Apache Tika实战
Apache Tika实战
Tika 简介
Apache Tika 是一个内容分析工具包,可以检测上千种文件类型,并提取它们的元数据和文本。tika在设计上十分精巧,单一的接口使它易于使用,在搜索引擎索引,内容分析,翻译等诸多方面得到了广泛使用。
Apache Tika曾经是Apache Lucene的一个子项目,现已成为Apache顶级项目。
Tika的特点
- 支持上千种不同的文件类型
- 提供了多种实用工具,如tika-app, tika-server等
- 除了Java,还提供了其他编程语言的调用,如Julia,Python
- 扩展性很好,支持自定义文件类型和解析器
Tika的组成
tika的核心是一个类库,提供了文件类型检测,内容语言检测等功能,并有一个完整的解析器框架,通过这个框架集成了许多Java平台上流行的文件分析工具,如针对压缩格式,使用了commons-compress,针对微软Office文档,使用了Apache POI,针对Adobe PDF格式,采用了Apache PDFbox
tika-core && tika-parsers
tika-core是tika的核心,提供了文件类型检测,语言检测,以及解析器框架。
tika-core并不包含具体的解析器,而是提供了一个api,实际的解析器实现放在tika-parsers中。
tika-parsers具有非常的传递依赖,使用时应该注意和项目已有依赖的冲突问题
tika-app
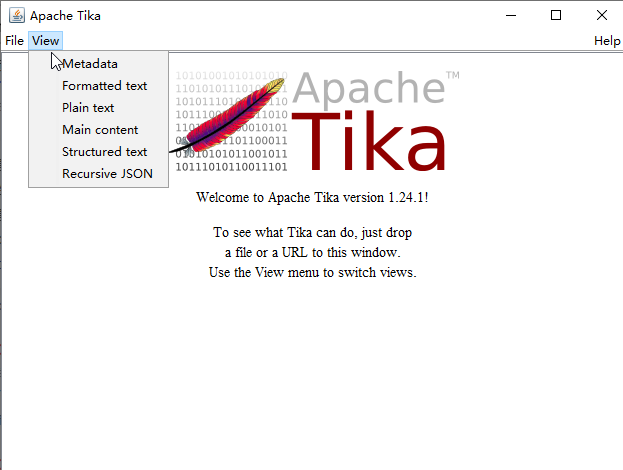
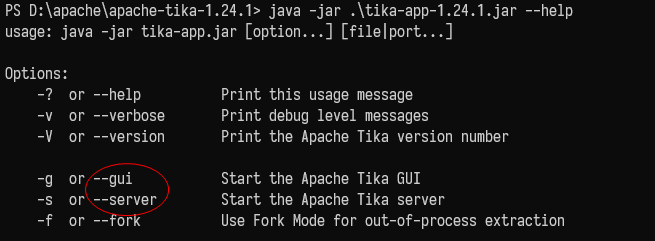
tika-app包含了tika核心类库和它的相关依赖,提供了命令行工具和图形用户界面,可以在脚本中使用,并支持管道。
tika-server
一个restful服务,方便和现有应用系统集成
$ curl -X PUT --data-binary @GeoSPARQL.pdf http://localhost:9998/tika --header "Content-type: application/pdf"
$ curl -T price.xls http://localhost:9998/tika --header "Accept: text/html"
tika-bundle
一个OSGi bundle,方便和基于OSGi的应用系统集成
OSGi: 开放服务网关协议,支持模块的动态加载,热拔插,可以在不停机的情况下,让应用程序加载新的模块,并提供新的服务
tika-eval
一个命令行工具,可以批量解析文件,然后把结果保存到数据库,支持多种类型的数据库,如h2,mysql......
