java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式
大数据概念
大数据概论
大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发现力和流程优化能力的海量,高增长率和多样化的信息资产.
- 主要解决海量数据的存储和海量数据的分析计算问题.
按顺序给出数据存储单位:bit,Byte,KB,MB,GB,TB,PB,EB,ZB,YB,BB,NB,DB.
1Byte =8bit 1KB=1024Byte 1MB=1024KB 1GB=1024MB 1TB=1024GB 1PB=1024TB
大数据特点(4V)
Volume(大量):
截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB.当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级.
Vekocity(高速):
这是大数据区分于传统数据挖掘的最显著特征.根据IDC的"数字宇宙"的报告,预计到2020年,全球数据使用量将达到35.2ZB.在如此海量的数据面前,处理数据的效率就是企业的生命.
Variety(多样):
这种类型的多样性也让数据被分为结构化数据和非结构化数据.相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志,音频,视频,图片,地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求.
Value(低价值密度):
价值密度的高低与数据总量的大小成反比.如何快速对有价值数据"提纯"成为目前大数据背景下待解决的难题.
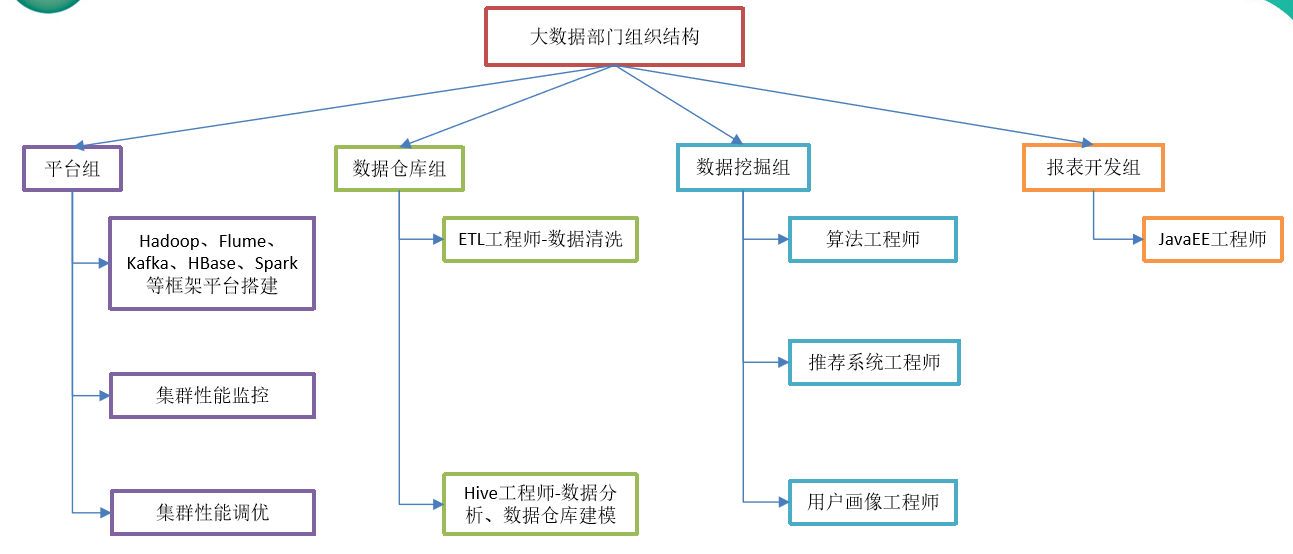
大数据部门组织结构
大数据部门组织结构,适用于大中型企业.
