《Connecting the Dots: A Knowledgeable Path Generator for Commonsense Question Answering》一文的理解和总结
构建常识问答知识路径生成器
论文贡献
提出学习一个多跳知识路径产生器来根据问题动态产生结构化证据。生成器以预先训练的语言模型为主干,利用语言模型中存储的大量非结构化知识来补充知识库的不完整性。路径生成器生成的这些相关路径被进一步聚合为知识嵌入,并与文本编码器给出的上下文嵌入进行融合。
论文架构
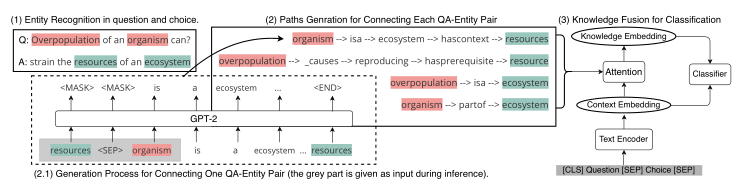
从问题和答案选择中提取实体
使用构造的路径生成器生成一个多跳知识路径来连接每对问答实体
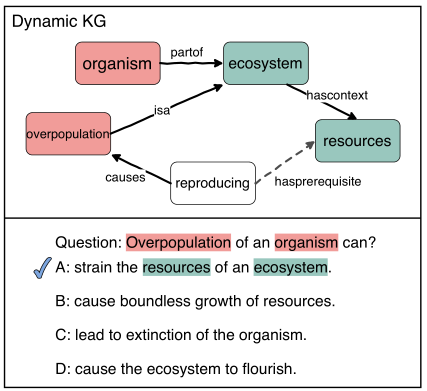
生成器学习将问题实体(红色)和选择实体(绿色)与生成的路径连接起来,这些路径充当QA的动态KG。
将生成的路径聚合为一个知识嵌入,并将其与文本编码器中的上下文嵌入相融合以进行分类。
识别实体
从问题选项对中识别出问题中出现的实体和选项中出现的实体
- 字符串匹配(论文中实际使用的方法)
- NER(命名实体识别)
知识路径采样
使用随机游走从一个常识KG中抽取符号路径,为GPT-2知识路径生成器采样具有代表性的关系路径作为训练的原始数据。
提高路径质量
假设使用Random Walk采样的这些样本路径包含和常识问答任务相关的知识,为了保证这些采样路径的质量,制定了两种启发式策略:
保证相关性——定义了一个可能对回答常识问题有帮助的关系类型的子集。例如 {atlocation,isa}。在进行采样之前,丢弃一些被认为是帮助不大甚至无用处的关系类型,这些关系对于回答问题没什么帮助,这些关系包括:relatedto(相关)、synonym(同义)、antonym(反义)、derived-from(派生自)、formof(一种..形式)、etymologicallyderivedfrom(词源派生自) 和 etymologicallyrelatedto(词源相关)。
保证信息性——要求采样的路径不包含具有重复关系类型的边,即路径上每条边的关系都是唯一的。
局部采样(帮助生成器生成适用于任务的路径)
- \(E\) 为实体集,\(R\)为关系集,\(E\) 由问题实体和选项实体组成,\(R\) 为定义的关系集合关系。以此给出静态的知识图(KG),\(G=(E,R)\)
- 随机游走是从任务训练集中的问题和答案选择中出现的实体开始的。随机游走算法进行图 \(G\) 上的路径采样,采样的路径形式为\(({e_{0},r_{0},e_{1},r_{1},\cdots ,r_{T-1},e_{T}})\),其中\(e_{T} \epsilon E\),\(r_{T} \epsilon R\),\(T\) 为路径跳数
全局采样(防止生成器偏向生成KG的局部结构的路径)
从静态KG中随机采样一些实体,并从它们开始进行随机游走,得到一些局部KG以外的路径用于生成器的泛化。
此外,还为每个关系添加了一个反向关系,这样采样的路径中不光有正向的路径和有反向的路径,这将使得路径生成器更加灵活地连接两个实体。
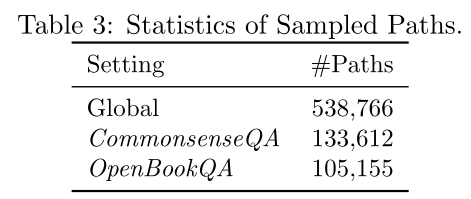
除此之外,还对具有混合跳数的路径进行采样,以训练生成器在需要事用可变长的路径来连接实体。对跳数从1到3的路径进行采样,以构造具有混合跳数的路径集。从特定任务数据集的全局采样和局部采样中获得的路径数如下表所示。将这两种抽样策略的路径合并,并进一步将其分成训练/开发/测试集,其比率为9:0.5:0.5。
基于GPT-2的路径生成器构建
在随机游走采样的那些路径上对GPT-2进行微调。
GPT-2是一种预训练的大容量语言模型,它从庞大的语料库中编码出丰富的非结构化知识。用它来作为路径生成器带来的好处是双重的。
- 微调时使用到的结构化知识路径帮助丰富GPT-2,使得它学到按照设计生成具有“常识”风格路径的能力。
- GPT-2从庞大的语料库中编码出的非结构化知识可以缓解KG的稀疏性问题。
采样的路径转化为文本化输入
GPT-2 使用字节对编码(Byte Pair Encoding)方式来创建词汇表中的词(token),也就是说词(token)其实通常只是单词的一部分。使用GPT2的字节对编码(Byte-Pair Encoding)方法将上一步直接对知识图进行随机游走采样得到的符号路径转换成GPT-2输入的文本形式:\({x}=\left\{X_{0}, Y_{0}, X_{1}, Y_{1}, \ldots, Y_{T-1}, X_{T}\right\}\)
