我叫MongoDb,不懂我的看完我的故事您就入门啦!

这是mongo基础篇,后续会连续更新4篇
大家好我叫MongoDb,自从07年10月10gen团队把我带到这个世界来,我已经13岁多啦,现在越来越多的小伙伴在拥抱我,我很高兴。我是NoSQL大家族的一员,我是C++的亲儿子啦。为了大家更好的熟悉我,今天我先简单从简单的使用角度来介绍我自己。
首先还是先介绍一下我们的大家族NoSQL吧
NoSQL只是他简称,他的中文名叫 非关系型数据库,外文名叫Not Only SQL。他是对关系型数据库的一个补充(RDBMS)。RDBMS追求数据存储和查询的高度结构化、严格的数据一致性;NOSQL不在乎形式,重点关心效率,NOSQL是高性能、无模式、高可扩展的分布式数据库,NOSQL存储包括四种类型:键值对存储、列存储、文档存储、图形数据存储。NoSQL就简单介绍到这,这不是今天的重点,下面还是重点介绍一下我自己(MongoDb),呵呵!
MongoDb自我介绍
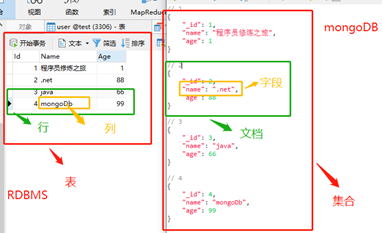
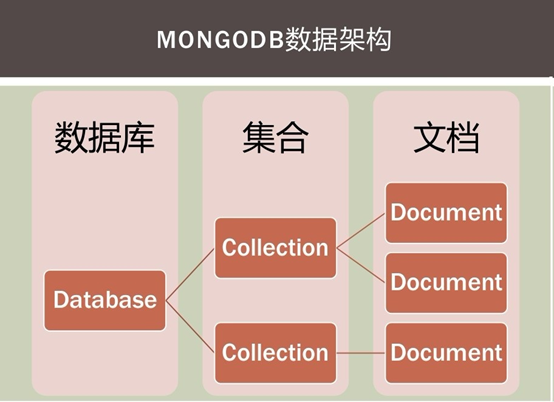
MongoDb是一个面向文档存储的键值对NOSQL数据库,是一个最接近关系型数据库的非关系数据库。在数据存储结构和查询上使用BJOSN(类似于JSON)结构,BJOSN支持多层机构,在具体的使用过程中,更像是操作Javascript脚本。正因为MongoDb的无模式化,在实际应用中变得更加灵活,易于扩展。与RDBMS一样,支持主键、索引、检索等操作,由于非结构化所以不支持join查询。
MongoDb的基本概念
具体的数据库安装就不在介绍了,网上一搜一大推。MongoDb采用BJON化的文档存储,所以其基本结构概念可以结合JSON联想一下:字段、文档、集合、数据库,这和RDBMS的属性、列、表、数据库是一一对应关系。下面以一个表格来对比说明一下:
|
RDBMS |
MongoDb |
||
|
概念 |
说明 |
概念 |
说明 |
|
database |
数据库 |
database |
数据库 |
|
table |
表 |
collection |
集合 |
|
row |
行 |
document |
文档:对应的一个BJSON |
|
column |
列 |
field |
字段:BJSON中的具体某一个字段 |
简单的一个表格显示还不够直观,那我们在来一张形象的图片来说明一下吧!
