Simple: SQLite3 中文结巴分词插件
一年前开发 simple 分词器,实现了微信在两篇文章中描述的,基于 SQLite 支持中文和拼音的搜索方案。具体背景参见这篇文章。项目发布后受到了一些朋友的关注,后续也发布了一些改进,提升了项目易用性。
最近重新体验微信客户端搜索功能,发现对于中文的搜索已经不是基于单字命中,而是更精准的基于词组。比如搜索“法国”,之前如果句子中有“法”和“国”两个字时也会命中,所以如果一句话里包含“国法”就会被命中,但是这跟“法国”没有任何关系。
本文描述对 simple 分词器添加的基于词组命中的实现,从而实现更好的查找效果。另外本文也会基于之前在 issue 中大家提到的问题,提供一个怎么使用 SQLite FTS 表的建议。
背景
先简单回顾一下之前的实现,因为结巴分词只跟中文有关,所以本文会略去拼音的部分。
搜索主要分为两部分,建立索引和命中索引。为了实现中文的搜索,我们先把句子按照单字拆分,按照单字建立索引;然后对于用户的输入,也同样按照单字拆分,这样 query 就能命中索引了。为了支持词组搜索,再按照单字拆分就很难满足需求了,所以可以考虑的方案是要么改索引,要么改 query。如果改索引的话会有一些问题,比如如果用户就输入了一个字比如“国”,但是我们建索引的时候把“法国”放到了一起,那“国”字就命中不了了,所以最好是保持单字索引不变,通过改写 query 来达到检索词组的效果。
实现
simple 分词器之前提供了一个 simple_query() 函数来帮助用户生成 query,我们也可以加一个新的函数来实现词组的功能。经过简单的调研,我们发现 cppjieba 用 C++ 实现了结巴分词的功能,很适用于我们的需求。
所以我实现了一个新的函数叫做 jieba_query() ,它的使用方式跟 simple_query() 一样,内部实现时,我们会先使用 cppjieba 对输入进行分词,再根据分词的结果构建 SQLite3 能理解的 query ,从而实现了词组匹配的功能。具体的逻辑可以参考 这里 。对于不需要结巴分词功能的用户,可以在编译的时候使用 -DSIMPLE_WITH_JIEBA=OFF 关闭结巴分词的功能,这样能减少编译文件的大小,方便客户端对文件大小敏感的场景使用。
使用
本文想着重介绍一下 SQLite3 FTS5 功能使用的问题,这些问题都是有朋友在项目的 issue 中提到过的,都是非常好的问题,但是也说明有不少人对怎么使用 FTS 表不太清楚,希望本文能解决一些疑惑。
首先第一点,FTS5 表虽然是一个虚拟表,提供了全文搜索的功能,但是它整体还是跳不出 SQL 的范畴,所以其实很多用法和其他 SQL 表是一样的,当然它也跳不出 SQL 的限制。比如有一个 issue 问如果表中有多列的时候,能不能检索全表,但是只返回命中的那些列?答案是不行的,因为按照 SQL 的语法规则,SELECT 语句后面必须显示说明你想要 SELECT 哪些列,所以结果列是必须用户指定的,如果我们像知道哪些列命中了,只能通过其他一些手段,感兴趣的朋友可以看这个 issue36。
另外 simple 分词器提供了不少额外的功能,比如 simple_query() 和 simple_highlight() 等辅助函数,但是它并不影响我们使用原有 FTS5 的功能,比如如果想按照相关度排序,FTS5 自带的 order by rank 功能还是可以继续可以使用,也就是说 FTS5 页面 提供的所有功能都是可以和 simple 分词器一起使用的。
最后也是最重要的一个问题,FTS5 表到底该怎么用?有一个 issue26 提到的问题非常好,我把它放到这里:
《微信全文搜索优化之路》一文中针对索引表的介绍,我对索引有几个问题想请教一下:
- 业务表是正常的程序的数据表,还要再为了全文搜索再多建立一份索引表,是吗?我直接将我的业务数据表在创建的时候按虚表建立行吗?(例如create virtual table tablename using fts5(列名1,列名2,tokenize = 'simple'))
- 如果再多建立一份索引表,那是不是每一个业务表和对应的索引表的表字段是完全相同?
