2.k8sPod、控制器、service
一、Pod生命周期
- Pod是k8s中最小的管理单元(逻辑上存在,实际不存在),是一组容器的集合
- 同一个Pod中的容器共享网络和存储(通过pause容器实现),由一个统一的IP向集群内部提供服务
- Pod分为自主式(死亡之后就会消失)和被控制器控制的(死亡之后会被控制器拉起来保持Pod的副本数量)
- Pod的生命周期是短暂的,Pod死亡之后,重新创建的Pod和原来的Pod完全不一样
1、init c
init c 即 init container (初始化容器)
Pod能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的Init容器
Init容器与普通的容器非常像,除了如下两点
- Init容器总是运行到成功完成为止
- 每个Init容器都必须在下一个Init容器启动之前成功完成
如果Pod的Init容器失败, Kubernetes 会不断地重启该Pod,直到Init容器成功为止。然而,如果Pod对应的 restartPolicy为Never,他不会重新启动
2、init c的作用
- 因为Init容器具有与应用程序容器分离的单独镜像,所以它们的启动相关代码具有如下优势
- 它们可以包含并运行实用工具,但是出于安全考虑,是不建议在应用程序容器镜像中包含这些实用工具的
- 它们可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要FROM另一个镜像,只需要在安装过程中使用类似 sed 、 awk 、 python或 dig这样的工具
- 应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像
- Init容器使用 Linux Namespace ,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问 Secret 的权限,而应用程序容器则不能
- 它们必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以Init容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法,直到满足了一组先决条件
- 也就是说在主容器启动之前使用init c可以做一些其他事情
- 读取配置文件等等(为保证主容器运行)
- 读取私密文件等等(保证系统的安全,init c一旦成功结束,就会删除,而读取私密文件放在主容器中,可能会出现安全隐患,因为主容器时一直运行)
- 但是不建议用init c去监测其他容器(比如,我们的服务mysql应该先启动,用init c去监测mysql的容器时是正常的,init c成功结束,但是主容器启动时mysql容器可能又挂了,所以这种方法不太准确)
3、特殊说明
- 在Pod启动过程中,Init容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出,init c按顺序执行,上一个执行成功之后才会执行下一个
- 如果由于运行时或失败退出,将导致容器启动失败,它会根据Pod的restartPolicy指定的策略进行重试。然而,如果Pod的restartPolicy设置为Always ,Init容器失败时会使用RestartPolicy策略
- 在所有的Init容器没有成功之前,Pod将不会变成Ready状态。Init容器的端口将不会在Service中进行聚集。正在初始化中的 Pod处于 Pending 状态,但应该会将 Initializing状态设置为 true
- 如果Pod重启,所有Init容器必须重新执行
- 对Init容器spec的修改被限制在容器image字段,修改其他字段都不会生效。更改Init容器的image字段,等价于重启该Pod
- Init容器具有应用容器的所有字段。除了 readinessProbe ,因为Init容器无法定义不同于完成(completion)的就绪(readiness)之外的其他状态。这会在验证过程中强制执行
- 在Pod中的每个app和Init容器的名称必须唯一;与任何其它容器共享同一个名称,会在验证时抛出错误
- start和stop会在main c 启动之后和结束之前做一些事情

4、init c资源清单示例
# pod 资源清单
apiVersion: v1
kind: Pod
metadata:
name: initc-pod
labels:
app: myapp
spec:
containers:
- name: initc-container
image: busybox
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
# 以下为init c容器
initContainers:
# 第一个init c容器
- name: init-myservice
image: busybox
# 监测service 看集群中有无名为myservice的service 直至监测到才会成功推出(直接写service名称可能不能解析,ping不同,解决方法如下)
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2;done;']
# 第一个init c容器
- name: init-mydb
image: busybox
# 监测service 看集群中有无名为mydb的service 直至监测到才会成功推出
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
# 查看pod状态
[root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
initc-pod 0/1 Init:0/2 0 43s # 查看pod日志
[root@k8smaster pods]# kubectl logs initc-pod -c init-myservice
;; connection timed out; no servers could be reached waiting for myservice
;; connection timed out; no servers could be reached waiting for myservice
;; connection timed out; no servers could be reached ......# service 资源清单 简写svc
kind: Service
apiVersion: v1
metadata:
name: myservice
spec:
ports:
# 使用的协议 TCP和UDP可选
- protocol: TCP
# 暴露给k8s内部集群的端口
port: 80
# 也监听就是sevice的pod下容器 并且容器暴露端口为9376
targetPort: 9376
# 用--- 分开表示一个yaml文件
---
kind: Service
apiVersion: v1
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
# 启动名为myservice的service 查看pod状态
[root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
initc-pod 0/1 Init:1/2 0 57s # 启动名为mydb的service 查看pod状态
[root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
initc-pod 1/1 Running 0 2m34s
解决pod内不能通过域名进行访问其他servce或者pod(ping 不同 不管是clusterIp,还是名称)
问题原因:kubeadm安装的k8s的kube-proxy使用的iptables,需要修改为ipvs
1.开启ipvs支持(每个节点执行)
- yum -y install ipvsadm ipset (好像可省略)
- 永久生效:cat > /etc/sysconfig/modules/ipvs.modules <<EOF
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF - 临时生效:modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
2.修改权限(每个节点执行,好像可省略)
- chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
3.修改kube-proxy的configMap
kubectl edit cm kube-proxy -n kube-system
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 30s
kind: KubeProxyConfiguration
metricsBindAddress: 127.0.0.1:10249
mode: "ipvs" # 修改此处为ipvs
4.重启kube-proxy
- kubectl get pod -n kube-system | grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}'
5.查看kube-proxy启动日志,确认是否为ipvs
kubectl logs -n kube-system kube-proxy-ff74q(自己的kube-proxy pod名)
# 有Using ipvs Proxier则配置成功
I1215 09:18:42.852942 1 server_others.go:259] Using ipvs Proxier.
6.进入Pod中使用ping 命令测试,如果不行重启k8s集群后再试
5、健康检查(探针)
探针是由kubelet对容器执行的定期诊断。要执行诊断,kubelet调用由容器实现的Handler 。有三种类型的处理程序
- ExecAction :在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功
- TCPSocketAction :对指定端口上的容器的IP地址进行TCP检查。如果端口打开,则诊断被认为是成功的
- HTTPGetAction :对指定的端口和路径上的容器的 IP地址执行 HTTP Get请求。如果响应的状态码大于等于200且小于400 ,则诊断被认为是成功的,可以防止端口是开的但是服务已经挂掉
每次探测都将获得以下三种结果之一
- 成功:容器通过了诊断
- 失败:容器未通过诊断
- 未知:诊断失败,因此不会采取任何行动
探针分类
readinessProbe :指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与Pod匹配的所有Service的端点中删除该Pod的IP地址。初始延迟之前的就绪状态默认为Failure 。如果容器不提供就绪探针,则默认状态为 Success,也就是在主容器创建时,检测该主容器是否已经准备就绪,可以向外界提供服务了,防止出现,容器启动了,但是容器中的服务还没有启动,这个是否向外界提供服务就会出现异常
readinessProbe只影响Realy状态,不会重启pod,重启pod会重新执行readinessProbe
资源清单示例
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
namespace: default
spec:
containers:
- name: readiness-httpget-container
image: nginx
# 镜像拉取方式,如果本地有就用本地
imagePullPolicy: IfNotPresent
# 就绪检查方式采用httpGet,默认的nginx肯定没有index1.html
readinessProbe:
httpGet:
port: 80
path: /index1.html
# 开始检测延迟时间1s
initialDelaySeconds: 1
# 检测间隔时间3s
periodSeconds: 3
启动readiness-httpget-pod并查看
# pod的状态为Running,但是READY没准备好
[root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-httpget-pod 0/1 Running 0 5m51s # 查看pod的描述 就绪检测失败
[root@k8smaster pods]# kubectl describe pod readiness-httpget-pod
Warning Unhealthy 4m26s (x100 over 9m23s) kubelet, k8snode2 Readiness probe failed: HTTP probe failed with statuscode: 404
进入Pod中添加index1.html
# 向/usr/share/nginx/html 中添加index1.html 后查看pod状态已经就绪
# kubectl exec -it pod名 -c 容器名(pod中只有一个容器可不指定) -- /bin/sh(执行的命令)
[root@k8smaster pods]# kubectl exec -it readiness-httpget-pod -c readiness-httpget-container -- /bin/sh
# cd /usr/share/nginx/html
# echo "123" >> index1.html
# ls
50x.html index.html index1.html
# exit [root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-httpget-pod 1/1 Running 0 16m
livenessProbe :指示容器是否正在运行。如果存活探测失败,则kubelet会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为Success,也就是为了防止僵尸进程存在,进程还在,不能提供服务
