分布式任务框架elastic-job 学习笔记
官方资料:https://github.com/dangdangdotcom/elastic-job
-------------------------------------------------------------------------------------
官方资料非常完整而且思路清晰,按照自己学习过程整理如下:
1、 何为分布式任务?
自己理解,就是一件事情让多台机器来完成。单机环境下,所有任务都是单个电脑独立完成,分布式任务就是把任务按一定逻辑进行切分(也就是所谓的分片),分成几个小的片段,然后分给不同的电脑,每台电脑执行其中的几个片段。
分片概念:
任务的分布式执行,需要将一个任务拆分为n个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
例如:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器应执行作业的50%。 为满足此需求,可将作业分成2片,每台服务器执行1片。作业遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。 如果分成10片,则作业遍历数据的逻辑应为:每片分到的分片项应为ID%10,而服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据。
2、 github源码
从github下载下来,maven导入eclipse后,分为5部分:

官方目录结构说明:
elastic-job-core //核心模块,只通过Quartz和Curator就可执行分布式作业。
elastic-job-spring //对spring支持的模块,包括命名空间,依赖注入,占位符等。
elastic-job-console // web控制台,可将编译之后的war放入tomcat等servlet容器中使用。
elastic-job-example //使用示例。
elastic-job-doc //使用markdown生成文档的项目,使用方无需关注。
需要说明一下,官方也提到了,需要一个lombok.jar。个人感觉这个确实很不错,有了这个jar包,可以省掉get set方法,在属性很多的时候特别方便。
*************************************************
lombok 的官方网址:http://projectlombok.org/
lombok 注解在线帮助文档:http://projectlombok.org/features/index. 下面介绍几个我常用的
lombok 注解:
@Data :注解在类上;提供类所有属性的 getting 和
setting 方法,此外还提供了equals、canEqual、hashCode、toString 方法
@Setter:注解在属性上;为属性提供
setting 方法
@Getter:注解在属性上;为属性提供
getting 方法
@Log4j :注解在类上;为类提供一个 属性名为log
的
log4j 日志对象
@NoArgsConstructor:注解在类上;为类提供一个无参的构造方法
@AllArgsConstructor:注解在类上;为类提供一个全参的构造方法
*************************************************
3、 快速上手部署应用(单机跟集群)
快速上手可以参照官方文档: http://dangdangdotcom.github.io/elastic-job/post/quick_start/
这是个单机环境的例子。为加深理解,自己部署集群环境,步骤如下:
a、启动zookeeper(测试用,可单机可集群),步骤参见官方快速上手文档
b、修改官方example代码如下:
1)、在com.dangdang.example.elasticjob.spring包下新建myjob包,创建新类MySimpleJobTest.java,代码如下:
@Component
public class MySimpleJobTest extends AbstractSimpleElasticJob { private PrintContext printContext = new PrintContext(SimpleJobDemo.class); @Resource
private FooRepository fooRepository; private static AtomicInteger count = new AtomicInteger(0); @Override
public void process(JobExecutionMultipleShardingContext shardingContext) {
System.out.println("第"+count.addAndGet(1)+"次执行,当前分片号为:"+shardingContext.getShardingItemParameters());
} }
2)、修改resources/META-INF/withNamespace.xml为:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:reg="http://www.dangdang.com/schema/ddframe/reg"
xmlns:job="http://www.dangdang.com/schema/ddframe/job"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.dangdang.com/schema/ddframe/reg
http://www.dangdang.com/schema/ddframe/reg/reg.xsd
http://www.dangdang.com/schema/ddframe/job
http://www.dangdang.com/schema/ddframe/job/job.xsd
">
<context:component-scan base-package="com.dangdang.example.elasticjob" />
