Greenplum 性能优化之路 --(二)存储格式
一、存储格式介绍
Greenplum(以下简称 GP)有2种存储格式,Heap 表和 AO 表(AORO 表,AOCO 表)。
Heap 表:这种存储格式是从 PostgreSQL 继承而来的,目前是 GP 默认的表存储格式,只支持行存储。
AO 表: AO 表最初设计是只支持 append 的(就是只能 insert ),因此全称是Append-Only,在4.3之后进行了优化,目前已经可以 update 和 delete 了,全称也改为 Append-Optimized。AO 支持行存储(AORO)和列存储(AOCO)。
二、Heap表
Heap 表是从 PostgreSQL 继承而来,使用 MVCC 来实现一致性。如果你在创建表的时候没有指定任何存储格式,那么 GP 就会使用 Heap 表。
Heap 表支持分区表,只支持行存,不支持列存和压缩。需要注意的是在处理 update 和 delete 的时候,Heap 表并没有真正删除数据,而只是依靠 version 信息屏蔽老的数据,因此如果你的表有大量的 update 或者 delete,表占用的物理空间会不断增大,这个时候需要依靠 vacuum 来清理老数据。
Heap 表不支持逻辑增量备份,因此如果要对 Heap 表做快照,每次都需要导出全量数据。
建表语句
CREATE TABLE heap(
a int,
b varchar(32)
) DISTRIBUTED BY (a);
最佳实践:
如果该表是一张小表,比如数仓中的维度表,或者数据量在百万以下,推荐使用 Heap 表。
如果该表的使用场景是 OLTP 的,比如有较多的 update 和 delete,查询多是带索引的点查询等,推荐使用 Heap 表。
三、AO表
AO 表是 GP 特有的,设计的目的就是为了数仓中大型的事实表。AO 表支持行存和列存,并且也支持对数据进行压缩。
AO 表无论是在表的逻辑结构还是物理结构上,都与 Heap 表有很大的不同。比如上文所述 Heap 表使用 MVCC 控制 update 和 delete 之后数据的可见性,而 AO 表则使用一个附加的 bitmap 表来实现,这个表的的内容就是表示 AO 表中哪些数据是可见的。
对于有大量 update 和 delete 的 AO 表,同样需要 vacuum 进行维护,不过在 AO 表中, vacuum 需要对 bitmap 进行重置并压缩物理文件,因此通常比 Heap 的 vacuum 要慢。
AORO表
AORO 就是行存的 AO 表,同时行存也是 AO 表的默认存储方式。
AORO 支持表级别的压缩,不支持列级别的压缩。
建表语句如下,重点是 with 后的 appendonly=true,由于 AO 表默认是行存,因此 orientation=row 也可以不要,后面的 compresstype=zlib, compresslevel=4 都是压缩相关选项。
CREATE TABLE aoro(
a int,
b int,
c varchar(32),
d varchar(32)
)
WITH (appendonly=true, orientation=row, compresstype=zlib, compresslevel=4)
DISTRIBUTED BY (a)
压缩选项:
compresstype :压缩格式,开源版本的 AORO 表只支持 zlib。
compresslevel :压缩级别,从1-9,简单说来,级别越低(1最低),压缩比越低,但是压缩与解压消耗的 cpu 资源就越少。默认压缩级别是1。
最佳实践____________________:
AO 表主要是针对大表,比如数仓中的事实表。
AO 表支持逻辑增量备份,对于比较大的表,如果需要定期做快照,建议使用 AO 表,否则每次都要导出全量数据。
如果该表是大表,使用场景偏 OLTP 并且 update 和 delete 频率不高,可以考虑使用 AORO 表。
如果该表是大表,并且查询通常都需要扫描大多数列比如查询明细(最典型的就是 SELECT * FROM ),可以考虑使用 AORO 表。