livenessProbe检测失败会重启pod,重启pod会重新执行readinessProbe
资源清单示例一:exec方式
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: busybox
imagePullPolicy: IfNotPresent
# 容器启动的命令 在/tmp下创建live文件 过30s删除
command: ["/bin/sh","-c","touch /tmp/live ; sleep 30; rm -rf /tmp/live; sleep 3600"]
# 存活检查采用 命令的方式 看/tmp下创建live文件存不存在 不存在则检测失败,使用Pod的重启策略
livenessProbe:
exec:
command: ["test","-e","/tmp/live"]
initialDelaySeconds: 1
periodSeconds: 3
# 查看pod 在30s的时候进行了重启(也不一定是30s,因为容器启动也会浪费时间)
[root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 0 29s
web-5dcb957ccc-r74d6 1/1 Running 0 28m [root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 1 32s
web-5dcb957ccc-r74d6 1/1 Running 0 28m
资源清单示例二:httpGet方式
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
# 该Pod监听其下容器的端口
containerPort: 80
# 存活检查采用 httpGet的方式 访问/index.html存不存在
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
# 超时时间 超时代表失败
timeoutSeconds: 10
# 查看pod状态
[root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-httpget-pod 1/1 Running 0 5m12s # 进入pod删除index.html
[root@k8smaster pods]# kubectl exec -it liveness-httpget-pod -c readiness-httpget-container -- /bin/sh
# cd /usr/share/nginx/html
# rm index.html # 查看pod状态
[root@k8smaster pods]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-httpget-pod 1/1 Running 1 9m43s
资源清单示例三:tcp方式
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp-pod
spec:
containers:
- name: liveness-tcp-container
image: nginx
# 存活检查采用 tcp的方式 检查8080端口
livenessProbe:
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 3
tcpSocket:
port: 8080
# 查看pod状态 一直重启 因为8080端口一直不存在
NAME READY STATUS RESTARTS AGE
liveness-tcp-pod 1/1 Running 4 104s
readinessProbe和livenessProbe 同时使用
资源清单示例
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
# 该Pod监听其下容器的端口
containerPort: 80
readinessProbe:
httpGet:
port: 80
path: /index1.html
# 开始检测延迟时间1s
initialDelaySeconds: 1
# 检测间隔时间3s
periodSeconds: 3
# 存活检查采用 httpGet的方式 访问/index.html存不存在
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
# 超时时间 超时代表失败
timeoutSeconds: 10
6、start和stop
Pod hook(钩子)是由 Kubernetes管理的kubelet发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。可以同时为Pod中的所有容器都配置hookHook
Hook 的类型包括两种
- exec :执行一段命令
- HTTP :发送 HTTP 请求
资源清单示例
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
# 容器启动后执行
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler >/usr/share/message"]
# 容器关闭前执行
preStop:
exec:
command: ["/bin/sh", "-c", "echo Hello from the poststop handler >/usr/share/message"]
# 进入容器查看
[root@k8smaster pods]# kubectl exec -it lifecycle-demo -- /bin/sh
# cat /usr/share/message
Hello from the postStart handler
7、pod状态
- 挂起( Pending ): Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod
- 运行中( Running ):该 Pod 已经绑定到了一个节点上, Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态
- 成功( Succeeded ): Pod 中的所有容器都被成功终止,并且不会再重启 常见job和cronjob
- 失败( Failed ): Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0
- 未知( Unknown ):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败
二、控制器
- Kubernetes中内建了很多controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为,也就是说pod是最小的调度单元,而控制器用来管理pod,由控制器管理的pod死亡后,会被拉起,而没被管理的pod不会被管(也就是自主式pod)
1、Replication Controller(RC)
Replication Controller(RC)是Kubernetes系统中核心概念之一,当我们定义了一个 RC并提交到Kubernetes集群中以后,Master节点上的Controller Manager组件就得到通知,定期检查系统中存活的Pod,并确保目标Pod实例的数量刚好等于RC的预期值,如果有过多或过少的Pod运行,系统就会停掉或创建一些Pod.此外我们也可以通过修改RC副本数量,来实现Pod的动态缩放功能,也就是说RC用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收
资源清单示例
apiVersion: v1
kind: ReplicationController
metadata:
name: rcdemo
spec:
# pod需要保持的副本数
replicas: 3
# RC的标签选择器
selector:
# 所管理的Pod上有tier=frontend 这个标签,也就是说RC是通过labels来区分自己要管理的Pod,不支持集合式的selector
tier: frontend
# template 相当于定义的Pod
template:
metadata:
# pod的标签key=value的形式 如果跟RC所需要的一致,就会被匹配到的RC管理
labels:
tier: frontend
spec:
# pod中的容器
containers:
- name: mynginx
image: nginx
# 容器内部添加环境变量
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80
# 创建RC
[root@k8smaster deployments]# kubectl apply -f rcdemo.yaml
replicationcontroller/rcdemo created # 查看rc DESIRED:设计数量 CURRENT:当前数量 READY:准备的数量
[root@k8smaster deployments]# kubectl get rc
NAME DESIRED CURRENT READY AGE
rcdemo 3 3 3 11m 并查看Pod Pod名称规则(控制器name+随机字符串)
[root@k8smaster deployments]# kubectl get pod
NAME READY STATUS RESTARTS AGE
rcdemo-4sgkd 1/1 Running 0 37s
rcdemo-hkhfw 1/1 Running 0 37s
rcdemo-xnr2n 1/1 Running 0 37s # 删除所有pod 在查看pod是否被控制器拉起
[root@k8smaster deployments]# kubectl delete pod --all
pod "rcdemo-4sgkd" deleted
pod "rcdemo-hkhfw" deleted
pod "rcdemo-xnr2n" deleted # --show-labels(显示标签) 被拉起的Pod和原来的完全不一样 说明是重新创建的
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
rcdemo-bxtzt 1/1 Running 0 62s tier=frontend
rcdemo-f2pnn 1/1 Running 0 62s tier=frontend
rcdemo-gbxt4 1/1 Running 0 62s tier=frontend # 修改其中一个Pod的label 观察Pod情况 发现多了一个Pod(说明了控制器是通过label来控制Pod的)
[root@k8smaster deployments]# kubectl label pod rcdemo-bxtzt tier=frontend123 --overwrite
pod/rcdemo-bxtzt labeled
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
rcdemo-8kt4h 1/1 Running 0 14s tier=frontend
rcdemo-bxtzt 1/1 Running 0 7m34s tier=frontend123
rcdemo-f2pnn 1/1 Running 0 7m34s tier=frontend
rcdemo-gbxt4 1/1 Running 0 7m34s tier=frontend
2、ReplicaSet(RS)
Kubernetes 官方建议使用 RS(ReplicaSet ) 替代 RC (ReplicationController ) 进行部署,RS 跟 RC 没有本质的不同,只是名字不一样,并且 RS 支持集合式的 selector
资源清单示例
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rsdemo
spec:
# pod需要保持的副本数
replicas: 3
# RC的标签选择器
selector:
# 所管理的Pod上需要有tier=frontend 这个标签,也就是说RS是通过labels来区分自己要管理的Pod,支持集合式的selector matchLabels等(RC不支持)
matchLabels:
tier: frontend
# template 相当于定义的Pod
template:
metadata:
# pod的标签key=value的形式 如果跟RC所需要的一致,就会被匹配到的RS管理
labels:
tier: frontend
spec:
# pod中的容器
containers:
- name: mynginx
image: nginx
# 容器内部添加环境变量
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80
# 使用效果和RC一样
3、Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 (declarative) 方法,用来替代以前的ReplicationController来方便的管理应用,Kubenetes v1.2 引入的新概念,引入的目的是为了更好的解决 Pod 的编排问题,Deployment 内部使用了 Replica Set 来实现。Deployment 的定义与 Replica Set 的定义很类似
应用场景
- RS和RC只能维持Pod的副本数量,功能薄弱
- 定义 Deployment 来创建 Pod 和 ReplicaSet
- 滚动升级和回滚应用:可以动态的切换版本,底层使用不同的RS来实现的
- 扩容和缩容:增加或减少副本的数量
- 暂停和继续 Deployment
- 滚动升级和回滚
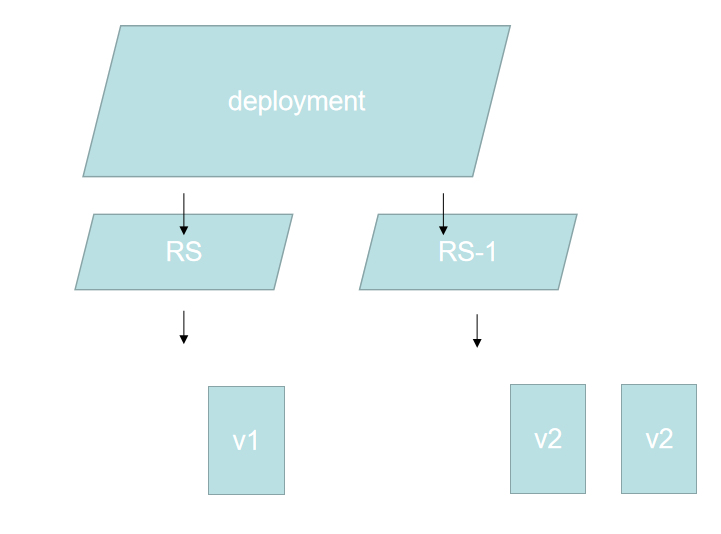
说明:从V1版升级到V2版 共有三个Pod副本
- 1.创建新的RS1,创建一个(数量可控)新的V2Pod,当新的V2Pod可以正常使用后,删除一个旧的V1Pod,保证k8s集群中该中Pod的数量不会变,直至所有的V1Pod换成V2Pod,并且旧的RS不会被删除(用于回滚)
