python基础--14大内置模块(上)
python的内置模块(重点掌握以下模块)
什么是模块
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
(1)random模块
import random
# 此模块提供了和随机数获取相关的方法,这是一个伪随机数
# random.random():获取(0.0,1.0)范围内的浮点数
# a = random.random()
# print(a) # 0.20995790068871445
# print(random.random()) # 0.5998669738158883
# random.randint(a,b):获取这个[a,b]区间的一个随机整数
# c = random.randint(3,5)
# print(c) # 4
# random.uniform(a,b):获取[a,b)范围内的浮点数
# b = random.uniform(3,5) # 3.0224368251871145
# print(b) # 3.0224368251871145
# random.shuffle(x):把参数指定的数据中的元素打乱。混洗。参数是一个可变的数据类型
# lst = [i for i in range(10)]
# random.shuffle(lst)
# print(lst) # [0, 1, 5, 4, 9, 2, 3, 8, 6, 7]
# random.sample(x,k):从x中随机抽取k个数据,组成一个列表返回。
# lst1 = random.sample(lst, 4)
# print(lst1) # [6, 1, 3, 5]
# 随机选择一个返回
# random.choice([1,'23',[4,5]]) # #1或者23或者[4,5]
>>> import random
#随机小数
>>> random.random() # 大于0且小于1之间的小数
0.7664338663654585
>>> random.uniform(1,3) #大于1小于3的小数
1.6270147180533838#恒富:发红包
#随机整数
>>> random.randint(1,5) # 大于等于1且小于等于5之间的整数
>>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数
#随机选择一个返回
>>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5]
#随机选择多个返回,返回的个数为函数的第二个参数
>>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合
[[4, 5], '23']
#打乱列表顺序
>>> item=[1,3,5,7,9]
>>> random.shuffle(item) # 打乱次序
>>> item
[5, 1, 3, 7, 9]
>>> random.shuffle(item)
>>> item
[5, 9, 7, 1, 3]
练习:生成随机验证码
import random
def v_code():
code = ''
for i in range(5):
num=random.randint(0,9)
alf=chr(random.randint(65,90))
add=random.choice([num,alf])
code="".join(code,str(add))
return code
print(v_code()) # GO3W8
(2)time模块
和时间有关系的我们就要用到时间模块。在使用模块之前,应该首先导入这个模块。
#常用方法
1.time.sleep(secs)
(线程)推迟指定的时间运行。单位为秒。
2.time.time()
获取当前时间戳
表示时间的三种方式
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String): ‘1999-12-06’
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
python中时间日期格式化符号:
(3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
'''
time模块:和时间相关
这个模块封装了获取时间戳和字符串形式的时间的一些方法
'''
import time
# 获取时间戳 print(time.time()) # 1593600077.0403051 什么是时间戳:从时间元年(1970 1 1 00:00:00)到现在经过的秒数。
# 获取格式化的时间对象:是九个字段组成的。
# 默认参数是当前系统时间的时间戳
print(time.gmtime()) # time.struct_time(tm_year=2020, tm_mon=7, tm_mday=1, tm_hour=10, tm_min=53,tm_sec=43, tm_wday=2, tm_yday=183, tm_isdst=0)
print(time.localtime()) # time.struct_time(tm_year=2020, tm_mon=7,tm_mday=1, tm_hour=18, tm_min=57, tm_sec=1, tm_wday=2, tm_yday=183, tm_isdst=0)
print(time.mktime(time.localtime())) # 1593600077.0把时间戳就保留一位小数
print(time.gmtime(1)) # 时间元年过一秒后,对应的时间对象
# time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=1, tm_wday=3, tm_yday=1, tm_isdst=0)
print(time.gmtime(time.time()))
# time.struct_time(tm_year=2020, tm_mon=7, tm_mday=2, tm_hour=11, tm_min=37, tm_sec=20, tm_wday=3, tm_yday=184, tm_isdst=0)
# 将格式化时间对象和字符串之间的转换。
#时间字符串
time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04'
# 将字符串转和格式化时间对象之间的转换。
# 格式化时间 ----> 结构化时间
ft = time.strftime('%Y/%m/%d %H:%M:%S')