在设置压缩级别的时候,通常对于数据仓库用户,设置到 4 或者 5 是比较折中的一个选择。
AOCO表
AOCO 表就是列存的 AO 表。
AOCO 不仅支持表级别的压缩,同时也支持列级别的压缩。
建表语句如下,这里还加入了分区特性,关于分区可以参见上一篇:Greenplum 性能优化之路 --(一)分区表:
CREATE TABLE aoco(
a int ENCODING (compresstype=zlib, compresslevel=5),
b int ENCODING (compresstype=none),
c varchar(32) ENCODING (compresstype=RLE_TYPE, blocksize=32768),
d varchar(32),
fdate date
)
WITH (appendonly=true, orientation=column, compresstype=zlib, compresslevel=6, blocksize=65536)
DISTRIBUTED BY (a)
PARTITION BY RANGE(fdate)
(
PARTITION pn START ('2018-11-01'::date) END ('2018-11-10'::date) EVERY ('1 day'::interval),
DEFAULT PARTITION pdefault
);
压缩选项:
compresstype:支持2种压缩格式,zlib 和 RLE_TYPE,其中 RLE_TYPE(Run-length Encoding)对于有较多重复值的列压缩比很高,因为它会将多个重复值存储为一个值,从而大大降低存储量,比如日期,性别,年龄等字段。
compresslevel:compresstype 如果是 zlib,compresslevel 在1-9,compresstype 如果是 RLE_TYPE,compresslevel 在1-4。
列压缩与表压缩:AOCO 表除了支持表级别的压缩外,还支持列级别的压缩,列级别的压缩配置会覆盖表级别的压缩配置,比如上述语法中4个字段,每个字段都采用了不用的压缩方式,d 列没有定义,则会默认使用表级别的压缩方式。
分区压缩:在使用分区表的时候,每个分区表也可以设置不同的压缩配置,这个常用于对数据进行冷热分离,比如对于非常老的数据,由于访问频率较低,可以考虑采用较大的压缩比,减少存储量。
BLOCKSIZE:
表的存储块大小,通常表数据对应的物理文件就是按 blocksize 的粒度增加,也就是初始就是 blocksize 大,并且保持 blocksize 的倍数。
blocksize 大小在8192和2097152之间,必须是 8192 的倍数,默认是 32768。
在 AOCO 表中,每一列也可以设置自己的 blocksize,列的配置会覆盖表的配置。
物理文件:
AOCO 表之所以能够按照列来设置压缩等参数,本质原因在于 AOCO 表中每一列的数据都会单独存储在一个文件中。因此不同文件之间可以按不同的参数进行存储,互不影响。
对于 AOCO 表,如果使用了分区,那么对于每一个分区的每一列都会有一个文件,如果一个表的分区很多,又是一张大宽表,那么产生的文件就会很多,也会对性能有一些影响。
最佳实践:
AOCO 表通常用于数仓中的核心事实表,这种表字段多,数据量大,主要是用于 OLAP 场景,也就是查询的过程不会 SELECT * FROM,而是对其中部分字段进行读取和聚合。
由于 AOCO 表一般用于大表,因此经常搭配压缩和分区,以减少表的实际存储量来提升性能。
一般情况下,压缩格式选择 zlib,压缩级别可以采用折中的 4 或者 5,但是对于有大量重复值的字段,记得要采用 RLE_TYPE 压缩格式。
blocksize 不要设置过大,特别是对于分区表,GP 对于每个分区的每个字段都会维护一个 buffer,blocksize 过大,会导致消耗的内存过大,通常就采用默认值 32768 即可。
四、修改表结构