- 2.回滚的过程和上述相反,启动旧的RS
资源清单示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
# 这个版本的Deployment不能省去selector
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
# 启动Deployment 查看 Deployment 、rs(rs名称规则:Deployment的name+随机字符串) 和 pod (pod名称规则:rs的name+随机字符串)
# --record 方便查看版本
[root@k8smaster deployments]# kubectl apply -f nginx-deployment.yaml --record
deployment.apps/nginx-deployment created [root@k8smaster deployments]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 42s [root@k8smaster deployments]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-5bf87f5f59 3 3 3 47s [root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-5bf87f5f59-hxj25 1/1 Running 0 93s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-wgw7w 1/1 Running 0 93s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-zcf82 1/1 Running 0 93s app=nginx,pod-template-hash=5bf87f5f59 # 动态扩容到10个Pod副本
[root@k8smaster deployments]# kubectl scale deployment nginx-deployment --replicas 10
deployment.apps/nginx-deployment scaled
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-5bf87f5f59-58vtn 1/1 Running 0 29s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-dmrrs 1/1 Running 0 29s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-f7cl6 1/1 Running 0 29s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-g5n6j 1/1 Running 0 29s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-gsvpd 1/1 Running 0 29s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-hfmjh 1/1 Running 0 29s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-hxj25 1/1 Running 0 2m30s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-wgw7w 1/1 Running 0 2m30s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-wzjtm 1/1 Running 0 29s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-zcf82 1/1 Running 0 2m30s app=nginx,pod-template-hash=5bf87f5f59 # 动态缩减到3个Pod副本 发现还是原来的那3个 说明会保留存活时间长的
[root@k8smaster deployments]# kubectl scale deployment nginx-deployment --replicas 3
deployment.apps/nginx-deployment scaled
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-5bf87f5f59-hxj25 1/1 Running 0 3m11s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-wgw7w 1/1 Running 0 3m11s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-zcf82 1/1 Running 0 3m11s app=nginx,pod-template-hash=5bf87f5f59
[root@k8smaster deployments]# # 动态扩容和缩减都不会重新创建新的RS
[root@k8smaster deployments]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-5bf87f5f59 3 3 3 5m9s# 滚动更新 更新镜像版本 查看 RS 和 pod
[root@k8smaster deployments]# kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
deployment.apps/nginx-deployment image updated
# 已经创建了新的RS
[root@k8smaster deployments]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-5bf87f5f59 3 3 3 9m46s
nginx-deployment-678645bf77 1 1 0 3s
# 已经启动的新Pod
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-5bf87f5f59-hxj25 1/1 Running 0 9m49s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-wgw7w 1/1 Running 0 9m49s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-zcf82 1/1 Running 0 9m49s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-678645bf77-4k5ls 0/1 ContainerCreating 0 6s app=nginx,pod-template-hash=678645bf77 # 持续观察 RS 和 pod READY的数量始终会保持在我们需要的副本数量
[root@k8smaster deployments]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-5bf87f5f59 1 1 1 10m
nginx-deployment-678645bf77 3 3 2 41s
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-5bf87f5f59-wgw7w 1/1 Running 0 10m app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-678645bf77-4k5ls 1/1 Running 0 48s app=nginx,pod-template-hash=678645bf77
nginx-deployment-678645bf77-szk6f 1/1 Running 0 18s app=nginx,pod-template-hash=678645bf77
nginx-deployment-678645bf77-tm4jl 0/1 ContainerCreating 0 16s app=nginx,pod-template-hash=678645bf77 # 最终结果 旧的RS并没有删除
[root@k8smaster deployments]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
nginx-deployment-5bf87f5f59 0 0 0 23m nginx nginx:1.7.9 app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-678645bf77 3 3 3 13m nginx nginx:1.9.1 app=nginx,pod-template-hash=678645bf77
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-678645bf77-4k5ls 1/1 Running 0 67s app=nginx,pod-template-hash=678645bf77
nginx-deployment-678645bf77-szk6f 1/1 Running 0 37s app=nginx,pod-template-hash=678645bf77
nginx-deployment-678645bf77-tm4jl 1/1 Running 0 35s app=nginx,pod-template-hash=678645bf77 # 使用 kubectl edit deployment/nginx-deployment 可以编辑资源的yaml
# 回滚到上一个版本 启用上一个版本对应的RS
[root@k8smaster deployments]# kubectl rollout undo deployment/nginx-deployment
deployment.apps/nginx-deployment rolled back
[root@k8smaster deployments]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
nginx-deployment-5bf87f5f59 2 2 1 27m nginx nginx:1.7.9 app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-678645bf77 2 2 2 17m nginx nginx:1.9.1 app=nginx,pod-template-hash=678645bf77
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-5bf87f5f59-97lds 1/1 Running 0 9s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-lb7mm 1/1 Running 0 13s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-zltbv 1/1 Running 0 11s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-678645bf77-4k5ls 0/1 Terminating 0 18m app=nginx,pod-template-hash=678645bf77
nginx-deployment-678645bf77-szk6f 0/1 Terminating 0 17m app=nginx,pod-template-hash=678645bf77
nginx-deployment-678645bf77-tm4jl 0/1 Terminating 0 17m app=nginx,pod-template-hash=678645bf77
[root@k8smaster deployments]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
nginx-deployment-5bf87f5f59 3 3 3 28m nginx nginx:1.7.9 app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-678645bf77 0 0 0 18m nginx nginx:1.9.1 app=nginx,pod-template-hash=678645bf77
[root@k8smaster deployments]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-5bf87f5f59-97lds 1/1 Running 0 26s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-lb7mm 1/1 Running 0 30s app=nginx,pod-template-hash=5bf87f5f59
nginx-deployment-5bf87f5f59-zltbv 1/1 Running 0 28s app=nginx,pod-template-hash=5bf87f5f59 # 查看回滚状态如果 rollout 成功完成, kubectl rollout status 将返回一个0值的 Exit Code
[root@k8smaster deployments]# kubectl rollout status deployment/nginx-deployment
deployment "nginx-deployment" successfully rolled out
[root@k8smaster deployments]# echo $?
