Strom入门
Worker、Executor、Task详解:
Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
1. Worker Process(工作进程)——Spout/Bolt中运行具体处理逻辑的进程
2. Executor(线程、执行器)——物理线程
3. Task(任务)——具体的处理逻辑对象
下图简要描述了这3者之间的关系: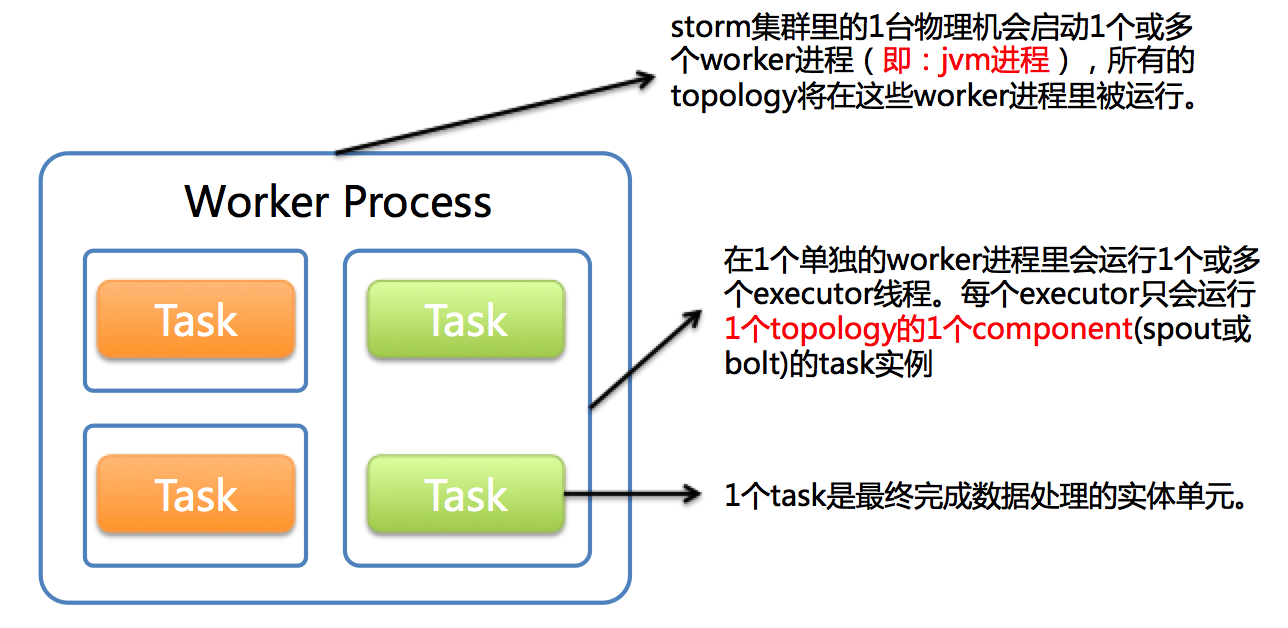
storm集群的一个节点可能有一个或者多个工作进程(worker)运行在一个多个拓扑上,一个工作进程执行拓扑的一个子集。工作进程(worker)属于一个特定的拓扑,并可能为这个拓扑的一个或者多个组件(spout/bolt)运行一个或多个执行器(executor线程)。一个运行中的拓扑包括多个运行在storm集群内多个节点的进程。
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
配置拓扑的并行度:
1.工作进程的数量
工作进程的数量表示集群中不同节点的拓扑可以创建多少个工作进程。
配置参数是:TOPOLOGY_WORKERS
也可以通过java API进行设置:
Config#setNumWorkers
2.执行器(线程)的数量
执行器的数量指的是每个组件产生多少个线程。
这个参数暂时只能通过java API进行配置:
TopologyBuilder#setSpout()
TopologyBuilder#setBolt()
3.任务的数量
任务的数量表示的是每个组件创建多少个任务。
配置选项:TOPOLOGY_TASKS
也可以通过java API进行配置:
ComponentConfigurationDeclarer#setNumTasks()
T setNumTasks(java.lang.Number val)
拓扑示例
下面我们定义一个名为mytopology的拓扑,由一个Spout组件(BlueSpout)、两个Bolt组件(GreenBolt和YellowBolt)共三个组件构成,代码如下:

1 Config conf = new Config();
2 conf.setNumWorkers(2);
3
4 topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
5
6 topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
7 .setNumTasks(4)
8 .shuffleGrouping("blue-spout");
9
10 topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
