第七篇Python基本数据类型之数字&字符串&布尔值
数字
写在最前,必须要会的:int()
整型
Python3里无论数字多长都用int表示,Python2里有int和Long表示,Long表示长整型
有关数字的常用方法,方法调用后面都必须带括号()
int():将字符串转换为整型,且字符串内容只能是数字
a = ""
b = "123a"
c = int(a)
d = int(b) # ValueError: invalid literal for int() with base 10: '123a'
print(type(c))
print(type(d))
int(x,[base]):将x转换为整型,base指定转换的基数,base=2, 8, 16,表示以2,8,16进制转换,默认是10进制
e = "a"
f = int(e, base=16)
print(type(f))
print(f) #结果
<class 'int'>
10
bit_length():当前数字用二进制表示时,至少有几位
age1 = 1
age2 = 2
age3 = 3
age4 = 4
age5 = 5
age6 = 6
age7 = 30
print(age1.bit_length())
print(age2.bit_length())
print(age3.bit_length())
print(age4.bit_length())
print(age5.bit_length())
print(age6.bit_length())
print(age7.bit_length()) #结果
1
2
2
3
3
3
5
字符串
写在最前,必须要会的:replace(),find(),join(),strip(),stratwith(),endwith(),split(),upper(),lower(),format()
format(self, *args, **kwargs):格式化字符串
temp = "I am {name},age: {age}"
v = temp.format(name = "alex",age = 19)
print(v)
# 如果方法的定义里有**kwargs,就表示 他可以写成name = x,也可以写成字典形式
v1 = temp.format(**{"name":"alex2","age":20})
print(v1)
#结果
I am alex,age: 19
I am alex2,age: 20
总结
1、常用需要记住的字符串的基本魔法(7个)
join()、split()、find()、strip()、upper()、lower()、replace()
2、灰魔法(4个)
(1)、索引(下表):从0开始的,也就是某个字符串的第一个字符的索引是0
test = "alex"
print(test[0]) #结果
a
(2) 切片
test = "alex"
print(test[0:2]) # 范围 0<=test[0:2]<2 #结果
al
(3)、len():获取当前字符串的长度,即由几个字符组成
print(len(test)) # 结果
4
test1 = "你好世界"
print(len(test1)) # 结果
4 (Python3)
9 (Python2.7) # 如果len()的对象是列表,是以逗号为标记,获得有几个元素
li = ["adf","dfad","fadf","fad","re"]
print(len(li)) # 结果
5
(4)、将字符串里的每个字符单独拿出来的两种方法
test = "他说妹子冲我来"
# 方法1:while 循环实现
index = 0
while index < len(test):
v = test[index]
print(v)
index = index + 1
# 方法2:for 循环实现
for count in test:
print(count)
rnage():用来创建连续的数字
v = range(100)
print(v) # range(0, 100) # 在python2.7里,range(100)在内存里立即就创建了,命令行里立马就打出0~99个数
# 在python3里,range(100)是在循环开始的时候才一个一个的创建内存
# 其实这是python3的一个优化,试想,如果又10000万个数,如果立即创建,内存占用会立刻升高
range(0,100,step):可以通过设置步长,来创建不连续的数字
v = range(0, 100, 30) #0 到100个数里,步长30,每个30个数取一个
for i in v:
print(i) #结果
30
60
90
#练习: 将test对应的字符串的索引和对应的字符打印出来
test = input(">>>")
l= len(test)
for item in range(l):
print(item,test[item])
字符串一旦创建,就不能修改;但是一旦修改或者拼接,都会造成重新生成字符串,开辟新的内存
字符串的表示方法:通过引号表示
# 下面对字符串的表示都是正确的
str1 = '单引号'
str2 = "双引号"
str3 = '''三个单引号'''
str4 = """三个双引号""" # 注意:引号不能混用,比如
str5 = "引号不能混用,会报错'
字符串的方法太多了,两种方式可以获得字符串都有哪些方法:
1. Pycharm等带有自动提示功能的编译器,写一个字符串,后面 点一下,就会提示它可用的方法
2. Pycharm里,安装Ctrl,鼠标光标移到 str()上,点击左键就会进入str()的方法,里面可以看到每种方法的具体定义