从Hadoop框架讨论大数据生态
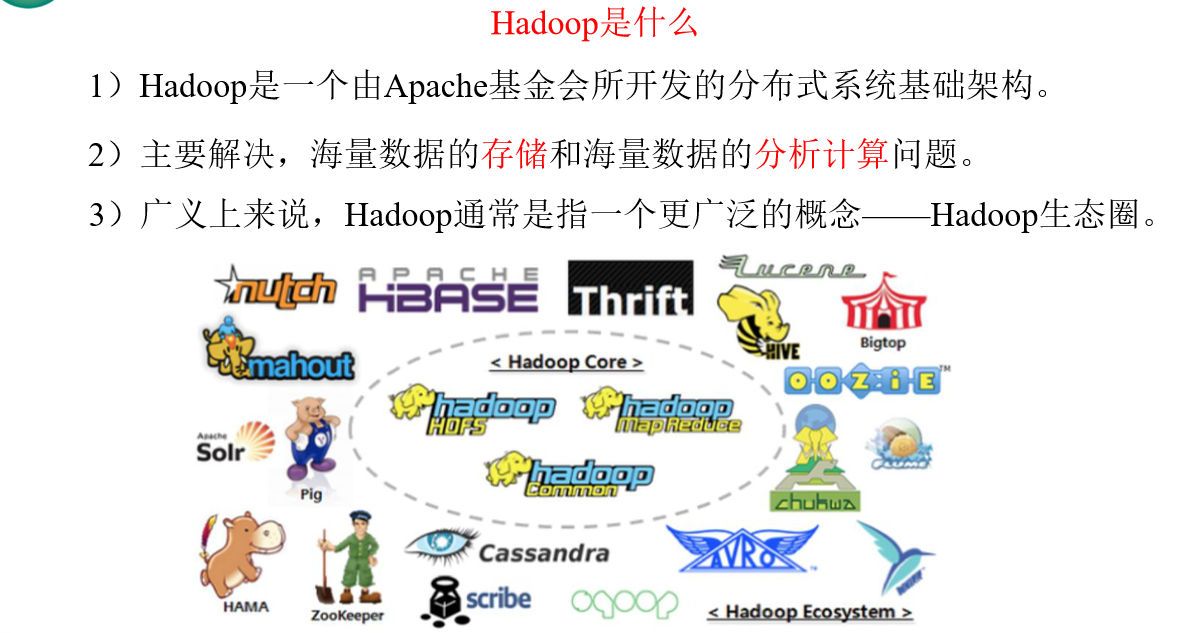
Hadoop是什么
hadoop的初衷是采用大量的廉价机器,组成一个集群!完成大数据的存储和计算!
Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
Hadoop的优势(4高)
高可靠性
Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失.
高扩展性
在集群间分配任务数据,可方便的扩展数以千计的节点.
高效性
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度.
高容错性
能够自动将失败的任务重新分配
Hadoop组成(面试重点)
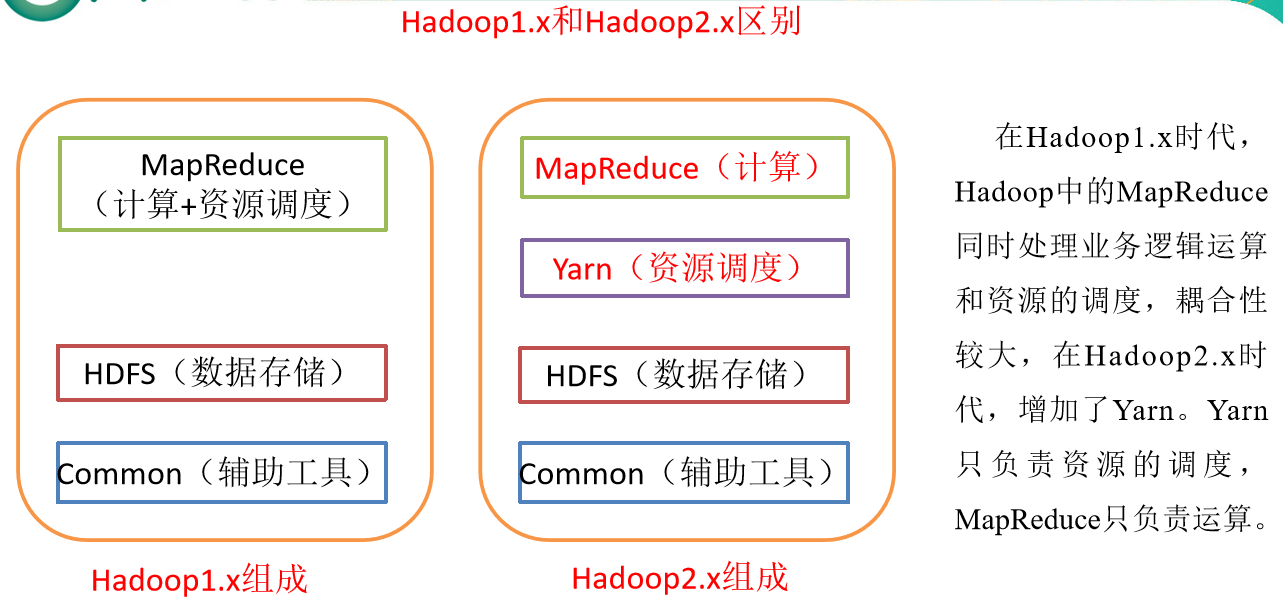
- Hadoop1.x
- HDFS: 负责大数据的存储
- common: HDFS和MR共有的常用的工具包模块
- MapReduce: 负责计算,负责计算资源的申请的调度
- 完成大数据的计算
- 写程序.程序需要复合计算框架的要求
- java-->main-->运行
- MapReduce(编程模型)-->Map-->Reducer
- 运行程序.申请计算资源(CPU+内存,磁盘IO,网络IO)
- java-->JVM-->os-->申请计算资源
- 1.x: MapReduce(编程模型)-->JobTracker-->JVM-->申请计算资源
- 2.x: MapReduce(编程模型)-->jar-->运行时,将jar包中的任务,提交给YARN,和YARN进行通信
- 由YARN中的组件-->JVM-->申请计算资源
- 写程序.程序需要复合计算框架的要求
- 1.x和2.x的区别是将资源调度和管理进行分离!由统一的资源调度平台YARN进行大数据计算资源的调度!提升了Hadoop的通用性!Hadoop搭建的集群中的计算资源,不仅可以运行Hadoop中的MR程序!也可以运行其他计算框架的程序!
- 由于MR的低效性,出现了许多更为高效的计算框架!例如:Tez,Storm,Spark,Flink