<context:property-placeholder location="classpath:conf/*.properties" /> <reg:zookeeper id="regCenter" serverLists="${serverLists}" namespace="${namespace}" baseSleepTimeMilliseconds="${baseSleepTimeMilliseconds}" maxSleepTimeMilliseconds="${maxSleepTimeMilliseconds}" maxRetries="${maxRetries}" nestedPort="${nestedPort}" nestedDataDir="${nestedDataDir}" /> <!-- <job:bean id="simpleElasticJob" class="com.dangdang.example.elasticjob.spring.job.SimpleJobDemo" regCenter="regCenter" shardingTotalCount="${simpleJob.shardingTotalCount}" cron="${simpleJob.cron}" shardingItemParameters="${simpleJob.shardingItemParameters}" monitorExecution="${simpleJob.monitorExecution}" monitorPort="${simpleJob.monitorPort}" failover="${simpleJob.failover}" description="${simpleJob.description}" disabled="${simpleJob.disabled}" overwrite="${simpleJob.overwrite}" /> -->
<!-- <job:bean id="throughputDataFlowJob" class="com.dangdang.example.elasticjob.spring.job.ThroughputDataFlowJobDemo" regCenter="regCenter" shardingTotalCount="${throughputDataFlowJob.shardingTotalCount}" cron="${throughputDataFlowJob.cron}" shardingItemParameters="${throughputDataFlowJob.shardingItemParameters}" monitorExecution="${throughputDataFlowJob.monitorExecution}" failover="${throughputDataFlowJob.failover}" processCountIntervalSeconds="${throughputDataFlowJob.processCountIntervalSeconds}" concurrentDataProcessThreadCount="${throughputDataFlowJob.concurrentDataProcessThreadCount}" description="${throughputDataFlowJob.description}" disabled="${throughputDataFlowJob.disabled}" overwrite="${throughputDataFlowJob.overwrite}" /> -->
<!-- <job:bean id="sequenceDataFlowJob3" class="com.dangdang.example.elasticjob.spring.job.SequenceDataFlowJobDemo" regCenter="regCenter" shardingTotalCount="${sequenceDataFlowJob.shardingTotalCount}" cron="${sequenceDataFlowJob.cron}" shardingItemParameters="${sequenceDataFlowJob.shardingItemParameters}" monitorExecution="${sequenceDataFlowJob.monitorExecution}" failover="${sequenceDataFlowJob.failover}" processCountIntervalSeconds="${sequenceDataFlowJob.processCountIntervalSeconds}" maxTimeDiffSeconds="${sequenceDataFlowJob.maxTimeDiffSeconds}" description="${sequenceDataFlowJob.description}" disabled="${sequenceDataFlowJob.disabled}" overwrite="${sequenceDataFlowJob.overwrite}" /> --> <job:bean id="simpleElasticJob2" class="com.dangdang.example.elasticjob.spring.myjob.MySimpleJobTest" regCenter="regCenter" shardingTotalCount="${simpleJob.shardingTotalCount}" cron="${simpleJob.cron}" shardingItemParameters="${simpleJob.shardingItemParameters}" monitorExecution="${simpleJob.monitorExecution}" monitorPort="${simpleJob.monitorPort}" failover="${simpleJob.failover}" description="${simpleJob.description}" disabled="${simpleJob.disabled}" overwrite="${simpleJob.overwrite}" /> </beans>
c、建虚拟机(多台电脑的用另一电脑即可),配置环境变量。
此处本地采用ubuntu16.04的64位版本.
需配置的有:jdk,maven,为了让maven能在本地找到jar包,而不再浪费时间去网络maven库下载,可以线运行mvn install生成.m2目录(该目录隐藏,本地虚拟机是位于/home下),将win下的.m2/repository文件夹拷贝到虚拟机的.m2下.
