4.MySQL优化---多表查询优化
整理自互联网
一、多表查询连接的选择:
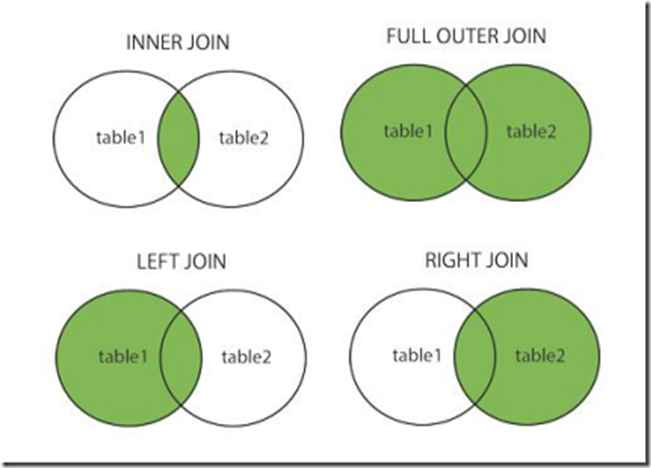
相信这内连接,左连接什么的大家都比较熟悉了,当然还有左外连接什么的,基本用不上我就不贴出来了。这图只是让大家回忆一下,各种连接查询。 然后要告诉大家的是,需要根据查询的情况,想好使用哪种连接方式效率更高。(这是技术文)
二、MySQL的JOIN实现原理
在MySQL 中,只有一种Join 算法,就是大名鼎鼎的Nested Loop Join,他没有其他很多数据库所提供的Hash Join,也没有Sort Merge Join。顾名思义,Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与Join,则再通过前两个表的Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。 ——摘自《MySQL 性能调优与架构设计》 三、补充:mysql对sql语句的容错问题
即在sql语句不完全符合书写建议的情况,mysql会允许这种情况,尽可能解释它:
1)一般cross join后面加上where条件,但是用cross join+on也是被解释为cross join+where;
2)一般内连接都需要加上on限定条件,如上面场景一;如果不加会被解释为交叉连接;
3)如果连接表格使用的是逗号,会被解释为交叉连接;
注:sql标准中还有union join和natural inner join,mysql不支持,而且本身也没有多大意义,其实就是为了“健壮”。但是其实结果可以用上面的几种连接方式得到。
三、超大型数据尽可能尽力不要写子查询,使用连接(JOIN)去替换它:
当然,关于这句话,也不一定就全是这样。
1)因为在大型的数据处理中,子查询是非常常见的,特别是在查询出来的数据需要进一步处理的情况,无论是可读性还是效率上,这时候的子查都是更优。
2)然而在一些特定的场景,可以直接从数据库读取就可以的,比如一个表(A表 a,b,c字段,需要内部数据交集)join自己的效率必然比放一个子查在where中快得多。(这真是技术文)
四、使用联合(UNION)来代替手动创建的临时表
UNION是会把结果排序的!!!