HDFS架构概述
HDFS: 负责大数据的存储
核心进程(必须进程):
NameNode(1个):存储文件的元数据.如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.
职责
接收客户端的请求!
接收DN的请求!
向DN分配任务!
DataNode(N个):在本地文件系统存储文件块数据,以及块数据的校验和.
职责
负责接收NN分配的任务!
负责数据块(block)的管理(读,写)!
可选进程:
- Secondary Namenode(N个):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照.
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总

- MapReduce(编程规范): 程序中有Map(简单处理)和Reducer(合并)
- 遵循MapReduce的编程规范编写的程序打包后,被称为一个Job(任务)
- Job需要提交到YARN上,向YARN申请计算资源,运行Job中的Task(进程)
- Job会先创建一个进行MRAppMaster(mapReduce应用管理者),由MRMaster向YARN申请资源!MRAppMaster负责监控Job中各个Task运行情况,进行容错管理!
YARN架构概述

YARN负责集群中所有计算资源的管理和调度
常见进程
ResourceManager(1个): 负责整个集群所有资源的管理!
职责
负责接受客户端的提交Job的请求!
负责向NM分配任务!
负责接受NM上报的信息!
NodeManager(N个): 负责单台计算机所有资源的管理!
职责
负责和RM进行通信,上报本机中的可用资源!
负责领取RM分配的任务!
负责为Job中的每个Task分配计算资源!
Container(容器)
NodeManager为Job的某个Task分配了2个CPU和2G内存的计算资源!
为了防止当前Task在使用这些资源期间,被其他的task抢占资源!
将计算资源,封装到一个Container中,在Container中的资源,会被暂时隔离!无法被其他进程所抢占!