11 .shuffleGrouping("green-bolt");
12
13 StormSubmitter.submitTopology(
14 "mytopology",
15 conf,
16 topologyBuilder.createTopology()
17 );
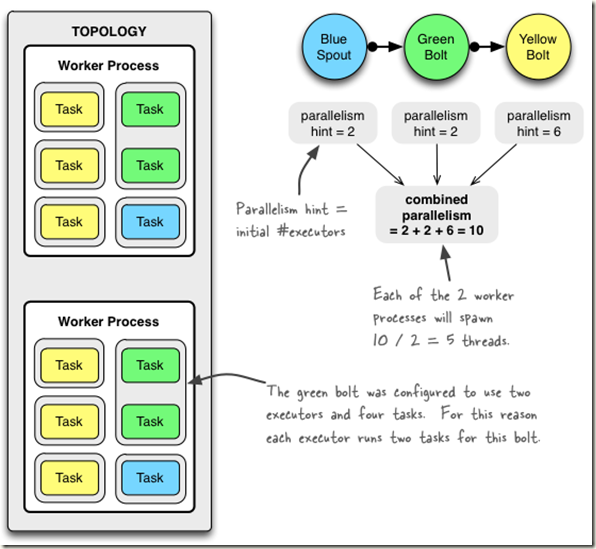
mytopology拓扑的描述如下:
1、拓扑将使用两个工作进程(Worker)。
2、Spout是id为“blue-spout”、并行度为2的BlueSpout实例(产生两个执行器和两个任务)。
3、第一个Bolt的id为"green-bolt"、并行度为2、任务数为4、使用随机分组方式接收"blue-spout"所发射元组的GreenBolt实例(产生两个执行器和4个任务)。
4、第二个Bolt是id为"yellow-bolt"、并行度为6、使用随机分组方式接收"green-bolt"所发射元组的YellowBolt实例(产生6个执行器和6个任务)。
综上所述,该拓扑一共有两个工作进程(Worker),2+2+6=10个执行器(Executor),2+4+6=12个任务。因此,每个工作进程可以分配到10/2=5个执行器,12/2=6个任务。默认情况下,一个执行器执行一个任务,但是如果指定了任务的数目,则任务会平均分配到执行器中,因此,GreenBolt的实例"green-bolt"的一个执行器将会分配到4/2个任务。
mytopology的拓扑及其对应的资源分配如下图所示:

动态设置拓扑的并发度
Storm支持在不重启topology的情况下,动态的改变(增减)worker process的数目和executor的数目,称为rebalancing。有两种方式可以实现拓扑的再平衡:
1、使用Storm Web UI
2、使用Storm rebalance命令(推荐使用)
使用命令行的方式如下:
1 # 重新配置拓扑
2 # "mytopology" 拓扑使用5个Worker进程
3 # "blue-spout" Spout使用3个Executor
4 # "blue-spout" Bolt使用10个Executor
5
6 # storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
注:"mytopology"是拓扑的名称,"blue-spout"和"yellow-bolt"是组件的名称。
Strom入门的更多相关文章
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- Hadoop 入门
我看过的比较全的文章.赞一下 原文链接:http://www.aboutyun.com/thread-8329-1-1.html 问题导读: 1.hadoop编程需要哪些基础?2.hadoop编程需要 ...