st = time.strptime(ft,'%Y/%m/%d %H:%M:%S')
print(st)
# 结构化时间 ---> 时间戳 mktime是将结构化时间转换为时间戳。
t = time.mktime(st)
print(t)
# 时间戳 ----> 结构化时间
t = time.time()
st = time.localtime(t)
print(st)
# 结构化时间 ---> 格式化时间
ft = time.strftime('%Y/%m/%d %H:%M:%S',st)
print(ft)
首先,我们先导入time模块,来认识一下python中表示时间的几种格式:
#导入时间模块
>>>import time
#时间戳
>>>time.time()
1500875844.800804
#时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04'
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24,
tm_hour=13, tm_min=59, tm_sec=37,
tm_wday=0, tm_yday=205, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种格式之间的转换
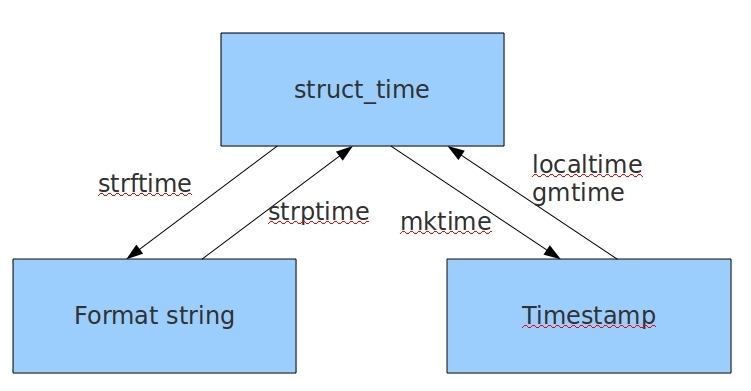
# 格式化时间 ----> 结构化时间
ft = time.strftime('%Y/%m/%d %H:%M:%S')
st = time.strptime(ft,'%Y/%m/%d %H:%M:%S')
print(st)
# 结构化时间 ---> 时间戳
t = time.mktime(st)
print(t)
# 时间戳 ----> 结构化时间
t = time.time()
st = time.localtime(t)
print(st)
# 结构化时间 ---> 格式化时间
ft = time.strftime('%Y/%m/%d %H:%M:%S',st)
print(ft)
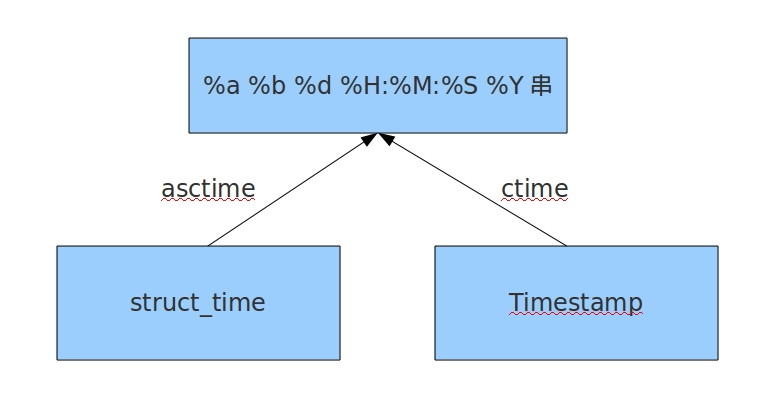
#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
>>>time.asctime(time.localtime(1500000000))
'Fri Jul 14 10:40:00 2017'
>>>time.asctime()
'Mon Jul 24 15:18:33 2017'
#时间戳 --> %a %d %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
>>>time.ctime()
'Mon Jul 24 15:19:07 2017'
>>>time.ctime(1500000000)
'Fri Jul 14 10:40:00 2017'
t = time.time()
ft = time.ctime(t)
print(ft)
st = time.localtime()
ft = time.asctime(st)
print(ft)
计算时间差:
import time
true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S'))
time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S'))
dif_time=time_now-true_time
struct_time=time.gmtime(dif_time)
print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1,
struct_time.tm_mday-1,struct_time.tm_hour,
struct_time.tm_min,struct_time.tm_sec))
计算时间差
(3)datetime模块
datetime模块:日期时间模块,可以对时间做数学计算。
datetime封装了一些和日期,时间相关的类。这些类包括date、time、datetime、timedelta等。
import datetime
# data类:(年月日)
# print(datetime.date.year)
# print(datetime.date.day)
# print(datetime.date.month)
'''
输出的结果为:
<attribute 'year' of 'datetime.date' objects>
<attribute 'day' of 'datetime.date' objects>
<attribute 'month' of 'datetime.date' objects>
'''
# a = datetime.date(2020, 7, 9) # 获取到'datetime.date' objects
# print(a) # 2020-07-09
# print(a.year) # 获取对象的属性 2020
# print(a.month) # 7
# print(a.day) # 9
# # time类:(时分秒)
# print(datetime.time.hour) # 'datetime.time' objects
# print(datetime.time.minute)
# print(datetime.time.second)
'''
<attribute 'hour' of 'datetime.time' objects>
<attribute 'minute' of 'datetime.time' objects>
<attribute 'second' of 'datetime.time' objects>
'''
# t = datetime.time(10, 48, 59)
# print(t) # 10:48:59
# print(t.hour) # 10
# print(t.minute) # 48
# print(t.second) # 59
# datetime 日期和时期的结合体
# print(datetime.datetime.year) # 'datetime.date' objects
# dt = datetime.datetime(2011, 11, 11, 11, 11, 11)
# print(dt) # 2011-11-11 11:11:11
# datetime中的类,主要是用于数学计算的。
# timedelta类:时间的变化量
td = datetime.timedelta(days=1)