d、将elastic-job-example拷贝到虚拟机,本地为/usr/mytest目录
修改虚拟机中example项目的配置文件/resources/conf/reg.properties
serverLists为zookeeper服务器地址
nestedPort设置为-1,不启动自带zookeeper(两台电脑都不启用默认zookeeper)
e、虚拟机切换到elastic-job-example目录(该目录下有pom文件)
运行:mvn compile ,运行完毕后
运行:mvn exec:java -Dexec.mainClass="com.dangdang.example.elasticjob.spring.main"
f、切回主机,com.dangdang.example.elasticjob.spring.main运行该文件的main方法
可明显看到:虚拟机开始单机运行时,处理分片为0-9,在主机开始运行后,变为5-9,两者确实进行了任务分配:
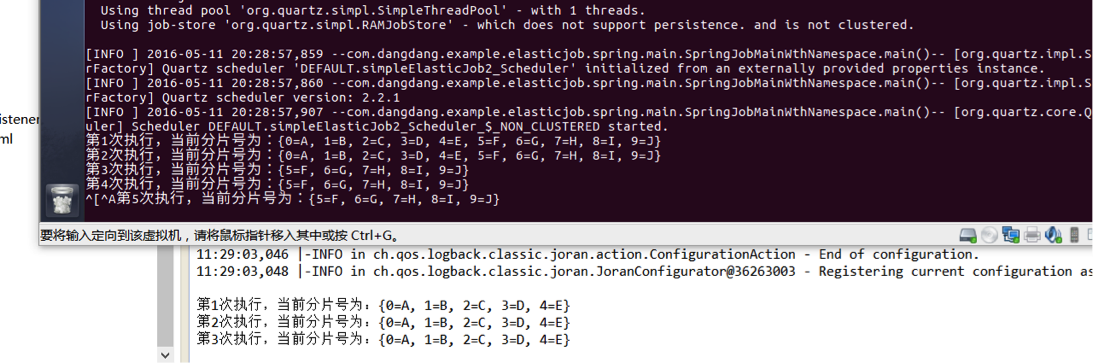
g、部署tomcat监控
虚拟机部署tomcat,将elastic-job-console在主机打war包,然后放入tomcat的webapp下,启动tomcat,访问http://ip:端口号/elastic-job-console,账号密码:root/root
填写zookeeper地址,作业名称等,可以看到控制页面:

我们刚刚部署的测试环境:

小结:
单纯开发使用的话,方式之一是:将elastic-job-core跟elastic-job-spring打jar包,然后按照官方的开发指南,重写相关方法即可。部署的话应该是按照上方集群部署的方式进行的。
至于具体分片怎么分(官方提供了几种方式,直接配置属性),具体内部调度原理,开发过程中具体应用等细节仍待思考。
补充:
ej的使用,方式之一是如上所说,jar引入,重写方法然后集群部署;方式之二是单独写一个调度项目,在此处进行“调度”,将分片信息以参数形式传递给远程方法接口,从而实现了将一个大的任务分割给了多个不同机器(这里边很可能由于远程也是分布式,
从而可能导致某机器多次接收之类,可能会并不那么均衡),从而减轻了单机压力。具体分片逻辑跟接口逻辑根据具体业务场景的不同而不同。东西是死的,具体怎么个用法,正如当当网张亮所言:怎么用都可以。
基于方式二的使用方式,即使不用ej框架,单纯的一个项目C用于定时请求某个远程接口,只要该远程接口是集群部署的,那么负载就会分发到不同的机器,从而导致某种程度上实现了多机器执行,虽然这只是分布式带来的福利而已。
分布式任务框架elastic-job 学习笔记的更多相关文章
- 机器学习框架ML.NET学习笔记【4】多元分类之手写数字识别
一.问题与解决方案 通过多元分类算法进行手写数字识别,手写数字的图片分辨率为8*8的灰度图片.已经预先进行过处理,读取了各像素点的灰度值,并进行了标记. 其中第0列是序号(不参与运算).1-64列是像 ...
- 机器学习框架ML.NET学习笔记【3】文本特征分析
一.要解决的问题 问题:常常一些单位或组织召开会议时需要录入会议记录,我们需要通过机器学习对用户输入的文本内容进行自动评判,合格或不合格.(同样的问题还类似垃圾短信检测.工作日志质量分析等.) 处理思 ...
- 机器学习框架ML.NET学习笔记【2】入门之二元分类
一.准备样本 接上一篇文章提到的问题:根据一个人的身高.体重来判断一个人的身材是否很好.但我手上没有样本数据,只能伪造一批数据了,伪造的数据比较标准,用来学习还是蛮合适的. 下面是我用来伪造数据的代码 ...
- 机器学习框架ML.NET学习笔记【1】基本概念与系列文章目录
一.序言 微软的机器学习框架于2018年5月出了0.1版本,2019年5月发布1.0版本.期间各版本之间差异(包括命名空间.方法等)还是比较大的,随着1.0版发布,应该是趋于稳定了.之前在园子里也看到 ...
