使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。
ImagesPipeline是scrapy自带的类,用来处理图片(爬取时将图片下载到本地)用的。
优势:
- 将下载图片转换成通用的JPG和RGB格式
- 避免重复下载
- 缩略图生成
- 图片大小过滤
- 异步下载
- ......
工作流程:
- 爬取一个Item,将图片的URLs放入
image_urls字段 - 从
Spider返回的Item,传递到Item Pipeline - 当
Item传递到ImagePipeline,将调用Scrapy 调度器和下载器完成image_urls中的url的调度和下载。 - 图片下载成功结束后,图片下载路径、url和校验和等信息会被填充到images字段中。
实现方式:
- 自定义pipeline,优势在于可以重写ImagePipeline类中的实现方法,可以根据情况对照片进行分类;
- 直接使用ImagePipeline类,简单但不够灵活;所有的图片都是保存在full文件夹下,不能进行分类
实践:爬取http://699pic.com/image/1/这个网页下的前四个图片集(好进行分类演示)

这里使用方法一进行实现:
步骤一:建立项目与爬虫
1.创建工程:scrapy startproject xxx(工程名)
2.创建爬虫:进去到上一步创建的目录下:scrapy genspider xxx(爬虫名) xxx(域名)
步骤二:创建start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl 699pic(爬虫名)".split(" "))
步骤三:设置settings
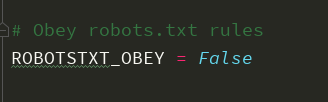
1.关闭机器人协议,改成False
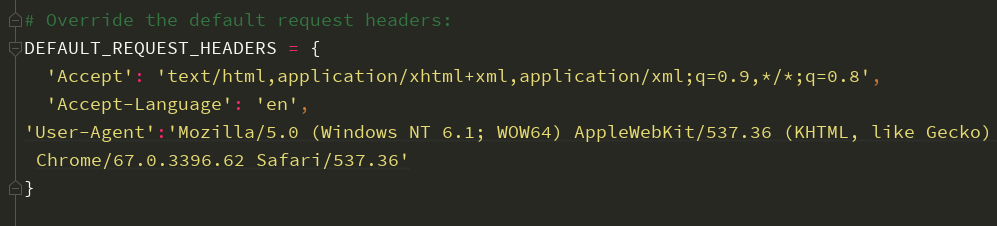
2.设置headers
3.打开ITEM_PIPELINES
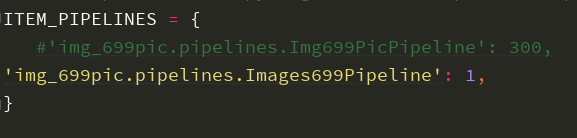
将项目自动生成的pipelines注释掉,黄色部分是下面步骤中自己写的pipeline,这里先不写。
步骤四:item
class Img699PicItem(scrapy.Item):
# 分类的标题
category=scrapy.Field()
# 存放图片地址
image_urls=scrapy.Field()
# 下载成功后返回有关images的一些相关信息
images=scrapy.Field()
步骤五:写spider
import scrapy
from ..items import Img699PicItem
import requests
from lxml import etree class A699picSpider(scrapy.Spider):
name = '699pic'
allowed_domains = ['699pic.com']
start_urls = ['http://699pic.com/image/1/']
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'
} def parse(self, response):
divs=response.xpath("//div[@class='special-list clearfix']/div")[0:4]
for div in divs:
category=div.xpath("./a[@class='special-list-title']//text()").get().strip()