- 如果再多建立一份索引表,那数据库的大小是不是加倍了,尤其是把文件或图片影片存入数据库的情况(BLOB类型)?
- 原文中【为了解决业务变化而带来的表结构修改问题,微信把业务属性数字化】,这也是我想要的,能否帮助贴下原文中提到的【索引表-IndexTable】和【数据表-MetaTable】的建表语句?
核心的问题是:想让表数据支持全文搜索,需要把数据复制一份吗?这样会不会导致数据库膨胀?在用户的手机上我们可不想占用太多无谓的空间。
externel content table
其实这个问题在 FTS5 的官方文档中已经给出了解决方案那就是 externel content table,大家也可以参考 这篇文章 。
它的意思是我们可以建一张普通表,然后再建一张 FTS5 表来支持全文索引,这张虚拟表本身不会存储真实的数据,如果 SELECT 语句用到具体的内容,都会通过关联关系去原表获取,这样就不存在数据重复的问题了。但是这里就会涉及到数据一致性的问题,怎么保证原表的数据和索引表是一致的呢?通过 trigger 也就是触发器来实现:对于原表的增删改,都会通过触发器同步到 FTS 表。这样基本上就完美解决了上面用户的问题。
可能有人会问为什么不直接用 FTS5 表呢?这样普通表就不用了,也省了触发器的逻辑。原因是 FTS 表提供了全文索引的能力,但是它也有限制,对于基于 ID 或者其他普通索引的请求它是不支持的,如果我们想有一个时间列并且基于时间列索引排序,FTS表就不行,还是需要普通表。通过普通表和 FTS 表结合的方案,我们就能同时使用两者的能力。
微信的方案
需要注意的是,微信并没有使用上面提到的方案,而是单独建了一张打平的索引表,把所有需要全文索引的数据放到一张单独的表里面,再通过外键关联到具体的业务去。这样的好处在微信的文章中有所提及,主要是其他关联的表结构变更的时候,FTS 表不用动,这样很容易添加想要搜索的字段,只需把该字段写入 FTS 表及关联关系的表就行,表结构见下图:
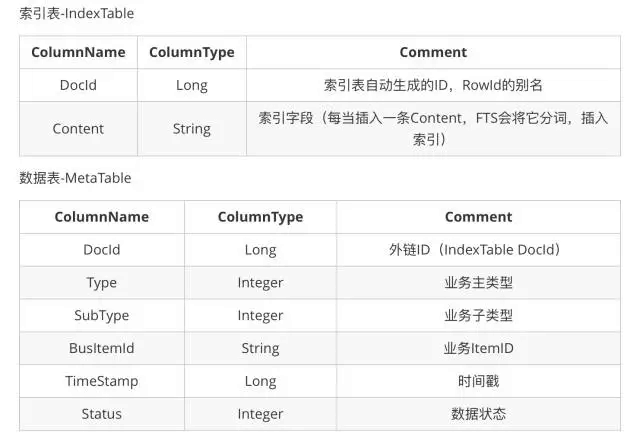
个人觉得对于微信这个复杂度的业务,可以考虑这个方案,毕竟需要搜索的信息非常多,这样方便各个业务复用搜索能力。但是对于大部分的业务,用 external content table 可能是更简单的方案,毕竟在数据写入和读取的时候都更快更方便,微信的方案在数据操作流程上会复杂不少,需要逻辑上做更多的封装。
总结
上面主要介绍了 simple 分词器最新的功能,基于结巴分词实现基于词组的搜索功能,实现更精准的匹配。另外也介绍了在实际项目中使用 FTS 表的方案,希望对大家有所助益。
Reference
- Simple 分词器: https://github.com/wangfenjin/simple
- sqlite 官方文档:https://www.sqlite.org/fts5.html
- 微信全文搜索优化之路:https://cloud.tencent.com/developer/article/1006159
- 微信移动端的全文检索多音字问题解决方案:https://cloud.tencent.com/developer/article/1198371
- Simple: 一个支持中文和拼音搜索的 sqlite fts5插件:https://www.wangfenjin.com/posts/simple-tokenizer/
- Full Text Search With Sqlite SQLite:https://kimsereylam.com/sqlite/2020/03/06/full-text-search-with-sqlite.html
Simple: SQLite3 中文结巴分词插件的更多相关文章
- ElasticSearch自定义分析器-集成结巴分词插件
关于结巴分词 ElasticSearch 插件: https://github.com/huaban/elasticsearch-analysis-jieba 该插件由huaban开发.支持Elast ...
