一招教你如何在Python中使用Torchmoji将文本转换为表情符号
很难找到关于如何使用Python使用DeepMoji的教程。我已经尝试了几次,后来又出现了几次错误,于是决定使用替代版本:torchMoji。
TorchMoji是DeepMoji的pyTorch实现,可以在这里找到:https://github.com/huggingface/torchMoji

事实上,我还没有找到一个关于如何将文本转换为表情符号的教程。如果你也没找到,那么本文就是一个了。
安装
这些代码并不完全是我的写的,源代码可以在这个链接上找到。
!pip3 install torch==1.0.1 -f https://download.pytorch.org/whl/cpu/stable
!git clone https://github.com/huggingface/torchMoji
import os
os.chdir('torchMoji')
!pip3 install -e .
#if you restart the package, the notebook risks to crash on a loop
#I did not restart and worked fine
该代码将下载约600 MB的数据用于训练人工智能。我一直在用谷歌Colab。然而,我注意到,当程序要求您重新启动笔记本进行所需的更改时,它开始在循环中崩溃并且无法补救。如果你使用的是jupyter notebook或者colab记事本不要重新,不管它的重启要求就可以了。
!python3 scripts/download_weights.py
这个脚本应该下载需要微调神经网络模型。询问时,按“是”确认。
设置转换功能函数
使用以下函数,可以输入文进行转换,该函数将输出最可能的n个表情符号(n将被指定)。
import numpy as np
import emoji, json
from torchmoji.global_variables import PRETRAINED_PATH, VOCAB_PATH
from torchmoji.sentence_tokenizer import SentenceTokenizer
from torchmoji.model_def import torchmoji_emojis EMOJIS = ":joy: :unamused: :weary: :sob: :heart_eyes: :pensive: :ok_hand: :blush: :heart: :smirk: :grin: :notes: :flushed: :100: :sleeping: :relieved: :relaxed: :raised_hands: :two_hearts: :expressionless: :sweat_smile: :pray: :confused: :kissing_heart: :heartbeat: :neutral_face: :information_desk_person: :disappointed: :see_no_evil: :tired_face: :v: :sunglasses: :rage: :thumbsup: :cry: :sleepy: :yum: :triumph: :hand: :mask: :clap: :eyes: :gun: :persevere: :smiling_imp: :sweat: :broken_heart: :yellow_heart: :musical_note: :speak_no_evil: :wink: :skull: :confounded: :smile: :stuck_out_tongue_winking_eye: :angry: :no_good: :muscle: :facepunch: :purple_heart: :sparkling_heart: :blue_heart: :grimacing: :sparkles:".split(' ')
model = torchmoji_emojis(PRETRAINED_PATH)
with open(VOCAB_PATH, 'r') as f:
vocabulary = json.load(f)
st = SentenceTokenizer(vocabulary, 30)def deepmojify(sentence,top_n =5):
def top_elements(array, k):
ind = np.argpartition(array, -k)[-k:]
return ind[np.argsort(array[ind])][::-1]tokenized, _, _ = st.tokenize_sentences([sentence])
prob = model(tokenized)[0]
emoji_ids = top_elements(prob, top_n)
emojis = map(lambda x: EMOJIS[x], emoji_ids)
return emoji.emojize(f"{sentence} {' '.join(emojis)}", use_aliases=True)
文本实验
text = ['I hate coding AI']for _ in text:
print(deepmojify(_, top_n = 3))
输出

如您所见,这里给出的是个列表,所以可以添加所需的字符串数。
原始神经网络
如果你不知道如何编码,你只想试一试,你可以使用DeepMoji的网站:https://deepmoji.mit.edu/

源代码应该完全相同,事实上,如果我输入5个表情符号而不是3个,这就是我代码中的结果:

如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,
帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,
又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,
想转行怕学不会的,都可以加入我们644956177。
群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
输入列表而不是一句话
在进行情绪分析时,我通常会在Pandas上存储tweets或评论的数据库,我将使用以下代码,将字符串列表转换为Pandas数据帧,其中包含指定数量的emojis。
import pandas as pddef emoji_dataset(list1, n_emoji=3):
emoji_list = [[x] for x in list1]for _ in range(len(list1)):
for n_emo in range(1, n_emoji+1):
emoji_list[_].append(deepmojify(list1[_], top_n = n_emoji)[2*-n_emo+1])emoji_list = pd.DataFrame(emoji_list)
return emoji_listlist1 = ['Stay safe from the virus', 'Push until you break!', 'If it does not challenge you, it will not change you']
我想估计一下这个字符串列表中最有可能出现的5种表情:
emoji_dataset(list1, 5)
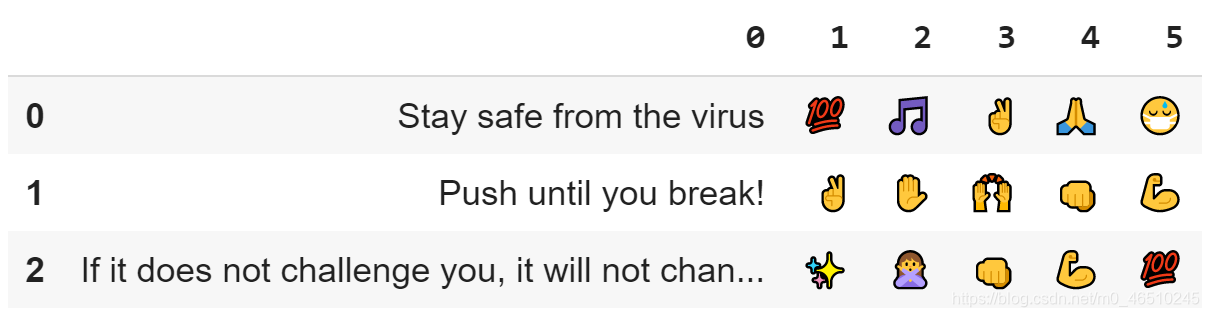
就是这么简单
一招教你如何在Python中使用Torchmoji将文本转换为表情符号的更多相关文章
- 手摸手教你如何在 Python 编码中做到小细节大优化
手摸手教你如何在 Python 编码中做到小细节大优化 在列表里计数 """ 在列表里计数,使用 Python 原生函数计数要快很多,所以尽量使用原生函数来计算. &qu ...
- 如何在Python中从零开始实现随机森林
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 决策树可能会受到高度变异的影响,使得结果对所使用的特定测试数据而言变得脆弱. 根据您的测试数据样本构建多个模型(称为套袋)可以减少这种差异,但是 ...
- 如何在Python中快速画图——使用Jupyter notebook的魔法函数(magic function)matplotlib inline
如何在Python中快速画图--使用Jupyter notebook的魔法函数(magic function)matplotlib inline 先展示一段相关的代码: #we test the ac ...
- 如何在Python中使用Linux epoll
如何在Python中使用Linux epoll 内容 介绍 阻塞套接字编程示例 异步套接字和Linux epoll的好处 epoll的异步套接字编程示例 性能考量 源代码 介绍 从2.6版开始,Pyt ...
- 如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释
如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释 PIP $ pip install beauti ...
- 面试官问我:如何在 Python 中解析和修改 XML
摘要:我们经常需要解析用不同语言编写的数据.Python提供了许多库来解析或拆分用其他语言编写的数据.在此 Python XML 解析器教程中,您将学习如何使用 Python 解析 XML. 本文分享 ...
- 如何在Python中加速信号处理
如何在Python中加速信号处理 This post is the eighth installment of the series of articles on the RAPIDS ecosyst ...
- 如何在Word中批量选中特定文本
如何在Word中批量选中特定文本 举个例子,我们对如下文本进行操作,将文本中所有的“1111111”标红,所有的“2222222”标绿,所有的“3333333”标蓝 在Word中找到“查找”下的“高级 ...
- 如何在python中使用Elasticsearch
什么是 Elasticsearch 想查数据就免不了搜索,搜索就离不开搜索引擎,百度.谷歌都是一个非常庞大复杂的搜索引擎,他们几乎索引了互联网上开放的所有网页和数据.然而对于我们自己的业务数据来说 ...
随机推荐
- Mysql基础(四):库、表、记录的详细操作、单表查询
目录 数据库03 /库.表.记录的详细操作.单表查询 1. 库的详细操作 3. 表的详细操作 4. 行(记录)的详细操作 5. 单表查询 数据库03 /库.表.记录的详细操作.单表查询 1. 库的详细 ...
- Python之爬虫(二十二) Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- OSCP Learning Notes - Capstone(3)
DroopyCTF Walkthrough Preparation: Download the DroopyCTF virtual machine from the following website ...
- python基础算法
一.简介 定义和特征 定义:算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时 ...
- 图灵学院笔记-java虚拟机底层原理
Table of Contents generated with DocToc 一.java虚拟机概述 二.栈内存解析 2.1 概述 2.2 栈帧内部结构 2.2.1 我们来解析一下compute() ...
- 利用华为eNSP模拟器实现vlan之间的通信
eNSP交换机配置VLAN 1. 搭建网络拓扑结构 运行eNSP>新建拓扑>搭建如下图的拓扑结构>启动设备.利用调色板将划分的vlan进行区分. 2. pc机IP地址配置 pc1的I ...
- React Native 报错 Error: spawn EACCES 权限
权限不足,运行命令修改权限 chmod android/gradlew
- DNA Consensus String UVA - 1368
题目链接:https://vjudge.net/problem/UVA-1368 题意:给出一组字符串,求出一组串,使与其他不同的点的和最小 题解:这个题就是一个点一个点求,利用桶排序,求出最多点数目 ...
- 多个activity的博客参考,用mainactivity 调用 明天阅读一下
https://blog.csdn.net/hbwxy521/article/details/53101019
- Redis简介与部署
一.简介 Redis是什么?redis是一款基于BSD协议,开源的非关系型数据库(nosql数据库),作者是意大利开发者Salvatore Sanfilippo在2009年发布,使用C语言编写:red ...