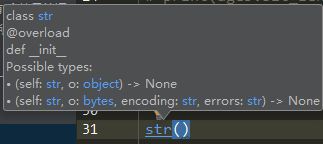
字符串的方法:
因为太多了,所以练一个写一个。
capitalize():首字母大写
str1 = "alex"
v = str1.capitalize()
print(v) #结果
Alex
casefold():将字母变成小写
lower():将字母变成小写
test = "alex"
v1 = test.casefold() # 更牛逼,很多未知的对应关系也可以变小写
print(v1) v2 = test.lower() # 对普通的,我们能想到的变小写
print(v2) #结果
alex
alex
center(self, width, fillchar=None):设置宽度,并将内容居中,width表示总长度,fillchar表示空白位置填充,可以用不填,要填只能填一个字符,表示空白位置用该字符填充。
对于方法里有参数的,调用的时候必须带参数,此方法里width对应的必须带个参数,而fillchar后面有=,默认值是None,对应这种参数有默认值的可以不带,
如果带了参数,fillchar就取写的值
test = "ALex" v3 = test.center(20)
v4 = test.center(20,"国")
print(v3)
print(v4) #结果
ALex
国国国国国国国国ALex国国国国国国国国
ljust():字符串左对齐,其余宽度用指定字符填充
rjust():字符串右对齐,其余宽度用指定字符填充
zfill():默认只能用0填充,不能指定填充字符
test = "alex"
v = test.ljust(20,"*") # 字符串左对齐,其余宽度用指定字符填充
print(v)
v1 = test.rjust(20,"¥") # 字符串右对齐,其余宽度用指定字符填充
print(v1)
v2 = test.zfill(20) # 默认只能用0填充
print(v2) # 结果
alex****************
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥alex
0000000000000000alex
count(self, sub, start=None, end=None):去字符串中寻找子序列(子字符)出现的次数,start:表示开始查找的位置,end:表示查找结束的位置
test = "ALexalexr"
v = test.count("ex")
print(v) v1 = test.count("ex",5,6)
print(v1) #结果
2
0
string.encode(encoding='UTF-8', errors='strict'):以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace'
endswith(self, suffix, start=None, end=None):表示以什么什么结尾,返回值是布尔值
test = "ALexalexr"
v1 = test.endswith("r")
v2 = test.endswith("xr",4,6)
print(v1)
print(v2)
#结果
True
False
startswith(self, suffix, start=None, end=None):表示以什么什么开始,返回值是布尔值
test = "ALexalexr"
v1 = test.startswith("ALe")
v2 = test.startswith("a",4,6)
print(v1)
print(v2)
#结果
True
True
find():从开始往后寻找,找到第一个匹配字符后,返回它的索引位置
test = "alexalex"
v = test.find("ex")
print(v) #结果
2
find(self, suffix, start=None, end=None):start表示起始寻找的位置,end表示结束寻找的位置 [start,end)
v1 = test.find("ex", 5, 7)
print(v1)
v2 = test.find("ex", 5, 8)
print(v2)
#结果
-1 表示没有找到
6
结论:[start, end) 左闭右开区间
index():寻找字符在字符串中是否存在,并返回位置索引值
test = "alexalex"
v = test.index("ex")
print(v) v1 = test.index("")
print(v1) # 没有找到,直接就程序报错了。 # 结论
find()找到后返回的也是位置索引,index()也是返回位置索引,但是find()找到不到的时候返回-1,index()找不到的时候程序报错,所以,实践中常用find()
format(): 格式化,将一个字符串中的占位符替换为指定的值,有两种方式:
1. format()里通过指定name 和 a 的对应的具体的值进行格式化
test = "I am {name}, age {a}" # {name},{a}是占位符
print(test)
v = test.format(name = "alex", a = 19)
print(v)
#结果
I am {name}, age {a}
I am alex, age 19
2. format()里不指定具体的占位符对应的值,就会按照占位符的顺序进行替换
test = "I am {0}, age {1}"
print(test)
#结果
I am {0}, age {1}
v = test.format("alex", 19)
print(v)
#结果
I am alex, age 19
