基于 MPI 的快速排序算法的实现
完整代码:
#include <iostream>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <cmath>
#include <mpi.h>
using namespace std;
struct Pair {
int left;
int right;
};
const int MAX_PROCESS = 128;
const int NUM = 8000;
const int MAX = 1000000;
const int MIN = 0;
int arr[NUM];
int temp[NUM];
Pair pairs[MAX_PROCESS];
int counter = -1;
void swap(int A[], int i, int j) {
int temp = A[i];
A[i] = A[j];
A[j] = temp;
}
int findpivot(int i, int j) {
return (i + j) / 2;
}
int partition(int A[], int l, int r, int pivot) {
do {
while (A[++l] < pivot);
while ((r != 0 && (A[--r] > pivot)));
swap(A, l, r);
} while (l < r);
swap(A, l, r);
return l;
}
void quicksort(int A[], int i, int j, int currentdepth, int targetdepth) {
if (currentdepth == targetdepth) {
int rank = ++counter;
pairs[rank].left = i;
pairs[rank].right = j;
cout << pairs[rank].left << " and " << pairs[rank].right << " : rank " << rank << endl;
return;
}
if (j <= i) return;
int pivotindex = findpivot(i, j);
swap(A, pivotindex, j);
int k = partition(A, i - 1, j, A[j]);
swap(A, k, j);
quicksort(A, i, k - 1, currentdepth + 1, targetdepth);
quicksort(A, k + 1, j, currentdepth + 1, targetdepth);
}
void quicksort(int A[], int i, int j) {
if (j <= i) return;
int pivotindex = findpivot(i, j);
swap(A, pivotindex, j);
int k = partition(A, i - 1, j, A[j]);
swap(A, k, j);
quicksort(A, i, k - 1);
quicksort(A, k + 1, j);
}
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
int RANK, SIZE, targetdepth, left, right, REAL_SIZE;
MPI_Comm_rank(MPI_COMM_WORLD, &RANK);
MPI_Comm_size(MPI_COMM_WORLD, &SIZE);
REAL_SIZE = SIZE;
if (RANK == 0) {
cout << "Quick sort start..." << endl;
cout << "Generate random data... ";
memset(arr, 0, NUM * sizeof(arr[0]));
srand(time(NULL));
for (int i = 0; i < NUM; i++) {
arr[i] = MIN + rand() % (MAX - MIN);
}
cout << "Done." << endl;
targetdepth = log2(SIZE);
cout << "Rank: " << RANK << endl;
cout << "Sorting... ";
quicksort(arr, 0, NUM - 1, 0, targetdepth);
REAL_SIZE = counter + 1;