0 # 查看版本 前面的REVISION可用于回退于指定版本
[root@k8smaster deployments]# kubectl rollout history deployment/nginx-deployment deployment.apps/nginx-deployment
REVISION CHANGE-CAUSE
2 kubectl apply --filename=nginx-deployment.yaml --record=true
3 kubectl apply --filename=nginx-deployment.yaml --record=true# Deployment 更新策略
# Deployment 可以保证在升级时只有一定数量的 Pod 是 down 的。默认的,它会确保至少有比期望的Pod数量少一个是up状态(最多一个不可用)
# Deployment 同时也可以确保只创建出超过期望数量的一定数量的 Pod。默认的,它会确保最多比期望的Pod数量多一个的 Pod 是 up 的(最多1个 surge )
[root@k8smaster deployments]# kubectl describe deployments
Name: nginx-deployment
Namespace: default
CreationTimestamp: Wed, 16 Dec 2020 10:57:54 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 3
kubernetes.io/change-cause: kubectl apply --filename=nginx-deployment.yaml --record=true
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge # 未来的 Kuberentes 版本中,将从1-1变成25%-25%
Rollover(多个rollout并行)
- 假如您创建了一个有5个niginx:1.7.9 replica的Deployment,但是当还只有3个nginx:1.7.9 的 replica 创建出来的时候您就开始更新含有5个 nginx:1.9.1 replica 的 Deployment。在这种情况下,Deployment 会立即杀掉已创建的3个 nginx:1.7.9 的 Pod,并开始创建 nginx:1.9.1 的 Pod。它不会等到所有的5个 nginx:1.7.9 的Pod 都创建完成后才开始改变航道
回退Deployment
# 查看版本历史记录 REVISION可用于回退于指定版本
kubectl rollout history deployment/nginx-deployment
[root@k8smaster deployments]# kubectl rollout history deployment/nginx-deployment deployment.apps/nginx-deployment
REVISION CHANGE-CAUSE
2 kubectl apply --filename=nginx-deployment.yaml --record=true
3 kubectl apply --filename=nginx-deployment.yaml --record=true # 回退到当前的上一个版本
kubectl rollout undo deployment/nginx-deployment # 回退到指定版本 可以使用 --revision参数指定某个历史版本
kubectl rollout undo deployment/nginx-deployment --to-revision=2 # 暂停 deployment 的更新
kubectl rollout pause deployment/nginx-deployment # 通过设置.spec.revisonHistoryLimit来指定deployment最多保留多少revision历史记录。默认会保留所有revision;如果将该项设置为0,Deployment 就不能回退
4、DaemonSet
DaemonSet 确保全部(或者一些)Node上运行一个Pod 的副本。当有Node加入集群时,也会为他们新增一个Pod 。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod,也就是说由DaemoSet控制的Pod会在每个Node上都会运行一个,相当于一个守护模式,当有新的Node加入到集群时,新的Node也会有这种Pod,当有Node退出集群时,这个Node上的Pod就会删除
应用场景
- 运行集群存储 daemon,例如在每个 Node 上运行 glusterd 、 ceph
- 在每个 Node 上运行日志收集 daemon,例如 fluentd 、 logstash
- 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、 collectd 、Datadog 代理、New Relic 代理,或 Ganglia gmond
资源清单示例
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: deamonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: deamonset-example
template:
metadata:
labels:
name: deamonset-example
spec:
containers:
- name: daemonset-example
image: nginx
# 启动deamonset-example
[root@k8smaster deployments]# kubectl apply -f deamonset-example.yaml
daemonset.apps/deamonset-example created # 查看 DaemonSet
[root@k8smaster deployments]# kubectl get daemonset
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
deamonset-example 2 2 2 2 2 <none> 71s # 查看 Pod node1和node2节点上各一个
[root@k8smaster deployments]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deamonset-example-5l9f6 1/1 Running 0 28s 10.244.2.31 k8snode1 <none> <none>
deamonset-example-lwhrl 1/1 Running 0 28s 10.244.1.35 k8snode2 <none> <none>
5、StatefulSet
StatefulSet作为Controller为Pod提供唯一的标识。它可以保证部署和scale的顺序
StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计)例如mysql
应用场景
- 定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
- 有序收缩,有序删除(即从N-1到0)
需要用到的知识有service,pvc存储等,可先跳过,先学习下前置知识
在PVC模块详细介绍
6、Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
Job Spec
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure(仅执行成功一次所以不能用Always)
- 单个Pod时,默认Pod成功运行后Job即结束
- .spec.completions 标志Job结束需要成功运行的Pod个数,默认为1 (Pod的返回码为0时成功一次)
- .spec.parallelism 标志并行运行的Pod的个数,默认为1
- .spec.activeDeadlineSeconds 标志失败Pod的重试最大时间,超过这个时间不会继续重试
资源清单示例
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
# 该镜像用于计算圆周率 CMD是将2000位的圆周率输出
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
# 创建job
[root@k8smaster deployments]# kubectl apply -f job-test.yaml
job.batch/pi created # 查看job 已经成功结束
[root@k8smaster deployments]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 1/1 90s 109s # 查看pod 已经成功结束
[root@k8smaster deployments]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-ljl4g 0/1 Completed 0 101s # 查看pod日志
[root@k8smaster deployments]# kubectl logs pi-ljl4g
3.1415926535897932384626433832795028841971693993751058209...以后位数省略
7、CronJob
CronJob管理基于时间的 Job