format()三种方法更直观的示例:
res='{} {} {}'.format('egon',18,'male')
res='{1} {0} {1}'.format('egon',18,'male')
res='{name} {age} {sex}'.format(sex='male',name='egon',age=18)
format_map():格式化,传入的值是按字典的键值对方式传入的,其功能与format一样
test = "I am {name}, age {a}"
v3 = test.format_map({"name":"alex", "a":19})
print(v3)
#结果
I am alex, age 19
isalnum():判断字符串中是否只包含 字母和数字,如果还包含其他字符,返回FALSE,只有数字或字母,返回TURE
test = "alexalex898_+"
print(test.isalnum()) test = "alexalex898_"
print(test.isalnum()) test = "alexalex898"
print(test.isalnum()) #结果
False
False
True
isalpha():判断字符串中是否只包含 字母,如果还包含其他字符,返回FALSE,只有字母,返回TURE
test = "adfad"
print(test.isalpha()) test1 = "adfad2"
print(test1.isalpha()) #结果
True
False
expandtabs():断句,可以制作表格,如下示例:
以20个字符为一组进行断句,如果没有满20个字符,就遇到了\t, 剩下的字符\t自动会以空格补齐。
比如,username是8个字符,就遇到了\t, 还差12个字符才够20个一组,所以剩下12个字符就以12个空格补齐
test = "username\temail\tpassword\nlaiying\tlaying@163.com\t78749798\nlaiying\tlaying@163.com\t1234567" print(test.expandtabs(20)) #结果
username email password
laiying laying@163.com 78749798
laiying laying@163.com 1234567
isdecimal():判断当前字符串输入的是否为数字
isdigit():判断当前字符串输入的是否为数字,也可以判断其他形式的数字,而isdecimal()则不可以
isnumeric():判断字符串是否是数字,可以判断中文,特殊符号的数字
test = ""
print(test.isdecimal()) # True
print(test.isdigit()) # True
print(test.isnumeric()) # True test1 = "②"
print(test1.isdecimal()) # False
print(test1.isdigit()) # True
print(test1.isnumeric()) # True test2 = "二"
print(test2.isdecimal()) # False
print(test2.isdigit()) # False
print(test2.isnumeric()) # True
swapcase():大小写字母转换
test = "alex"
print(test.swapcase()) # ALEX test1 = "AlsdR"
print(test1.swapcase()) # aLSDr
isidentifier():判断标识符的起名是否符合规范,符合返回TRUE,不符合返回FALSE
标识符起名,以字母,数字,下划线组成,但是开通不能是数字
a1 = "jakd_87943"
a2 = "87943jakd_"
print(a1.isidentifier()) # True
print(a2.isidentifier()) # False
isprintable():是否存在不可显示的字符
\t:表示制表符
\n:表示换行
test = "fadjajk"
print(test.isprintable()) # True test1 = "fadjajk\nfjakdjf"
test2 = "fadjajk\tadfd"
print(test1.isprintable()) #False
print(test2.isprintable()) #False
isspace():判断是否全部字符串都是空格。 即判断是否为空字符串
test = "fadjajk"
print(test.isspace()) # False
test1 = " "
print(test1.isspace()) # True
istitle():判断是否为标题
title():将字符串变成标题
# 标题的首字母都是大写的
test = "Return True if all cased chakd"
print(test.istitle()) # False #将字符串变成标题,所有首字母都大写
print(test.title()) # Return True If All Cased Chakd
join(): 将字符串中的每一个元素按照指定分割符进行拼接 ※※※※※重要※※※※※
Join()的内部原理其实是循环字符串,找到一个字符串就加上指定的分隔符,再去循环下一个
test = "你是风儿我是沙"
# 想把上面的字符串都用空格隔开
t = " "
v = t.join(test)
print(v) # 你 是 风 儿 我 是 沙
