Kafka高可用的保证
zookeeper作为去中心化的集群模式,消费者需要知道现在那些生产者(对于消费者而言,kafka就是生产者)是可用的。
如果没有zookeeper每次消费者在消费之前都去尝试连接生产者测试下是否连接成功,这样无法保证效率
Replication & Leader election
Kafka中主题的每个partition有一个预写式日志,每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中,
partition中的每个消息都由一个连续的序列号叫做offset,确定他在分区日志中唯一的位置。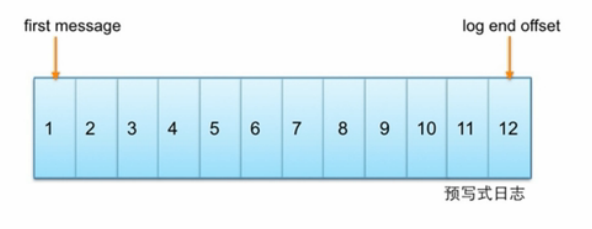
分布式:
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的,副本使Kafka具备了容错能力。
每个分区都由一个服务器作为leader,零或若干服务器作为followers,leader负责处理消息的读和写,followers则去复制leader,如果leader宕了,
followers中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,
这样集群就会具有较好的负载均衡。
Replication与leader election:
Replication与leader election配合提供了自动的failover机制,replication对Kafka的吞吐率是有一定影响的,
但极大的增强了可用性。默认情况下,Kafka的replication数量(不能为0,不能大于broker数量)为1,每个partition都有唯一的leader,所有的读写操作
都在leader上完成follower批量从leader上pull数据。和大部分分布式系统一样,Kafka处理失败需要明确定义一个broker
是否alive,对于Kafka而言,Kafka存货包含两个条件,一是它必须维护与zookeeper的会话(这个通过zookeeper的heartbeat机制来实现)
二是follower必须能够及时将leader的writing复制过来。
Kafka每个topic的partition有N个副本,其中N是topic的复制因子,Kafka通过多副本机制实现故障转移,当Kafka集群中的一个Broker
失效情况下仍然保证服务可用。在Kafka中发生复制时确保partition的预写式日志有序地写到其他节点上。N个replications中,其中一个replication
为leader,其他都为follower,leader处理partition的所有读写请求,与此同时,follower会被定期地去复制leader上的数据。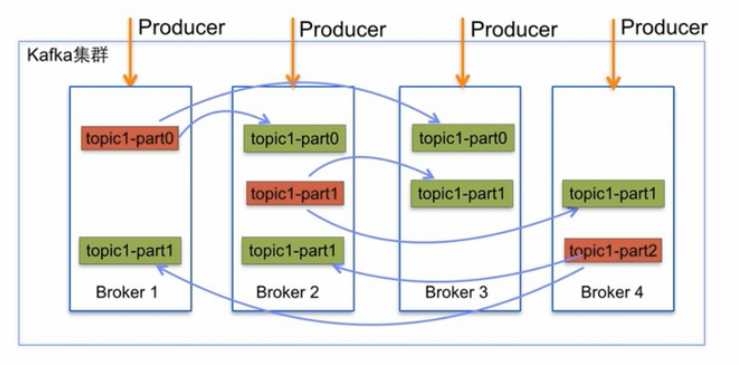
Kafka高可用的保证的更多相关文章
- Kafka 高可用设计
Kafka 高可用设计 2016-02-28 杜亦舒 Kafka在早期版本中,并不提供高可用机制,一旦某个Broker宕机,其上所有Partition都无法继续提供服务,甚至发生数据丢失对于分布式系统 ...
- kafka高可用探究
kafka高可用探究 众所周知 kafka 的 topic 可以使用 --replication-factor 数和 partitions 数来保证服务的高可用性 问题发现 但在最近的运维过程中,3台 ...
- Kafka高可用环境搭建
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发,Linkedin于2010年贡献给 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- redis高可用,保证高并发
目录 redis如何通过读写分离来承载读请求QPS超过10万+ redis replication以及master持久化对主从架构的安全意义 redis主从复制原理.断点续传.无磁盘化复制.过期key ...
- Kafka高可用实现原理
数据存储格式 Kafka的高可靠性的保障来源于其健壮的副本(replication)策略.一个Topic可以分成多个Partition,而一个Partition物理上由多个Segment组成. Seg ...
随机推荐
- Spring 注解 @Scheduled(cron = "0 0/10 * * * ? ") 任务调度动态改变时间
不需要重启应用就可以动态的改变Cron表达式的值 import java.util.Date; import java.util.concurrent.Executor; import java.ut ...
- Linux vi 文件编辑
1.通过vi filename 进入编辑状态 2.退出 vi 编辑器 退出命令 说明 q 如果文件未被修改,会直接退回到Shell:否则提示保存文件. q! 强行退出,不保存修改内容. wq w 命令 ...
- Memcached 常见的问题
memcached是怎么工作的? Memcached的奇妙来自两阶段哈希(two-stage hash).Memcached就像一个巨大的.存储了非常多<key,value>对的哈希表. ...
- php+redis秒杀
啥都不说了,看代码 前台: 包括开始和结束的秒杀时间,倒计时插件,统一看一遍再去写代码,思路会更清晰. js文件引入一个.min.js和一个插件js(在下面,自己复制吧) // JavaScript ...
- SVN服务器迁移,SVN版本库迁移(网络copy)
做法: 准备:系统平台:windows server 2003 版本库:vos 源服务器:10.10.13.48 目标服务器:10.10.13.129源SVN版本库的path: D:\svn\vos要 ...
- asp.net 页面延时五秒,跳转到另外的页面
asp.net 页面延时五秒,跳转到另外的页面的实现代码. --前台 <%@ Page Language="C#" AutoEventWireup="true&qu ...
- Python gevent学习笔记-2
在上一篇里面介绍了gevent的最主要的功能,先来来了解一下gevent里面一些更加高级的功能. 事件 事件是一种可以让greenlet进行异步通信的手段. ? 1 2 3 4 5 6 7 8 9 1 ...
- xshell ftp报错:找不到匹配的outgoing encryption算法
场景:由于登陆跳板机都是从采用密钥的方式进行登陆的,然后在传输文件的时候报错 报错信息: 解决方案: 点击属性--->选择aes256-ctr加密方式默认这里是没有选择的 再次连接就成功连接上去 ...
- cocos2d-x:七彩连珠
大学前,我一直以为学计算机就是学做游戏,或者玩游戏...(我果断的用大学的差不多五分之二实践了后面半块.) 大学后,人们一直以为学计算机的就是 修电脑.装机.盗qq号.word.excel....最近 ...
- iphone开发常用代码笔记
1.显示图像: 1 2 3 4 5 6 CGRect myImageRect = CGRectMake(0.0f, 0.0f, 320.0f, 109.0f); UIImageView *myImag ...