MySQL在按照某个字段分组、排序加序号
事情是这样的,最近领导给了一个新的需求,要求在一张订单表中统计每个人第一次和第二次购买的时间间隔,最后还需要按照间隔统计计数,求出中位数等数据。
- 由于MySQL不想Oracle那般支持行号、中位数等,所以怎么在表中统计处数据成为了关键
订单表结构,主要包含字段如下
- id、订单号、购买人id、下单时间、商品信息字段、购买人信息字段等
1.为了方便后续统计,我的想法是构建了一张中间表,只存储一些关键字段,如购买人id,下单时间,订单号,以及购买的第几次,结构如下图:

字段解释:fans_id:购买人id、order_time:下单时间、tid:订单号、series:商品系列、shop:店铺、times:第几次购买、sync_time:同步时间、effective:是否有效、failure_time:失效时间
2.写了一段代码,处理历史订单,把所有数据按照表中格式添加进去,方便统计,每次新订单进来时,更新一下这个表即可。
3.统计:
-- 统计购买次数最大和最小
select max(times) from 统计表 where effective = '有效'
-- 统计最大购买次数间隔、最小间隔以及平均间隔(中位数的话,由于MySQL没有中位数函数,所以可以利用子查询的SQL通过程序代码计算)
SELECT
max(date) as max,
min(date) as min,
sum( date * mans ) / count( mans ) as avg
FROM
(
SELECT
ifnull(datediff( a.order_time, ( SELECT order_time FROM 统计表 WHERE times = 次数1 AND effective = '有效' AND a.fans_id = fans_id ) ),0) AS date,
a.fans_id,
1 AS mans
FROM
统计表 a
WHERE
a.times = 次数2 AND effective = '有效'
) t
4.由于接收订单后,可能状态会变,无法确保次数准确,更新统计表中每个人的次数SQL如下:
UPDATE
(SELECT @rownum:=@rownum+1 as rn,id,fans_id,order_time from
(SELECT id,fans_id,order_time from
统计表 where fans_id = 购买人 and effective = '有效'
ORDER BY order_time asc) h,
(SELECT @rownum:=0) t) t1,
statistics_repurchase t2
set t2.times=t1.rn where t2.id=t1.id;
5.由于需求还需要支持按照商品系列查询,所以需要在该表基础之上建立临时表以作统计,满足MySQL在按照某个字段分组、排序加序号
第一版SQL如下:
SELECT
a.fans_id,
a.order_time,
a.sync_time,
count( * ) AS times
FROM
统计表 AS a,
统计表 AS b
WHERE
a.fans_id = b.fans_id
AND a.order_time >= b.order_time
AND a.effective = '有效'
AND b.effective = '有效'
AND a.series LIKE concat('%','系列','%')
AND b.series LIKE concat('%','系列','%')
GROUP BY
a.fans_id,
a.id
-- 按照购买人id,按照购买时间进行排序,并标记序号,加上创建表语句如下(建表时需加索引,方便后续查找):
CREATE TABLE 临时表名 (
id INT PRIMARY KEY AUTO_INCREMENT,
fans_id VARCHAR ( 32 ),
order_time datetime,
sync_time date,
times INT ( 6 ),
PRIMARY KEY ( id ),
INDEX mid_fans_id ( fans_id ) USING BTREE,
INDEX mid_order_time ( order_time ) USING BTREE,
INDEX mid_times ( times ) USING BTREE,
INDEX mid_sync_time ( sync_time ) USING BTREE
)
AS
(
SELECT
a.fans_id,
a.order_time,
a.sync_time,
count( * ) AS times
FROM
统计表 AS a,
统计表 AS b
WHERE
a.fans_id = b.fans_id
AND a.order_time >= b.order_time
AND a.effective = '有效'
AND b.effective = '有效'
AND a.series LIKE concat('%','系列','%')
AND b.series LIKE concat('%','系列','%')
GROUP BY
a.fans_id,
a.id
);
-- 由于数据库版本为5.4,所以建完临时表不支持一条sql多次查询,没办法,只能直接创建表
结果如图:
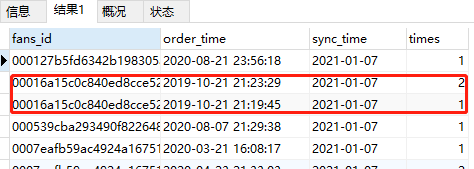
满足了排序,但是后来我发现有一些人是同时间下单的,以至于某些人的times是重复的,于是更新为下面的SQL
SELECT
a.fans_id,
a.order_time,
a.sync_time,
( @i := CASE WHEN @pre_keyword = fans_id THEN @i + 1 ELSE 1 END ) AS times,
@pre_keyword:=fans_id
FROM
( SELECT fans_id, order_time, sync_time FROM 统计表 WHERE effective = '有效' AND series LIKE concat('%','系列','%') ORDER BY fans_id,order_time ) a,
( SELECT @i := 0, @pre_keyword := '' ) AS b
这次的sql是按照时间排序后,判断当前购买人第几次出现,打上序号,由此满足需求
查询结果和上图相同,就不附图了哈
效率这,购买人id,下单时间需要创建索引,否则可能有些慢,测试库中数据大概七百万左右,总体查询可在四秒内完成
希望这篇文章能在开发中给予您一定的帮助,新人博客主,码龄一年,如有更好的方案,望指教!