- 机器学习框架ML.NET学习笔记【5】多元分类之手写数字识别(续)
一.概述 上一篇文章我们利用ML.NET的多元分类算法实现了一个手写数字识别的例子,这个例子存在一个问题,就是输入的数据是预处理过的,很不直观,这次我们要直接通过图片来进行学习和判断.思路很简单,就是 ...
- 机器学习框架ML.NET学习笔记【6】TensorFlow图片分类
一.概述 通过之前两篇文章的学习,我们应该已经了解了多元分类的工作原理,图片的分类其流程和之前完全一致,其中最核心的问题就是特征的提取,只要完成特征提取,分类算法就很好处理了,具体流程如下: 之前介绍 ...
- 机器学习框架ML.NET学习笔记【7】人物图片颜值判断
一.概述 这次要解决的问题是输入一张照片,输出人物的颜值数据. 学习样本来源于华南理工大学发布的SCUT-FBP5500数据集,数据集包括 5500 人,每人按颜值魅力打分,分值在 1 到 5 分之间 ...
- 机器学习框架ML.NET学习笔记【8】目标检测(采用YOLO2模型)
一.概述 本篇文章介绍通过YOLO模型进行目标识别的应用,原始代码来源于:https://github.com/dotnet/machinelearning-samples 实现的功能是输入一张图片, ...
- 机器学习框架ML.NET学习笔记【9】自动学习
一.概述 本篇我们首先通过回归算法实现一个葡萄酒品质预测的程序,然后通过AutoML的方法再重新实现,通过对比两种实现方式来学习AutoML的应用. 首先数据集来自于竞赛网站kaggle.com的UC ...
- Java框架spring Boot学习笔记(六):Spring Boot事务管理
SpringBoot和Java框架spring 学习笔记(十九):事务管理(注解管理)所讲的类似,使用@Transactional注解便可以轻松实现事务管理.
随机推荐
- inline 内联函数
1.目的: 引入内联函数的目的是为了解决程序中函数调用的效率问题. 函数的引入可以减少程序的目标代码,实现程序代码和数据的共享.但是,函数调用也会带来降低效率的问题,因为调用函数实际上将程序执行顺序转 ...
- javascript 获取iframe元素的方法
javascript 获取iframe元素的方法 第一种: $("#IframeID").contents().find("div"); 第二种: $(win ...
- day01.3-常用Dos命令
一. 常用Dos命令 Windons系统下:开始 —> 运行—> cmd —> 进入命令运行界面 1. ipconfig /? |—> 查看ip帮助: 2. ping / ...
- webpack4 入门(一)
一.简介 WebPack可以看做是模块打包机:它做的事情是,分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行的拓展语言(Scss,less, TypeScript等),并 ...
- 【51Nod 1363】最小公倍数之和(欧拉函数)
题面 传送门 题解 拿到式子的第一步就是推倒 \[ \begin{align} \sum_{i=1}^nlcm(n,i) &=\sum_{i=1}^n\frac{in}{\gcd(i,n)}\ ...
- SAP ABAP ALV构建动态输出列与构建动态内表(包留备用),包含操作abap元类型表及类
https://blog.csdn.net/zhongguomao/article/details/51095946
- iOS自定义相机
1.首先声明以下对象 #import <AVFoundation/AVFoundation.h> //捕获设备,通常是前置摄像头,后置摄像头,麦克风(音频输入) @property (no ...
- HashMap 1.8的源码分析一
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, ...
- 我的web安全工程师学习之路——规划篇
据网上收集的web安全工程师需要掌握哪些技能,职位要求以及如何入门,加上学习网易推出的web安全工程师微专业课程,为了进一步学习,所以给自己做了一些小小规划,也希望给同样想成为web安全工程师的同仁们 ...
- appium键盘处理
最近对appium感兴趣,就从网上找了些资料,搭建了环境,下载了appium测试代码和测试apk,这方面的东西晚上再写 appium最新版(v1.4.0.0)已经没有sendKeyEvent了,所以现 ...