当前Task运行结束后,当前Container中的资源会被释放!允许其他task来使用!
大数据技术生态体系

图中涉及的技术名词解释如下:
Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Hadoop运行环境搭建(开发重点)
虚拟机环境准备
克隆虚拟机
修改克隆虚拟机的静态IP
修改主机名
关闭防火墙
创建atguigu用户
useradd atguigu
passwd atguigu
配置atguigu用户具有root权限(详见大数据技术之Linux)
vim /etc/sudoers
- 找到root所在的位置,加入atguigu ALL=(ALL) NOPASSWD: ALL
root ALL=(ALL) ALL
atguigu ALL=(ALL) NOPASSWD: ALL在/opt目录下创建文件
sudo mkdir module
sudo mkdir soft
- 将/opt目录下创建的soft目录和module目录的所属主修改为atguigu
sudo chown -R atguigu:atguigu /opt/soft /opt/module
安装JDK
安装过程(略)
配置JDK环境变量
vim /etc/profile
- Shift+G到最后一行新增
JAVA_HOME=/opt/module/jdk1.8.0_121
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME PATH
- wq保存退出后,让修改后的文件生效
source /etc/profile
- 测试JDK是否安装成功
java -version
java version "1.8.0_144"
安装Hadoop
安装过程(略)
将Hadoop添加到环境变量
最后文件内容为:
JAVA_HOME=/opt/module/jdk1.8.0_121
HADOOP_HOME=/opt/module/hadoop-2.7.2
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME PATH HADOOP_HOME
Hadoop目录结构
- 查看Hadoop目录结构
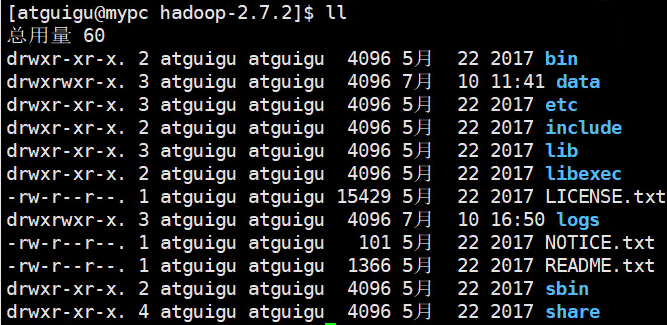
重要目录
- bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
本地运行模式
官方Grep案例
- 创建在hadoop-2.7.2文件下面创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir input
- 将Hadoop的xml配置文件复制到input
[atguigu@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input
- 执行share目录下的MapReduce程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
- 查看输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*
官方WordCount案例
- 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir wcinput
- 在wcinput文件下创建一个wc.input文件
[atguigu@hadoop101 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop101 wcinput]$ touch wc.input
- 编辑wc.input文件
[atguigu@hadoop101 wcinput]$ vi wc.input
- 在文件中输入如下内容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
- 保存退出::wq
回到Hadoop目录/opt/module/hadoop-2.7.2
执行程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
查看结果
1.命令查看