用户权限管理
在生成环境数据库管理中,数据库权限是一个很重要的功能。在具体的权限上,需要针对全局的权限控制,需要精确到具体的数据的权限,在具体的权限分类上包括:读、读写、管理员等权限。下面列表介绍mongodb的内置权限:
|
权限名称 |
权限说明 |
|
read |
允许用户读取指定数据库 |
|
readWrite |
允许用户读写指定数据库 |
|
dbAdmin |
允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile |
|
userAdmin |
允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户 |
|
clusterAdmin |
只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限。 |
|
readAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的读权限 |
|
readWriteAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的读写权限 |
|
userAdminAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的userAdmin权限 |
|
dbAdminAnyDatabase |
只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限。 |
|
root |
只在admin数据库中可用。超级账号,超级权限 |
通过上面的表,我们可以得出:根据权限的作用范围上来看,权限分为了两大类权限:针对每一库的权限、针对全部数据库的权限。根据不同的权限分类,在赋值格式上也有一定差异,在具体的用户权限分配上,一个用户可以同时分配多个权限。
新增用户时权限初始化格式为:
针对全部数据库权限初始化命令格式:
db.createUser({user:"用户名",pwd:"密码",roles:["权限值"]})
针对指定数据库权限初始化命令格式:
db.createUser({user:"用户名",pwd:"密码",roles:[ {role:"权限值",db:"对应的数据库"},{role:"权限值",db:"对应的数据库"}….]})
这样说可能不怎么好理解,那么我们还是以实际工作的使用情况来举例说明。
条件假设:有3个数据库:testdb001、testdb002
需要给如用户分配对应的权限
|
用户 |
需要分配的权限 |
具体的命令 |
|
adminRoot |
超级账号,具有所有数据库的全部操作权限 |
use admin db.createUser({user:"adminRoot",pwd:"123",roles:["root"]}) |
|
adminWrite |
超级写账号,具有所有数据库的读写操作权限 |
use admin db.createUser({user:"adminWrite",pwd:"123",roles:["readWriteAnyDatabase"]}) |
|
adminRead |
超级写账号,具有所有数据库的读操作权限 |
use admin db.createUser({user:"adminRead",pwd:"123",roles:["readAnyDatabase"]}) |
|
001Write |
具有数据库testdb001的读写操作权限 |
use admin db.createUser({user:"001Write",pwd:"123",roles:[ {role:"readWrite",db:" testdb001"}]}) |
|
001Read |
具有数据库testdb001的读操作权限 |
use admin db.createUser({user:"001Read",pwd:"123",roles:[ {role:"read",db:" testdb001"}]}) |
|
012Write |
具有数据库testdb001、testdb002的读写操作权限 |
use admin db.createUser({user:"001Write",pwd:"123",roles:[ {role:"readWrite",db:" testdb001"},{role:"readWrite",db:" testdb002"}]}) |
通过实际举例,应该对权限的新增初始化操作命令有了理解,那么下面我们就来对权限的根据新操作命令简单聊聊,其实根系和初始化具体的权限格式是一至的,具体如下:
针对全部数据库权限更新命令格式:
db.updateUser("被更新用户名",{pwd:"更新后的密码",roles:["权限值"]})
针对指定数据库权限更新命令格式:
db.updateUser("被更新用户名",{pwd:"更新后的密码",roles:[{role:"权限值",db:"对应的数据库"},{role:"权限值",db:"对应的数据库"}….]})
注意:updateUser的第二个参数有两个节点:pwd和roles。如果不需要更新某一节点的数据,那么直接不要该节点即可。
实例:继续上面的实例继续操作
|
用户更新述求 |
具体的命令 |
|
更新用户adminRoot的密码为111111 |
use admin db.updateUser("adminRoot",{pwd:"111111"}) |
|
更新001Write的同时具有testdb001和testdb002的写权限 |
use admin db.updateUser("adminWrite",{roles:[ {role:"readWrite",db:" testdb001"},{role:"readWrite",db:" testdb002"}]}) |
|
更新001Read的同时具有testdb001和testdb002的读权限,并且密码也更新为111111 |
use admin db.updateUser("001Read",{ pwd:"111111",roles:[ {role:"read",db:" testdb001"},{role:"read",db:" testdb002"}]}) |
数据库(database)
具体的数据库概念和RDBMS一致,一个mongodb可以创建多个数据库,不同数据库也可以存储在不同的mongodb。系统的默认数据库包括:admin(存储用户权限相关)、config(配置信息)、local(日志信息)。针对数据库我们常用的操作包括:创建、删除。具体的实现如下:
创建:use 数据库名称
当数据库名称不存在时,系统自动创建(创建后不能显示,需要向里面插入数据才会显示),存在则切换。
删除:首先要切换到对于的数据库,然后在执行dropDatabase命令
