为什么堆化 heapify() 只用 O(n) 就做到了?
heapify()
前面两篇文章介绍了什么是堆以及堆的两个基本操作,但其实呢,堆还有一个大名鼎鼎的非常重要的操作,就是 heapify() 了,它是一个很神奇的操作,
可以用 O(n) 的时间把一个乱序的数组变成一个 heap。
但是呢,heapify() 并不是一个 public API,看:

所以我们没有办法直接使用。
唯一使用 heapify() 的方式呢,就是使用
PriorityQueue(Collection<? extends E> c)
这个 constructor 的时候,人家会自动调用 heapify() 这个操作。
那具体是怎么做的呢?
哈哈源码已经暴露了:
从最后一个非叶子节点开始,从后往前做 siftDown().
因为叶子节点没必要操作嘛,已经到了最下面了,还能和谁 swap?
举个例子:
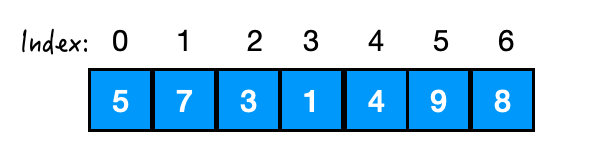
我们想把这个数组进行 heapify() 操作,想把它变成一个最小堆,拿到它的最小值。
那就要从 3 开始,对 3,7,5进行 siftDown().
Step 1.
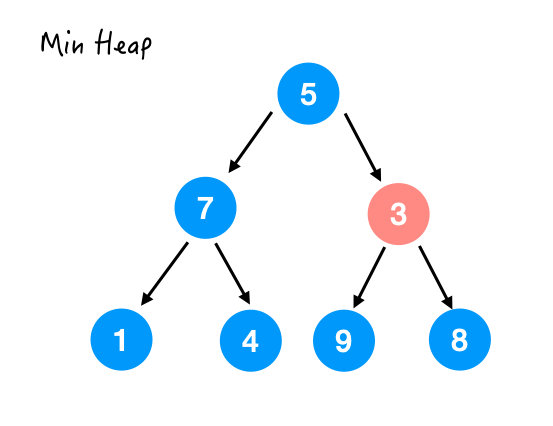
尴尬 ,3 并不用交换,因为以它为顶点的这棵小树已经满足了堆序性。
Step 2.

7 比它的两个孩子都要大,所以和较小的那个交换一下。
交换完成后;
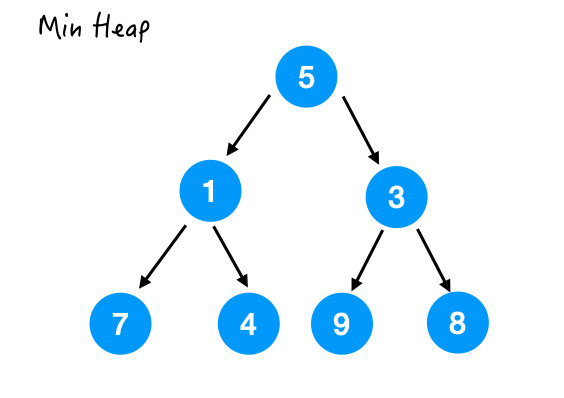
Step 3.