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
- 使用条件:当前使用的 Kubernetes 集群,版本 >= 1.8(对 CronJob)
- CronJob通过创建Job来进行管理
应用场景
- 在给定的时间点调度 Job 运行
- 建周期性运行的 Job,例如:数据库备份、发送邮件
CronJob Spec
- .spec.schedule指定任务运行周期,格式同Cron
- .spec.jobTemplate指定需要运行的任务,格式同Job,包含了.spec.completions、.spec.parallelism、.spec.activeDeadlineSeconds
- .spec.startingDeadlineSeconds :启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
- .spec.concurrencyPolicy :并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:
- Allow (默认):允许并发运行 Job
- Forbid :禁止并发运行,如果前一个还没有完成,则直接跳过下一个
- Replace :取消当前正在运行的 Job,用一个新的来替换
- 注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行
- .spec.suspend :挂起,该字段也是可选的。如果设置为true ,后续所有执行都会被挂起。它对已经开始执行的Job不起作用。默认值为 false
- .spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit :历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为3和1 。设置限制的值为0 ,相关类型的Job完成后将不会被保留
- .spec.startingDeadlineSeconds指定任务开始的截止期限
资源清单示例
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
# 一分钟创建一个Job去执行 (分钟 小时 天 月 周)
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
# 启动cronjob
[root@k8smaster deployments]# kubectl apply -f cronjob-test.yaml
cronjob.batch/hello created # 查看cronjob
[root@k8smaster deployments]# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 <none> 12s # 等待几分钟查看job和pod 默认只保留3条
[root@k8smaster deployments]# kubectl get job
NAME COMPLETIONS DURATION AGE
hello-1608103680 1/1 16s 2m49s
hello-1608103740 1/1 17s 108s
hello-1608103800 1/1 17s 48s
[root@k8smaster deployments]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-1608103680-68c5t 0/1 Completed 0 2m54s
hello-1608103740-9rwpl 0/1 Completed 0 114s
hello-1608103800-fjv7z 0/1 Completed 0 54s注意事项:
- 创建Job操作应该是幂等的(防止后面的运行结果影响前面的结果)
- cronjob不能连接到job的成功,只会周期的创建job,但是job是否运行成功可以监测到
三、Service
Kubernetes Service定义了这样一种抽象:一个Pod的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。 这一组Pod能够被Service访问到,通常是通过Label Selector,标签选择不到创建的是空集群
Kubernetes Service可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上,提供了服务注册与发现(因为Pod挂掉之后,新创建的Pod的原来的完全不一样,防止Pod失联),相当于注册中心
Service能够提供负载均衡的能力,但是在使用上有以下限制
- 只提供 4 层负载均衡能力,而没有7层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上 4 层负载均衡是不支持的,仅支持轮询算法
- 四层负载均衡:通过Ip和端口进行转发
- 七层负载均衡:主机和域名进行转发(k8s通过ingress可以实现)
service原理:
service分类
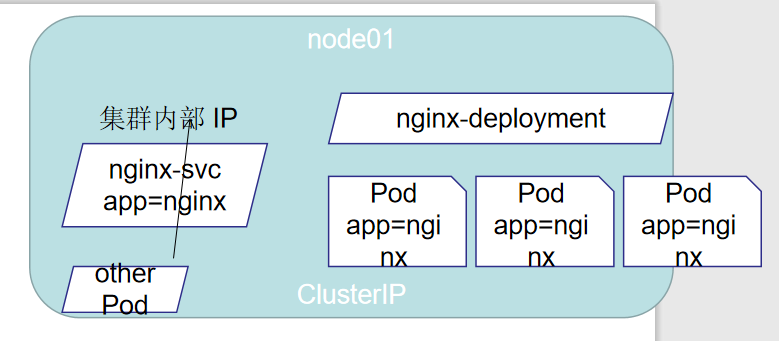
- ClusterIp:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP
- NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 : NodePort 来访问该服务
- LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部负载均衡器,并将请求转发到: NodePort
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 kubernetes 1.7 或更高版本的 kube-dns 才支持
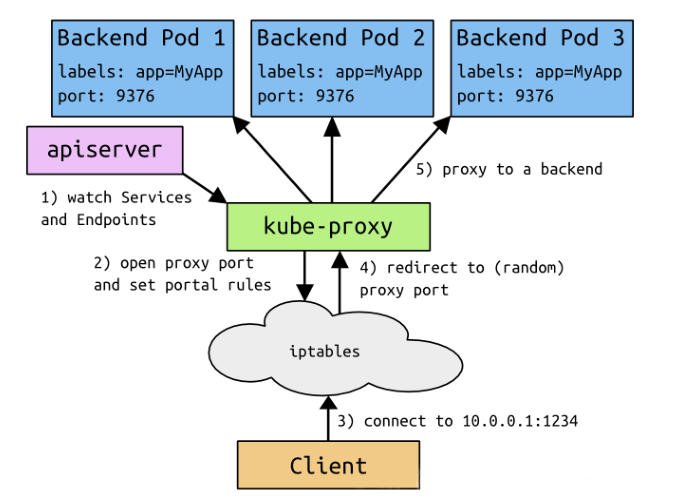
VIP和Service代理
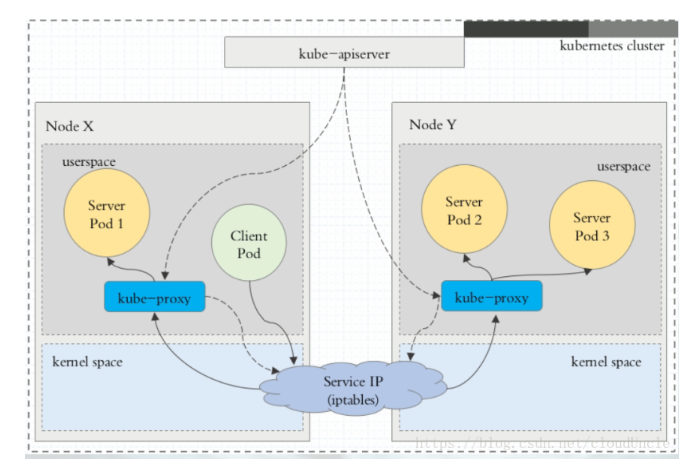
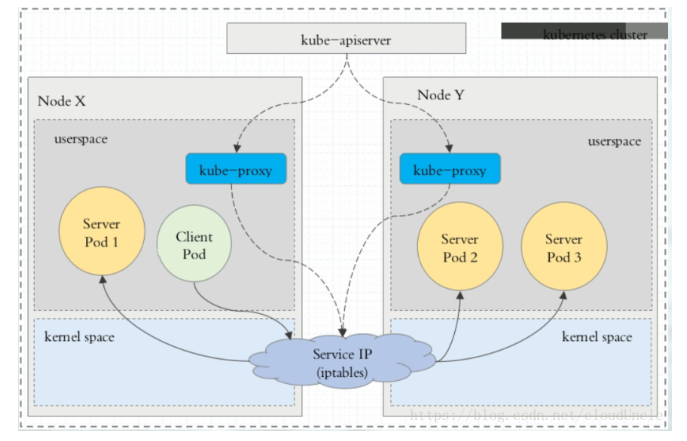
- 在 Kubernetes 集群中,每个 Node 运行一个kube-proxy 进程。kube-proxy负责为Service实现了一种VIP(虚拟 IP)的形式,而不是ExternalName的形式。 在Kubernetes v1.0 版本,代理完全在 userspace。在Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。 从 Kubernetes v1.2 起,默认就是iptables 代理。 在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理
在 Kubernetes 1.14 版本开始默认使用 ipvs 代理 - 在 Kubernetes v1.0 版本, Service 是 “4层”(TCP/UDP over IP)概念。 在 Kubernetes v1.1 版本,新增了Ingress API(beta 版),用来表示 “7层”(HTTP)服务
- 为什么不使用DNS代理
- 因为DNS有缓存,不能实现负载均衡
- 在 Kubernetes 集群中,每个 Node 运行一个kube-proxy 进程。kube-proxy负责为Service实现了一种VIP(虚拟 IP)的形式,而不是ExternalName的形式。 在Kubernetes v1.0 版本,代理完全在 userspace。在Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。 从 Kubernetes v1.2 起,默认就是iptables 代理。 在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理
代理模式分类
userspace 代理模式
iptables 代理模式
ipvs 代理模式
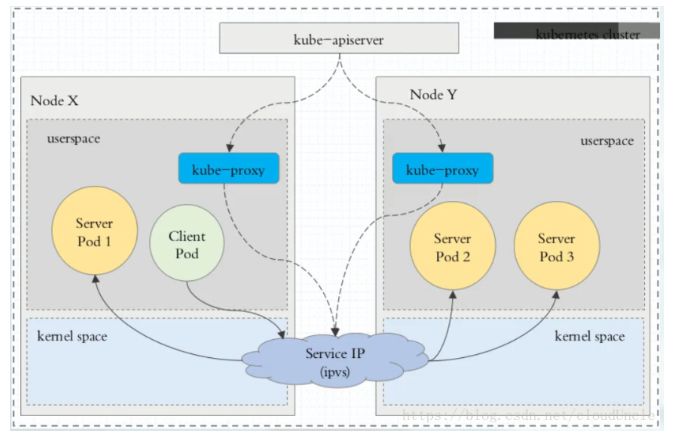
这种模式,kube-proxy 会监视 Kubernetes Service 对象和 Endpoints ,调用 netlink 接口以相应地创建ipvs 规则并定期与 Kubernetes Service 对象和 Endpoints 对象同步 ipvs 规则,以确保 ipvs 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod与 iptables 类似,ipvs 于 netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs 可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs 为负载均衡算法提供了更多选项,例如:
- rr :轮询调度
- lc :最小连接数
- dh :目标哈希
- sh :源哈希
- sed :最短期望延迟
- nq : 不排队调度
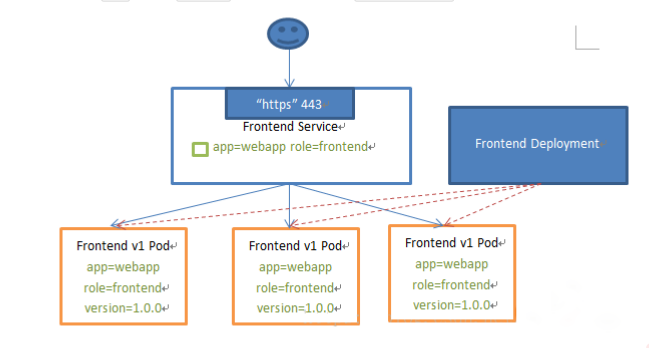
1、ClusterIp
默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP(自身节点也可访问)
clusterIP 主要在每个 node 节点使用 iptables或ipvs,将发向 clusterIP 对应端口的数据,转发到 kube-proxy 中。然后 kube-proxy 自己内部实现有负载均衡的方法,并可以查询到这个 service 下对应 pod 的地址和端口,进而把数据转发给对应的 pod 的地址和端口