单独列出这一节是因为 Heap,AORO 和 AOCO 这3种表在修改表结构时表现是不一样的,这也是大家容易忽视的地方。
对于不同的表类型,同样的修改语法耗时可能会差异很多,主要原因在于对于有些修改操作会导致表重写,而表重写的时间就取决于表本身的数据量。
以下列出了不同的表结构,在不同的 ALTER 语法下的行为,其中 YES 代表需要重写表,NO代表不需要重写表。
|
操作 |
Heap |
AORO |
AOCO |
|---|---|---|---|
|
ADD COLUMN |
NO |
YES |
NO |
|
DROP COLUMN |
NO |
NO |
NO |
|
ALTER COLUMN TYPE |
YES |
YES |
YES |
|
ADD COLUMN DEFAULT NULL |
YES |
YES |
NO |
|
ADD COLUMN DEFAULT VALUE |
YES |
YES |
NO |
可以看出 AOCO 表由于每个列都是单独一个文件,因此在修改列结构时影响最小,这也是 AOCO 表的一个优势。
五、混合存储
一张表是否可以同时使用多种存储方式呢?对于分区表,是可以的。
混合存储一般用于这样的场景,对于一张按时间分区的表,通常对于不同时间点的数据行为是不一样的,比如对于最近的数据,会有较多的明细查询,而对于比较老的数据,则是以分析为主。同时由于业务可能要保存较长时间的数据,为了节约成本,较老的数据会考虑使用压缩比较大的存储方式。
混合存储的关键就是使用到了 GP 的交换分区语法,也就是将一张独立的表与自己的一个分区表进行交换,当然这里前提是新表的结构是一样,并且交换的过程没有新数据进入。
流程如下:
1.创建一张分区表(1到5月份,每月一张表),采用 Heap 存储
CREATE TABLE hyper_storage (
a int,
b varchar(32),
fdate date
) DISTRIBUTED BY (a)
PARTITION BY RANGE(fdate)
(
PARTITION pn START ('2018-01-01'::date) END ('2018-06-01'::date) EVERY ('1 month'::interval),
DEFAULT PARTITION pdefault
); storage=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------------------+-------+--------------+---------
public | hyper_storage | table | test | heap
public | hyper_storage_1_prt_pdefault | table | test | heap
public | hyper_storage_1_prt_pn_1 | table | test | heap
public | hyper_storage_1_prt_pn_2 | table | test | heap
public | hyper_storage_1_prt_pn_3 | table | test | heap
public | hyper_storage_1_prt_pn_4 | table | test | heap
public | hyper_storage_1_prt_pn_5 | table | test | heap
2.现在要对1月份的表修改存储格式,因此创建一张新的 AOCO 表
CREATE TABLE exchange_table(
a int,
b varchar(32),
fdate date
) WITH (appendonly=true, ORIENTATION=column, compresstype=zlib, compresslevel=6)
DISTRIBUTED BY (a)
3.将1月份的数据导入新表
INSERT INTO exchange_table SELECT * FROM hyper_storage_1_prt_pn_1;