- Elasticsearch如何安装中文分词插件ik
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库. 安装步骤: 1.到github网站下载源代码,网站地址为:https://github.com/medcl/ ...
- Elasticsearch安装中文分词插件ik
Elasticsearch默认提供的分词器,会把每一个汉字分开,而不是我们想要的依据关键词来分词.比如: curl -XPOST "http://localhost:9200/userinf ...
- 中文分词之结巴分词~~~附使用场景+demo(net)
常用技能(更新ing):http://www.cnblogs.com/dunitian/p/4822808.html#skill 技能总纲(更新ing):http://www.cnblogs.com/ ...
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- Elasticsearch安装ik中文分词插件(四)
一.IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Lu ...
- 北大开源全新中文分词工具包:准确率远超THULAC、结巴分词
最近,北大开源了一个中文分词工具包,它在多个分词数据集上都有非常高的分词准确率.其中广泛使用的结巴分词误差率高达 18.55% 和 20.42,而北大的 pkuseg 只有 3.25% 与 4.32% ...
- ElasticSearch(三) ElasticSearch中文分词插件IK的安装
正因为Elasticsearch 内置的分词器对中文不友好,会把中文分成单个字来进行全文检索,所以我们需要借助中文分词插件来解决这个问题. 一.安装maven管理工具 Elasticsearch 要使 ...
- python 中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
随机推荐
- SSM、SSH框架搭建,面试点总结
文章目录 1.SSM如何搭建:三个框架的搭建: 2.SSM系统架构 3.SSM整合步骤 4.Spring,Spring MVC,MyBatis,Hibernate个人总结 5.面试资源 关于SSM.S ...
- 日志框架(Log4J、SLF4J、Logback)--日志规范与实践
文章目录 一.Log4j 1.1新建一个Java工程,导入Log4j包,pom文件中对应的配置代码如下: 1.2resources目录下创建log4j.properties文件. 1.3输出日志 1. ...
- python模块----pymysql模块 (连接MySQL数据库)
pymysql模块是专门用来连接mysql数据库的模块,是非标准库模块,需要pip下载 下载 pip install pymysql 查询 import pymysql # 打开数据库连接 db = ...
- MySQL数据库---配置文件及数据文件
1.主配置文件 #/usr/local/mysql/bin/mysqld --verbose --help |grep -A 1 'Default options' #cat /etc/my.cnf ...
- CentOS 安装TFTP
1.当然是使用yum安装最直接,一共会安装3个东东tftp.i386tftp-server.i386xinetd.i386[root@localhost CentOS]# yum -y install ...
- 如何用RabbitMQ实现延迟队列
前言 在 jdk 的 juc 工具包中,提供了一种延迟队列 DelayQueue.延迟队列用处非常广泛,比如我们最常见的场景就是在网购或者外卖平台中发起一个订单,如果不付款,一般 15 分钟后就会被关 ...
- Java排序算法(二)选择排序
一.测试类SortTest import java.util.Arrays; public class SortTest { private static final int L = 20; publ ...
- HarmonyOS应用开发-Component体系介绍(一)
目录: 1. Component的内部类/接口 2. Component方法简介 3.总结 在HarmonyOS的UI框架中,Component为用户界面提供基本组件,Component类位于ohos ...
- 2018 ACM-ICPC 焦作区域赛 E Resistors in Parallel
Resistors in Parallel Gym - 102028E 吐槽一下,网上搜索的题解一上来都是找规律,对于我这种对数论不敏感的人来说,看这种题解太难受了,找规律不失为一种好做法,但是题解仅 ...
- .net core面试题
第1题,什么是ASP net core? 首先ASP net core不是 asp net的升级版本.它遵循了dot net的标准架构, 可以运行于多个操作系统上.它更快,更容易配置,更加模块化,可扩 ...