- apiserver 用户通过kubectl命令向apiserver发送创建service的命令,apiserver接收到请求后将数据存储到etcd中
- kube-proxy kubernetes的每个节点中都有一个叫做kube-porxy的进程,这个进程负责感知service,pod的变化,并将变化的信息写入本地的iptables规则中
- iptables 使用NAT等技术将virtualIP的流量转至endpoint中
- 服务支持tcp和UDP,但是默认的是TCP
资源清单示例
# deployment 的资源清单
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
# 需要匹配的标签
matchLabels:
app: myapp
release: stabel
template:
metadata:
# Pod携带的标签
labels:
app: myapp
release: stabel
env: test
spec:
containers:
- name: myapp
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
# ClusterIP service 的资源清单
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
# service 的类型
type: ClusterIP
# 通过标签来选择pod,需全部满足
selector:
app: myapp
release: stabel
# 暴露端口
ports:
# name 是pod的一个端口
- name: http
# 集群内部使用的端口
port: 80
# 转发到其下Pod的容器端口 负载均衡算法是轮询
targetPort: 80
# 创建myapp-deploy的deployment 并查看Pod
[root@k8smaster services]# kubectl apply -f myapp-deploy.yaml
deployment.apps/myapp-deploy created
[root@k8smaster services]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
myapp-deploy 3/3 3 3 14s
[root@k8smaster services]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-deploy-7c4dbc97b9-qk62v 1/1 Running 0 20s
myapp-deploy-7c4dbc97b9-qvx4h 1/1 Running 0 20s
myapp-deploy-7c4dbc97b9-svsww 1/1 Running 0 20s # 创建service并查看
[root@k8smaster services]# kubectl apply -f clusterip.yaml
service/myapp created
[root@k8smaster services]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20h <none>
myapp ClusterIP 10.110.54.87 <none> 80/TCP 6m28s app=myapp,release=stabel # 使用 CLUSTER-IP 进行访问
[root@k8smaster services]# curl 10.110.54.87:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p> <p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p>
</body>
</html>
2、Headless
有时不需要或不想要负载均衡,以及单独的 Service IP 。遇到这种情况,可以通过指定 ClusterIP(spec.clusterIP) 的值为 “None” 来创建 Headless Service 。这类 Service 并不会分配 Cluster IP, kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由,简单点说CLUSTER-IP为None 部署有状态服务时必须使用
资源清单示例
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
clusterIP: "None"
ports:
- port: 80
targetPort: 80
# 创建无头service并查看
[root@k8smaster services]# kubectl apply -f headless.yaml
service/myapp-headless created
[root@k8smaster services]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h <none>
myapp-headless ClusterIP None <none> 80/TCP 4s app=myapp # 通过endpoints查看其关联的Pod
[root@k8smaster services]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.47.150:6443 66s
myapp-headless 10.244.1.76:80,10.244.2.73:80,10.244.2.74:80 8s
通过解析域名的方式查看Headless所关联的Pod(也就意味着没有CLUSTER-IP,还能使用域名的方式去访问Headless)
# 查看系统Pod 其中 coredns 就是负责域名解析的
[root@k8smaster services]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-7ff77c879f-494fb 1/1 Running 2 41h 10.244.2.14 k8snode1 <none> <none>
coredns-7ff77c879f-tvgrz 1/1 Running 2 42h 10.244.1.20 k8snode2 <none> <none>
etcd-k8smaster 1/1 Running 3 6d14h 192.168.47.150 k8smaster <none> <none>
kube-apiserver-k8smaster 1/1 Running 3 6d14h 192.168.47.150 k8smaster <none> <none>
kube-controller-manager-k8smaster 1/1 Running 15 6d14h 192.168.47.150 k8smaster <none> <none>
kube-flannel-ds-amd64-hflj8 1/1 Running 4 6d1h 192.168.47.150 k8smaster <none> <none>
kube-flannel-ds-amd64-s9xhk 1/1 Running 3 6d1h 192.168.47.162 k8snode2 <none> <none>
kube-flannel-ds-amd64-wp7mp 1/1 Running 4 6d1h 192.168.47.161 k8snode1 <none> <none>
kube-proxy-5l8kb 1/1 Running 2 42h 192.168.47.150 k8smaster <none> <none>
kube-proxy-6n8vp 1/1 Running 2 42h 192.168.47.161 k8snode1 <none> <none>
kube-proxy-lgcxp 1/1 Running 2 42h 192.168.47.162 k8snode2 <none> <none>
kube-scheduler-k8smaster 1/1 Running 16 6d14h 192.168.47.150 k8smaster <none> <none> # 使用dig 命令 解析域名 dig -t A service名.命名空间名.svc.cluster.local.(默认集群域名) @coredns的Ip(任意一个即可)
# 如果没有dig 命令 安装即可 yum -y install bind-utils
# 我们发现 其中所关联的Pod都显示了出来
[root@k8smaster services]# dig -t A myapp-headless.default.svc.cluster.local. @10.244.2.14 ; <<>> DiG 9.11.13-RedHat-9.11.13-3.el8 <<>> -t A myapp-headless.default.svc.cluster.local. @10.244.2.14
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37833
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 96e732da9566602d (echoed)
;; QUESTION SECTION:
;myapp-headless.default.svc.cluster.local. IN A ;; ANSWER SECTION:
myapp-headless.default.svc.cluster.local. 30 IN A 10.244.2.73
