Python基础及爬虫入门
**写在前面**
我们在学习任何一门技术的时候,往往都会看很多技术博客,很多程序员也会写自己的技术博客。但是我想写的这些不是纯技术博客,我暂时也没有这个能力写出 Python 或者爬虫相关的技术博客来。我只是作为一个初学 Python 和爬虫的产品,把我学习的过程和心得记录下来,供大家参考。
我会给到我在学习过程中参考的技术博客链接,在此也对他们的无私奉献表示感谢。
我创了一个 python交流群,有感兴趣的小伙伴也可以加我的扣扣群867零67久45,群里有专门的老师跟资料可以提供给小伙伴们学习python,晚上8点也有老师直播教小伙伴们怎么学习python,欢迎大家加入python这个大家庭。
**Python 基础
先来点开胃菜**
可能对于很多人来说, Python 最大的特点就是“简短”。那么用Python 写程序到底有多短呢?举个栗子~
我有两个室友,一个前端,一个后台。他们分别用 JavaScript 和 C# 实现下面这个功能,需要多少行代码呢?
输出 (0:100)之间的,【1X1, 2X2 ··· 100X100】中 2 的倍数
JavaScript 用了10行,C# 用了5行 (当然,这也跟他们当时的技术水平有关。一般来说,用任何语言实现这个功能应该都不需要10行代码)
那么用 Python 呢?只需要一行

Python 代码简短明确,相对来说比较好入门,适合在课余和工作之余 的时间去学习,所以大家不用担心自己没有时间。
PS. 我无意比较各语言的好坏,我知道 C、C++ 的运行效率比 Python 高很多,我也相信有大牛能够通过其他语言只用一行代码来实现。在此只是简述 Python 简短易入门。
**Python 版本**
如果你有百度过 Python,那么你应该知道,Python 目前有两个主要的版本: Python 2.7.X 和 Python 3.3.X,而且这两者是不完全兼容的。
目前来说,Python 2.X 的教程和库更多,更好学。但 Python 3.X 更先进,而且解决了 Python 2.X 在使用中文的时候容易出现的编码错误问题。
这里不评价哪个版本更好,但是我目前用的是 Python 2.7,因此这里所说的所有博客、教程、语法和库···都是基于 Python 2.7
**开始学习吧**
我在学习 Python 基础的时候主要参考了 Python 教程 ,他的博客通俗易懂,在“技术博客界”也比较出名。
但是这个教程几乎涵盖了 Python 的所有知识教程,如果只是需要用 Python 写一个爬虫或者其他小脚本的话,实际上是不需要全部看完的(当然如果你愿意也可以)。如果你有其他语言的基础,那么可以只看个大概,了解一些基本的语法和特性就行了;如果你没有其他语言的基础,甚至对编程一窍不通,那么建议你多学习一些,最好看到“错误、调试和测试”那一章,并且一定要把其中每一篇的示例代码放到自己的编译器里跑一遍(不要复制,自己敲),这样才能理解其中的一些原理。
我大学的专业是软件工程,因此有一定的 C++ 基础。我大概只看到“高级特性”那一章,然后就开始学习爬虫了。
我创了一个 python交流群,有感兴趣的小伙伴也可以加我的扣扣群867零67久45,群里有专门的老师跟资料可以提供给小伙伴们学习python,晚上8点也有老师直播教小伙伴们怎么学习python,欢迎大家加入python这个大家庭。