[atguigu@hadoop101 hadoop-2.7.2]$ cat wcoutput/part-r-00000
atguigu 2
hadoop 2
mapreduce 1
yarn 1
2.浏览器查看
伪分布式运行模式
启动HDFS并运行MapReduce程序
分析
配置集群
启动、测试集群增、删、查
执行WordCount案例
执行步骤
配置集群
配置: hadoop-env.sh
Linux系统中获取JDK的安装路径:
[atguigu@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置: core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mypc:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
配置: hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
启动集群
格式化NameNode(第一次启动时格式化,以后就不要总格式化)
atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
启动NameNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
启动DataNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
查看集群
查看是否启动成功
[atguigu@hadoop101 hadoop-2.7.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
web端查看HDFS文件系统
查看产生的Log日志
说明:在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。
当前目录:/opt/module/hadoop-2.7.2/logs
[atguigu@hadoop101 logs]$ ls
hadoop-atguigu-datanode-hadoop.atguigu.com.log
hadoop-atguigu-datanode-hadoop.atguigu.com.out
hadoop-atguigu-namenode-hadoop.atguigu.com.log
hadoop-atguigu-namenode-hadoop.atguigu.com.out
SecurityAuth-root.audit
[atguigu@hadoop101 logs]# cat hadoop-atguigu-datanode-hadoop101.log
思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[atguigu@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/
[atguigu@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837 [atguigu@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
操作集群
- 在HDFS文件系统上创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/atguigu/input
- 将测试文件内容上传到文件系统上
[atguigu@hadoop101 hadoop-2.7.2]$bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/
- 查看上传的文件是否正确
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -ls /user/atguigu/input/
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/ input/wc.input
- 运行MapReduce程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output