myapp-headless.default.svc.cluster.local. 30 IN A 10.244.2.74
myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.76 ;; Query time: 2 msec
;; SERVER: 10.244.2.14#53(10.244.2.14)
;; WHEN: Thu Dec 17 11:02:40 CST 2020
;; MSG SIZE rcvd: 249
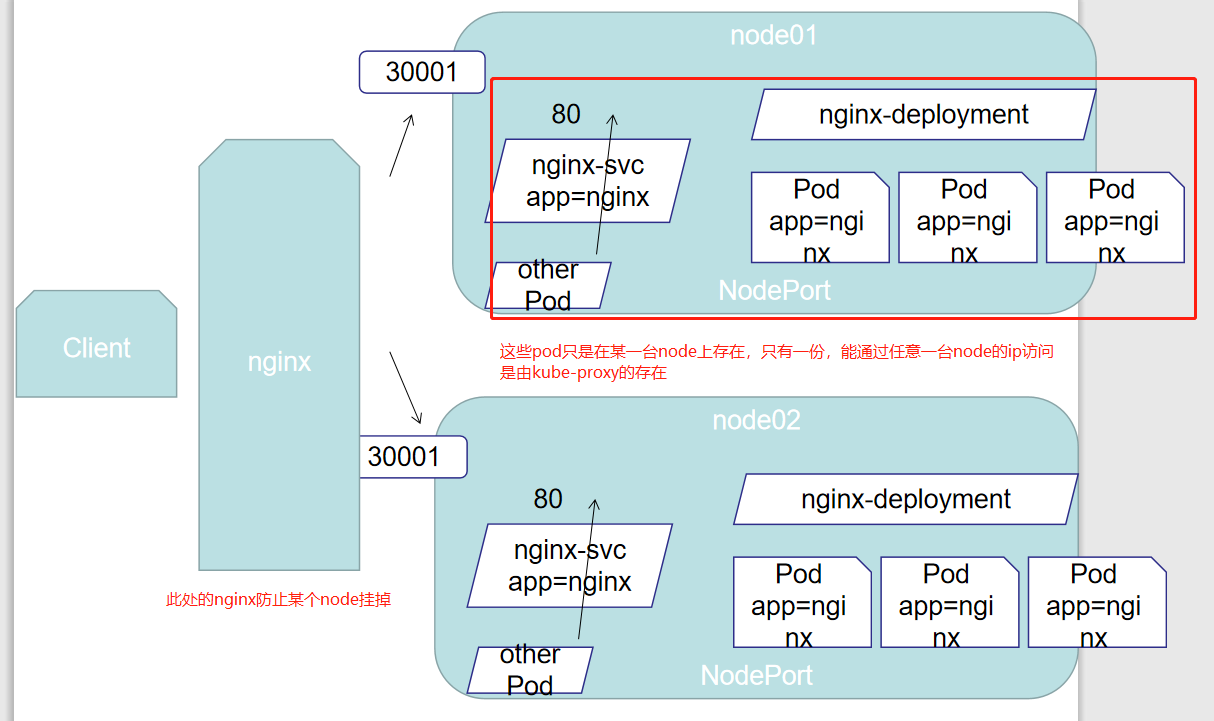
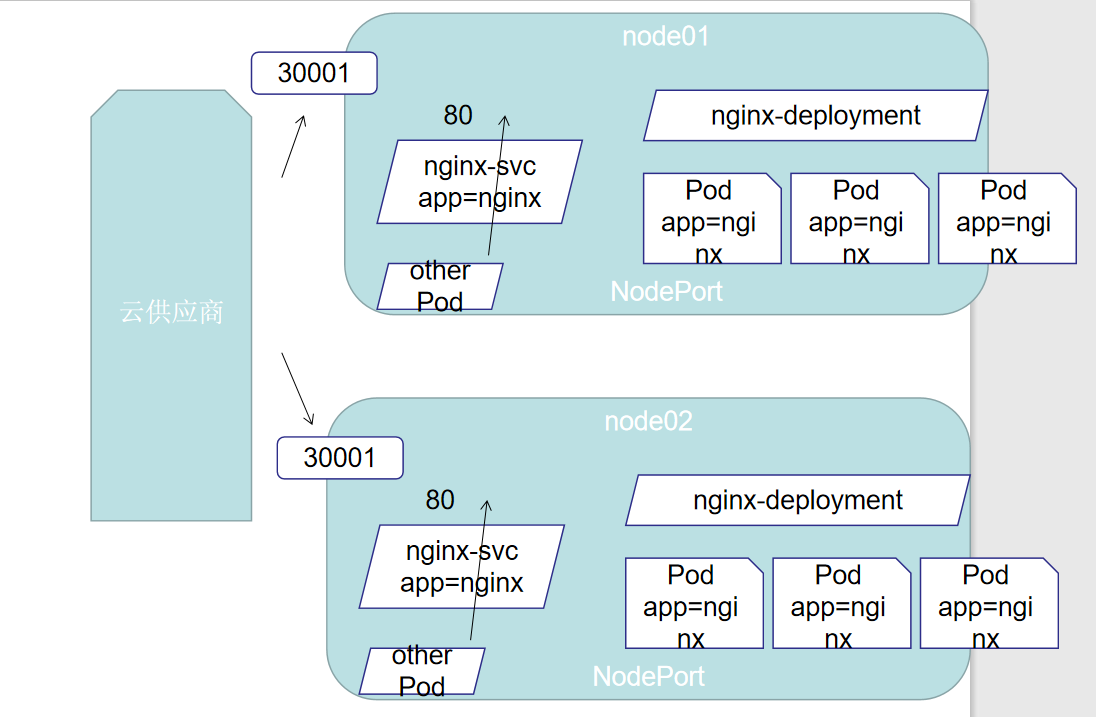
3、NodePort
nodePort的原理在于在node上开了一个端口,将向该端口的流量导入到kube-proxy,然后由kube-proxy进一步到给对应的pod
将服务暴露给集群外部使用,可指定端口
NodePort,Kubernetes master会分配一个区域范围内,(默认是30000-32767),并且,每一个node,都会代理(proxy)这个端口到你的服务中,我们可以在spec.ports[*].nodePort 找到具体的值,如果我们向指定一个端口,我们可以直接写在nodePort上,系统就会给你指派指定端口,但是这个值必须是指定范围内的
资源清单示例
apiVersion: v1
kind: Service
metadata:
name: myapp-nodeport
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
# node暴露的端口 外界使用任意nodeIp:该端口 不指定随机分配
nodePort: 30001
# 创建myapp-nodeport并查看service
[root@k8smaster services]# kubectl apply -f nodeport.yaml
service/myapp-nodeport created
[root@k8smaster services]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h <none>
myapp-nodeport NodePort 10.111.91.90 <none> 80:30001/TCP 4s app=myapp,release=stabel # 经过测试 在外界使用任意nodeIp:30001 都可访问成功 # iptables -t nat -nvL 查询转发流程
# ipvsadm -Ln 查询转发流程
[root@k8smaster services]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 192.168.47.150:6443 Masq 1 1 0
TCP 10.96.0.10:53 rr
-> 10.244.1.20:53 Masq 1 0 0
-> 10.244.2.14:53 Masq 1 0 0
4、LoadBalancer
- loadBalancer 和 nodePort 其实是同一种方式。区别在于 loadBalancer 比 nodePort 多了一步,就是可以调用cloud provider 去创建LB来向节点导流(nodePort使用的是nginx等其他)
- 云服务商收费
5、ExternalName
这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容( 例如:www.baidu.com )。ExternalName Service 是 Service 的特例,它没有 selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务
在集群内部访问集群外部的服务
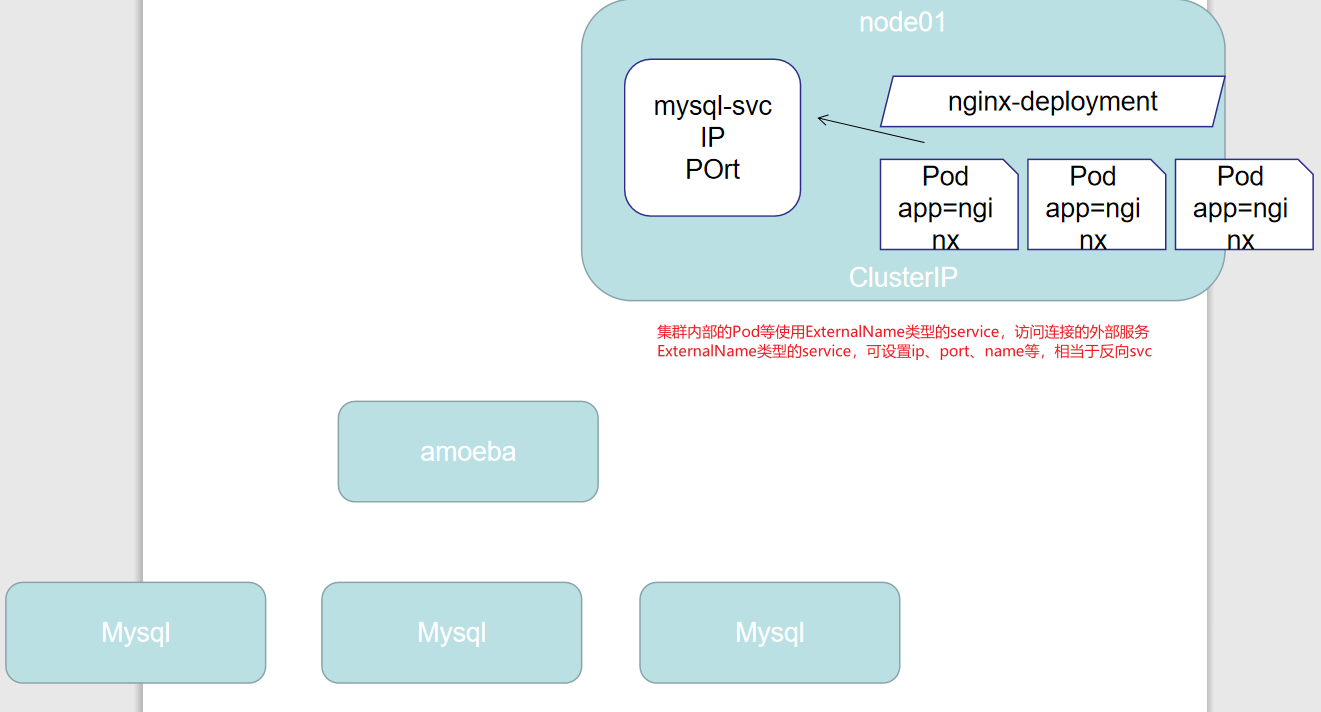
资源清单示例
apiVersion: v1
kind: Service
metadata:
# 名称externalName-1、externalName1 为什么不合法 不能使用驼峰 只能用-连接单词 并且还要小写
name: external1
namespace: default
spec:
type: ExternalName
# 连接的外界域名
externalName: www.baidu.com
# 查看ExternalName类型的service
[root@k8smaster services]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
external1 ExternalName <none> www.baidu.com <none> 15h
当查询主机 my-service.defalut.svc.cluster.local ( SVC_NAME.NAMESPACE.svc.cluster.local )时,集群的DNS 服务将返回一个值 my.database.example.com 的 CNAME 记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发
6、Multi-Port
可能很多服务需要开发不止一个端口,为了满足这样的情况,Kubernetes允许在定义时候指定多个端口,当我们使用多个端口的时候,我们需要指定所有端口的名称,这样endpoints才能清楚
资源清单示例
apiVersion: v1
kind: Service
metadata:
name: multiPort
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
# 查看service和endpoints
[root@k8smaster services]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h [root@k8smaster services]# kubectl get endpoints
NAME ENDPOINTS AGE
multi-port 10.244.1.76:9376,10.244.2.73:9376,10.244.2.74:9376 + 3 more... 48s
7、Endpoints
当我们创建一个service之后,我们可以使用这个service对Pod进行访问,而service是通过标签的选择来确定访问那些Pod,Kubernete提供了一个简单的Endpoints API,这个Endpoints api的作用就是当一个服务中的pod发生变化时,Endpoints API随之变化,对于哪些不是原生的程序,Kubernetes提供了一个基于虚拟IP的网桥的服务,这个服务会将请求转发到对应的后台pod,也就是service和pod的对应关系,通过Endpoints可以找到,当我们创建一个service之后,k8s就会创建一个同名的Endpoints(没有选择器的情况下 值为None),ExternalName是没有Endpoints的
资源清单示例
apiVersion: v1
kind: Service
metadata:
name: myapp1
namespace: default
spec:
type: ClusterIP
# 通过标签来选择pod,需全部满足 当前环境下并没有携带app=myapp1的Pod,也就是该service连接不到任何Pod 所以Endpoints为null
selector:
app: myapp1
release: stabel
# 暴露端口
ports:
- name: http
# 集群内部使用的端口
port: 80
# 转发到其下Pod的容器端口
targetPort: 80
# 查看service
[root@k8smaster services]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
multi-port NodePort 10.102.72.19 <none> 80:31277/TCP,443:31584/TCP 11s
myapp1 ClusterIP 10.102.0.48 <none> 80/TCP 17m # 查看endpoints 发现myapp1的为<none> 前面的Ip为Pod的ip,端口为targetPort
[root@k8smaster services]# kubectl get endpoints -o wide
NAME ENDPOINTS AGE
multi-port 10.244.1.76:9376,10.244.2.73:9376,10.244.2.74:9376 + 3 more... 63s
myapp1 <none> 18m # 查看pod 发现和endpoints中的ip一致
[root@k8smaster services]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy-7c4dbc97b9-7cdzf 1/1 Running 0 16h 10.244.2.74 k8snode1 <none> <none>
myapp-deploy-7c4dbc97b9-k44kg 1/1 Running 0 16h 10.244.2.73 k8snode1 <none> <none>
myapp-deploy-7c4dbc97b9-lglrv 1/1 Running 0 16h 10.244.1.76 k8snode2 <none> <none>
这种情况下,我们需要手动创建Endpoints,将service和Pod进行关联
资源清单示例
apiVersion: v1
kind: Endpoints