默认数据库为h2,使用其他类型的数据库需要在启动时将相关的依赖放到classpath下
感觉是为Lucene准备的,提取文件内容后,保存到数据库,然后再由索引器进行索引,最后对外提供搜索服务
tika设计&实现
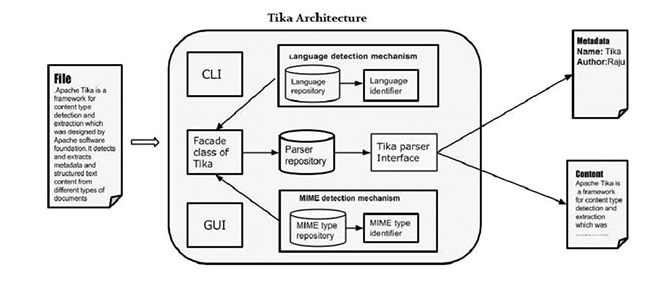
tika的核心功能是文件内容分析,这里分析主要有两个含义,一是提取文件的元数据(Metadata),包括文件类型,版本,作者,编辑工具,压缩算法等;二是解析文件得到文本内容(Text),这里的文本是指在相应的阅览软件中打开文件时看到的内容。
为了实现上述目标,tika设计了一个扩展性极强的框架,主要包括文件类型检测和内容解析两个部分。首先判断文件类型(Detector),再根据文件类型选用适当的解析器(Parser),解析结果保存在Metadata和ContentHandler中,我们可以通过自定义ContentHandler来得到想要的信息。
文件类型检测
文件类型检测是处理文件的第一个步骤,在大部分情况下,我们可以根据文件名简单判断出文件的类型,这样处理的效率很高,但是结果并不精准(因为文件名可以轻松伪造),因此Tika设计了一个检测器接口,并采用了几种更加完备的策略来检测文件类型。
//org.apache.tika.detect.Detector
MediaType detect(InputStream stream, Metadata metadata) throws IOException;
文件类型检测机制
- 文件名检测 - 简单地根据文件后缀名判断文件类型。
- 魔术字检测 - 有些文件格式会将文件最开始的几个字节设置会特定的模式,通过这些特殊的字节模式,可以判断文件类型。
- 容器格式检测 - 有些文件格式是一种容器格式,这一类文件无法通过魔术字判断出文件类型,需要对容器内的数据做更多的分析,如微软Office文档(.docx, .xlsx, .pptx)这些文档实际上都是zip压缩文件,魔术字是一样的。
容器格式检测耗时比较长,最坏的情况下需要读取整个文件
文件类型的检测顺序
容器格式检测(OLE2ContainerDetector, ZipContainerDetector......)=>
魔术字检测(MimeTypes)=>
文件名检测(MimeTypes)
MimeTypes底层实际使用了NameDetector和MagicDetector
解析器
Parser是tika的核心概念,它隐藏了不同文件格式和解析库的复杂性,为客户端程序提供了一个简单而强大的机制,用来从各种各样的文档中提取元数据和结构化文本内容。tika提供了很多解析器,用来对各种各种的文件类型进行处理,如针对微软Office文档的OfficeParser,针对Adobe PDF文档的PDFParser,针对压缩文件的CompressorParser,针对归档文件的PackageParser,还有一些特殊的Parser,如TesseractOCRParser,用来对图片进行OCR内容提取
如果服务器安装了tesseract,那么TesseractOCRParser就会被启用,在实时分析系统中,TesseractOCRParser的性能是不可接受的,建议手动禁用掉
void parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException;
接口说明
| 参数 | 说明 |
|---|---|
| InputStream | 待解析的文档,以字节流形式传入,可以避免tika占用太多内存 |
| ContentHandler | 内容处理器,用来收集结果,Tika会将解析结果包装成XHTML SAX event进行分发,通过ContentHandler处理这些event就可以得到文本内容和其他有用的信息 |
| Metadata | 元数据,既是输入也是输出,可以将文件名或者可能的文件类型传入,tika解析时可以根据这些信息判断文件类型,再调用相应的解析器进行处理;另外,tika也会将一些额外的信息保存到Metadata中,如文件修改日期,作者,编辑工具等 |
| ParseContext | 解析上下文,用来控制解析过程,比如是否提取Office文档里面的宏等 |
扩展机制
- 定义Mimetype(可选,如果需要处理一些特殊文件,它们的文件类型tika目前并不支持,就需要自定义Mimetype)
- 实现Parser,可以针对tika已有的文件类型编写自己的解析器,也可以创建支持新的文件类型的解析器
- 注册Parser,通过SPI机制可以轻松地将自己的解析器放进tika的解析器库里(CompositeParser)
- 在类路径下创建文件 - META-INF/services/org.apache.tika.parser.Parser
- 文件内容就是自定义的Parser的全路径类名
其他tika组件(如类型检测器,翻译器,语言检测器等)也使用该机制进行扩展
注意事项
配置
tika在启动时可以加载一个配置文件,通过这个文件可以对tika-core的各个组件进行配置,可以配置Parser,Detector,Mimetype, ServiceLoader......