# print(td) # 1 day, 0:00:00
# 参与数学运算,类型与第(另)一个操作数保持一致。
# 创建时间对象
# date,datetime,timedelta
d = datetime.date(2010, 10, 10)
res = d + td
print(res) # 2010-10-11
# 时间变化量的计算是否会产生进位,答案是会产生时间的进位。
# t = datetime.time(10, 10, 59) # unsupported operand type(s) for +: 'datetime.time' and 'datetime.timedelta'
t = datetime.datetime(2010, 10, 10, 10, 10, 59)
td = datetime.timedelta(seconds=1)
res = t + td
print(res) # 2010-10-10 10:11:00
# datatime模块
import datetime
now_time = datetime.datetime.now() # 现在的时间
# 只能调整的字段:weeks days hours minutes seconds
print(datetime.datetime.now() + datetime.timedelta(weeks=3)) # 三周后
print(datetime.datetime.now() + datetime.timedelta(weeks=-3)) # 三周前
print(datetime.datetime.now() + datetime.timedelta(days=-3)) # 三天前
print(datetime.datetime.now() + datetime.timedelta(days=3)) # 三天后
print(datetime.datetime.now() + datetime.timedelta(hours=5)) # 5小时后
print(datetime.datetime.now() + datetime.timedelta(hours=-5)) # 5小时前
print(datetime.datetime.now() + datetime.timedelta(minutes=-15)) # 15分钟前
print(datetime.datetime.now() + datetime.timedelta(minutes=15)) # 15分钟后
print(datetime.datetime.now() + datetime.timedelta(seconds=-70)) # 70秒前
print(datetime.datetime.now() + datetime.timedelta(seconds=70)) # 70秒后
current_time = datetime.datetime.now()
# 可直接调整到指定的 年 月 日 时 分 秒 等
print(current_time.replace(year=1977)) # 直接调整到1977年
print(current_time.replace(month=1)) # 直接调整到1月份
print(current_time.replace(year=1989,month=4,day=25)) # 1989-04-25 18:49:05.898601
# 将时间戳转化成时间
print(datetime.date.fromtimestamp(1232132131)) # 2009-01-17
(4)os和sys模块
os模块是与操作系统交互的一个接口
'''
os:和操作系统相关的操作被封装到这个模块中.操作系统管理的相关路径。
和操作系统相关的文件的操作
'''
import os
# 和文件操作相关,重命名,删除
# os.remove(r'a.txt')
# os.rename(r'a.txt', r'b.txt')
# 删除目录,必须是空目录
# os.removedirs(r'aa')
# 使用shutil模块可以删除带内容的目录
# import shutil
# shutil.rmtree('aa')
# 和路径相关的操作,被封装到另一个子模块中;os.path
# os.path.dirname(__file__)
# res = os.path.dirname(r'd:/aaa/bbb/ccc/a.txt')
# # 不判断路径是否存在
# print(res) # d:/aaa/bbb/ccc,取的是文件的父路径
#
# res = os.path.basename(r'd:/aaa/bbb/ccc/a.txt')
# print(res) # a.txt,取得是路径中的最后一个文件名。
#
# # 把路径中的路径名和文件名切分开,结果为是二元组
# res = os.path.split(r'd:/aaa/bbb/ccc/a.txt')
# print(res) # ('d:/aaa/bbb/ccc', 'a.txt'),相当于上面两个方法组成的元组
#
# # 拼接路径,这里的\\表示的是转义
# res = os.path.join('d:\\', 'aaa', 'bbb', 'ccc')
# print(res) # d:\aaa\bbb\ccc
#
# res = os.path.abspath(r'd:/a/b/c')
# print(res) # d:\a\b\c
# # 如果是/开头的路径,默认是在当前的盘符下。
# res = os.path.abspath(r'/a/b/c')
# # 如果没有/开头的路径,默认是当前项目的路径
# res1 = os.path.abspath(r'a/b/c')
# print(res) # D:\a\b\c
# print(res1) # D:\Program Files (x86)\DjangoProjects\basic\day16\a\b\c
#
# # 判断是否是绝对路径
# os.path.isabs()
# # 判断是否为目录
# os.path.isdir()
# # 判断是否为文件
# os.path.isfile()
# # 判断这个路径是否存在
# os.path.exists()
# # 判断是不是链接文件,相当于windows的快捷方式
# os.path.islink()
当前执行这个python文件的工作目录相关的工作路径