**爬虫入门**
网络爬虫(又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。——百度百科
**网页知识简介**
一般来说,爬虫获取的是网页上的内容。我们通过浏览器上网时,首先会对该网站的服务器发送一个访问请求,服务器收到请求后,把我们需要的数据传回来给到浏览器,然后浏览器解析数据并展现给我们。
而这些数据在被浏览器解析之前,其实就是一些代码。我们在浏览器页面按一下F12,就能看到该网址的源代码。
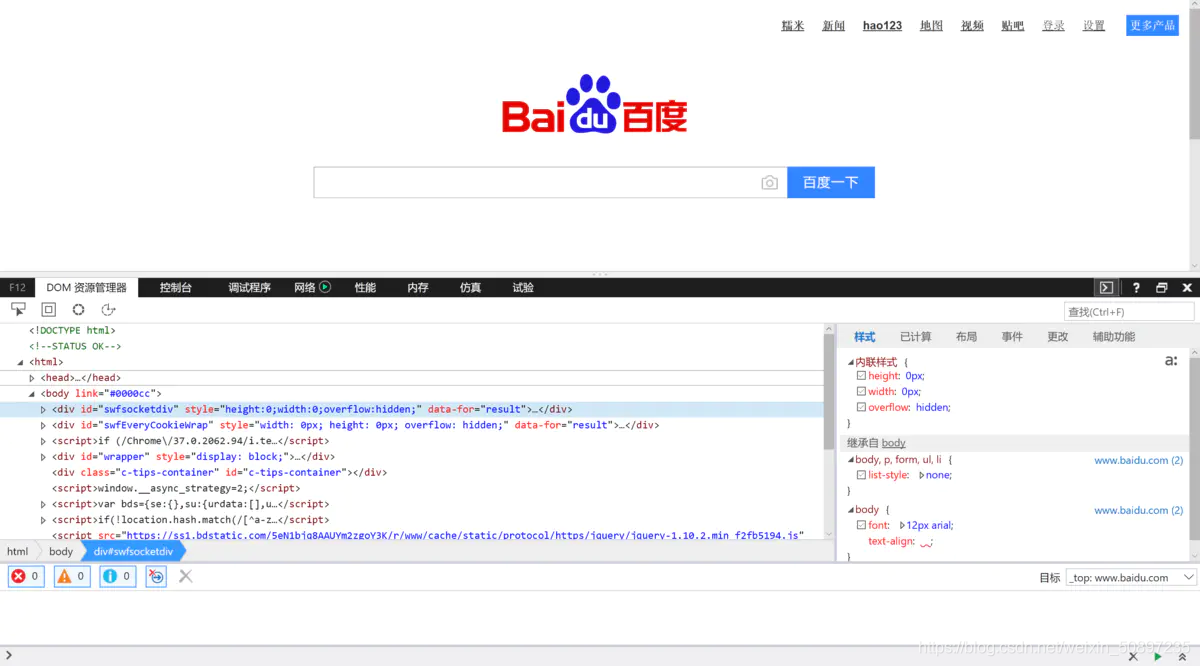
**爬虫原理简介**
如果没有前端基础,那么我们可能完全看不懂这些源代码。但是,我们通过浏览器看到的文字、图片等信息,其实也包含在源代码里。
比如这个页面的部分文字和图片:
其中包含文字和图片的代码是这样的

也就是说,只要我们爬到了网页的源代码,那么这个网页展示出来的(甚至隐藏掉的)所有信息,我们只要从源码中筛选就能够获取。
所以一般爬虫的原理其实非常简单:
爬取源码
筛选信息
如何获取源代码
我们访问网页一般都是通过浏览器,而浏览器其实也就是一个程序而已。相应的,爬虫其实也是一个程序。
因此爬虫程序(脚本)其实就是把自己伪装成一个浏览器,然后跟浏览器一样向目标网页的服务器发送访问请求,只要骗过了服务器,那么服务器就会把源码返回给你,这样你就获得该网页的源代码了。
PS. 上面指的网页都是静态网页,不包括动态内容;源代码也只是 HTML 代码,不包括 JS 代码。爬取动态内容要更为复杂一些
API
如果你是一个互联网从业者,那么应该听过 API 这个词。
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。——百度百科
简单来说,你可以把 API 当做一个管道接口,当你连接上这个管道接口后,你就能从中获取一些数据信息(当然,你能获取哪些信息是它说了算)。
很多企业都会对外开放一些 API 接口,通过这些接口,我们能更为快速、高效、便捷地获取天气、航班、股市等信息。(不只是这些公共信息,其实像 QQ、微博、facebook 等都会开放一些 API 接口,这样能让公司的业务更好地渗透到市场中去,也利于业务之间的合作)
显然,我们也可以通过爬虫程序来连接这些 API 接口,以此来获取数据信息。
开始学习吧
我在学习爬虫的过程中主要参考的是Python爬虫学习系列教程 ,他主要分了4个学习阶段。按照这个教程一步一步的实践,很快你就能收获一些成果了。
我创了一个 python交流群,有感兴趣的小伙伴也可以加我的扣扣群867零67久45,群里有专门的老师跟资料可以提供给小伙伴们学习python,晚上8点也有老师直播教小伙伴们怎么学习python,欢迎大家加入python这个大家庭。
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
Python基础及爬虫入门的更多相关文章
- 入门python有什么好的书籍推荐?纯干货推荐,你值得一看 python基础,爬虫,数据分析
Python入门书籍不用看太多,看一本就够.重要的是你要学习Python的哪个方向,或者说你对什么方向感兴趣,因为Python这门语言的应用领域比较广泛,比如说可以用来做数据分析.机器学习,也可以用来 ...