print("++".join(test)) # 你++是++风++儿++我++是++沙
a = "hello"
c = " "
b = "world" print("".join([a,b])) # hello888world
print("".join([a,b, "新家"])) # hello888world888新家
islower():判断字符串是否全部为小写
lower():将所有字母转换成小写
用法:不区分大小写可以用的方法
test = "Alex"
print(test.islower()) # False
print(test.lower()) # alex
isupper():判断字符串是否全部为大写
upper():将所有字母转换成大写
v1 = test.isupper()
v2 = test.upper()
print(v1) # False
print(v2) # ALEX
swapcase():大小写字母转换
test = "dajlkjdfakdDSFSSWDSdlfja;ldkfjfajdkfja"
print(test.swapcase()) #结果
DAJLKJDFAKDdsfsswdsDLFJA;LDKFJFAJDKFJA
lstrip() :默认去除字符串左边的空白、去除\n , \t ,如果指定去除字符的时候,连左边的所有空白和指定字符都去除掉了
rstrip() :去除字符串左边的空白
strip() :去除字符串左右两边的空白
test = " Alex "
v1 = test.lstrip() # 去除字符串左边的空白
v2 = test.rstrip() # 去除字符串左边的空白
v3 = test.strip() # 去除字符串左右两边的空白
print(v1)
print(v2)
print(v3) # 结果
Alex
Alex
Alex
test1 = " \nalex "
test2 = " alex\t " print(test1.lstrip()) # 去除\n
print(test2.rstrip()) # 去除 \t test3 = "alexed"
print(test3.lstrip("al")) # 指定字符去除
test = "xaexlex"
v = test.rstrip('9lexxexa')
print(v)
# 移除指定字符
# 遵循最多匹配
# 上面用的是从右开始往左找
1. lex有,test里就移除掉lex,然后ex也有,test就再移除ex,同样还有xa,也可以移除
maketrans():创建对应关系
translate():执行替换
maketrans()总是与translate()一起用
# test 和 test1 字符个数必须上下对应
# 然后将v里的字符进行替换,即v里如果发现你,就用1替换,返现是就用2替换 test = "你是风儿我是沙"
test1 ="" v = "你是风儿我是沙,缠缠绵绵去你家"
m = str.maketrans("你是风儿我是沙","") # 1. 先创建对应关系
new_v = v.translate(m) # 2. 再根据对应关系进行替换
print(new_v) #结果
1634567,缠缠绵绵去1家
字符串分割的方法:
partition():指定分割字符,永远只能分割三份
rpartition():指定分割字符,永远只能分割三份,从右边开始找并进行分割
partition()分割后,指定的分割字符自己可以拿得到,而split()指定的分割字符自己是拿不到的
split(self, sep=None, maxsplit=-1):指定分割字符,maxsplit默认为不指定分割次数,有几个分割字符就分割几次。 指定3,就最大分割三次
rsplit(self, sep=None, maxsplit=-1):同上,只是从右边开始查找分割
后面还会介绍一个正则表达式,也能进行字符串分割
# 字符串分割
test = "testasdfjfadssddfd"
# 按自定字符串进行分割,找到第一个匹配字符就可以进行分割
# 如果能分割,永远只能分割为三份
print(test.partition("s")) # ('te', 's', 'tasdfjfadssddfd') # 从右边开始找,找到第一个指定字符后,开始分割,永远只能分割为三份
print(test.rpartition("s")) # ('testasdfjfads', 's', 'ddfd') # 根据指定字符进行分割,而且可以指定分割的个数,想分几个分几个
# split()有个弊端, 指定的分割字符匹配到后,自己拿不到
print(test.split("s")) # ['te', 'ta', 'dfjfad', '', 'ddfd']
print(test.split('s',1)) # ['te', 'tasdfjfadssddfd']
print(test.split('s',2)) # ['te', 'ta', 'dfjfadssddfd'] # 从右开始找
print(test.rsplit('s',3)) # ['testa', 'dfjfad', '', 'ddfd']
splitlines(self, keepends=None):按照换行符\n进行分割,默认不保留换行符
test = "dajlkjdfakdjfa\nfjadlfja;ldkfj\nfajdkfja"
print(test.splitlines())
print(test.splitlines(True)) # True 表示 分割后保留换行符
print(test.splitlines(False)) # False 表示 分割后不保留换行符 # 结果