查看输出结果
命令行查看:
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/*
浏览器查看:

- 将测试文件内容下载到本地
[atguigu@hadoop101 hadoop-2.7.2]$ hdfs dfs -get /user/atguigu/output/part-r-00000 ./wcoutput/
- 删除输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ hdfs dfs -rm -r /user/atguigu/output
YARN上运行MapReduce 程序
分析
- 配置集群YARN上运行
- 启动、测试集群增、删、查
- 在YARN上执行WordCount案例
执行步骤
配置集群
配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
配置:mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
[atguigu@hadoop101 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[atguigu@hadoop101 hadoop]$ vi mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
启动集群
启动前必须保证NameNode和DataNode已经启动
启动ResourceManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
启动NodeManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
集群操作
YARN的浏览器页面查看
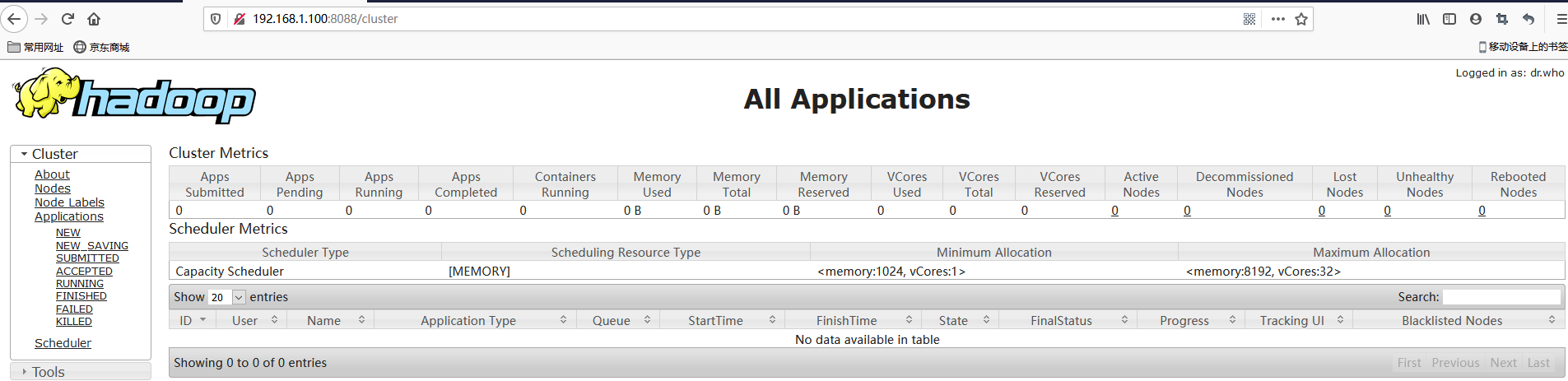
2. 删除文件系统上的output文件
```shell
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output
```
3. 执行MapReduce程序
```shell
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
```
4. 查看运行结果
```shell
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/*
```

配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器
- 配置mapred-site.xml
[atguigu@hadoop101 hadoop]$ vi mapred-site.xml
在该文件里面增加如下配置
<property>
<name>mapreduce.jobhistory.address</name>
<value>mypc:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>mypc:19888</value>
</property>
<!--第三方框架使用yarn计算的日志聚集功能 -->
<property>
<name>yarn.log.server.url</name>
<value>http://mypc:19888/jobhistory/logs</value>
</property>
启动历史服务器
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
查看历史服务器是否启动
atguigu@hadoop101 hadoop-2.7.2]$ jps
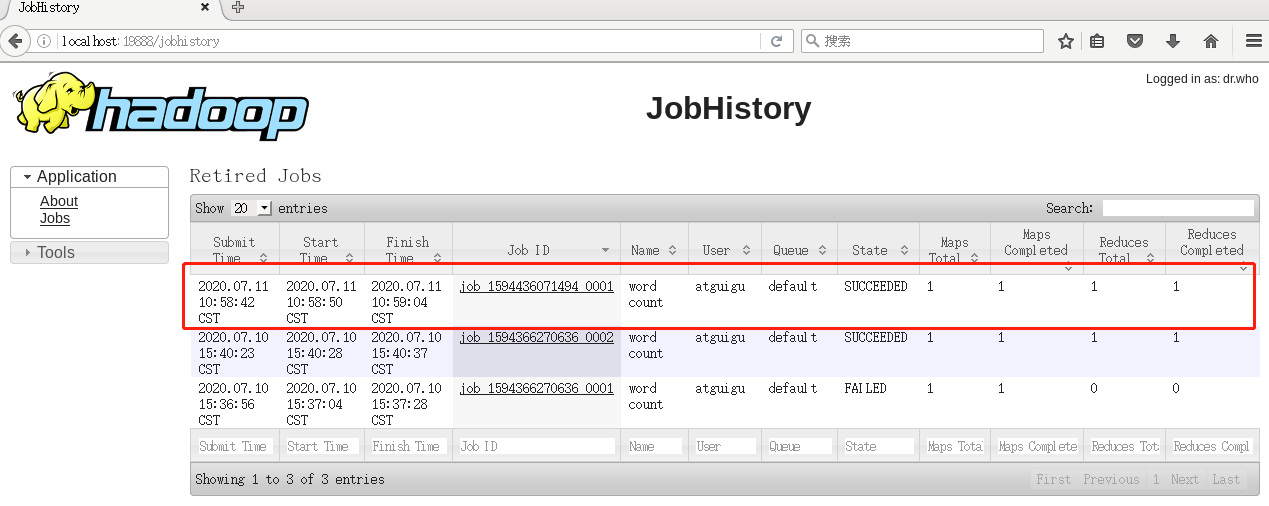
查看JobHistory
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
- 开启日志聚集功能具体步骤如下:
配置yarn-site.xml
[atguigu@hadoop101 hadoop]$ vi yarn-site.xml