最后一个要处理的就是 5 了,那这里 5 比它的两个孩子都要大,所以也和较小的那个交换一下。
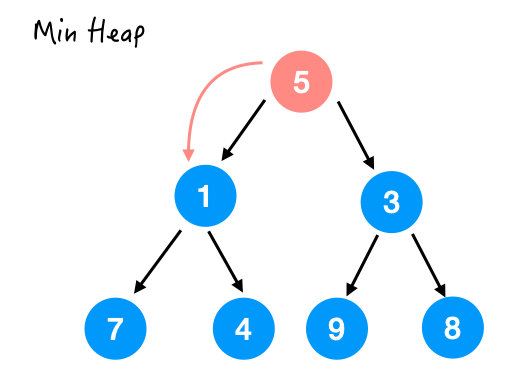
换完之后结果如下,注意并没有满足堆序性,因为 4 还比 5 小呢。
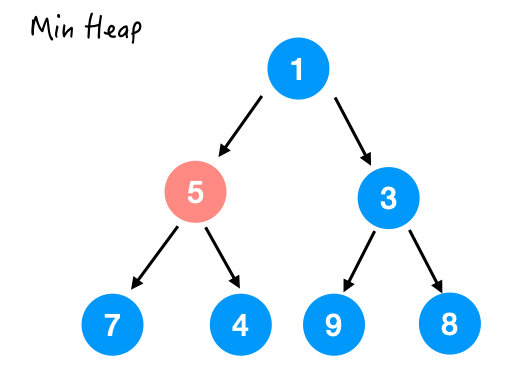
所以接着和 4 换,结果如下:
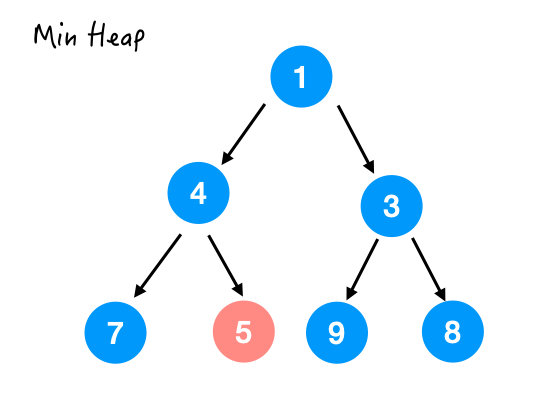
这样整个 heapify() 的过程就完成了。
好了难点来了,为什么时间复杂度是 O(n) 的呢?
怎么计算这个时间复杂度呢?
其实我们在这个过程里做的操作无非就是交换交换。
那到底交换了多少次呢?
没错,交换了多少次,时间复杂度就是多少。
那我们可以看出来,其实同一层的节点最多交换的次数都是相同的。
那么这个总的交换次数 = 每层的节点数 * 每个节点最多交换的次数
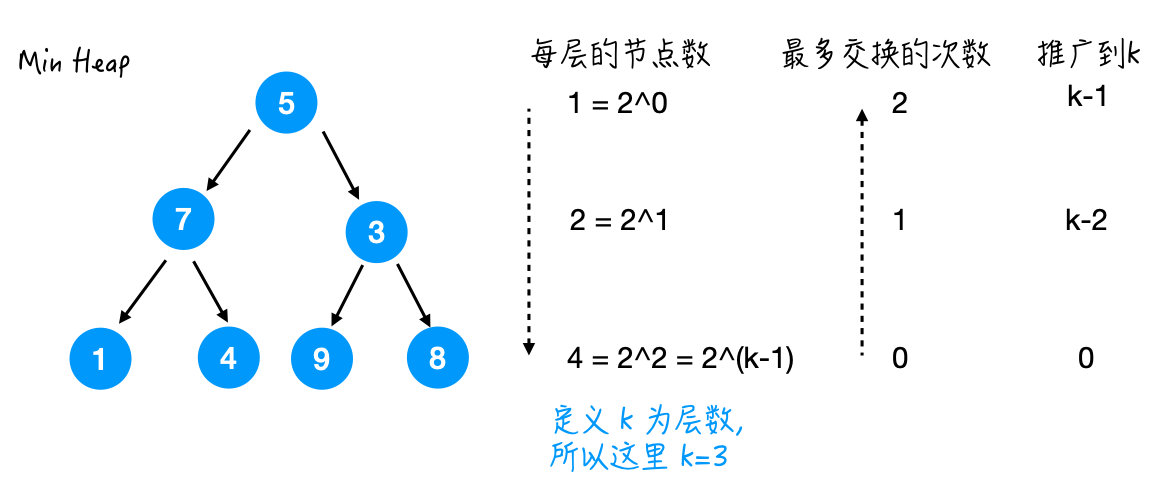
这里设 k 为层数,那么这个例子里 k=3.