['dajlkjdfakdjfa', 'fjadlfja;ldkfj', 'fajdkfja']
['dajlkjdfakdjfa\n', 'fjadlfja;ldkfj\n', 'fajdkfja']
['dajlkjdfakdjfa', 'fjadlfja;ldkfj', 'fajdkfja']
startswith(self, prefix, start=None, end=None):判断字符串是否以某某字符开头,start 和 end 参数表示开始和结束的位置
endswith(self, suffix, start=None, end=None):判断字符串是否以某某字符结尾,start 和 end 参数表示开始和结束的位置
test = "dajlkjdfakdjfa\nfjadlfja;ldkfj\nfajdkfja"
print(test.startswith("da"))
print(test.startswith("a"))
print(test.endswith("ja"))
print(test.endswith("j"))
# 结果:
True
False
True
False
replace(self, old, new, count=None):替换字符串,old是要被替换的字符,new是替换字符, count是几,表示就替换前面几个
test = "alexalexalexalex"
print(test.replace("ex","bbbb"))
print(test.replace("ex","bbbbb", 2)) #结果
albbbbalbbbbalbbbbalbbbb
albbbbbalbbbbbalexalex
关于字符串两个练习
# 1. 将输入的下划线风格转驼峰风格
data = input("请输入一个带有下划线风格的变量名: ")
words = data.split("_") # 首先,以_进行分割,得到一个个独立的单词,是个列表
result =""
for word in words:
result += word.capitalize() # 然后将每个单词的首字母大写,再利用字符串运算符+拼接字符串
print(result)
# 2. # 写一个脚本解析url http://localhost:8080/test/data?abc=def&test=debug,得到协议,host,端口号,路径。参数
# 首先解析要注意,两个冒号解析的话,可能会越解析越乱,所以,先以?来分割
a = url1.split("?")
# 直接就可以得到参数了
# print(a) # ['http://localhost:8080/test/data', 'abc=def&test=debug']
# 然后再以:来分割
b = a[0].split(":")
# print(b) # ['http', '//localhost', '8080/test/data']
# 可以得到协议了
print("protal:{}".format(b[0]))
# 再处理得到host
print("host:{}".format(b[1].split("//")[1]))
# 以"/"分割,拿到端口,并拼接path
c=b[-1].split("/")
# 注意,有些url是没有端口的,所以就需要有异常处理或者判断
try:
d = int(c[0])
print("port:{}".format(d))
except Exception as error:
print("port:{}".format("not port in this url"))
print("path:{}{}".format("/", "/".join(c[1:])))
print("parameter: {}".format(a[-1]))
Python字符串运算符
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 |
>>>a + b 'HelloPython'
|
| * | 重复输出字符串 |
>>>a * 2 'HelloHello'
|
| [] | 通过索引获取字符串中字符 |
>>>a[1] 'e'
|
| [ : ] | 截取字符串中的一部分 |
>>>a[1:4] 'ell'
|
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True |
>>>"H" in a True
|
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True |
>>>"M" not in a True
|
| % | 格式字符串 | 请看下一章节 |
# 示例 a = "hello"
c = " "
b = "world" print(a+c+b)
# hello world
print(50 * "=")
# ==================================================
print(len(a))
# print(a[2])
# l print(a[1:-1])
# ell print(a[:])
# hello print("l" in a)
# True print("a" not in a)
# True
Python字符串转义
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other |
其它的字符以普通格式输出 |
布尔值
后面还有,12之前的某个课程里讲的,要补课
写在最前:
1. 转换: bool([])
2. 布尔值本身就是0 和 1
3.特殊情况,哪些是假?