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<detector class="org.apache.tika.detect.DefaultDetector">
<detector-exclude class="org.apache.tika.parser.pkg.ZipContainerDetector"/>
<detector-exclude class="org.apache.tika.parser.microsoft.POIFSContainerDetector"/>
</detector>
<parsers>
<!-- Default Parser for most things, except for 2 mime types, and never use the Executable Parser -->
<parser class="org.apache.tika.parser.DefaultParser">
<mime-exclude>image/jpeg</mime-exclude>
<mime-exclude>application/pdf</mime-exclude>
<parser-exclude class="org.apache.tika.parser.executable.ExecutableParser"/>
</parser>
<!-- Use a different parser for PDF -->
<parser class="org.apache.tika.parser.EmptyParser">
<mime>application/pdf</mime>
</parser>
</parsers>
</properties>
安全问题
tika设计了一个扩展性很好的解析器框架,但是具体的解析任务交给了外部的各种开源工具,因此也带来了很多安全问题,在实际使用中推荐使用最新版本的类库。
!!! 另外,tika有线程死锁的问题,可能导致服务器CPU资源耗尽,建议在容器(如docker)里运行,或者使用tika-server
图像,音频,视频
tika可以从图像,音频,视频文件中提取元数据,但是几乎无法提取出任何有价值的文本内容,在大多数场景下建议禁用这些类型的Parser
针对图像,可以使用TesseractOCRParser进行OCR操作,这需要服务器安装了tesseract,OCR的效率很低,普通文件的解析一般在几十毫秒左右,OCR的耗时约为几秒钟;而且OCR的结果依赖于算法模型的训练,需要整理出合适,足够的样本,工作量比较多。
解析时间跟文件大小和服务器性能有关系,数据来自对8M以下互联网文件的解析
文件修复
tika可以在解析时对文件进行一定程度的修复
比如,ZipSalvager可以对基于ZipContainer格式的文件进行修复
为了将解析耗时控制在一定范围内,不得不对大文件进行截断
提取其他信息
tika的解析逻辑默认只会保留元数据(Metadata)和文本(Text),如果对其他信息感兴趣,就需要对ContentHandler进行定制
tika提供了很多有用的ContentHandler,
比如ToXMLContentHandler将以XML形式输出文件的文本内容,
WriteLimitContentHandler可以在解析得到一定字符数的结果后,中断解析过程(抛出异常),
LinkContentHandler可以收集文件内容中的超链接,
PhoneContentHandler可以收集文件内容中的电话号码。
提取压缩文件里的文件名
默认配置下,tika解析压缩文件(.gz, .bzip2等)和归档文件(.zip, .tar, .7z等)时,文件名会和文件内容杂糅在一起,如果需要区分开,可以自定义一个ContentHandler对class="embedded"的XHTML SAX event进行处理
Tika对压缩文件内文件名的提取实现不完整,遇到特殊情况建议手动处理,重写Parser
提取图片
某些文件(主要是容器文件格式)内部可能含有其他内嵌文件,如压缩文件,Word文档,PDF文档等,tika可以递归处理压缩文件内部的子文件,但是除此之外没有提供别的处理方法。
如果想要提取微软Office文档或者PDF文档内的图片,建议在tika的解析器框架下自己实现Parser,将图片写入的逻辑加上;或者直接使用具体的解析库额外处理(比如使用Apache POI可以很方便的提取微软Office文档里的图片)
tika的局限性
tika支持上千种文件类型,并且提供了统一的接口,非常容易上手;但是有些文件格式非常复杂,可能会出现支持不完善的情况,如对压缩文件的解析依赖commons-compress,但是commons-compress对压缩文件的支持就不完整,所以tika在处理某些文件时无法得到有用信息
tika的性能
tika的解析器本质上是一个适配器,底层使用了很多第三方开源工具来实现具体的内容解析,因此tika的解析效率也跟这些工具有关
对某个具体文件来说,解析耗时主要跟文件大小,文件格式的复杂程度,压缩算法,服务器性能等关系较大
实时系统中最好限制一下文件大小,推荐在离线环境中使用
简单使用
tika是一个工具集,包括类库,cli,gui,rest服务等,如何使用需要根据具体场景进行选择。以下给出了tika作为类库使用时的一些demo,更多的例子可以参考http://tika.apache.org/1.24.1/examples.html
- 引入依赖
pom.xml
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.24.1</version>
</dependency>
//Parsing using the Tika Facade
public String parseToStringExample() throws IOException, SAXException, TikaException {
Tika tika = new Tika();
try (InputStream stream = ParsingExample.class.getResourceAsStream("test.doc")) {
return tika.parseToString(stream);
}
}
//Parsing using the Auto-Detect Parser
public String parseExample() throws IOException, SAXException, TikaException {
AutoDetectParser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
try (InputStream stream = ParsingExample.class.getResourceAsStream("test.doc")) {
parser.parse(stream, handler, metadata);
return handler.toString();
}
}
//Picking different output formats
public String parseToPlainText() throws IOException, SAXException, TikaException {
BodyContentHandler handler = new BodyContentHandler();
AutoDetectParser parser = new AutoDetectParser();
Metadata metadata = new Metadata();
try (InputStream stream = ContentHandlerExample.class.getResourceAsStream("test.doc")) {
parser.parse(stream, handler, metadata);
return handler.toString();