每层的节点数是从上到下以指数增长:
$$\ce{1, 2, 4, ..., 2^{k-1}}$$
每个节点交换的次数,
从下往上就是:
$$ 0, 1, ..., k-2, k-1 $$
那么总的交换次数 S(k) 就是两者相乘再相加:
$$S(k) = \left(2^{0} *(k-1) + 2^{1} *(k-2) + ... + 2^{k-2} *1 \right)$$
这是一个等比等差数列,标准的求和方式就是错位相减法。
那么
$$2S(k) = \left(2^{1} *(k-1) + 2^{2} *(k-2) + ... + 2^{k-1} *1 \right)$$
两者相减得:
$$S(k) = \left(-2^{0} *(k-1) + 2^{1} + 2^{2} + ... + 2^{k-2} + 2^{k-1} \right)$$
化简一下:
(不好意思我实在受不了这个编辑器了。。。
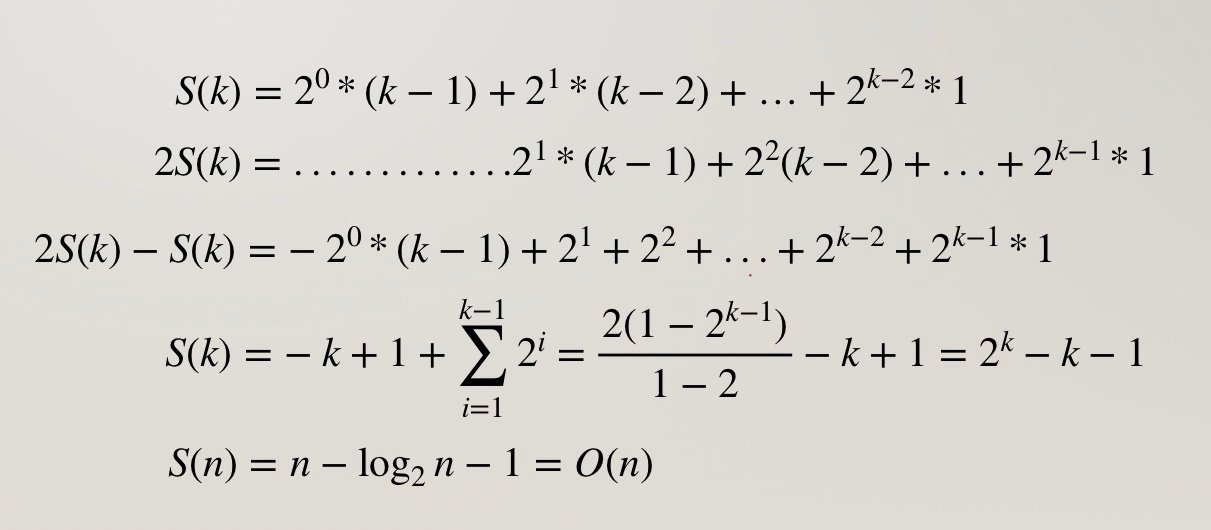
所以 heapify() 时间复杂度是 O(n).
以上就是堆的三大重要操作,最后一个 heapify() 虽然不能直接操作,但是堆排序中用到了这种思路,之前的「选择排序」那篇文章里也提到了一些,感兴趣的同学可以后台回复「选择排序」获得文章~至于堆排序的具体实现和应用,以及为什么实际生产中并不爱用它,我们之后再讲。
如果你喜欢这篇文章,记得给我点赞留言哦~你们的支持和认可,就是我创作的最大动力,我们下篇文章见!
我是小齐,纽约程序媛,终生学习者,每天晚上 9 点,云自习室里不见不散!
更多干货文章见我的 Github: https://github.com/xiaoqi6666/NYCSDE
为什么堆化 heapify() 只用 O(n) 就做到了?的更多相关文章
- lintcode: 堆化
堆化 给出一个整数数组,堆化操作就是把它变成一个最小堆数组. 对于堆数组A,A[0]是堆的根,并对于每个A[i],A [i * 2 + 1]是A[i]的左儿子并且A[i * 2 + 2]是A[i]的右 ...
- Java实现的二叉堆以及堆排序详解
一.前言 二叉堆是一个特殊的堆,其本质是一棵完全二叉树,可用数组来存储数据,如果根节点在数组的下标位置为1,那么当前节点n的左子节点为2n,有子节点在数组中的下标位置为2n+1.二叉堆类型分为最大堆( ...