- Python爬虫从入门到进阶(1)之Python概述及爬虫入门
一.Python 概述 1.计算机语言概述 (1).语言:交流的工具,沟通的媒介 (2).计算机语言:人跟计算机交流的工具 (3).Python是计算机语言的一种 2.Python编程语言 代码:人类 ...
- Python 基础:分分钟入门
Python和Pythonic Python是一门计算机语言(这不是废话么),简单易学,上手容易,深入有一定困难.为了逼格,还是给你们堆一些名词吧:动态语言.解释型.网络爬虫.数据处理.机器学习.We ...
- scrapy基础 之 爬虫入门:先用urllib2来理解爬虫
1,概念理解 爬虫:抓取和保存网页信息,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片文字等资源的获取. URL:即统一资源定位符 ...
- Python基础之爬虫(持续更新中)
python通过urllib.request.urlopen("https://www.baidu.com")访问网页 实战,去网站上下载一只猫的图片 import urllib. ...
- python简单页面爬虫入门 BeautifulSoup实现
本文可快速搭建爬虫环境,并实现简单页面解析 1.安装 python 下载地址:https://www.python.org/downloads/ 选择对应版本,常用版本有2.7.3.4 安装后,将安装 ...
- python基础===【爬虫】爬虫糗事百科首页图片代码
import requests import re import urllib.request def getHtml(url): page = requests.get(url) html = pa ...
- python基础之1--Python入门
第1章 Python生态圈 第2章 编程与编程语言 python是一门编程语言,作为学习python的开始,需要事先搞明白:编程的目的是什么?什么是编程语言?什么是编程? 2.1 编程的目的: 计算机 ...
- Python 基础 4-1 字典入门
引言 字典 是Python 内置的一种数据结构,它便于语义化表达一些结构数据,字典是开发中常用的一种数据结构 字典介绍 字典使用花括号 {} 或 dict 来创建,字典是可以嵌套使用的 字典是成对出现 ...
随机推荐
- matlab数据插值
由图可见采样点前段比较稀疏,比较有规律,后段比较密集,比较复杂 这里的spline是三次样条插值 随着次数的增高,曲线在两端震荡的越来越剧烈 用上其他插值的方法 线性插值 最近点插值 分段三次米勒插值 ...
- 关于python中break与continue的区别
在python中break和continue都有跳出循环体的作用,但是他们还是有一些区别的,具体区别如下: break:是直接跳出循环,跳出自己所处的整个循环体 continue:只是跳出本次循环,而 ...
- 刷题[CISCN2019 华北赛区 Day2 Web1]Hack World
解题思路 打开发现是很简单的页面,告诉了表名和列名,只需知道字段即可 尝试一下,输入1,2都有内容,后面无内容.输入1'让他报错,发现返回bool(false) 大概思路就是布尔型注入了,通过不断返回 ...
- eureka源码--服务的注册、服务续约、服务发现、服务下线、服务剔除、定时任务以及自定义注册中心的思路
微服务注册后,在注册中心的注册表结构是一个map: ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>& ...
- 走进shiro,构建安全的应用程序---shiro修仙序章
0. 写在前面 在最近的一个项目当中,我们基于Shiro实现我们系统的认证和授权.借此机会,写几篇博客,总结一下在本次实践当中遇到的问题,和较全面地学习一下Shiro的知识点, 1. 权限管理 权限管 ...
- sqli-labs第三关 详解
通过第二关,来到第三关 我们用了前两种方法,都报错,然后自己也不太会别的注入,然后莫名的小知识又增加了.这居然是一个带括号的字符型注入, 这里我们需要闭合前面的括号. $sql=select * fr ...
- 024 01 Android 零基础入门 01 Java基础语法 03 Java运算符 04 关系运算符
024 01 Android 零基础入门 01 Java基础语法 03 Java运算符 04 关系运算符 本文知识点:Java中的关系运算符 关系运算符
- C++实现串口通信问题(与Arduino)
参考1(已验证稍加修改可与Arduino通信):https://blog.csdn.net/qq_36106219/article/details/81701368 参考2(比较全,main函数需要自 ...
- #ifndef, #define, #endif三者的作用
#ifndef, #define, #endif 作用 #ifndef 它是if not define 的简写,是宏定义的一种,实际上确切的说,这应该是预处理功能三种(宏定义.文件包含.条件编译) ...
- Trie树【字典树】浅谈
最近随洛谷日报看了一下Trie树,来写一篇学习笔记. Trie树:支持字符串前缀查询等(目前我就学了这些qwq) 一般题型就是给定一个模式串,几个文本串,询问能够匹配前缀的文本串数量. 首先,来定义下 ...