HDFS案例
shell日志采集
需求说明
点击流日志每天都10T,在业务应用服务器上,需要准实时上传至数据仓库(Hadoop HDFS)上
需求分析
一般上传文件都是在凌晨24点操作,由于很多种类的业务数据都要在晚上进行传输,为了减轻服务器的压力,避开高峰期。
如果需要伪实时的上传,则采用定时上传的方式
技术分析
HDFS SHELL: hadoop fs –put xxxx.tar /data 还可以使用 Java Api
满足上传一个文件,不能满足定时、周期性传入。
定时调度器:
Linux crontab
crontab -e
*/5 * * * * $home/bin/command.sh //五分钟执行一次
系统会自动执行脚本,每5分钟一次,执行时判断文件是否符合上传规则,符合则上传
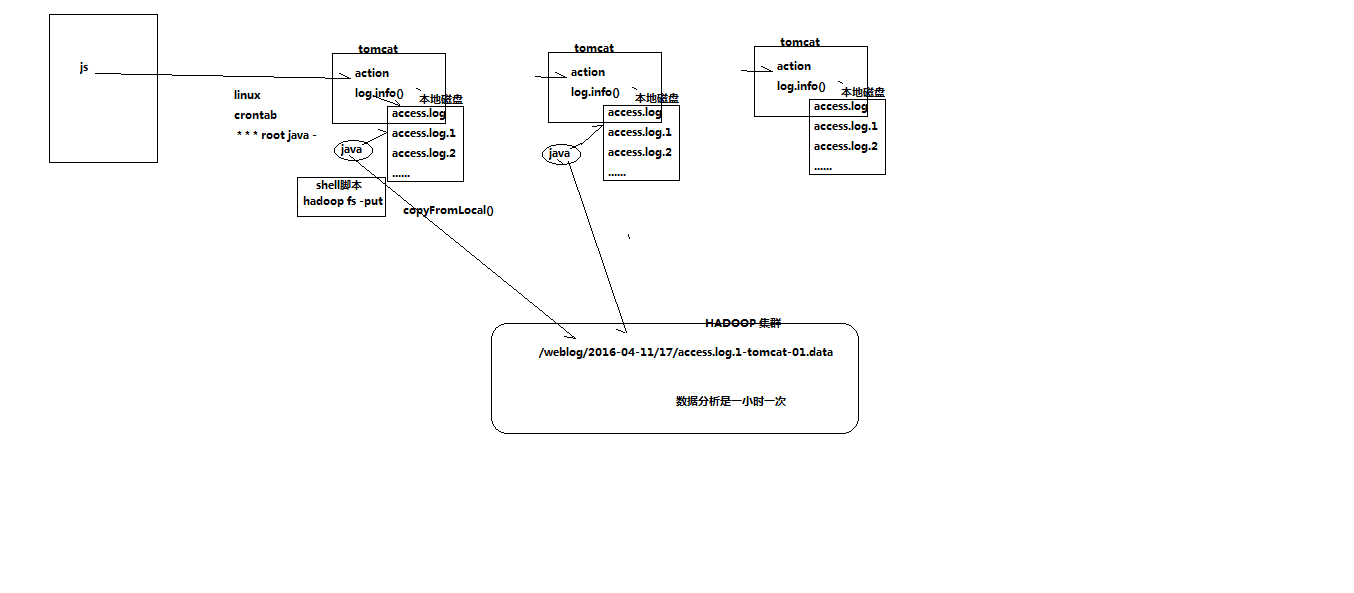
实现流程
日志产生程序
日志产生程序将日志生成后,产生一个一个的文件,使用滚动模式创建文件名。
日志生成的逻辑由业务系统决定,比如在log4j配置文件中配置生成规则,如:当xxxx.log 等于10G时,滚动生成新日志
|
log4j.logger.msg=info,msg log4j.appender.msg=cn.maoxiangyi.MyRollingFileAppender log4j.appender.msg.layout=org.apache.log4j.PatternLayout log4j.appender.msg.layout.ConversionPattern=%m%n log4j.appender.msg.datePattern='.'yyyy-MM-dd log4j.appender.msg.Threshold=info log4j.appender.msg.append=true log4j.appender.msg.encoding=UTF-8 log4j.appender.msg.MaxBackupIndex=100 log4j.appender.msg.MaxFileSize=10GB log4j.appender.msg.File=/home/hadoop/logs/log/access.log |
细节:
1、 如果日志文件后缀是1\2\3等数字,该文件满足需求可以上传的话。把该文件移动到准备上传的工作区间。
2、 工作区间有文件之后,可以使用hadoop put命令将文件上传。
阶段问题:
1、 待上传文件的工作区间的文件,在上传完成之后,是否需要删除掉。
伪代码
使用ls命令读取指定路径下的所有文件信息,
ls | while read line
//判断line这个文件名称是否符合规则
if line=access.log.* (
将文件移动到待上传的工作区间
)
//批量上传工作区间的文件
hadoop fs –put xxx
脚本写完之后,配置linux定时任务,每5分钟运行一次。
代码实现
#!/bin/bash #set java env
export JAVA_HOME=/home/hadoop/app/jdk1..0_51
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH #set hadoop env
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH #版本1的问题:
#虽然上传到Hadoop集群上了,但是原始文件还在。如何处理?