- apache Storm之一-入门学习
准备工作 这个教程使用storm-starter项目里面的例子.我推荐你们下载这个项目的代码并且跟着教程一起做.先读一下:配置storm开发环境和新建一个strom项目这两篇文章把你的机器设置好. 一 ...
- 01-项目简介Springboot简介入门配置项目准备
总体课程主要分为4个阶段课程: ------------------------课程介绍------------------------ 01-项目简介Springboot简介入门配置项目准备02-M ...
- hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
问题导读 1.说说你对集群配置的认识?2.集群配置的配置项你了解多少?3.下面内容让你对集群的配置有了什么新的认识? 目的 目的1:这个文档描述了如何安装配置hadoop集群,从几个节点到上千节点.为 ...
- Kafka入门宝典(详细截图版)
1.了解 Apache Kafka 1.1.简介 官网:http://kafka.apache.org/ Apache Kafka 是一个开源消息系统,由Scala 写成.是由Apache 软件基金会 ...
- Angular2入门系列教程7-HTTP(一)-使用Angular2自带的http进行网络请求
上一篇:Angular2入门系列教程6-路由(二)-使用多层级路由并在在路由中传递复杂参数 感觉这篇不是很好写,因为涉及到网络请求,如果采用真实的网络请求,这个例子大家拿到手估计还要自己写一个web ...
- ABP入门系列(1)——学习Abp框架之实操演练
作为.Net工地搬砖长工一名,一直致力于挖坑(Bug)填坑(Debug),但技术却不见长进.也曾热情于新技术的学习,憧憬过成为技术大拿.从前端到后端,从bootstrap到javascript,从py ...
- Oracle分析函数入门
一.Oracle分析函数入门 分析函数是什么?分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计 ...
随机推荐
- mtd-util
1.1.4.1. mtd-util简介 mtd-util,即mtd的utilities,是mtd相关的很多工具的总称,包括常用的mtdinfo,flash_erase, flash_eraseall, ...
- Qt 学习之路 2(71):线程简介
Qt 学习之路 2(71):线程简介 豆子 2013年11月18日 Qt 学习之路 2 30条评论 前面我们讨论了有关进程以及进程间通讯的相关问题,现在我们开始讨论线程.事实上,现代的程序中,使用线程 ...
- anaconda多环境配置
分享几篇比较好的帖子: https://zhuanlan.zhihu.com/p/25198543 http://www.imooc.com/article/18123
- SQL数据库“单个用户”不能访问,设置为多个用户的解决方法
USE master; GO DECLARE @SQL VARCHAR(MAX); SET @SQL='' SELECT @SQL=@SQL+'; KILL '+RTRIM(SPID) FROM ma ...
- 选择排序 Selection Sort
选择排序 Selection Sort 1)在数组中找最小的数与第一个位置上的数交换: 2)找第二小的数与第二个位置上的数交换: 3)以此类推 template<typename T> / ...
- python-Generalization of Hops
python provides a general purpose HOP,map simple form-a unary function and a collection of suitable ...
- ASP.NET与.NET区别
1.NET是什么? .Net全称.NET Framework是一个开发框架,不是一门编程语言,简单的来说 就是一组类库框架,.NET开发支持C#.VB.NET.J#.Js和Managed C++等 其 ...
- PIE SDK打开网络地图数据
1. 数据介绍 网络地图数据是在线地图服务发布出来的数据,其支持数据的网络查看和传输,极大的促进了GIS的发展. 目前PIE SDK支持百度地图.谷歌地图.高德地图.天地图.Bing地图.ArcGIS ...
- PIE SDK文本元素的绘制
1. 功能简介 在数据的处理中会用到文本元素的绘制,利用ITextElement文本元素接口进行绘制,目前PIE SDK支持ITextSymbol符号接口,TextSymbol对象是用于修饰文字元素对 ...
- 转 How To Stop A Running Job Using DBMS_JOB
There is no procedure within the dbms_job package to stop a running job.You will need to determine w ...