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')#和文件夹相关
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
# 和文件相关os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息# 和操作系统差异相关
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'# 和执行系统命令相关
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.environ 获取系统环境变量#path系列,和路径相关os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。os.path.exists(path) 如果path存在,返回True;如果path不存在,返回Falseos.path.isabs(path) 如果path是绝对路径,返回Trueos.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回Falseos.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回Falseos.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间os.path.getsize(path) 返回path的大小
sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
import sys
try:
sys.exit(1)
except SystemExit as e:
print(e)
'''
和python解释器相关的操作
'''
# 获取命令行方式运行的脚本后面的参数
import sys
# print('脚本名:' + sys.argv[0]) # 脚本本身,脚本名
# print('第一个参数:' + sys.argv[1]) # 第一个参数
# print('第二个参数:' + sys.argv[2]) # 第二个参数
# print(type(sys.argv[1])) # str
'''
输出的结果为:
脚本名:os_sys_demo.py
第一个参数:hello
第二个参数:zhouqian
'''
# 解释器寻找模块的路径,这个与解释器相关。与解释器相关的操作。
# sys.path
# 已经加载的模块
# print(sys.modules)
(5)json模块
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?
现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。
但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。
你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢?
没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串,
但是你要怎么把一个字符串转换成字典呢?
聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。
eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。
BUT!强大的函数有代价。安全性是其最大的缺点。
想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。
而使用eval就要担这个风险。
所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
序列化的目的
1、以某种存储形式使自定义对象持久化;
2、将对象从一个地方传递到另一个地方。
3、使程序更具维护性。

Json模块提供了四个功能:dumps、dump、loads、load
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json转换完的字符串类型的字典中的字符串是由""表示的
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
import json
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
import json
f = open('file','w')
json.dump({'国籍':'中国'},f)
ret = json.dumps({'国籍':'中国'})
f.write(ret+'\n')
json.dump({'国籍':'美国'},f,ensure_ascii=False)
ret = json.dumps({'国籍':'美国'},ensure_ascii=False)
f.write(ret+'\n')
f.close()
Serialize obj to a JSON formatted str.(字符串表示的json对象)
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:将数据根据keys的值进行排序。
To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
import json
data = {'username':['李华','二愣子'],'sex':'male','age':16}
json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False)
print(json_dic2)
(6)pickle模块
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) #字典
import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open('pickle_file','wb')
pickle.dump(struct_time,f)
f.close()
f = open('pickle_file','rb')
struct_time2 = pickle.load(f)
print(struct_time2.tm_year)
这时候机智的你又要说了,既然pickle如此强大,为什么还要学json呢?