4.交换分区
ALTER TABLE hyper_storage EXCHANGE PARTITION pn_1 WITH TABLE exchange_table;
注:pn_1是1月份的分区表的 partitionname,可以从 pg_partitions 中查询得到
5.查看结果
storage=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------------------+-------+--------------+----------------------
public | hyper_storage | table | test | heap
public | hyper_storage_1_prt_pdefault | table | test | heap
public | hyper_storage_1_prt_pn_1 | table | test | append only columnar
public | hyper_storage_1_prt_pn_2 | table | test | heap
public | hyper_storage_1_prt_pn_3 | table | test | heap
public | hyper_storage_1_prt_pn_4 | table | test | heap
public | hyper_storage_1_prt_pn_5 | table | test | heap
public | exchange_table | table | test | heap
这样1月份的分区表就变成了 AOCO 表,而其他分区表仍然是 Heap 表
六、对比测试
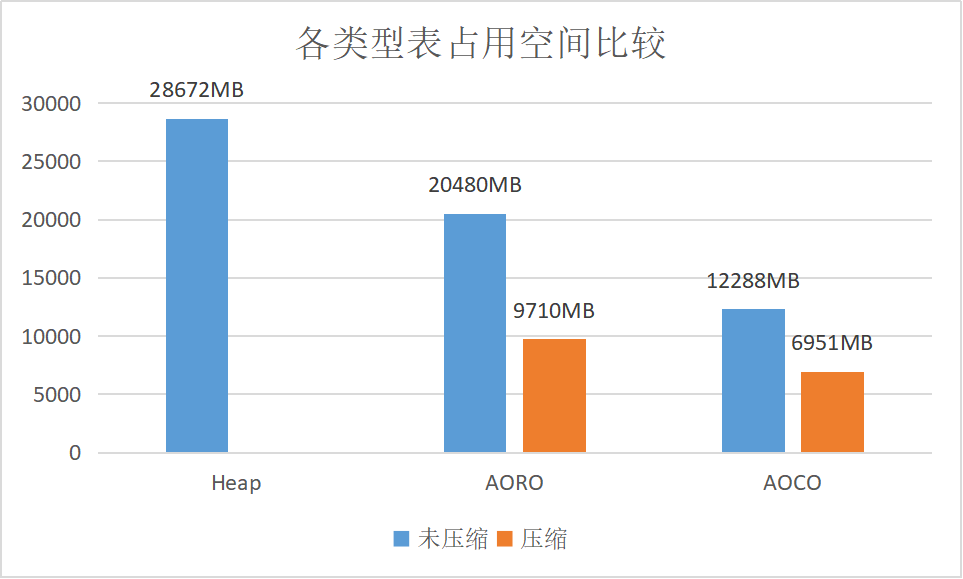
各类型表占用空间比较
选取 Heap,AORO,AOCO 三种表,分别采用压缩和不压缩2种方式(Heap表不支持压缩,AO 表压缩采用zlib格式,压缩级别设置为6),插入5亿条随机数据,然后使用
select pg_size_pretty(pg_relation_size('{tablename}'));
查看表所占大小,结果如下:
各类型表大小比较.png
说明:可以看出 Heap 表占用空间更大,即使 AO 表不采用压缩。AOCO 表由于是按列进行存储,所以相比行存的 AORO 表压缩比更大。当然这三者的差距取决于数据的实际情况,一般生产环境中 Heap 表不会和 AO 表有如此大的差距。
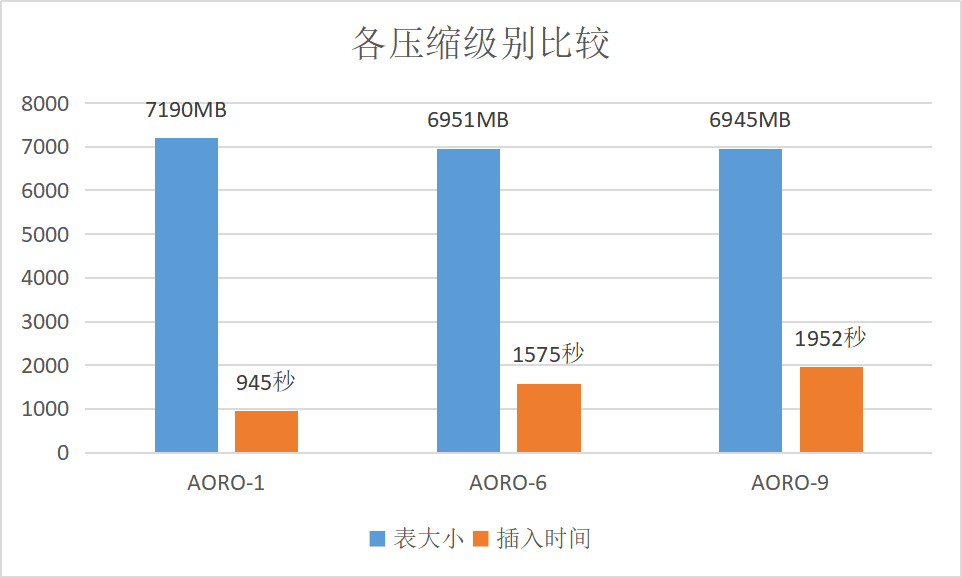
各级别压缩率比较
使用 AOCO 表,zlib 压缩格式,选取不同的压缩级别,比较数据写入时间和表所占大小,由于 zlib 支持9个级别,这里选取1,6,9 三个级别进行比较,体现出趋势即可,结果如下:
各压缩级别比较.png
说明:实际生产环境中不同压缩级别的数据,压缩比的差距可能会更大。但可以看出,越高的压缩级别,在插入的时候越耗时,其它 SQL,类似 SELECT,UPDATE 等也都是一样。
写在最后
切记,从其它系统迁移数据到 GP 上来,第一件事情就是给每张表选择合适的存储格式,特别是核心表。

关注“腾讯云大数据”公众号,技术交流、最新活动、服务专享一站Get~
Greenplum 性能优化之路 --(二)存储格式的更多相关文章
- Greenplum 性能优化之路 --(三)ANALYZE
一.为什么需要 ANALYZE 首先介绍下 RBO 和 CBO,这是数据库引擎在执行 SQL 语句时的2种不同的优化策略. RBO(Rule-Based Optimizer) 基于规则的优化器,就是优 ...
- Greenplum 性能优化之路 --(一)分区表
一.什么是分区表 分区表就是将一个大表在物理上分割成若干小表,并且整个过程对用户是透明的,也就是用户的所有操作仍然是作用在大表上,不需要关心数据实际上落在哪张小表里面.Greenplum 中分区表的原 ...