其中,\(X_{t}=\left\{x_{t}^{0}, x_{t}^{1}, \ldots, x_{t}^{\left|e_{t}\right|}\right\}\) 是实体 \(e_{t}\) 的短语token,而\(Y_{t}=\left\{y_{t}^{0}, y_{t}^{1}, \ldots, y_{t}^{\left|r_{t}\right|}\right\}\)是关系 \(r_{t}\) 的短语token。
这样生成的文本形式的路径,方可在GPT-2中作为输入。
字节对编码方法
BPE最早是一种数据压缩算法,于2015年被引入到机器翻译领域并很快得到推广。该算法简单有效,因而目前它是最流行的子词表构建方法。GPT-2和RoBERTa使用的Subword算法都是BPE。
BPE获得Subword的步骤如下:
- 准备足够大的训练语料,并确定期望的Subword词表大小;
- 将单词拆分为成最小单元。比如英文中26个字母加上各种符号,这些作为初始词表;
- 在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的Subword单元;
- 重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1.
例子:
假设有语料集经过统计后表示为{'l o w ': 5, 'l o w e r ': 2, 'n e w e s t ': 6, 'w i d e s t ': 3},其中数字代表的是对应单词在语料中的频数。其中为终止符,用于区分单词的边界。
step 1, 最高频连续字节对"e"和"s"出现了6+3=9次,合并成"es"。输出:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w es t </w>': 6, 'w i d es t </w>': 3}
step 2, 最高频连续字节对"es"和"t"出现了6+3=9次, 合并成"est"。输出:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w est </w>': 6, 'w i d est </w>': 3}
step 3, 以此类推,最高频连续字节对为"est"和"" 输出:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w est</w>': 6, 'w i d est</w>': 3}
……
step n, 继续迭代直到达到预设的subword词表大小或下一个最高频的字节对出现频率为1。
编码和解码
- 编码
在之前的算法中,已经得到了subword的词表,对该词表按照子词长度由大到小排序。编码时,对于每个单词,遍历排好序的子词词表寻找是否有token是当前单词的子字符串,如果有,则该token是表示单词的tokens之一。
从最长的token迭代到最短的token,尝试将每个单词中的子字符串替换为token。 最终,我们将迭代所有tokens,并将所有子字符串替换为tokens。 如果仍然有子字符串没被替换但所有token都已迭代完毕,则将剩余的子词替换为特殊token,如。
例子
# 给定单词序列
[“the</w>”, “highest</w>”, “mountain</w>”]
# 假设已有排好序的subword词表
[“errrr</w>”, “tain</w>”, “moun”, “est</w>”, “high”, “the</w>”, “a</w>”]
# 迭代结果
"the</w>" -> ["the</w>"]
"highest</w>" -> ["high", "est</w>"]
"mountain</w>" -> ["moun", "tain</w>"]
- 解码
将所有的tokens拼在一起,以\(</w>\)为界定符。
例子:
# 编码序列
[“the</w>”, “high”, “est</w>”, “moun”, “tain</w>”]
# 解码序列
“the</w> highest</w> mountain</w>”
通过BPE编码和解码,为采样的路径构造出适合GPT-2的输入的文本格式。
GPT-2生成器输入构造
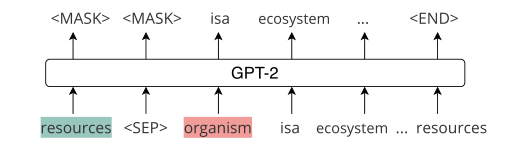
为了进一步模拟生成器提供一个问题实体和一个选择实体的场景,在每个路径的开始处添加最后一个实体短语标记 \(x_{T}\) 和一个单独的标记[SEP]。这样,生成器将知道在生成路径时它应该输出的最后一个实体。