use 被删除的数据库名称
db.dropDatabase()
集合(Collection)
集合是mongodb中对数据存储的一个分组,和关系数据库中的表是对应关系。集合中存储的文档数据的无固定格式,可以自由存储不同格式的bjson数据,但是在实际使用中,我们还是存储同一类型的bjson数据。集合的常见的操作命令如下:
创建集合:
db.createCollection(集合名称,集合规则),其中第二次参数为一个json数据,非必填,具体的参数节点为:
集合规则:{ capped :选填bool类型:设置改集合是否为一个固定集合,
true:代表固定集合,集合中的数据不可修改,与size配对使用,代表当集合达到指定大小后,会自动覆盖历史数据(最先添加的数据),
size:选填数字类型:指定集合的最大存储数据(字节数),当集合达到指定大小后,会自动覆盖历史数据(最先添加的数据) }
max: 选填数字类型:指定集合的最大存储的文档总个数,当文档个数大于max值时,会自动替换历史文档
}
collection删除:
db.集合名称.drop();
文档(Document)
文档就一组键值(key-value)对数据(一个BJON),具体的一个文档结构可以多层嵌套,不同文档间的数据结构可以不一样,并且相同节点的数据类型也可不一样,这是与RDBMS最大的区别所在,这也奠定了MongoDB的高可扩展性。其实简单的说就是一个一个的jon格式的数据。
文档常见的几个操作命令汇总:
|
操作 |
命令格式 |
|
插入数据 |
db.集合名称.insert(json对象) json可以是单个数据,也可以是一个集合列表 |
|
更新数据 |
db. 集合名称.update(query , update,option) query :被更新文档条件json update:更新后的文档json option:更新方式json,参数格式为{ upsert: boolean, multi : boolean } upsert:非必填参数,如果不存在是否新增,当值为true时,如果没有符合条件的数据,就插入数据, ,默认为false multi: 非必填参数,是否更新符合要求的所有数据,当值为true时,符合条件的数据全部更新,默认为false |
|
删除数据 |
db.集合名称.remove(query , justOne ) query :(可选)删除的文档的条件。 justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。 |
|
查询数据 |
db.集合名称.find(jison对象查询条件) |
字段
字段就很好理解了,就是文档中的json数据的每一个节点。

通过对mongodb的操作简单介绍,其实我们不难发现以下一些特性:
1.无论是对文档的增、删、改、查操作的参数一切皆json,在实际操作的时候,按照json方式来操作即可。
2.数据库和集合都可以在使用是自动创建:
2.1 use 切换数据库时,如果没有数据库自动创建;
2.2 db.集合.insert() 当集合不存在时,系统自动创建集合。
Mongodb的这一些特性用起来是不是很爽的感觉。下面从数据库的创建,到文档的整体操作流程写一些演示实例,来加深印象。
|
操作 |
命令格式 |
|
连接到mongdb |
mongo use admin db.auth("用户名","用户密码") |
|
创建数据库 bd001和表user001 |
use bd001 db.createCollection("user001") |
|
创建数据库 bd002和user002 |
use bd002 db.createCollection("user002") |
|
查看所有数据库 |
show dbs 输出结果 admin 0.000GB config 0.000GB local 0.000GB bd001 0.000GB bd002 0.000GB |
|
删除集合user002 |
use db002 db.user002.drop() |
|
删除数据库db002 |
use db002 db. dropDatabase() |
|
向表user001插入一条数据 |
use db001 db.user001.insert({name:”程序员修炼之旅”,age:2}) |
|
向表user001插入两条数据 |
use db001 db.user001.insert([ {name:"mongodb",age:12,type:"database"}, {"name":".net",from:"U.S.A"} ]) |
|
向表user001插入三条数据 |
use db001 db.user001.insert([ {name:"zhangsan",age:12,sex:"man"}, {name:"zhangsan",age:18,sex:"woman"}, {name:"zhangsan",age:22,sex:"man"} ]) |
|
查询一下表中的数据情况 |
use db001 db.user001.find() 查询结果: { "_id" : ObjectId("5fa0ab4195368a0bf20f38cd"), "name" : "程序员修炼之旅", "age" : 2 } { "_id" : ObjectId("5fa0abb495368a0bf20f38d0"), "name" : ".net", "from" : "U.S.A" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d1"), "name" : "zhangsan", "age" : 12, "sex" : "man" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d2"), "name" : "zhangsan", "age" : 18, "sex" : "woman" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d3"), "name" : "zhangsan", "age" : 22, "sex" : "man" } |
|
查询表中name="程序员修炼之旅"的数据 |
use db001 db.user001.find({name: "程序员修炼之旅"}) 查询结果: { "_id" : ObjectId("5fa0ab4195368a0bf20f38cd"), "name" : "程序员修炼之旅", "age" : 2 } |
|
修改表中name="程序员修炼之旅"的数据的age=66,并新增一个节点from节点 |
use db001 db.user001.update({name: "程序员修炼之旅"},{$set:{age:66,from: "CDU"}}) |
|
查看修改后的数据 |