}
}
参考
- 白宁超 - Tika常见格式文件抽取内容并做预处理
- Tika官方文档
Apache Tika实战的更多相关文章
- 1.6.3 Uploading Data with Solr Cell using Apache Tika
1. Uploading Data with Solr Cell using Apache Tika solr使用Apache Tika工程的代码提供了一个框架,用于合并所有不同格式的文件解析器为so ...
- DataPipeline |《Apache Kafka实战》作者胡夕:Apache Kafka监控与调优
胡夕 <Apache Kafka实战>作者,北航计算机硕士毕业,现任某互金公司计算平台总监,曾就职于IBM.搜狗.微博等公司.国内活跃的Kafka代码贡献者. 前言 虽然目前Apache ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- 《Apache kafka实战》读书笔记-kafka集群监控工具
<Apache kafka实战>读书笔记-kafka集群监控工具 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如官网所述,Kafka使用基于yammer metric ...
- 《Apache Kafka实战》读书笔记-调优Kafka集群
<Apache Kafka实战>读书笔记-调优Kafka集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.确定调优目标 1>.常见的非功能性要求 一.性能( ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
- 【apache tika】apache tika获取文件内容(与FileUtils的对比)
Tika支持多种功能: 文档类型检测 内容提取 元数据提取 语言检测 重要特点: 统一解析器接口:Tika封装在一个单一的解析器接口的第三方解析器库.由于这个特征,用户逸出从选择合适的解析器库的负担, ...
- Apache CXF实战之四 构建RESTful Web Service
Apache CXF实战之一 Hello World Web Service Apache CXF实战之二 集成Sping与Web容器 Apache CXF实战之三 传输Java对象 这篇文章介绍一下 ...
随机推荐
- ajax模拟表单提交,后台使用npoi实现导入操作 方式一
页面代码: <form id="form1" enctype="multipart/form-data"> <div style=" ...
- [转] Java Agent使用详解
以下文章来源于古时的风筝 ,作者古时的风筝 我们平时写 Java Agent 的机会确实不多,也可以说几乎用不着.但其实我们一直在用它,而且接触的机会非常多.下面这些技术都使用了 Java Agent ...
- IDEA生成MyBatis文件
IDEA 逆向 MyBatis 工程时,不像支持 Hibernate 那样有自带插件,需要集成第三方的 MyBatis Generator. MyBatis Generator的详细介绍 http:/ ...
- Neo4j 的使用说明(二)
上一篇: https://www.cnblogs.com/infoo/p/9840965.html 阅读量挺多的,因此继续写一下(二) 在上一篇说到:(版本依然基于V3.4.9) 如果为了方便更改d ...
- SeaweedFS在.net core下的实践方案
一直对分布式的文件储存系统很感兴趣,最开始关注淘宝的TFS(Taobao File System),好像搁浅了,官方地址无法访问,github上面,各种编译问题,无意间发现了SeaweedFS 链接s ...
- markdown公式指导手册
#Cmd Markdown 公式指导手册 标签: Tutorial 转载于https://www.zybuluo.com/codeep/note/163962#1%E5%A6%82%E4%BD%95% ...
- Nginx - location常见配置指令,alias、root、proxy_pass
1.[alias]——别名配置,用于访问文件系统,在匹配到location配置的URL路径后,指向[alias]配置的路径.如: location /test/ { alias/first/secon ...
- python 正则表达式与JSON-正则表达式匹配数字、非数字、字符、非字符、贪婪模式、非贪婪模式、匹配次数指定等
1.正则表达式:目的是为了爬虫,是爬虫利器. 正则表达式是用来做字符串匹配的,比如检测是不是电话.是不是email.是不是ip地址之类的 2.JSON:外部数据交流的主流格式. 3.正则表达式的使用 ...
- C#LeetCode刷题-队列
队列篇 # 题名 刷题 通过率 难度 363 矩形区域不超过 K 的最大数值和 27.2% 困难 621 任务调度器 40.9% 中等 622 设计循环队列 C#LeetCode刷题之#622 ...
- C#LeetCode刷题之#852-山脉数组的峰顶索引(Peak Index in a Mountain Array)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4003 访问. 我们把符合下列属性的数组 A 称作山脉: A.le ...