在该文件里面增加如下配置
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
关闭NodeManager 、ResourceManager和HistoryManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
启动NodeManager 、ResourceManager和HistoryManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
删除HDFS上已经存在的输出文件
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output
执行WordCount程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
- 我wc1里有文件,wc3不存在

- 所以我执行了一个简单的测试命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wc1 /wc3
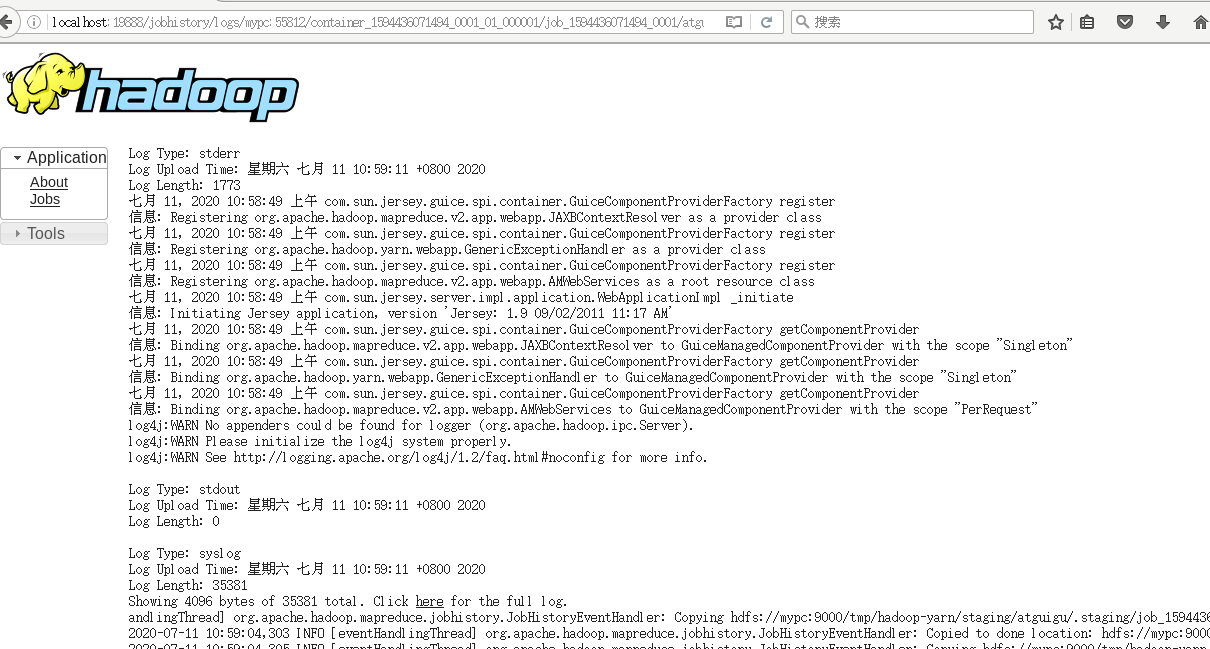
查看日志

配置文件说明及其他注意事项
配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件
要获取的默认文件 文件存放在Hadoop的jar包中的位置 [core-default.xml] hadoop-common-2.7.2.jar/ core-default.xml [hdfs-default.xml] hadoop-hdfs-2.7.2.jar/ hdfs-default.xml [yarn-default.xml] hadoop-yarn-common-2.7.2.jar/ yarn-default.xml [mapred-default.xml] hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml 自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
其他注意事项
本次学习使用的虚拟机系统是centOS6.8,和生产环境普遍使用的centOS7.X的部分命令有差异,请注意识别!
在Hadoop中启动多种不同类型的进程.例如NN,DN,RM,NM,这些进程需要进行通信!在通信时,常用主机名进行通信!
在192.168.1.100机器上的DN进程,希望访问192.168.1.104机器的NN进程!需要在集群的每台机器上,配置集群中所有机器的host映射!
配置:
Linux: /etc/hosts
Windows: C:\Windows\System32\drivers\etc\hosts不配报错:DNS映射异常,HOST映射异常
Linux配置完hosts文件后一定要重启网络配置!!!
service network restart
注意权限
- hadoop框架在运行需要产生很多数据(日志),数据的保存目录,必须让当前启动hadoop进程的用户拥有写权限!
关闭防火墙,设置开机不自启动
service iptables stop
chkconfig iptables offHDFS的运行模式的参数设置
fs.defaultFS在core-default.xml中!
本地模式(在本机上使用HDFS,使用的就是本机的文件系统)
fs.defaultFS=file:///(默认)
分布式模式
fs.defaultFS=hdfs://
提交任务的命令
hadoop jar jar包 主类名 参数{多个输入目录,一个输出目录}
输入目录中必须全部是文件!
输出目录必须不存在!
java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式的更多相关文章
- java大数据最全课程学习笔记(2)--Hadoop完全分布式运行模式
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 Hadoop完全分布式运行模式 步骤分析: 编写集群分发脚本xsync 集群配置 集群部署规划 配置集群 集群单 ...