这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。
如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。
但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~
所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块
但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle
(7)hashlib模块(md5加密)
'''
封装一些用于加密的类。
'''
md5加密的目的:适用于判断和验证,而并非解密。
特点:
1.把一个大的数据,切分成不同的小块,分别对不同的快进行加密,再汇总结果,和直接对整体数据加密的结果是一样的。(一致的)
2.单向加密不可逆。
3.原始数据的一小点变化,将导致加密结果有非常大的差异。'雪崩'
md5的使用方式,加密算法
import hashlib
# 获取一个加密的对象
m = hashlib.md5()
# 使用加密对象的update方法进行加密,可以累积解密多次。在上一次加密的结果上再次的加密。
m.update('abc中文'.encode('utf-8'))
m.update('def'.encode('utf-8'))
# 通过hexdigest方法或者是digest()获取加密结果
res = m.hexdigest() # 32个16进制数
# res = m.digest() # 这种方式的加密结果:b'/\x1bn)Nr\xd2Z\xe1\x96\xfeJ\xc2\xd2}\xe6'
print(res) # 1af98e0571f7a24468a85f91b908d335 再次加密的结果变为:2f1b6e294e72d25ae196fe4ac2d27de6
'''
主要用于验证,而非解密。(记住),雪崩效应
给一个数据加密,
验证:用另外一个数据的加密结果与第一次加密的结果对比。
如果结果相同,说明原文相同。
如果结果不相同,说明原文不相同。
'''
# 不同加密算法:实际上是加密结果的长度不相同。
s = hashlib.sha224()
s.update(b'abc')
print(s.hexdigest()) # 56个16进制数
# 23097d223405d8228642a477bda255b32aadbce4bda0b3f7e36c9da7
# 在创建加密对象时,可以指定参数,称作为盐(salt)
m = hashlib.md5(b'abc')
print(m.hexdigest())
m = hashlib.md5()
m.update(b'abc')
print(m.hexdigest())
# 上面两种输出的结果是一样的,结果如下所示:
# 900150983cd24fb0d6963f7d28e17f72
# 900150983cd24fb0d6963f7d28e17f72
m = hashlib.md5()
m.update(b'abc')
m.update(b'def')
print(m.hexdigest())
m = hashlib.md5()
m.update(b'abcdef')
print(m.hexdigest())
# 上面两种输出的结果是一样的,结果如下所示:
# e80b5017098950fc58aad83c8c14978e
# e80b5017098950fc58aad83c8c14978e
(8)collections模块(了解)
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
1)namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
这时,namedtuple就派上了用场:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
# namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
2)deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
3)OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
4)defaultdict
有如下值集合 [``11``,``22``,``33``,``44``,``55``,``66``,``77``,``88``,``99``,``90.``..],将所有大于 ``66` `的值保存至字典的第一个key中,将小于 ``66` `的值保存至第二个key的值中。
即: {``'k1'``: 大于``66` `, ``'k2'``: 小于``66``}
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = {}
for value in values:
if value>66:
if my_dict.has_key('k1'):
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.has_key('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value]
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
print(my_dict)
# 输出的结果为:defaultdict(<class 'list'>, {'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
5)Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba')
print c
输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
python基础--14大内置模块(上)的更多相关文章
- python基础--14大内置模块(下)
(9)正则表达式和re模块(重点模块) 在我们学习这个模块之前,我们先明确一个关系.模块和实际工作的关系. 1)模块和实际工作时间的关系 1.time模块和时间是什么关系?time模块和时间本身是没有 ...
- 十四. Python基础(14)--递归
十四. Python基础(14)--递归 1 ● 递归(recursion) 概念: recursive functions-functions that call themselves either ...