Union查询:它可以把需要使用临时表的两条或更多的select查询合并的一个查询中(即把两次或多次查询结果合并起来。)。在客户端的查询会话结束的时候,临时表会被自动删除,从而保证数据库整齐、高效。使用union来创建查询的时候,我们只需要用UNION作为关键字把多个select语句连接起来就可以了,要注意的是所有select语句中的字段数目要想同。
要求:两次查询的列数必须一致(列的类型可以不一样,但推荐查询的每一列,相对应的类型要一样)
可以来自多张表的数据:多次sql语句取出的列名可以不一致,此时以第一个sql语句的列名为准。如果不同的语句中取出的行,有完全相同(这里表示的是每个列的值都相同),那么union会将相同的行合并,最终只保留一行。也可以这样理解,union会去掉重复的行。
如果不想去掉重复的行,可以使用union all。
如果子句中有order by,limit,需用括号()包起来。推荐放到所有子句之后,即对最终合并的结果来排序或筛选。
注意:
1、UNION 结果集中的列名总是等于第一个 SELECT 语句中的列名
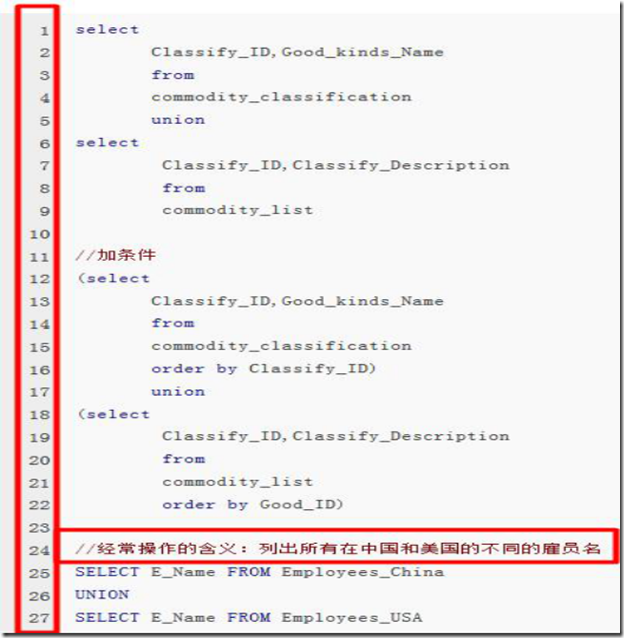
2、UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同
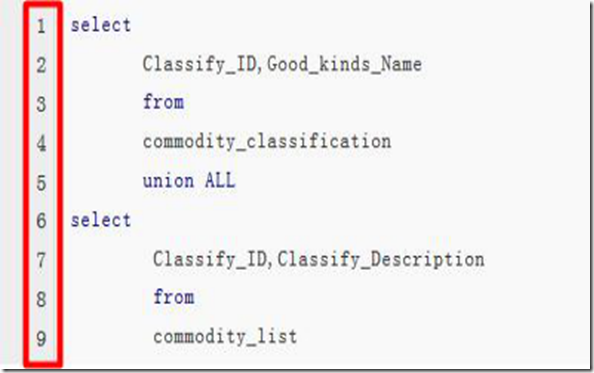
UNION ALL的作用和语法:
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。
五、总结
(1)对于要求全面的结果时,我们需要使用连接操作(LEFT JOIN / RIGHT JOIN / FULL JOIN);
(2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:

备注、描述、评论之类的可以设置为 NULL,其他最好不要使用NULL。
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num = 0
(3)in 和 not in 也要慎用,否则会导致全表扫描,如:

对于连续的数值,能用 between 就不要用 in 了:

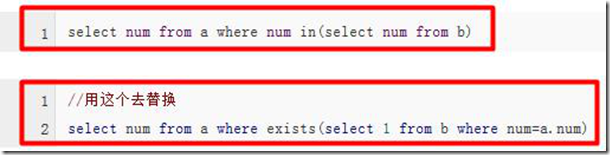
很多时候用 exists 代替 in 是一个好的选择:
(4)尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连 接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
(5)尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
(6)不要以为使用MySQL的一些连接操作对查询有多么大的改善,其实核心是索引.
4.MySQL优化---多表查询优化的更多相关文章
- 3.MySQL优化---单表查询优化的一些小总结(非索引设计)
整理自互联网.摘要: 接下来这篇是查询优化.其实,大家都知道,查询部分是远远大于增删改的,所以查询优化会花更多篇幅去讲解.本篇会先讲单表查询优化(非索引设计).然后讲多表查询优化.索引优化设计以及库表 ...
- mysql优化一之查询优化
这一篇笔记的mysql优化是注重于查询优化,根据mysql的执行情况,判断mysql什么时候需要优化,关于数据库开始阶段的数据库逻辑.物理结构的设计结构优化不是本文重点,下次再谈 查看mysql语句的 ...
- MySQL优化之表结构优化的5大建议(数据类型选择讲的很好)
殊不知,在N年前被奉为"圣经"的数据库设计3范式早就已经不完全适用了.这里我整理了一些比较常见的数据库表结构设计方面的优化技巧,希望对大家有用. 由于MySQL数据库是基于行(Ro ...
