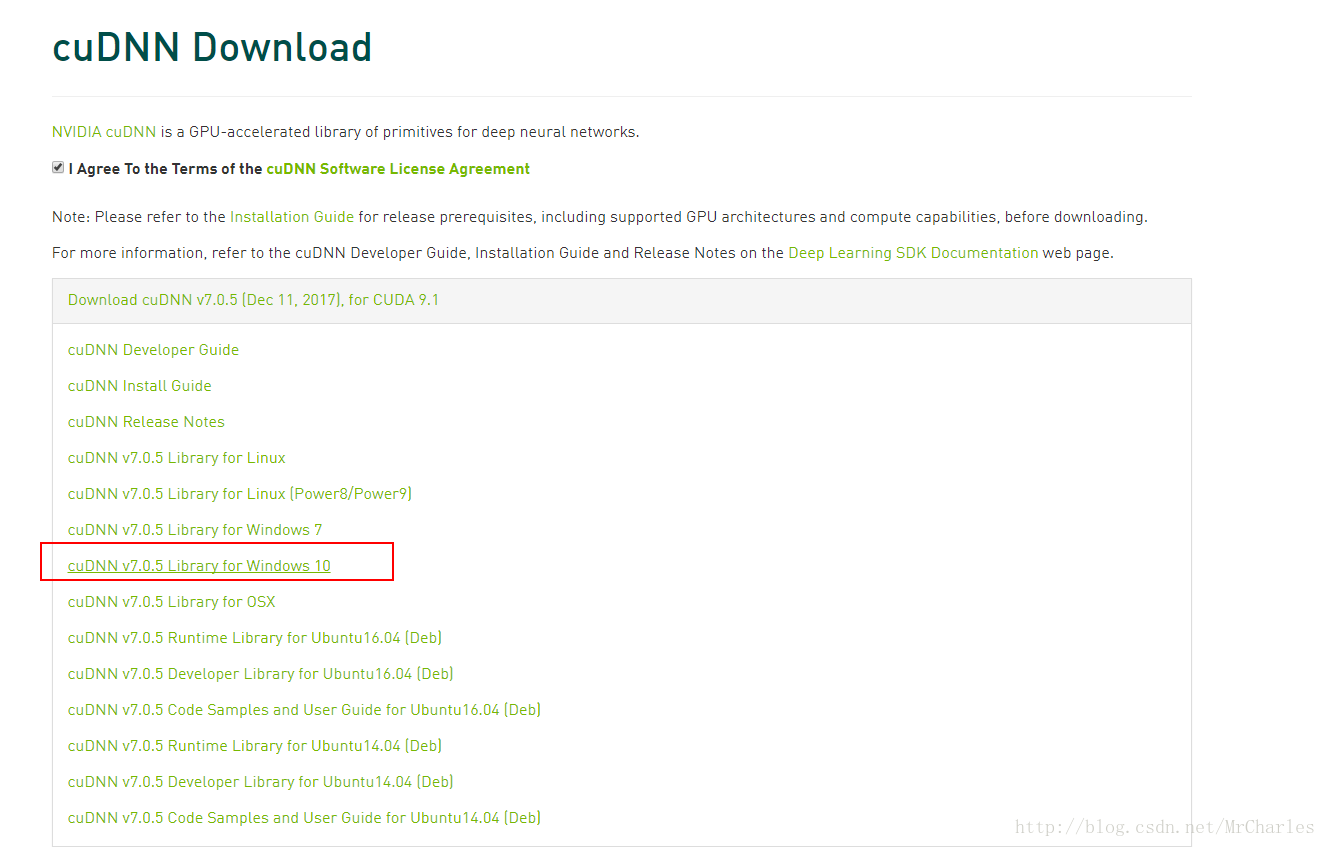
第二个安装cuDNN
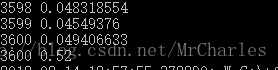
运行3600循环之后,准确率:0.52左右
tensorflow识别验证码(2)-tensorflow 编写CNN 识别验证码的更多相关文章
- tensorFlow(六)应用-基于CNN破解验证码
TensorFlow基础见前博客 简介 传统的验证码识别算法一般需要把验证码分割为单个字符,然后逐个识别.本教程将验证码识别问题转化为分类的问题,实现对验证码进行整体识别. 步骤简介 本教程一共分为四 ...