- 阿里巴巴 web前端性能优化进阶路
Web前端性能优化WPO,相信大多数前端同学都不会陌生,在各自所负责的站点页面中,也都会或多或少的有过一定的技术实践.可以说,这个领域并不缺乏成熟技术理论和技术牛人:例如Yahoo的web站点性能优化 ...
- 专访阿里巴巴研究员“赵海平”:Facebook的PHP底层性能优化之路(HipHop,HHVM)
专访阿里巴巴研究员“赵海平”:Facebook的PHP底层性能优化之路 http://www.infoq.com/cn/articles/interview-alibaba-zhaohaiping
- Android性能优化典范(二)
Google前几天刚发布了Android性能优化典范第2季的课程,一共20个短视频,包括的内容大致有:电量优化,网络优化,Wear上如何做优化,使用对象池来提高效率,LRU Cache,Bitmap的 ...
- Android性能优化第(二)篇---Memory Monitor检测内存泄露
上篇说了一些性能优化的理论部分,主要是回顾一下,有了理论,小平同志又讲了,实践是检验真理的唯一标准,对于内存泄露的问题,现在通过Android Studio自带工具Memory Monitor 检测出 ...
- SQL Server 性能优化实战系列(二)
SQL Server datetime数据类型设计.优化误区 一.场景 在SQL Server 2005中,有一个表TestDatetime,其中Dates这个字段的数据类型是datetime,如果你 ...
- Linux性能优化实战(二)
一.CPU使用率过高 1,CPU使用率 a>节拍率 为了维护CPU时间,Linux通过事先定义的节拍率(内核中表示为HZ),触发时间中断,并使用全局变量Jiffies记录开机以来的节拍数.每发生 ...
- javascript性能优化之避免二次评估
Javascript与许多脚本语言一样,允许你在程序中获取一个包含代码的字符串然后运行它,有多种方式可以实现在一串Javascript代码并运行它. 代码示例如下 <html> <h ...
随机推荐
- java8新特性LocalDate、LocalTime、LocalDateTime的学习
以前操作时间都是使用SimpleDateFormat类改变Date的时间格式,使用Calendar类操作时间.但是SimpleDateFormat是线程不安全的,源码如下: private Strin ...
- python中a+=b 和a=a+b的结果一样吗
这里涉及到可变类型和不可变类型. 可变类型:列表,字典,集合 不可变:数字,字符串,元祖 先看一下不可变类型的运算: +=运算 >>> a, b = 1, 2 >>> ...
- 如何使用ABBYY FineReader 的用户模式?
在运用ABBYY FineReader 15(Windows系统)进行文档识别时,用户可能会遇到识别的文档包含一些特殊字符或者其他软件无法识别的字体等情况,容易造成识别出现乱码的结果.在这种情况下,用 ...
- Shamir秘密共享方案 (Python)
Shamir's Secret Sharing scheme is an important cryptographic algorithm that allows private informati ...
- Java中的单例模式最全解析
单例模式是 Java 中最简单的设计模式之一,它是指一个类在运行期间始终只有一个实例,我们就把它称之为单例模式.它不但被应用在实际的工作中,而且还是面试中最常考的题目之一.通过单例模式我们可以知道此人 ...
- shardingsphere与分布式事务
rt https://blog.csdn.net/l1028386804/article/details/79769043 https://blog.csdn.net/qq_20387013/arti ...
- 【NOIP2017提高A组模拟9.17】猫
[NOIP2017提高A组模拟9.17]猫 题目 Description 信息组最近猫成灾了! 隔壁物理组也拿猫没办法. 信息组组长只好去请神刀手来帮他们消灭猫.信息组现在共有n 只猫(n 为正整数) ...
- 第15.38节 PyQt(Python+Qt)入门学习:containers容器类部件QDockWidget停靠窗功能详解
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 一.概述 QDockWidget类提供了一个可以停靠在QMainWin ...
- Python中序列解包与函数的参数收集之间的关系
在<第4.7节 Python特色的序列解包.链式赋值.链式比较>中老猿介绍了序列解包,<第5.2节 Python中带星号的函数参数实现参数收集>介绍了函数的参数收集,实际上函数 ...
- 第8.30节 重写Python __setattr__方法实现属性修改捕获
一. 引言 在<第8.26节 重写Python类中的__getattribute__方法实现实例属性访问捕获>章节介绍了__getattribute__方法,可以通过重写该方法,截获所有通 ...