for (int i = 1; i < SIZE; i++) {
int left = pairs[i].left;
int right = pairs[i].right;
MPI_Send(&REAL_SIZE, 1, MPI_INT, i, 99, MPI_COMM_WORLD);
MPI_Send(&left, 1, MPI_INT, i, 0, MPI_COMM_WORLD);
MPI_Send(&right, 1, MPI_INT, i, 1, MPI_COMM_WORLD);
MPI_Send(&arr, NUM, MPI_INT, i, 2, MPI_COMM_WORLD);
}
left = pairs[0].left;
right = pairs[0].right;
quicksort(arr, left, right);
cout << "Process " << RANK <<" done."<< endl;
}
for (int process = 1; process < REAL_SIZE; process++) {
if (RANK == process) {
MPI_Status status;
MPI_Recv(&REAL_SIZE, 1, MPI_INT, 0, 99, MPI_COMM_WORLD, &status);
MPI_Recv(&left, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
MPI_Recv(&right, 1, MPI_INT, 0, 1, MPI_COMM_WORLD, &status);
MPI_Recv(&arr, NUM, MPI_INT, 0, 2, MPI_COMM_WORLD, &status);
if (process < REAL_SIZE) {
quicksort(arr, left, right);
MPI_Send(&arr, NUM, MPI_INT, 0, 0, MPI_COMM_WORLD);
cout << "Process " << RANK << " done." << endl;
}
}
}
if (RANK == 0) {
for (int i = 1; i < REAL_SIZE; i++) {
//cout << "Master is ready to receive data from process " << i << endl;
MPI_Status status;
MPI_Recv(&temp, NUM, MPI_INT, i, 0, MPI_COMM_WORLD, &status);
for (int j = pairs[i].left; j <= pairs[i].right; j++) {
arr[j] = temp[j];
}
//cout << "Master has combined data from process " << i << endl;
}
cout << "Done." << endl;
cout << "Result:" << endl;
int counter = 1;
int row = 20;
for (int i = 0; i < NUM; i++, counter++) {
cout << arr[i] << " ";
if (arr[i] < arr[max(i - 1, 0)]) {
cerr << "Invalid! " << arr[i] << " > "<< arr[max(i - 1, 0)] <<" i is "<< i << endl;
}
if (counter % row == 0) cout << endl;
}
}
MPI_Finalize();
}
运行截图:
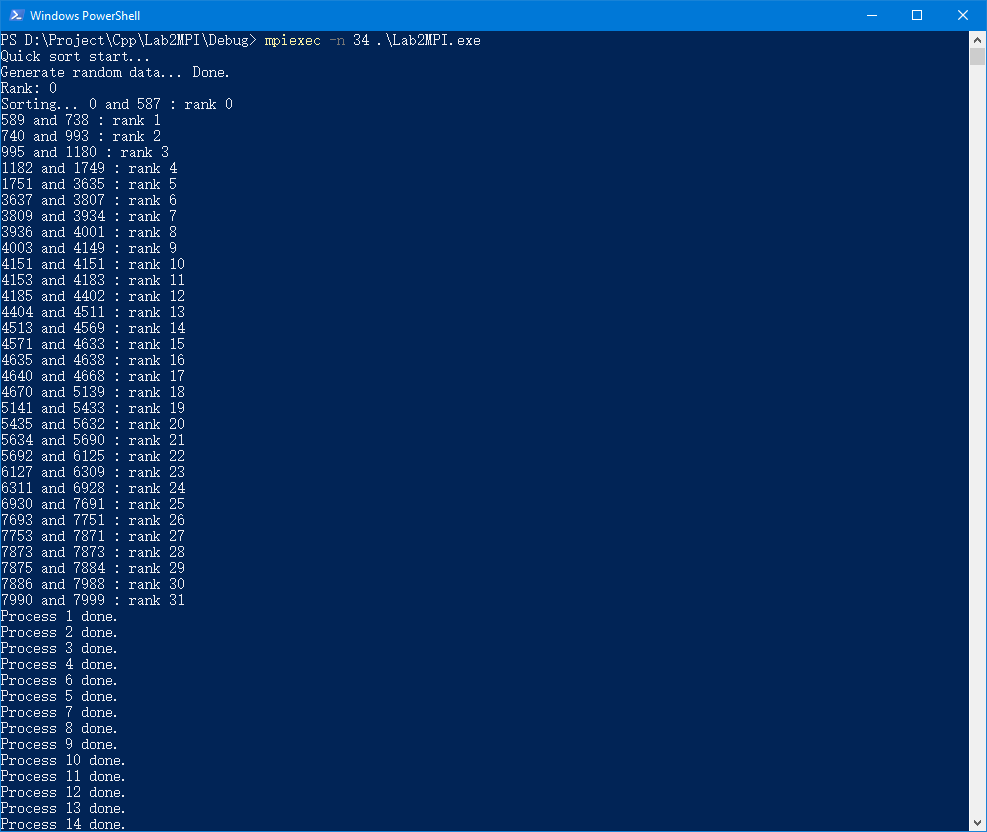
基于 MPI 的快速排序算法的实现的更多相关文章
- 基于c++的ostu算法的实现
图像二值化算法是图像处理的基础.一般来说,二值化算法可以分为两个类别:全局二值化和局部二值化.全局二值化是指通过某种算法找到一个全局的阈值T,对图像中坐标为(x,y)的像素值做如下处理: Ostu就是 ...
- 快速排序算法的实现 && 随机生成区间里的数 && O(n)找第k小 && O(nlogk)找前k大
思路:固定一个数,把这个数放到合法的位置,然后左边的数都是比它小,右边的数都是比它大 固定权值选的是第一个数,或者一个随机数 因为固定的是左端点,所以一开始需要在右端点开始,找一个小于权值的数,从左端 ...