将目标实体 + [SEP]标记 + 起始实体,即灰色部分交给GPT-2生成器来生成连接这两个实体的路径。
已知前 \(t-1\) 个生成的token \(s_{<t}\),当前第t个位置生成token \(s_{t}\) 的概率为:
\(P\left(s_{t} \mid s_{<t}\right)=\operatorname{softmax}\left(\mathbf{W}_{\text {vocab}} \cdot \mathbf{h}_{\mathrm{t}}\right)\)
这里 \(h_{t}\) 表示在解码时GPT-2对 \(s_{t}\) 的最终表示, \(W_{vocab}\) 是GPT-2使用的词汇表的嵌入矩阵。
为了在给定实体对的情况下最大化生成句子 \(s\) 的概率,将损失函数定义为:
\(\mathcal{L}=-\sum_{\mathbf{s}} \log P\left(\mathbf{s} \mid X_{T},[S E P], X_{0}\right)\)
其中,\(P\left(\mathbf{s} \mid X_{T},[S E P], X_{0}\right)\) 为条件概率的乘积,另外,由于输入的 \(X_{0}\) 和 \(X_{1}\) 以及 \([SEP]\)是固定的输入,所以 \(t\) 的下标从 \(|X_{0}|+|X_{1}| + 1\) 开始。
\(P\left(\mathbf{s} \mid X_{T},[S E P], X_{0}\right)=\prod_{t=\left|X_{0}\right|+\left|X_{T}\right|+1}^{|\mathbf{s}|} P\left(s_{t} \mid s_{<t}\right)\)
文本编码器的选择和构建
本文常识问答的框架由两个主要部分组成。第一部分是前面提到的路径生成器。第二部分是一个上下文编码器,它对问题和选择进行编码,以输出一个上下文嵌入 \(c\) 作为非结构化证据。
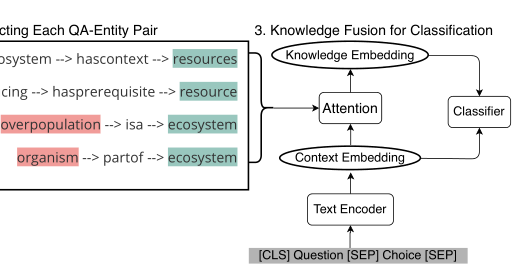
该论文实验采用的文本编码器为BERT和Robert,两种常用的文本输入上下文编码器。问题和选择通过添加一些特殊的标记串接起来,然后输入上下文编码器得到 \(c\) 。上下文嵌入 \(c\) 和路径生成器生成的路径进行Attention之后,输出一个知识嵌入 \(p\) 作为结构化证据。最后,这两类证据被输入分类器,为每个选择输出一个似然性得分。
KE(知识嵌入)模块
路径生成器GPT-2为每对问题选项生成一条最终的推理路径,对于生成的这些长度不一的离散路径,将GPT-2中最后一层隐藏状态的平均值 \(p_{k}\) 作为路径嵌入,从而最大限度地利用路径生成器。
\(\mathbf{p}_{\mathbf{k}}=\operatorname{MEAN}\left(\left\{\mathbf{h}_{\mathbf{0}}, \mathbf{h}_{\mathbf{1}}, \ldots, \mathbf{h}_{\mathbf{T}}\right\}\right)\)
由于GPT-2已经在一个大型语料库上进行了预训练,这样的表示应该足以保存路径的信息。
由于并非所有的路径都会对决定哪个选择是正确答案做出同等贡献,所以我们利用非结构化证据,即上面提到的上下文嵌入c作为编码这种结构化证据的指导。
\(\mathbf{p}=W_{p r o j} \cdot \sum_{k} \alpha_{k} \mathbf{p}_{k}\)
其中 \(W_{proj}\) 是个可学习的映射矩阵,\(\alpha_{k}\) 为每条路径嵌入的注意力权重,其计算公式如下:
\(\alpha_{k}=\frac{\exp \left(s_{k}\right)}{\sum_{k^{\prime}} \exp \left(s_{k^{\prime}}\right)}\)
其中,\(s_{k}\) 的计算公式如下,注意力网络由 \(W_{att}\) 和 \(b_{att}\) 参数化
\(s_{k}=\mathbf{c}^{\top} \tanh \left(\mathbf{W}_{a t t} \cdot \mathbf{p}_{k}+\mathbf{b}_{a t t}\right)\)
融合异质信息进行分类
分类器利用路径生成器产生的路径嵌入 \(p\) 和文本编码器产生的非结构化的问题选项的上下文嵌入 \(c\) 来计算问题选择对的似然性。
如何计算似然性?