url=div.xpath("./a[@class='special-list-title']/@href").get().strip()
image_urls=self.parse_url(url)
item=Img699PicItem(category=category,image_urls=image_urls)
yield item def parse_url(self,url):
response=requests.get(url=url,headers=self.headers)
htmlElement=etree.HTML(response.text)
image_urls=htmlElement.xpath("//div[@class='imgshow clearfix']//div[@class='list']/a/img/@src")
return image_urls
步骤六:pipelines
import os
from scrapy.pipelines.images import ImagesPipeline
from . import settings class Img699PicPipeline(object):
def process_item(self, item, spider):
return item class Images699Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 这个方法是在发送下载请求之前调用的,其实这个方法本身就是去发送下载请求的
request_objs=super(Images699Pipeline, self).get_media_requests(item,info)
for request_obj in request_objs:
request_obj.item=item
return request_objs def file_path(self, request, response=None, info=None):
# 这个方法是在图片将要被存储的时候调用,来获取这个图片存储的路径
path=super(Images699Pipeline, self).file_path(request,response,info)
category=request.item.get('category')
image_store=settings.IMAGES_STORE
category_path=os.path.join(image_store,category)
if not os.path.exists(category_path):
os.makedirs(category_path)
image_name=path.replace("full/","")
image_path=os.path.join(category_path,image_name)
return image_path
步骤七:返回到settings中
1.将黄色部分填上

2.存放图片的总路径
IMAGES_STORE=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
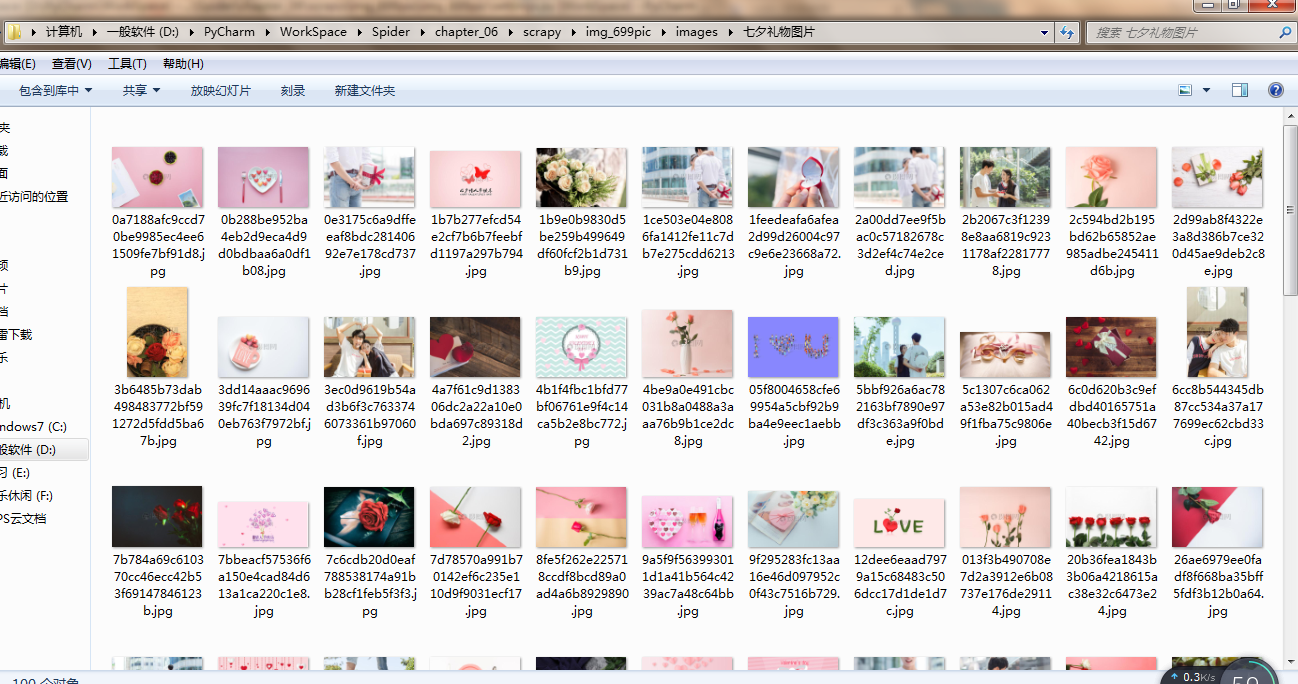
最终结果:

使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。的更多相关文章
- 通过scrapy内置的ImagePipeline下载图片到本地、并提取本地保存地址
1.通过scrapy内置的ImagePipeline下载图片到本地 2.获取图片保存本地的地址 1.通过scrapy内置的ImagePipeline下载图片到本地 1)在settings.py中打开 ...