use db001 db.user001.find({name: "程序员修炼之旅"}) 查询结果: { "_id" : ObjectId("5fa0ab4195368a0bf20f38cd"), "name" : "程序员修炼之旅", "age" : 66,from: "CDU"} 数据已经是修改后的数据了 |
|
修改表中name=" zhangsan"的数据的age=88,并且只修改一条符合要求的数据 |
use db001 db.user001.update({name: "zhangsan"},{$set:{age:88}},{ multi:false}) |
|
查看name=" zhangsan"修改后的数据,是否只有一条数据的age被修改为88? |
use db001 db.user001.find({name: "zhangsan"}) 查询结果: { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d1"), "name" : "zhangsan", "age" : 88, "sex" : "man" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d2"), "name" : "zhangsan", "age" : 18, "sex" : "woman" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d3"), "name" : "zhangsan", "age" : 22, "sex" : "man" } 只有第一条的age被修改为了88 |
|
修改表中name=" zhangsan"的数据的age=99,修改符合要求的所有数据 |
use db001 db.user001.update({name: "zhangsan"},{$set:{age:99}},{ multi:true}) |
|
查看name=" zhangsan"修改后的数据,是否只所有数据的age被修改为99? |
use db001 db.user001.find({name: "zhangsan"}) 查询结果: { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d1"), "name" : "zhangsan", "age" : 99, "sex" : "man" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d2"), "name" : "zhangsan", "age" : 99, "sex" : "woman" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d3"), "name" : "zhangsan", "age" : 99, "sex" : "man" } name="zhangsan"的所有数据age被修改为了99 |
|
修改name="lisi"的age=77 |
use db001 db.user001.update({name: "lisi"},{$set:{age:77}}) |
|
查看数据修改结果 由于没有name=lisi的数据,所有查询不到数据 |
use db001 db.user001.find({name: "lisi"}) 查询结果: 无数据 |
|
修改name="lisi"的age=77,如果没有则新增 |
use db001 db.user001.update({name: "lisi"},{$set:{age:77}},{ upsert:true}) |
|
查看数据修改结果 新增了一条name="lisi"的数据 |
use db001 db.user001.find({name: "lisi"}) 查询结果: { "_id" : ObjectId("5fa0b3731b875939723ffe26"), "name" : "lisi", "age" : 77 } |
|
删除一条name="zhangsan"的数据 |
use db001 db.user001.rmove({name: "zhangsan"},1) |
|
查看删除结果 |
use db001 db.user001.find({name:"zhangsan"}) 查询结果: { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d2"), "name" : "zhangsan", "age" : 18, "sex" : "woman" } { "_id" : ObjectId("5fa0ad3b95368a0bf20f38d3"), "name" : "zhangsan", "age" : 22, "sex" : "man" } name="zhangsan"的数据数据由原来的3条变为了2条,被删除了一条 |
|
删除所有name="zhangsan"的数据 |
use db001 db.user001.rmove({name: "zhangsan"}) |
|
查看删除结果 |
use db001 db.user001.find({name:"zhangsan"}) 查询结果: 无数据 name="zhangsan"的数据数据被全部删除了 |
通过上面的实际操作,我们发现所有新增文档都会自动生成一个节点”_id”( ObjectId),该_id是mongodb系统自动生成的类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:

1.前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
2.接下来的 3 个字节是机器标识码
3.紧接的两个字节由进程 id 组成 PID
4.最后三个字节是随机数
当然_id也可以根据实际需要自定义赋值。
好了今天就先写到这,通过本篇文章对mongo有了一个初步的认识了解,下一篇文章,我们在一起详聊查询,mongo的查询还是有很多聊的。谢谢您的查看。
END
为了更高的交流,欢迎大家关注我的公众号,扫描下面二维码即可关注,谢谢:

我叫MongoDb,不懂我的看完我的故事您就入门啦!的更多相关文章
- 还不懂Redis?看完这个故事就明白了!
我是Redis 你好,我是Redis,一个叫Antirez的男人把我带到了这个世界上. 说起我的诞生,跟关系数据库MySQL还挺有渊源的. 在我还没来到这个世界上的时候,MySQL过的很辛苦,互联网发 ...
- 看完此文还不懂NB-IoT,你就过来掐死我吧...【转】
转自:https://www.cnblogs.com/pangguoming/p/9755916.html 看完此文还不懂NB-IoT,你就过来掐死我吧....... 1 1G-2G-3G-4G-5G ...