- Python Tensorflow CNN 识别验证码
Python+Tensorflow的CNN技术快速识别验证码 文章来源于: https://www.jianshu.com/p/26ff7b9075a1 验证码处理的流程是:验证码分析和处理—— te ...
- Tensorflow搭建CNN实现验证码识别
完整代码:GitHub 我的简书:Awesome_Tang的简书 整个项目代码分为三部分: Generrate_Captcha: 生成验证码图片(训练集,验证集和测试集): 读取图片数据和标签(标签即 ...
- 基于tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的人工智能技术的发展 ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
- 6 TensorFlow实现cnn识别手写数字
------------------------------------ 写在开头:此文参照莫烦python教程(墙裂推荐!!!) ---------------------------------- ...
- 使用卷积神经网络CNN完成验证码识别
gen_sample_by_captcha.py 生成验证码图片 # -*- coding: UTF-8 -*- """ 使用captcha lib生成验证码(前提:pi ...
- CNN识别验证码1
之前学习python的时候,想尝试用requests实现自动登陆,但是现在网站登陆都会有验证码保护,主要是为了防止暴力破解,任意用户注册.最近接触深度学习,cnn能够进行图像识别,能够进行验证码识别. ...
- 端到端图片识别 Python实现 Tensorflow
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
随机推荐
- HDU3342:判断有向图中是否存在3元环-Tarjan或拓扑排序
题目大意: 给你一个关系图,判断是否合法.每个人都有师父和徒弟,可以有很多个: 若A是B的师父,B是C的师父,则A也算C的师父. 不合法: 1) . 互为师徒:(有回路) 2) .你的师父是你徒弟 ...
- spring-helloworld (1)
目录 一.eclipse安装springsource-tools插件 二.新建maven工程,引入spring配置 三.添加helloworld类 四.使用springsource-tools插件 创 ...
- trackback 捕获异常并打印
### 1 except Exception as e: print(traceback.format_exc()) def _handle_thread_exception(request, exc ...
- Java-Class-C:com.alibaba.fastjosn.JSON
ylbtech-Java-Class-C:com.alibaba.fastjosn.JSON 1.返回顶部 1.1.import com.alibaba.fastjson.JSON;import co ...
- 配置Tomcat-8.5 JVM内存参数
配置Tomcat-8.5 JVM内存参数 apache-tomcat-8.5与之前的版本存在些许差异,配置方式有所改变,并且针对JVM一些参数不再支持.故本文档主要简介一下如何在apache-tomc ...
- scrapy-redis + Bloom Filter分布式爬取tencent社招信息
scrapy-redis + Bloom Filter分布式爬取tencent社招信息 什么是scrapy-redis 什么是 Bloom Filter 为什么需要使用scrapy-redis + B ...
- mysql key分区,分区数制定
我相信不 太注意的同学肯定会入坑,今天我差点也入坑了,后面自己问自己如果我用key分区,自己问自己 我的分区数应该是多少??? 后面我陷入了沉思......... 我第一次想先随便弄一个分区数,在本地 ...
- 如何通过SVN管理好代码
来自:http://blog.csdn.net/baronyang/article/details/6942434 ------------------------------------------ ...
- 【ArcObject】 AxTocControl:实现图层可移动
设置axTocControl属性:EnableLayerDragDrop 为true即可
- js正则表达式常见面试题
1 . 给一个连字符串例如:get-element-by-id转化成驼峰形式. var str = "get-element-by-id"; var reg = /-\w/g; / ...