将 \(c\) 和 \(p\) 连接起来,并将它们提供给最终的线性分类层为每个问题选项对获取一个最终得分,这里涉及一个线性变换:
\(f(q, a)=\mathbf{W}_{c l s} \cdot[\mathbf{c} ; \mathbf{p}]+\mathbf{b}_{c l s}\)
最后通过一个softmax层对得分进行标准化,得到所有选择的最终概率。
Baselines
Pre-trained LM
BERT
RoBERTa
在该论文的框架中,使用了RoBERTa最后一层隐藏状态的平均池作为上下文嵌入,并将其输入到线性分类器以获得分数。
KG
- 静态KG,例如KagNet和RGCN
- 动态KG,该论文使用到的GPT-2路径动态生成
实验结果
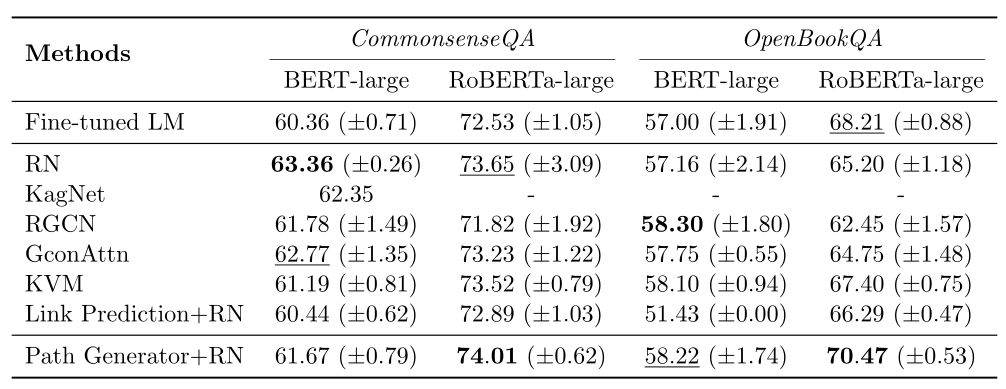
当使用RoBERTa作为上下文编码器以及上面提及的路径生成器之后,模型在CSQA的表现同baseline相比是最好的,但是当使用BERT作为上下文编码器时,表现并没有优于所有使用静态KG的模型。这是方法的局限性,在某种程度上仍然依赖上下文编码器来聚合具有注意机制的路径。如何设计一个与文本模块耦合较少的路径生成器是今后的工作。
总结
该论文提出了一种生成多跳知识路径的生成器,作为回答常识问题的结构化证据。为了学习这样一个路径生成器,微调了GPT-2,从一个常识KG中随机抽取样本。然后生成器将每对问答实体用一条知识路径连接起来。这些路径被进一步聚合为知识嵌入,并与文本编码器给出的上下文嵌入进行融合。在两个基准数据集上的实验结果表明,该论文的框架在性能上优于强预训练语言模型和静态KG增强方法。除此之外,还证明了所生成的路径在信息性和帮助性方面是可以解释的。未来的工作包括如何将生成器与文本编码器解耦,以及如何更好地融合知识。
感谢
- BPE字节对编码方法的内容摘自文章:https://zhuanlan.zhihu.com/p/86965595
- 论文地址:《Connecting the Dots: A Knowledgeable Path Generator for Commonsense Question Answering》
《Connecting the Dots: A Knowledgeable Path Generator for Commonsense Question Answering》一文的理解和总结的更多相关文章
- d3js path generator vs layouts
我们知道d3的一般套路就是d3.selectAll('path.mypath').data(yourDataset).enter().append('path').attr('class','mypa ...
- About me --- Connecting the dots
在这个难以入眠的夜里,乔布斯年在斯坦福的演讲里说的“Connecting the dots”又萦绕耳际,即当我们往回看,就清楚了 自己曾经的生活和现在甚至将来是串联在一起的,这些经历决定了我们事业.生 ...