MySQL在按照某个字段分组、排序加序号的更多相关文章
- mysql分组排序加序号(不用存储过程,就简简单单sql语句哦)
做前端好长时间了,好久没动sql了.在追一个喜欢的女孩,做测试的,有这么个需求求助与本屌丝,机会难得,开始折腾起来,配置mysql,建库,建表.... 一 建表 CREATE TABLE `my_te ...
- mysql分组排序加序号
参照https://www.cnblogs.com/CharlieLau/p/6737243.html 一.需求 新加一个Sort 字段,初始值为1,按照parentID分组添加sort值. 根据原数 ...
- mysql按某一字段分组取最大(小)值所在行的数据
mysql按某一字段分组取最大(小)值所在行的数据 mysql技巧--按某一字段分组取最大(小)值所在行的数据,这是mysql数据库程序员经常用到的在处理一些报表数据时候可以活用!那么猎微网将总结 ...
- MySQL使用用户变量更新分组排序
第一个需求是根据A字段进行排序,排序结果更新到B字段 简单搜索之后,很快得到答案 http://dev.mysql.com/doc/refman/5.7/en/update.html ; ) ORDE ...
- MySQL进阶5--分组函数 / 分组排序和分组查询 group by(having) /order by
MySQL进阶--分组排序和分组查询 group by(having) /order by /* 介绍分组函数 功能:用做统计使用,又称为聚合函数或组函数 1.分类: sum, avg 求和 /平均数 ...
- sql多字段分组排序显示全部数据
建表sql CREATE TABLE `tbl_demo` ( `id` ) COLLATE utf8_bin NOT NULL, `payer_name` ) COLLATE utf8_bin DE ...
- Linux sort 多字段分组排序
常用参数: -t: 指定分隔符 -k: 指定域 -u: 去除重复行 -n: 以数值排序 -r: 降序排序 (sort默认的排序方式是升序) -o: 结果重定向输出到文件 1.源文件: # cat hh ...
- mysql语句求按字段分组后组数是多少
select count(distinct ID) from table Thinkphp CURD写 $count = $model->where($where)->count('dis ...
- 【MySQL作业】多字段分组和 having 子句——美和易思分组查询应用习题
点击打开所使用到的数据库>>> 1.按照商品类型和销售地区分组统计商品数量和平均单价,并按平均单价升序显示. -- 按照商品类型和销售地区分组统计商品数量和平均单价,并按平均单价升序 ...
随机推荐
- scrapy爬虫爬取小姐姐图片(不羞涩)
这个爬虫主要学习scrapy的item Pipeline 是时候搬出这张图了: 当我们要使用item Pipeline的时候,要现在settings里面取消这几行的注释 我们可以自定义Item Pip ...
- Android10_原理机制系列_Window介绍及WMS的启动过程
简介 Window简介 Android中,Window是一个重要部分,用户看到的界面.触摸显示界面进行一系列操作都涉及到Window.但实际上,Window本身并不具备绘制功能. 该篇简单介绍下Win ...
- Oracle批量新增数据最佳实践
一.需求描述 现在的项目改造过程中,从国产的Gbase数据库改造为Oracle数据库,遇到一个问题有的业务操作需要批量新增数据. 这也是一个比较常规的操作,有很多地方确实需要一次性新增多条数据.Gba ...
- 【题解】P1852 跳跳棋
link 题意 跳跳棋是在一条数轴上进行的.棋子只能摆在整点上.每个点不能摆超过一个棋子.棋盘上有3颗棋子,分别在 \(a,b,c\) 这三个位置.我们要通过最少的跳动把他们的位置移动成 \(x,y, ...
- P5838 [USACO19DEC]Milk Visits G
发现是一道比较裸的树上莫队,于是就开始刚,然后发现好像是最难的一道题--(本题解用于作者加深算法理解,也欢迎各位的阅读) 题意 给你一棵树,树有点权,询问一条路径上是否有点权为 \(c\) 的点. 题 ...
- PHP表白墙网站源码
PHP表白墙网站源码,可以做校园内的,也可以做校区间的,可封装成APP.告别QQ空间的表白墙吧. 安装简单,上传程序安装,然后设置账号密码,登陆后台切换模板手机PC都要换开启插件访问前台. 安装完成后 ...
- 基于menu小插件探索工程实践
目录 一.准备工作 1.C/C++环境搭建 2.VSCode的配置 (1) 安装插件: (2) 设置配置文件: 二.工程化编程实战 1.模块化设计 2.可重用设计:进一步抽象 menu的进一步优化 可 ...
- mac下git连接远程仓库gitee
一.注册账号 https://gitee.com/ 二.创建仓库 三.创建后显示如下 四.根据页面上展示命令敲一遍就可以了. 备注:注意!!
- Day7 python高级特性-- 切片 Slice
先举一个例子,取list或tuple中的某几个元素: 1.取 ['a','b','c','d','e','f'] 第1.2.5.6个元素: >>> a = [' ...
- TLS 协议
一.背景 参与了一个Sofa-RPC开源项目,认领了TLS的任务,记录下这次宝贵的经历,并感谢章哥的信任以及在整个过程中对我的帮助. 负责的部分不难,主要是使用h2(HTTP 2加密)协议,完成RPC ...