metadata:
# 连接到的servcie名称 如果没有该service,会创建一个新的service 不会对原来的service进行更新
name: myapp1
subsets:
# 连接Pod的Ip和port 外部的也可以
- addresses:
- IP: 10.244.2.74
ports:
- port: 80
# 创建endpoints 并查看
[root@k8smaster services]# kubectl apply -f myapp1endpoints.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
endpoints/myapp1 configured # 发现名为myapp1 的endpoints的ENDPOINTS 不在为<none> 为我们设置的值
[root@k8smaster services]# kubectl get endpoints
NAME ENDPOINTS AGE
multi-port 10.244.1.76:9376,10.244.2.73:9376,10.244.2.74:9376 + 3 more... 63m
myapp1 10.244.2.74:80 80m
8、service转发
我们使用上述NodePort的资源清单创建service 查看其转发规则
这就说明了创建NodePort的service,使用任意node:端口都能访问的原因(包含master),在每个node上都开启了该端口
# 创建service
[root@k8smaster services]# kubectl apply -f nodeport.yaml
service/myapp-nodeport created # 查看service
[root@k8smaster services]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 53s
myapp-nodeport NodePort 10.109.117.16 <none> 80:30001/TCP 10s # 查看service ipvs的转发 ipvsadm -Ln
# 可以发现使用本机IP和127.0.0.1的30001端口 都会转发到任意Pod的80端口上
# 使用CLUSTER-IP:80 都会转发到任意Pod的80端口上
[root@k8smaster services]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.47.150:30001 rr
-> 10.244.1.76:80 Masq 1 0 0
-> 10.244.2.73:80 Masq 1 0 0
-> 10.244.2.74:80 Masq 1 0 0 TCP 10.109.117.16:80 rr
-> 10.244.1.76:80 Masq 1 0 0
-> 10.244.2.73:80 Masq 1 0 0
-> 10.244.2.74:80 Masq 1 0 0 TCP 127.0.0.1:30001 rr
-> 10.244.1.76:80 Masq 1 0 0
-> 10.244.2.73:80 Masq 1 0 0
-> 10.244.2.74:80 Masq 1 0 0 UDP 10.96.0.10:53 rr
-> 10.244.1.20:53 Masq 1 0 0
-> 10.244.2.14:53 Masq 1 0 0 # 还可以使用netstat -ano | grep 30001 查看
2.k8sPod、控制器、service的更多相关文章
- K8s-Pod控制器
在K8s-Pod文档中我们创建的Pod是非托管的Pod,因为Pod被设计为用后就弃的对象,如果Pod正常关闭,K8s会将该Pod清除,它没有自愈的能力.Pod控制器是用来保持Pod状态的一种对象资 ...
- k8spod控制器概述
自主式pod对象由调度器绑定至目标工作节点后即由相应节点上的kubelet负责监控其容器的存活性,容器主进程崩溃后,kubelet能够自动重启相应的容器.不过,kubelet对非主进程崩溃类的容器错误 ...
- 注解@Component,@Controller,@Service,@Repository简单了解
Spring 自 2.0 版本开始,陆续引入了一些注解用于简化 Spring 的开发.@Repository注解便属于最先引入的一批,它用于将数据访问层 (DAO 层 ) 的类标识为 Spring B ...
- service worker介绍
原文:Service workers explained 译者:neal1991 welcome to star my articles-translator, providing you advan ...
- kubernetes机理之调度器以及控制器
一 了解调度器 1.1 调度器是如何将一个pod调度到节点上的 我们都已然知晓了,API服务器不会主动的去创建pod,只是拉起系统组件,这些组件订阅资源状态的通知,之后创建相应的资源,而负责调度po ...
- K8S系列第八篇(Service、EndPoints以及高可用kubeadm部署)
更多精彩内容请关注微信公众号:新猿技术生态圈 更多精彩内容请关注微信公众号:新猿技术生态圈 更多精彩内容请关注微信公众号:新猿技术生态圈 Endpoints 命名空间级资源,如果endpoints和s ...
- springMVC+spring+hibernate 框架整合实例
先说一下流程思路: 流程讲解1:首先访问会先定位到控制器.这就用到了过滤器配置文件"spring-mvc.xml".这个文件负责定义控制器的包路径.视图的格式等.其次从" ...
- springMvc3.0.5搭建全程 (转)
用了大半年的Spring MVC3.0,用着感觉不错.简单写一个搭建Spring MVC3.0的流程(以Spring3.0.5为列),数据库交互使用spring JDBC Template,附件有项目 ...
- spring-mvc不拦截静态资源的配置
spring-mvc不拦截静态资源的配置 标签: spring 2015-03-27 23:54 11587人阅读 评论(0) 收藏 举报 版权声明:本文为博主原创文章,未经博主允许不得转载. &qu ...
- springmvc 例
1.结构 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvaXRscWk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCM ...
随机推荐
- JavaSE 学习笔记01丨开发前言与环境搭建、基础语法
本蒟蒻学习过C/C++的语法,故在学习Java的过程中,会关注于C++与Java的区别.开发前言部分,看了苏星河教程中的操作步骤.而后,主要阅读了<Java核心技术 卷1 基础知识>(第8 ...
- Goland 2020.2.x 激活码永久破解教程 (最新Goland激活码!2020.11.26亲测可用!)
在2020.11.26 Goland的用户们又迎来了一次更新,这就导致很多软件打开时候就提示Goland激活码已经失效,码小辫第一时间给各位分享了关于最新Goland激活破解教程! goland已经更 ...
- IEEE浮点数标准
IEEE浮点数标准 阅读笔记:Computer System : A Programmmer's Perspective 基本概念 IEEE浮点数标准采用 \[V=(-1)^s\times M\tim ...
- SpringIOC循环依赖
目录 1. 什么是循环依赖 注意: 这⾥不是函数的循环调⽤,是对象的相互依赖关系. 循环调⽤其实就是⼀个死循环,除⾮有终结 条件. 2. 循环依赖处理机制 2.1 演示场景: 2.2 处理机制简图 总 ...
- houdini 鱼眼相机
http://mattebb.com/weblog/houdini-fisheye-camera/ 这个网站是有提供一个相机shader的,,如图是方形的,国内的用户,比较多是做球幕的小伙伴,圆形就行 ...
- js声明 对象,数组 的方法
i={} 对象字面量 等同 i = new Object();i=[] 数组字面量 等同 i = new Array();
- day6(celery原理与组件)
1.Celery介绍 1.1 celery应用举例 Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理,如果你的业务场景中需要用到异步任务,就可以考 ...
- python核心高级学习总结3-------python实现进程的三种方式及其区别
python实现进程的三种方式及其区别 在python中有三种方式用于实现进程 多进程中, 每个进程中所有数据( 包括全局变量) 都各有拥有⼀份, 互不影响 1.fork()方法 ret = os.f ...
- PyQt学习随笔:QTableWidget的visualRow、visualColumn、logicalRow、logicalColumn(可见行、逻辑行、可见列、逻辑列)相关概念及方法探究
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概念 关于逻辑行logicalRow.列logicalColumn和可见行visualRow.列 ...
- PyQt(Python+Qt)学习随笔:调用disconnect进行信号连接断开时的信号签名与断开参数的匹配要求
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 在使用信号调用disconnect()方法断开信号和槽的连接时,信号可以带签名也可不带签名,参数可以 ...