- core graphics path
当UIKit无法满足画图需求的时候.就须要用到Core Graphics API.当中最普遍的就是path. 一些重要的概念 graphics context 能够理解成canvas.在ios里相应C ...
- SQL SERVER中XML查询:FOR XML指定PATH
SQL SERVER中XML查询:FOR XML指定PATH 前言 在SQL SERVER中,XML查询能够指定RAW,AUTO,EXPLICIT,PATH.本文用一些实例介绍SQL SERVER中指 ...
- Callback Promise Generator Async-Await 和异常处理的演进
根据笔者的项目经验,本文讲解了从函数回调,到 es7 规范的异常处理方式.异常处理的优雅性随着规范的进步越来越高,不要害怕使用 try catch,不能回避异常处理. 我们需要一个健全的架构捕获所有同 ...
- 漫话JavaScript与异步·第三话——Generator:化异步为同步
一.Promise并非完美 我在上一话中介绍了Promise,这种模式增强了事件订阅机制,很好地解决了控制反转带来的信任问题.硬编码回调执行顺序造成的"回调金字塔"问题,无疑大大提 ...
- Generator函数语法解析
转载请注明出处: Generator函数语法解析 Generator函数是ES6提供的一种异步编程解决方案,语法与传统函数完全不同.以下会介绍一下Generator函数. 写下这篇文章的目的其实很简单 ...
- eclipse java build path问题汇总
背景:在项目开发过程中,很多应用都进行了模块划分,有的时候是jar包依赖,有的时候通过build path进行配置,搞清楚这部分有助于理解项目之间的关系. 1 tms项目开发 1.1 问题描述 项目结 ...
- path设置
查看 export declare -x HISTCONTROL="ignoredups"declare -x HISTSIZE="1000"declare - ...
随机推荐
- git如何在远程某个分支的基础上新建分支
1.任意新建文件夹,右击git bash here $ git init(将此目录变成本地仓库) 2.$ git remote add origin 'https://git............g ...
- JVM垃圾回收行为的并行与并发
程序的并行和并发 程序的并发(Concurrent) 在操作系统中,是指一个时间段中有几个程序都处于己启动运行到运行完毕之间,且这几个程序都是在同一个处理器_上运行. 并发不是真正意义上的“同时进行” ...
- 这10道springboot常见面试题你需要了解下
1.什么是Spring Boot? 多年来,随着新功能的增加,spring变得越来越复杂.只需访问https://spring.io/projects页面,我们就会看到可以在我们的应用程序中使用的 ...
- springboot maven项目运行常见报错 及ajax请求报错
如图所示 tomcat运行后直接停止,也不报错 原因:我的原因是controller路径配置重名或者service没有配置@Service 遇见这错找了好久问题,网上也搜不到,特此记录一下 问题2 a ...
- 详细分析 Java 中实现多线程的方法有几种?(从本质上出发)
详细分析 Java 中实现多线程的方法有几种?(从本质上出发) 正确的说法(从本质上出发) 实现多线程的官方正确方法: 2 种. Oracle 官网的文档说明 方法小结 方法一: 实现 Runnabl ...
- 如何将炫酷的报表直接截图发送邮件——在Superset 0.37使用Schedule Email功能
Superset的图表是非常炫酷的,但是原来的版本只能在web端查看,而最新的0.37版本,可以将图表截图直接发送成邮件,非常的方便. 本文将详细介绍Superset 0.37 定时邮件功能.安装过程 ...
- Paxos 协议
可用性与一致性 为了向用户提供更好的服务体验,现代软件架构越来越注重系统的可用性availability. 正是在这种趋势的驱动下,微服务与容器化技术才能在今天大行其道. 而高可用架构的前提是冗余: ...
- IDEA文本编辑区的护眼绿豆沙色配置
第一步:打开IDEA -> File -> settings -> Editor -> Color Scheme -> General 第二步:找到右方Text -> ...
- [iTyran原创]iPhone中OpenGL ES显示3DS MAX模型之二:lib3ds加载模型
[iTyran原创]iPhone中OpenGL ES显示3DS MAX模型之二:lib3ds加载模型 作者:u0u0 - iTyran 在上一节中,我们分析了OBJ格式.OBJ格式优点是文本形式,可读 ...
- 查杀进程小工具——WPF和MVVM初体验
最近因为工作需要,研究了一下桌面应用程序.在winform.WPF.Electron等几种技术里,最终选择了WPF作为最后的选型.WPF最吸引我的地方,就是MVVM模式了.MVVM模式完全把界面和业务 ...