- MySQL优化三 表结构优化
由于MySQL数据库是基于行(Row)存储的数据库,而数据库操作 IO 的时候是以 page(block)的方式,也就是说,如果我们每条记录所占用的空间量减小,就会使每个page中可存放的数据行数增大 ...
- MYSQL优化派生表(子查询)在From语句中的
Mysql 在5.6.3中,优化器更有效率地处理派生表(在from语句中的子查询): 优化器推迟物化子查询在from语句中的子查询,知道子查询的内容在查询正真执行需要时,才开始物化.这一举措提高了性能 ...
- MySQL优化之表结构优化的5大建议
很多人都将 数据库设计范式 作为数据库表结构设计“圣经”,认为只要按照这个范式需求设计,就能让设计出来的表结构足够优化,既能保证性能优异同时还能满足扩展性要求殊不知,在N年前被奉为“圣经”的数据库设计 ...
- mysql 优化修复表
OPTIMIZE TABLE `table_name` 优化表 MyISAM 引擎清理碎片 OPTIMIZE语法: OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABL ...
- Mysql优化系列之查询优化干货1
从这一篇开始,准备总结一些直接受用的sql语句优化,写sql是第二要紧的,第一要紧的,是会分析怎么查最快, 因为当你写过很多sql后,查询出结果已经不是目标,快,才是目标.另外,通过测试和比较的结果才 ...
- mysql优化之表建设
就拿常见的用户表.文章类的表.日志表来分析如下 CREATE TABLE `user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMEN ...
随机推荐
- Android零散知识点积累
本文仅在记录android开发中遇到的零散知识点,会不断更新... 目录 .隐藏系统标题栏 .图片尺寸及屏幕密度 3.获取顶部状态栏高度 1.隐藏系统标题栏 1)在资源文件styles.xml中定义样 ...
- 05 Spring框架 依赖注入(二)
上一节我们讲了三种信息的注入,满足一个类的属性信息的注入,但是如果我们需要向一个实例中注入另一个实例呢?就像我们创建一个学生类,里边有:姓名,性别,年龄,成绩等几个属性(我习惯把类的域叫做属性),但是 ...
- KVM虚拟化安装配置
一.KVM的基础配置及安装: 1.查看是CPU否支持虚拟化: [root@oldboy-node1 ~]# grep -E "(vmx|svm)" /proc/cpuinfo vm ...
- 17南宁区域赛 J - Rearrangement 【规律】
题目链接 https://nanti.jisuanke.com/t/19976 题意 给出 一个n 然后 给出 2*n 个数 可以重新排列成两行 然后 相邻的两个数 加起来 不能被三整除 可以上下相邻 ...
- iOS 学习@autoreleasepool{}
" ojc-c 是通过一种"referring counting"(引用计数)的方式来管理内存的, 对象在开始分配内存(alloc)的时候引用计数为一,以后每当碰到有al ...
- 每天一个Linux命令(47)route命令
Linux系统的route命令用于显示和操作内核IP路由表(show / manipulate the IP routing table). (1)用法: 用法: route ...
- 04_Apache Hadoop 生态系统
内容提纲: 1)对 Apache Hadoop 生态系统的认识(Hadoop 1.x 和 Hadoop 2.x) 2) Apache Hadoop 1.x 框架架构原理的初步认识 3) Apache ...
- mysql 触发器 存储过程 java调用
触发器和存储过程是为了提高SQL的运行效率. SQL语句先编译.后执行,而触发器与存储过程都会提前预编译完成,且只编译一次,供反复调用. 随着时代的进步,硬件与带宽的提升,触发器和存储过程提升效率并不 ...
- P3437 [POI2006]TET-Tetris 3D
题目 P3437 [POI2006]TET-Tetris 3D 做法 一眼就是二维线段树,仔细想想,赋值操作怎么办??\(lazy\)标记放在一维,下一次又来放个标记二维就冲突了 正解:永久化标记 怎 ...
- JavaWeb 文件上传下载
1. 文件上传下载概述 1.1. 什么是文件上传下载 所谓文件上传下载就是将本地文件上传到服务器端,从服务器端下载文件到本地的过程.例如目前网站需要上传头像.上传下载图片或网盘等功能都是利用文件上传下 ...