- Java并发包源码学习系列:阻塞队列实现之PriorityBlockingQueue源码解析
目录 PriorityBlockingQueue概述 类图结构及重要字段 什么是二叉堆 堆的基本操作 向上调整void up(int u) 向下调整void down(int u) 构造器 扩容方法t ...
- Java数据结构和算法(五)二叉排序树(BST)
Java数据结构和算法(五)二叉排序树(BST) 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 二叉排序树(Binary S ...
- Java同步数据结构之PriorityBlockingQueue
前言 接下来继续BlockingQueue的另一个实现,优先级阻塞队列PriorityBlockingQueue.PriorityBlockingQueue是一个无限容量的阻塞队列,由于容量是无限的所 ...
- 两种建立堆的方法HeapInsert & Heapify
参考 堆排序中两种建堆方法的比较 第一种方法HeapInsert 它可以假定我们事先不知道有多少个元素,通过不断往堆里面插入元素进行调整来构建堆. 它的大致步骤如下: 首先增加堆的长度,在最末尾的地方 ...
- 索引堆(Index Heap)
首先我们先来看一个由普通数组构建的普通堆. 然后我们通过前面的方法对它进行堆化(heapify),将其构建为最大堆. 结果是这样的: 对于我们所关心的这个数组而言,数组中的元素位置发生了改变.正是因为 ...
- lintcode-130-堆化
130-堆化 给出一个整数数组,堆化操作就是把它变成一个最小堆数组. 对于堆数组A,A[0]是堆的根,并对于每个A[i],A [i * 2 + 1]是A[i]的左儿子并且A[i * 2 + 2]是A[ ...
- 数据结构中的堆(Heap)
堆排序总结 这是排序,不是查找!!!查找去找二叉排序树等. 满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树. 构建顶堆: a.构造初始堆 b.从最后一层非叶节点开始调整,一直到根节点 c.如果 ...
随机推荐
- Windows docker镜像文件无法删除
最近刚开始玩docker,下载镜像之前没有修改docker的保存路径,因此默认存在了c:\programdata下面,导致C盘空间不足. 之后修改了保存路径之后( docker engin里加&quo ...
- python操作从数据库中获取数据的接口
1.输入一个表名,获取表里面的数据 2.判断用户是否存在,如果不存在就添加到数据库里面
- Java成神之路:第三帖----数据结构与算法之队列
数据结构与算法--队列 今天掉了两根头发,摸掉的,记得 别乱摸,很珍贵的!! 什么是队列? 1)队列是一个有序列表,可以用数组或是链表来实现 2)遵循 先入先出 的原则.即:先存入队列的数据,要先取出 ...
- springboot:This application has no explicit mapping for /erro
springboot启动没有报错,但是访问的时候返回如上图的错误.看报错内容感觉是没有这个mapping对应的接口.但是确实写了. 最终发现是因为springboot的启动类放的位置不对.启动类所在的 ...
- Codeforces1146G. Zoning Restrictions
Description You are planning to build housing on a street. There are n spots available on the street ...
- macOS提示“将对您的电脑造成伤害……“进阶版
> 很多小伙伴在更新完系统后运行应用会闪退以及提示"xxxx 将对您的电脑造成伤害. 您应该将它移到废纸篓",本文将针对此问题提供解决方法.如图:
class Solution: def findKthLargest(self, nums: List[int], k: int) -> int: """堆排序思想 ...
- Cypress系列(60)- 运行时的截图和录屏
如果想从头学起Cypress,可以看下面的系列文章哦 https://www.cnblogs.com/poloyy/category/1768839.html 背景 在测试运行时截图和录屏能够在测试错 ...
- 记录jmeter使用beanshell断言获取复杂的json字符串参数值
实战示例 测试场景 电商系统经常会涉及到商品的库存数量的压测,在用户下单前需要先做库存余量的判断,当余量不足时用户无法下单,保证商品的有效售卖 库存余量查询响应结果 响应结果一般是json字符串的形式 ...