#日志文件的名称都是xxxx.log1,再次上传文件时,因为hdfs上已经存在了,会报错。如何处理? #如何解决版本1的问题
# 、先将需要上传的文件移动到待上传目录
# 、在讲文件移动到待上传目录时,将文件按照一定的格式重名名
# /export/software/hadoop.log1 /export/data/click_log/xxxxx_click_log_{date} #日志文件存放的目录
log_src_dir=/home/hadoop/logs/log/ #待上传文件存放的目录
log_toupload_dir=/home/hadoop/logs/toupload/ #日志文件上传到hdfs的根路径
hdfs_root_dir=/data/clickLog// #打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME" #读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi done
#找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
crontab的配置
*/1 * * * * sh /export/servers/shell/uploadFile2Hdfs.v2.sh
*/1 * * * * sh source /etc/profile;sh /export/servers/shell/uploadFile2Hdfs.v1.sh# 编辑命令是crontab -e
# 查看命令是crontab -l日志模拟器
package cn.itcast.bigdata.log; import java.util.Date; import org.apache.log4j.LogManager;
import org.apache.log4j.Logger; public class GenerateLog {
public static void main(String[] args) throws Exception {
Logger logger = LogManager.getLogger("testlog");
int i = 0;
while (true) {
logger.info(new Date().toString() + "-----------------------------");
i++;
Thread.sleep(500);
if (i > 1000000)
break; }
} }
HDFS案例的更多相关文章
- Flume采集目录及文件到HDFS案例
采集目录到HDFS 使用flume采集目录需要启动hdfs集群 vi spool-hdfs.conf # Name the components on this agent a1.sources = ...
- 04_ Flume采集文件到HDFS案例
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs 根据需求,首先定义以下3大要素 采集源,即source——监控文件内容更新 : ex ...
- 03_ Flume采集(监听)目录到HDFS案例
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去 根据需求,首先定义以下3大要素 l.采集数据源,即source——监控文件目录 : spool ...
- Flume案例Ganglia监控
Flume案例和Flume监控系统的使用: 安装 将apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/software目录下 解压apache-flume-1.7. ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- Flume推送数据到SparkStreaming案例实战和内幕源码解密
本期内容: 1. Flume on HDFS案例回顾 2. Flume推送数据到Spark Streaming实战 3. 原理绘图剖析 1. Flume on HDFS案例回顾 上节课要求大家自己安装 ...
- Flume 概述/企业案例
概述 1 Flume定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. 下面我们来详细介绍一下Flume架构中的 ...
- FileSystem实例化过程
HDFS案例代码 Configuration configuration = new Configuration(); FileSystem fileSystem = FileSystem.get(n ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
随机推荐
- python多线程抓取代理服务器
文章转载自:https://blog.linuxeye.com/410.html 代理服务器:http://www.proxy.com.ru #coding: utf-8 import urllib2 ...
- neutron二层网络实现
一.基本概念 1.tap设备 比如vnet0,是虚拟化技术和KVM和XEN用来实现虚拟网卡的,当一个以太网帧发送给TAP设备时,这个以太网帧就会被虚拟机操作系统所接手,命名空间用于隔离虚拟网络设备. ...
- 用js 创建 简单查找 删除 二叉树
<!DOCTYPE html> <html> <body> <canvas id="myCanvas" width="2000& ...
- everything 全盘文件查找工具及正则表达式的使用
首先需要开启 everything 工具在(字符串)查找时,对正则表达式功能的支持: [菜单栏]⇒ [Search]⇒ 勾选[Enable Regex] ctrl + i:字符大小写敏感/不敏感 1. ...
- zend studio 提升开发效率的快捷键及可视化订制相关设置
Zend studio快捷键使用 F3 快速跳转到当前所指的函数,常量,方法,类的定义处,相当常用.当然还可以用Ctrl+鼠标左键 shift+end 此行第一个到最后一个 shift+home 此行 ...
- Linux部分常用命令学习(一)
什么是linux命令? 是一个可执行程序,就像我们所看到的位于目录/usr/bin 中的文件一样. 属于这一类的程序,可以编译成二进制文件,诸如用 C 和 C++语言写成的程序, 也可以是由脚本语言写 ...
- pod上传私有spec文件库
一.验证 function podlint() { pod lib lint $1.podspec --use-libraries --allow-warnings --verbose --sourc ...
- 利用Github免费搭建个人主页(个人博客)
之前闲着, 利用Github搭了个免费的个人主页. 涉及: Github注册 Github搭建博客 域名选购 绑定域名 更多 一 Github注册 在地址栏输入地址:http://github.co ...
- 转:使用django-admin.py创建django工程
原文:http://blog.csdn.net/a921800467b/article/details/8257352 安装Django首先需要安装数据库,可选的数据库有好几种,我选择的是MySQL数 ...
- 一线互联网公司必备——最为详细的Docker入门吐血总结
在计算机技术日新月异的今天, Docker 在国内发展的如火如荼. 特别是在一线互联网公司 Docker 的使用是十分普遍的,甚至成为了一些企业面试的加分项,不信的话看看下面这张图. ...