- 看完此文还不懂NB-IoT,你就过来掐死我吧...
看完此文还不懂NB-IoT,你就过来掐死我吧....... 1 1G-2G-3G-4G-5G 不解释,看图,看看NB-IoT在哪里? 2 NB-IoT标准化历程 3GPP NB-IoT的标准化始于20 ...
- 深度分析:java设计模式中的原型模式,看完就没有说不懂的
前言 原型模式(Prototype模式)是指:用原型实例指定创建对象的种类,并且通过拷贝这些原型,创建新的对象 原型模式是一种创建型设计模式,允许一个对象再创建另外一个可定制的对象,无需知道如何创建的 ...
- 深度分析:面试阿里,字节跳动,美团90%被问到的List集合,看完还不懂算我输
1 List集合 1.1 List概述 在Collection中,List集合是有序的,可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素. 在List集合中,我们常用到Arr ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- 看完我的笔记不懂也会懂----bootstrap
目录 Bootstrap笔记 知识点扫盲 容器 栅格系统 源码分析部分 外部容器 栅格系统(盒模型)设计的精妙之处 Bootstrap笔记 写在开始: 由于我对AngulaJS的学习只是一个最浅显的过 ...
- 看完我的笔记不懂也会懂----AngulaJS
目录 Angular.js学习笔记 ng-app(指令) ng-model ng-init angular之表达式 双向数据绑定 数据流向的总结 作用域对象 控制器对象 依赖对象与依赖注入 命令式与声 ...
- 看完SQL Server 2014 Q/A答疑集锦:想不升级都难!
看完SQL Server 2014 Q/A答疑集锦:想不升级都难! 转载自:http://mp.weixin.qq.com/s/5rZCgnMKmJqeC7hbe4CZ_g 本期嘉宾为微软技术中心技术 ...
随机推荐
- Typore的简单用法
1 无序列表使用方法 +号和空格一起按就可以写出这个点 2 有序列表使用方法 .先写1.然后打个空格就再回车 3 使用#和空格表示一级标题 一级标题 4 使用##和空格表示二级标题 5 二级标题 6 ...
- 系统编程-文件IO-IO处理方式
IO处理五种模型 .
- Oracle报错>记录被另外一个用户锁定
原因 当一个用户对数据进行修改时,若没有进行提交或者回滚,Oracle不允许其他用户修改该条数据,在这种情况下修改,就会出现:"记录被另外一个用户锁定"错误. 解决 查询用户.数据 ...
- 彻底根治window弹窗小广告(今日热点)
在一个阴雨蒙蒙的下午,我上完厕所回到工位,输入锁屏密码,解锁,蹦出来三个小广告,我......这还能忍??? 废话不多说,开搞! 一.广告分为两种: 红色字的今日热点 蓝色字的今日热点 二.追溯根源: ...
- .NET 5.0 RC2 发布,正式版即将在 11 月 .NET Conf 大会上发布
原文:http://dwz.win/ThX 作者:Richard 翻译:精致码农-王亮 说明:本译文舍弃了少许我实在不知道如何翻译但又不是很重要的语句. 今天(10月13日)我们发布了 .NET 5. ...
- MeteoInfoLab脚本示例:加载图片和透明图层
MeteoInfoLab的georead函数提供了读取shape文件.image文件(JPG.PNG等,需要有相应的地理定位文件)文件生成图层的功能(事实上shaperead也是同样的功能,不过函数名 ...
- day15 Pyhton学习
迭代器 掌握for循环 实际上for循环的本质,就是将一个可迭代的变成迭代器 每一次从中取值都相当于执行了一次next 如果是迭代器,那么只能取一次值 生成器 - 本质就是迭代器 生成器函数(返回值是 ...
- node服务器基本搭建
const http = require('http') // 引入http模块 http.createServer(function(req,res){ // 创建一个http服务器 // 这里是一 ...
- 面经分享:看非科班研究生如何转行斩获 ATM 大厂的 Offer ?
前言 先介绍一下自己的情况吧,本科和研究生都是通信专业,本科是某 Top2,研究生是香港某大学.了解了通信行业的就业情况和工作内容后,大概今年3月份的时候开始想转互联网. 本人相关的基础情况是:学校学 ...
- Helium文档2-WebUI自动化-常用方法介绍
学习思路: 查看github项目的源码,每个方法都有介绍及使用说明 https://github.com/mherrmann/selenium-python-helium/blob/master/he ...