Storm的并行度、Grouping策略以及消息可靠处理机制简介
转自:https://my.oschina.net/zc741520/blog/409949
概念:
Workers (JVMs): 在一个节点上可以运行一个或多个独立的JVM 进程。一个Topology可以包含一个或多个worker(并行的跑在不同的machine上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
Executors (threads): 在一个worker
JVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。一个worker可以包含一个或多个executor,
每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集,
同时一个executor只能对应于一个component。
Tasks(bolt/spout
instances):Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。每一个task对应到一个线程,而stream
grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder.setSpout和TopBuilder.setBolt来设置并行度
— 也就是有多少个task。
配置并行度
对于并发度的配置, 在storm里面可以在多个地方进行配置,
优先级为:defaults.yaml < storm.yaml < topology-specific configuration
< internal component-specific configuration < external
component-specific configuration
worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目
executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数), 例如, setBolt("green-bolt", new GreenBolt(), 2)
tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过 storm rebalance 命令任意调整。
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout"); //set tasks number to 4
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6).shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());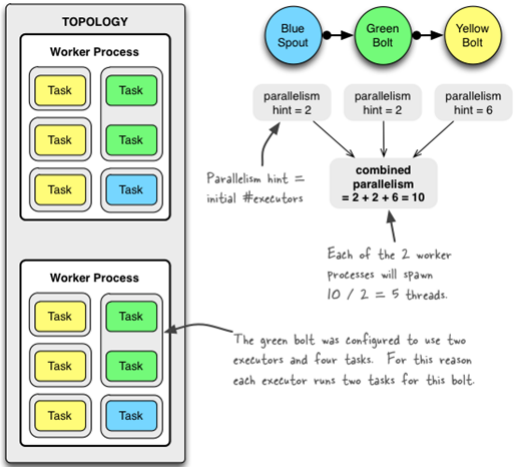
动态的改变并行度
Storm支持在不 restart topology 的情况下, 动态的改变(增减) worker processes 的数目和 executors 的数目, 称为rebalancing. 通过Storm web UI,或者通过storm rebalance命令实现:
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10流分组策略----Stream Grouping
Stream Grouping,告诉topology如何在两个组件之间发送tuple
定义一个topology的其中一步是定义每个bolt接收什么样的流作为输入。stream grouping就是用来定义一个stream应该如果分配数据给bolts上面的多个tasks
Storm里面有7种类型的stream grouping,你也可以通过实现CustomStreamGrouping接口来实现自定义流分组
1. Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
2. Fields Grouping
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
3. All Grouping
广播发送,对亍每一个tuple,所有的bolts都会收到
4. Global Grouping
全局分组,整个stream被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
5. None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果,
有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(如果可能的话)。
6. Direct Grouping
指向型分组,
这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct
Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过
TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致。
消息的可靠处理机制
在storm中,可靠的信息处理机制是从spout开始的。一个提供了可靠的处理机制的spout需要记录他发射出去的tuple,当下游bolt处理tuple或者子tuple失败时spout能够重新发射。
Storm通过调用Spout的nextTuple()发送一个tuple。为实现可靠的消息处理,首先要给每个发出的tuple带上唯一的ID,并且将ID作为参数传递给SoputOutputCollector的emit()方法:collector.emit(new
Values("value1","value2"), msgId);
给tuple指定ID告诉Storm系统,无论处理成功还是失败,spout都要接收tuple树上所有节点返回的通知。如果处理成功,spout的ack()方法将会对编号是msgId的消息应答确认;如果处理失败或者超时,会调用fail()方法。
bolt要实现可靠的信息处理机制包含两个步骤:1.当发射衍生的tuple时,需要锚定读入的tuple;2.当处理消息成功或失败时分别确认应答或者报错。
锚定一个tuple的意思是,建立读入tuple和衍生出的tuple之间的对应关系,这样下游的bolt就可以通过应答确认、报错或超时来加入到tuple树结构中。可以通过调用OutputCollector的emit()的一个重载函数锚定一个或一组tuple:collector.emit(tuple,
new Values(word))
非锚定(collector.emit(new Values(word));)的tuple不会对数据流的可靠性起作用。如果一个非锚定的tuple在下游处理失败,原始的根tuple不会重新发送。
超时时间可以通过任务级参数Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS进行配置,默认超时值为30秒。
Storm
系统中有一组叫做"acker"的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。acker任务保存了spout消息id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为"ack
val", 它是树中所有消息的随机id的异或计算结果。ack
val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。
每当acker发现一棵树的ack
val值为0的时候,它就知道这棵树已经被完全处理了。因为消息的随机ID是一个64bit的值,因此ack
val在树处理完之前被置为0的概率非常小。假设你每秒钟发送一万个消息,从概率上说,至少需要50,000,000年才会有机会发生一次错误。即使如此,也只有在这个消息确实处理失败的情况下才会有数据的丢失!