- java大数据最全课程学习笔记(3)--HDFS 简介及操作
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 HDFS 简介及操作 HDFS概述 HDFS产出背景及定义 HDFS优缺点 HDFS组成架构 HDFS文件块大小 ...
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- java大数据最全课程学习笔记(5)--MapReduce精通(一)
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(一) MapReduce入门 MapReduce定义 MapReduce优缺点 优点 缺 ...
- 吴裕雄--天生自然Hadoop学习笔记:Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储.Hadoop实现了一个分布式文件系统(H ...
- 《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群 1.Hadoop集群角色分配 2.上传Hadoop并解压 在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/mo ...
- NFC学习笔记2——Libnfc简介及安装
我一直希望自己的文章做一些记录的英文翻译.趁着学习NFC,现在,libnfc主页libnfc介绍和不同的操作系统libnfc文章做一些翻译安装.一方面,提高自己的英语,一方面有了解libnfc. 原文 ...
- 【传智播客】Libevent学习笔记(一):简介和安装
目录 00. 目录 01. libevent简介 02. Libevent的好处 03. Libevent的安装和测试 04. Libevent成功案例 00. 目录 @ 01. libevent简介 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
随机推荐
- ESP8266服务器模式 发送数据和接收数据 模板1
功能如下: 1.将客户端发来的数据转发到串口:2.串口数据转发给所有客户端3.可连接4个客户端4.可设置静态IP地址5.指示灯闪烁表示无客户端连接,灯亮代表有客户端连接 /** 功能: 1.将客户端发 ...
- 拒绝降权!教你用 Python 确保制作的短视频独一无二
1. 场景 前段时间有人私信我,说自己辛辛苦苦剪辑的短视频,上传到某平台后,由于播放量太大,收到 降权 的通知,直接导致这个账号废掉了! 其实,各大视频平台都有自己的一套鉴别算法,针对视频的二次创作, ...
- 测试必备工具之最强抓包神器 Charles,你会了么?
前言 作为软件测试工程师,大家在工作中肯定经常会用到各种抓包工具来辅助测试,比如浏览器自带的抓包工具-F12,方便又快捷:比如时下特别流行的Fiddler工具,使用各种web和APP测试的各种场景 ...
- 04.开发REST 接口
使用Django开发REST 接口 我们以在Django框架中使用的图书英雄案例来写一套支持图书数据增删改查的REST API接口,来理解REST API的开发. 在此案例中,前后端均发送JSON格式 ...
- docker配置国内镜像地址,解决无法pull镜像问题docker: Error response from daemon
问题: 执行命令 $ docker run -it --rm -p 8888:8080 tomcat:8.5.32 报错 Unable to find image 'tomcat:8.5.32' lo ...
- 【Flutter实战】定位装饰权重组件及柱状图案例
老孟导读:Flutter中有这么一类组件,用于定位.装饰.控制子组件,比如 Container (定位.装饰).Expanded (扩展).SizedBox (固定尺寸).AspectRatio (宽 ...
- 关于对Entity Framework 3.1的理解与总结
Entity Framework Core 是一个ORM,所谓ORM也是ef的一个框架之一吧,简单的说就是把C#一个类,映射到数据库的一个表,把类里面的属性映射到表中的字段.然后Entity Fram ...
- 基于 Angular Material 的 Data Grid 设计实现
自 Extensions 组件库发布以来,Data Grid 成为了使用及咨询最多的组件.最开始 Data Grid 的设计非常简陋,经过一番重构,组件质量有了质的提升. Extensions 组件库 ...
- Nginx详细介绍
1.Nginx是什么? Nginx就是反向代理服务器. 首先我们先来看看什么是代理服务器,代理服务器一般是指局域网内部的机器通过代理服务发送请求到互联网上的服务器,代理服务器一般作用于客户端.比如Go ...
- Spring中使用注解时启用<context:component-scan/>
在spring中使用注解方式时需要在spring配置文件中配置组件扫描器:http://blog.csdn.net/j080624/article/details/56277315 <conte ...