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- 使用 Scrapy 的 ImagesPipeline 下载图片
下载 百度贴吧-动漫壁纸吧 所有图片 定义item Spider spider 只需要得到图片的url,必须以列表的形式给管道处理 class PictureSpiderSpider(scrapy.S ...
- (二)scrapy 中如何自定义 pipeline 下载图片
这里以一个很简单的小爬虫为例,爬取 壹心理 网站的阅读页面第一页的所有文章及其对应的图片,文章页面如下: 创建项目 首先新建一个 scrapy 项目,安装好相关依赖(步骤可参考:scrapy 安装及新 ...
- scrapy 在爬取过程中抓取下载图片
先说前提,我不推荐在sarapy爬取过程中使用scrapy自带的 ImagesPipeline 进行下载,是在是太耗时间了 最好是保存,在使用其他方法下载 我这个是在 https://blog.csd ...
- scrapy中的ImagePipeline下载图片到本地、并提取本地的保存地址
通过scrapy内置到ImagePipeline下载图片到本地 在settings中打开 ITEM_PIPELINES的注释,并在这里面加入 'scrapy.pipelines.images.Imag ...
- 使用官方组件下载图片,保存到MySQL数据库,保存到MongoDB数据库
需要学习的地方,使用官方组件下载图片的用法,保存item到MySQL数据库 需要提前创建好MySQL数据库,根据item.py文件中的字段信息创建相应的数据表 1.items.py文件 from sc ...
- 使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件
目标网站:https://www.mn52.com/ 本文代码已上传至git和百度网盘,链接分享在文末 网站概览 目标,使用scrapy框架抓取全部图片并分类保存到本地. 1.创建scrapy项目 s ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
随机推荐
- js邮箱验证,身份证验证,正则表达式
邮箱验证: html部分: 邮箱验证:<input type="text" id="mail" value="" / onkeyup= ...
- ATK系列库说明
初衷 重构和复用是软件的一个古老话题. 在日常的软件项目开发的过程序中,如何保证团队代码的强健,同时在不断变化的需过程中最大限度的保障代码的一致性,是项目开发中的难以控制的,我们可以借助各种源码管理和 ...
- CRS
CRS是集群就绪服务(cluster ready service)的简称,主要负责集群中的资源管理以及OCR管理.为了与10gR2集群管理软件名称crs区分,这里用CRSD代替CRS.相关概念:--资 ...
- center os 创建用户、设置密码、修改用户、删除用户命令
参考:https://www.linuxidc.com/Linux/2017-06/144916.htm useradd testuser 创建用户testuserpasswd testuser ...
- oracle快速添加用户及授权
--Oracle使用的是用户管理模式--意味着,Oracle的数据使用用户来分割 --以后开发,我们需要每个项目都需要使用一个用户 --所以:一个数据文件是可以放多个用户的数据的.但是我们开发从数据的 ...
- Struts2前期(这框架目前正处于淘汰状态)
Struts2第一天 Struts2的学习路线 1. Struts2的入门:主要是学习Struts2的开发流程(Struts2的开发流程.常见的配置.Action类的编写) 2. Struts2的Se ...
- JDBC编程:使用 Statement 修改数据库
获取数据连接后,即可对数据库中的数据进行修改和查看.使用 Statement 接口可以对数据库中的数据进行修改,下面是程序演示. /** * 获取数据库连接,并使用SQL语句,向数据库中插入记录 */ ...
- SAP物料主数据的屏幕字段控制,必输,隐藏
http://www.cnblogs.com/275147378abc/p/5699077.html 1.事务码MM01,把物料组设为选填字段. 2.找到物料组的屏幕字段. 3.在后台根据屏幕字段找到 ...
- rhel7-Samba服务搭建
服务检查: [root@localhost ~]# systemctl status smb.service● smb.service - Samba SMB Daemon Loaded: loa ...
- MySQL版本详解
一.版本说明 1.1.MySQL相关连接 MySQL官网:https://www.mysql.com/ MySQL下载:https://dev.mysql.com/downloads/mirrors/ ...