面试必问:如何实现Redis分布式锁
摘要:今天我们来聊聊分布式锁这块知识,具体的来看看Redis分布式锁的实现原理。
一、写在前面
现在面试,一般都会聊聊分布式系统这块的东西。通常面试官都会从服务框架(Spring Cloud、Dubbo)聊起,一路聊到分布式事务、分布式锁、ZooKeeper等知识。
所以咱们这篇文章就来聊聊分布式锁这块知识,具体的来看看Redis分布式锁的实现原理。
说实话,如果在公司里落地生产环境用分布式锁的时候,一定是会用开源类库的,比如Redis分布式锁,一般就是用Redisson框架就好了,非常的简便易用。
大家如果有兴趣,可以去看看Redisson的官网,看看如何在项目中引入Redisson的依赖,然后基于Redis实现分布式锁的加锁与释放锁。
下面给大家看一段简单的使用代码片段,先直观的感受一下:
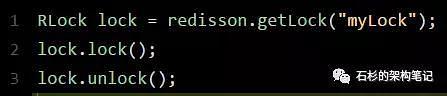
怎么样,上面那段代码,是不是感觉简单的不行!
此外,人家还支持redis单实例、redis哨兵、redis cluster、redis master-slave等各种部署架构,都可以给你完美实现。
二、Redisson实现Redis分布式锁的底层原理
好的,接下来就通过一张手绘图,给大家说说Redisson这个开源框架对Redis分布式锁的实现原理。
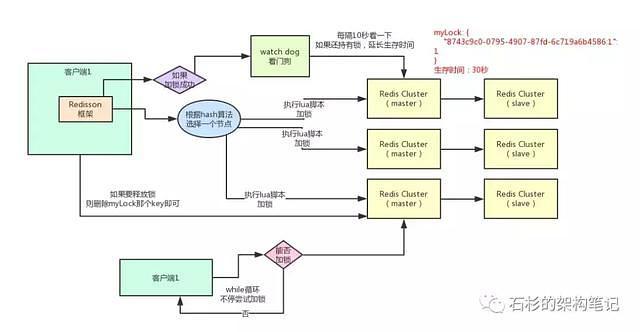
(1)加锁机制
咱们来看上面那张图,现在某个客户端要加锁。如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。
这里注意,仅仅只是选择一台机器!这点很关键!
紧接着,就会发送一段lua脚本到redis上,那段lua脚本如下所示:
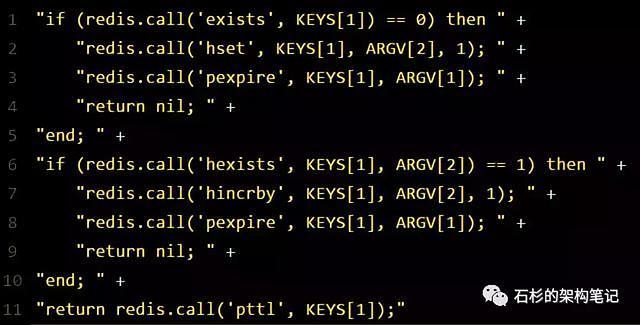
为啥要用lua脚本呢?
因为一大坨复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。
那么,这段lua脚本是什么意思呢?
KEYS[1]代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock("myLock");
这里你自己设置了加锁的那个锁key就是“myLock”。
ARGV[1]代表的就是锁key的默认生存时间,默认30秒。
ARGV[2]代表的是加锁的客户端的ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
给大家解释一下,第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的命令:
hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:
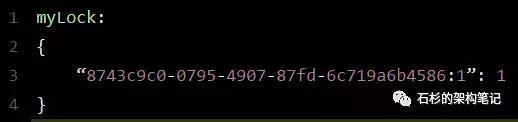
上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁。
接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒。
好了,到此为止,ok,加锁完成了。
(2)锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
(3)watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
(4)可重入加锁机制
那如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
比如下面这种代码:

这时我们来分析一下上面那段lua脚本。
第一个if判断肯定不成立,“exists myLock”会显示锁key已经存在了。
第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock
8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。
此时myLock数据结构变为下面这样:
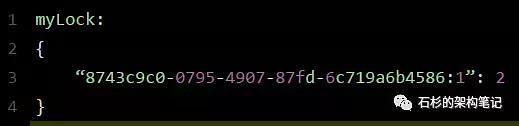
大家看到了吧,那个myLock的hash数据结构中的那个客户端ID,就对应着加锁的次数
(5)释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于redis进行分布式锁的加锁与释放锁。
(6)上述Redis分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
本文分享自华为云社区《redis分布式锁实现原理学习》,原文作者:minjie 。
面试必问:如何实现Redis分布式锁的更多相关文章
- 面试官问我,Redis分布式锁如何续期?懵了。
前言 上一篇[面试官问我,使用Dubbo有没有遇到一些坑?我笑了.]之后,又有一位粉丝和我说在面试过程中被虐了.鉴于这位粉丝是之前肥朝的粉丝,而且周一又要开启新一轮的面试,为了回馈他长期以来的支持,所 ...