- Python八大算法的实现,插入排序、希尔排序、冒泡排序、快速排序、直接选择排序、堆排序、归并排序、基数排序。
Python八大算法的实现,插入排序.希尔排序.冒泡排序.快速排序.直接选择排序.堆排序.归并排序.基数排序. 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得 ...
- 基于思岚A1激光雷达+OpenGL+VS2017的Ramer-Douglas-Peucker算法的实现
时隔两年 又借到了之前的那个激光雷达,最老版本的思岚A1,甚至不支持新的固件,并且转接板也不见了,看了下淘宝店卖¥80,但是官方提供了一个基于STM32的实现方式,于是我估摸着这个转接板只是一个普通的 ...
- Canny边缘检测算法的实现
图像边缘信息主要集中在高频段,通常说图像锐化或检测边缘,实质就是高频滤波.我们知道微分运算是求信号的变化率,具有加强高频分量的作用.在空域运算中来说,对图像的锐化就是计算微分.由于数字图像的离散信号, ...
- SSE图像算法优化系列十三:超高速BoxBlur算法的实现和优化(Opencv的速度的五倍)
在SSE图像算法优化系列五:超高速指数模糊算法的实现和优化(10000*10000在100ms左右实现) 一文中,我曾经说过优化后的ExpBlur比BoxBlur还要快,那个时候我比较的BoxBlur ...
- C++基础代码--20余种数据结构和算法的实现
C++基础代码--20余种数据结构和算法的实现 过年了,闲来无事,翻阅起以前写的代码,无意间找到了大学时写的一套C++工具集,主要是关于数据结构和算法.以及语言层面的工具类.过去好几年了,现在几乎已经 ...
- 排序算法的实现之Javascript(常用)
排序算法的实现之Javascript 话不多说,直接代码. 1.冒泡排序 1.依次比较相邻的两个数,如果前一个比后一个大,则交换两者的位置,否则位置不变 2.按照第一步的方法重复操作前length-1 ...
- Alink漫谈(六) : TF-IDF算法的实现
Alink漫谈(六) : TF-IDF算法的实现 目录 Alink漫谈(六) : TF-IDF算法的实现 0x00 摘要 0x01 TF-IDF 1.1 原理 1.2 计算方法 0x02 Alink示 ...
随机推荐
- kylin的实现原理
摘自https://blog.bcmeng.com/post/kylin-cube.html#kylin%E7%9A%84%E9%A2%84%E8%AE%A1%E7%AE%97%E6%98%AF%E5 ...
- redis学习之——主从复制(replication)
准备:拥有linux环境,并安装redis mater:主机,进行写操作 slave:从机,进行读操作 一.配置 继续前边的学习.我们是拷贝redis.conf,文件到了/root /redis 下. ...
- Python搭建调用本地dll的Windows服务(浏览器可以访问,附测试dll64位和32位文件)
一.前言说明 博客声明:此文链接地址https://www.cnblogs.com/Vrapile/p/14113683.html,请尊重原创,未经允许禁止转载!!! 1. 功能简述 (1)本文提供生 ...
- (数据科学学习手札100)搞定matplotlib中的字体设置
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 matplotlib作为数据可视化的利器,被广泛 ...
- MySQL_CRUD_In_Terminal
MySQL的CRUD操作 从Terminal中,可以对数据库进行链接,无需GUI界面就可以对数据库进行相关操作.对于Linux.Windows.MacOS,也可以使用可视化软件Navicat.MySQ ...
- 学习Python之数据类型
格式化字符串 字符串格式化是一种非常简洁的特性,它能让我们动态更新字符串中的内容.假设我们有从服务器获取的用户信息,并希望根据该信息显示自定义消息,第一个想法是应用字符串连接之类的东西. first_ ...
- RPC 核心,万变不离其宗
微信搜 「yes的练级攻略」干货满满,不然来掐我,回复[123]一份20W字的算法刷题笔记等你来领. 个人文章汇总:https://github.com/yessimida/yes 欢迎 star ! ...
- java 常用时间操作类,计算到期提醒,N年后,N月后的日期
package com.zjjerp.tool; import java.text.ParseException; import java.text.ParsePosition; import jav ...
- java中游标
package YouBiao; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.Resu ...
- node2vec实现源码详解
一.按照程序执行的顺序,第一步是walker.py中的preprocess_transition_probs()函数 这个函数的作用是生成两个采样预备数据,alias_nodes,alias_edge ...