- python基础(14)-反射&类的内置函数
反射 几个反射相关的函数可参考python基础(10)-匿名函数&内置函数中2.2.4反射相关 类的一些内置函数 __str__()&__repr__() 重写__str__()函数类 ...
- Python 基础【二】 上
一.python语言分类 1. C python c语言的python版本 官方推荐 使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行 ...
- python基础===基于requests模块上的协程【trip】
今天看博客get了一个有趣的模块,叫做 trip #(pip install trip) 兼容2.7版本 基于两大依赖包:TRIP: Tornado & Requests In Pa ...
- 『无为则无心』Python基础 — 14、Python流程控制语句(while循环语句)
目录 1.什么是循环结构 2.while循环 (1)while循环的语法 (2)while循环的应用 3.while语句的死循环 4.break和continue 5.while循环嵌套 (1)应用场 ...
- Python基础学习五 内置模块
time 模块 1 >>> import time 2 >>> time.time() 3 1491064723.808669 4 >>> # t ...
- python基础——14(shelve/shutil/random/logging模块/标准流)
一.标准流 1.1.标准输入流 res = sys.stdin.read(3) 可以设置读取的字节数 print(res) res = sys.stdin.readline() print(res) ...
- python基础语法12 内置模块 json,pickle,collections,openpyxl模块
json模块 json模块: 是一个序列化模块. json: 是一个 “第三方” 的特殊数据格式. 可以将python数据类型 ----> json数据格式 ----> 字符串 ----& ...
随机推荐
- 作为一个Java开发你用过Jib吗
1. 前言 Jib是Google开发的可以直接构建 Java应用的Docker和OCI镜像的类库,以Maven和Gradle插件形式提供.它最骚操作的是可以在没有Docker守护程序的情况下构建,也就 ...
- asp.net Core依赖注入(自带的IOC容器)
今天我们主要讲讲如何使用自带IOC容器,虽然自带的功能不是那么强大,但是胜在轻量级..而且..不用引用别的库. 在新的ASP.NET Core中,大量的采用了依赖注入的方式来编写代码. 比如,在我们的 ...
- 常用的rac搭建相关
平时自己测试环境搭建用,部分参数是不规范的. 生产请按照官方文档或者公司标准化文档来做. 共享硬盘: disk.locking = "FALSE" diskLib.dataCach ...
- 深入理解React:diff 算法
目录 序言 React 的核心思想 传统 diff 算法 React diff 两个假设 三个策略 diff 具体优化 tree diff component diff element diff 小结 ...
- SCOI 2016 萌萌哒
SCOI 2016 萌萌哒 solution 有点线段树的味道,但是并不是用线段树来做,而是用到另外一个区间修改和查询的利器--ST表 我们可以将一个点拆成\(logN\)个点,分别代表从点\(i\) ...
- UVA11383 Golden Tiger Claw KM算法
题目链接:传送门 分析 这道题乍看上去没有思路,但是我们仔细一想就会发现这道题其实是一个二分图最大匹配的板子 我们可以把这道题想象成将男生和女生之间两两配对,使他们的好感度最大 我们把矩阵中的元素\( ...
- Unity音量可视化——粒子随声浪跳动
起初是看到这么一篇博客 Shader特效-- 音符跳动,效果如下图 具体的shader代码就不贴在这里了,他的博客里都有. 处理音频的关键代码如下: private int m_NumSamples ...
- Blazor带我重玩前端(三)
写在前面 需要升级VS2019以及.NET Core到最新版(具体的最低支持,我已经忘了,总是越新支持的就越好),以更好的支持自己开发Blazor项目. WebAssembly 搜索Blazor模板 ...
- 面向对象之多态(Java实现)
本文借鉴于csdn,博客园,b站等各大知识分享平台 之前学习了封装与继承,封装就是数据的封装性(大致理解),继承就是一个类继承另一个类的属性,称为父子类 多态 多态是面向对象的第三大特性(共三大特性) ...
- 介绍下 npm 模块安装机制,为什么输入 npm install 就可以自动安装对应的模块?
1. npm 模块安装机制: 发出npm install命令 查询node_modules目录之中是否已经存在指定模块 若存在,不再重新安装 若不存在 npm 向 registry 查询模块压缩包的网 ...