- 死磕 java同步系列之redis分布式锁进化史
问题 (1)redis如何实现分布式锁? (2)redis分布式锁有哪些优点? (3)redis分布式锁有哪些缺点? (4)redis实现分布式锁有没有现成的轮子可以使用? 简介 Redis(全称:R ...
- 面试官再问Redis分布式锁如何续期?这篇文章甩 他一脸
一.真实案例 二.Redis分布式锁的正确姿势 据肥朝了解,很多同学在用分布式锁时,都是直接百度搜索找一个Redis分布式锁工具类就直接用了.关键是该工具类中还充斥着很多System.out.prin ...
- redis分布式锁,面试官请随便问,我都会
目录 前言 实现要点 错误解锁方式 正确加锁释放锁方式 前言 现在的业务场景越来越复杂,使用的架构也就越来越复杂,分布式.高并发已经是业务要求的常态.像腾讯系的不少服务,还有CDN优化.异地多备份等处 ...
- 互联网公司面试必问的Redis题目
Redis是一个非常火的非关系型数据库,火到什么程度呢?只要是一个互联网公司都会使用到.Redis相关的问题可以说是面试必问的,下面我从个人当面试官的经验,总结几个必须要掌握的知识点. 介绍:Redi ...
- Redis分布式锁实现Redisson 15问
大家好,我是三友. 在一个分布式系统中,由于涉及到多个实例同时对同一个资源加锁的问题,像传统的synchronized.ReentrantLock等单进程情况加锁的api就不再适用,需要使用分布式锁来 ...
- 面试官:你真的了解Redis分布式锁吗?
什么是分布式锁 说到Redis,我们第一想到的功能就是可以缓存数据,除此之外,Redis因为单进程.性能高的特点,它还经常被用于做分布式锁. 锁我们都知道,在程序中的作用就是同步工具,保证共享资源在同 ...
- 互联网公司面试必问的mysql题目(上)
又到了招聘的旺季,被要求准备些社招.校招的题库.(如果你是应届生,尤其是东北的某大学,绝对福利哦) 介绍:MySQL是一个关系型数据库管理系统,目前属于 Oracle 旗下产品.虽然单机性能比不上or ...
- Redis分布式锁 (图解-秒懂-史上最全)
文章很长,而且持续更新,建议收藏起来,慢慢读! 高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : 极致经典 + 社群大片好评 < Java 高并发 三 ...
随机推荐
- Tensorflow环境配置&安装
Tensorflow环境配置&安装 明知故犯,是不想有遗憾. 背景:Tensorflow 环境配置和安装. 一.安装 Anaconda 二.建立.激活.安装.验证.使用 Tensorflow ...
- [.NET] - EventLog.EntryWritten Event
刚看到在MSND论坛上有人问一个EventLog.EntryWritten Event相关的问题,说是在2015触发了一个2013年的EventWritten的事件,比较好奇,然后查看了下这个类: h ...
- Linux嵌入式学习-交叉编译openssl
利用arm-none-linux-gnueabi-gcc交叉编译openssl,生成静态库文件libcrypto.a ,libssl.a 1.从openssl官网下载openssl最新版本,我下载的是 ...
- 死磕以太坊源码分析之MPT树-上
死磕以太坊源码分析之MPT树-上 前缀树Trie 前缀树(又称字典树),通常来说,一个前缀树是用来存储字符串的.前缀树的每一个节点代表一个字符串(前缀).每一个节点会有多个子节点,通往不同子节点的路径 ...
- Redis 设计与实现 9:五大数据类型之集合
集合对象的编码有两种:intset 和 hashtable 编码一:intset intset 的结构 整数集合 intset 是集合底层的实现之一,从名字就可以看出,这是专门为整数提供的集合类型. ...
- Linux sed 命令总结
一.sed格式命令 sed 命令行格式为:sed [选项] 'command' 输入文本 二.sed命令的选项 sed [选项] [动作] 选项与参数: -n :使用安静(silent)模式.在一般 ...
- ceph对接k8s storage class
简介 对接ceph的rbd和cephfs到k8s中提供持久化存储 环境 主机名 IP role 操作系统 ceph-01 172.16.31.11 mon osd CentOS7.8 ceph-02 ...
- Liunx运维(十二)-Liunx系统常用内置命令
文档目录: 一.Liunx内置命令概述 二.LIunx常用内置命令实例 1.help查看内置命令帮助2.查看内置命令使用方法3.":" 占位符4. "." 与s ...
- Sentry(v20.12.1) K8S 云原生架构探索,玩转前/后端监控与事件日志大数据分析,高性能+高可用+可扩展+可伸缩集群部署
Sentry 算是目前开源界集错误监控,日志打点上报,事件数据实时分析最好用的软件了,没有之一.将它部署到 Kubernetes,再搭配它本身自带的利用 Clickhouse (大数据实时分析引擎)构 ...
- Label_table
<table border(边框) = "" width = height = align = bordercolor(边框色) = cellspacing 表格边框与单元格 ...