有三种方法可以去掉消息的可靠性:
1、将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用;
2、Spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法;
3、最后,如果你不在意某个消息派生出来的子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。
Storm的并行度、Grouping策略以及消息可靠处理机制简介的更多相关文章
- Storm-6 Storm的并行度、Grouping策略以及消息可靠处理机制简介
概念: 配置并行度 动态的改变并行度 流分组策略----Stream Grouping 消息的可靠处理机制 概念: Workers (JVMs): 在一个节点上可以运行一个或多个独立的JVM 进程.一 ...
- Storm消息可靠处理机制
在很多应用场景中,分布式系统的可靠性保障尤其重要.比如电商平台中,客户的购买请求需要可靠处理,不能因为节点故障等原因丢失请求:比如告警系统中,产生的核心告警必须及时完整的知会监控人员,不能因为网络故障 ...
- storm入门教程 第四章 消息的可靠处理【转】
4.1 简介 storm可以确保spout发送出来的每个消息都会被完整的处理.本章将会描述storm体系是如何达到这个目标的,并将会详述开发者应该如何使用storm的这些机制来实现数据的可靠处理. 4 ...
- Storm消息可靠机制
一:介绍 1.介绍 默认情况是,Spout每获取一条数据,封装后发送给后面的组件,不再管后面是否处理完成或成功接收,不再考虑. 这种的情况是不用太精确,没有启用可靠性消息机制. 2.方面的体现 spo ...
- IM消息送达保证机制实现(二):保证离线消息的可靠投递
1.前言 本文的上篇<IM消息送达保证机制实现(一):保证在线实时消息的可靠投递>中,我们讨论了在线实时消息的投递可以通过应用层的确认.发送方的超时重传.接收方的去重等手段来保证业务层面消 ...
- 简单聊聊Storm的流分组策略
简单聊聊Storm的流分组策略 首先我要强调的是,Storm的分组策略对结果有着直接的影响,不同的分组的结果一定是不一样的.其次,不同的分组策略对资源的利用也是有着非常大的不同,本文主要讲一讲loca ...
- #研发中间件介绍#异步消息可靠推送Notify
郑昀 基于朱传志的设计文档 最后更新于2014/11/11 关键词:异步消息.订阅者集群.可伸缩.Push模式.Pull模式 本文档适用人员:研发 电商系统为什么需要 NotifyServer? ...
- Storm概念学习系列之并行度与如何提高storm的并行度
不多说,直接上干货! 对于storm来说,并行度的概念非常重要!大家一定要好好理解和消化. storm的并行度,可以简单的理解为多线程. 如何提高storm的并行度? storm程序主要由spout和 ...
- 【RabbitMQ】如何进行消息可靠投递【上篇】
说明 前几天,突然发生线上报警,钉钉连发了好几条消息,一看是RabbitMQ相关的消息,心头一紧,难道翻车了? [橙色报警] 应用[xxx]在[08-15 16:36:04]发生[错误日志异常],al ...
随机推荐
- LeetCode:螺旋矩阵【54】
LeetCode:螺旋矩阵[54] 题目描述 给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素. 示例 1: 输入: [ [ 1, 2, 3 ], ...
- java多线程笔记
一,线程的状态 1,新建状态:新创建了一个线程对象 2,就绪状态:线程创建对象后,线程调用star()的方法,等待获取CPU的使用权. 3,运行状态:获取了cpu的使用权,执行程序代码 4,阻塞状态: ...
- Linux Shell基础 Bash常见命令 history、alias命令以及常用快捷键
概述 shell中常见命令history 历史纪录命令:history 命令格式如下: [root@localhost ~]# history [选项] [历史命令保存文件] -c:清空历史命令: ...
- EGLImage与纹理
http://blog.csdn.net/sunnytina/article/details/51895406 Android使用Direct Textures提高glReadPixels.glTex ...
- poj 3414 Pots【bfs+回溯路径 正向输出】
题目地址:http://poj.org/problem?id=3414 Pots Time Limit: 1000MS Memory Limit: 65536K Total Submissions ...
- win10打不开菜单且点击通知栏无反应的解决方法
1.在键盘上按下win+R键,或在开始菜单图标上点击右键选择"运行" 2.输入powershell,按下“确定”运行 3.在窗口里输入或复制粘贴以下命令,注意只有一行: Get-A ...
- JS,Jquery获取屏幕的宽度和高度
Javascript: 网页可见区域宽: document.body.clientWidth网页可见区域高: document.body.clientHeight网页可见区域宽: document.b ...
- EntityFramework 学习 一 Validate Entity
可以为实体实现自定义验证,重写DBContext中的个ValidateEntity方法 protected override System.Data.Entity.Validation.DbEntit ...
- HDU 6096 AC自动机
n个字符串 m个询问 每个询问给出前后缀 并且不重合 问有多少个满足 m挺大 如果在线只能考虑logn的算法 官方题解:对n个串分别存正序倒序 分别按照字典序sort 每一个串就可以被化作一个点 那么 ...
- VC 写注册表
BOOL Running() { HKEY hKey; LPCTSTR strRegPath = L"SOFTWARE\\Microsoft\\Windows\\CurrentVersion ...