None,空字符串,空字典,空列表,空元组,0,空集合 这几个用布尔值判断的时候都是False,其他都是真
print(bool(["dfjdak","fad"]))
print(bool([])) #结果
True
False
第七篇Python基本数据类型之数字&字符串&布尔值的更多相关文章
- Python数据类型-01.数字和布尔值
本节主要介绍Python中的基础知识中的数据类型,数字和布尔值 介绍几个知识点:1)内置函数print()的用法,直接打印括号里面的内容,或者print后跟多个输出,以逗号分隔.2)内置函数type( ...
- 【python基础语法】数字、布尔值(第1天课堂笔记)
# 导入模块 import keyword # print语句将内容输出到控制台 print("hello world!") # pep8编码规范 # 代码快速格式化快捷键:ctr ...
- python 基本数据类型之整数和布尔值
#1. 当前整数的二进制表示,以最少位数 # age = # print(age.bit_length()) #2. 获取当前数据的字节表示 # age = # v = age.to_bytes(,b ...
- Python基础之格式化输出、运算符、数字与布尔值互换以及while...else
python是一天学一点,就这样零零碎碎…… 格式化输出 %是占位符,%s是字符串格式,%d整数格式,%f是浮点数格式 name = input('输入姓名') age = input('输入年龄') ...
- js中对象转化成字符串、数字或布尔值的转化规则
js中对象可以转化成 字符串.数字.布尔值 一.对象转化成字符串: 规则: 1.如果对象有toString方法,则调用该方法,并返回相应的结果:(代码通常会执行到这,因为在所有对象中都有toStrin ...
- jsoncpp封装和解析字符串、数字、布尔值和数组
使用jsoncpp进行字符串.数字.布尔值和数组的封装与解析. 1)下载jsoncpp的代码库 百度网盘地址 :http://pan.baidu.com/s/1ntqQhIT 2)解压缩文件 json ...
- Python学习【第七篇】基本数据类型
基本数据类型 数字 2是一个整数的例子. 长整数 不过是大一些的整数. 3.23和52.3E-4是浮点数的例子,E标记表示10的幂.在这里,52.3E-4表示52.3*10-4. (-5+4j)和(2 ...
- Python基础数据类型(数字、字符串、布尔、列表、元组、字典、集合等)
数据类型 计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值.但是,计算机能处理的远不止数值,还可以处理文本.图形.音频.视频.网页等各种各样的数据,不同的数据,需要定 ...
- Python基础4:数据类型:数字 字符串 日期
[ Python 数据类型 ] 我们知道,几乎任何编程语言都具有数据类型:常见的数据类型有:字符串.整型.浮点型以及布尔类型等. Python也不例外,也有自己的数据类型,主要有以下几种: 1.数字: ...
随机推荐
- 用keytool制作证书并在tomcat配置https服务(四)
用keytool制作证书并在tomcat配置https服务(一) 用keytool制作证书并在tomcat配置https服务(二) 用keytool制作证书并在tomcat配置https服务(三) 上 ...
- 【luogu P4137 Rmq Problem / mex】 题解
题目链接:https://www.luogu.org/problemnew/show/P4137 求区间内最大没出现过的自然数 在add时要先判断会不会对当前答案产生影响,如果有就去找下一个答案. # ...
- 转载:Python中的if __name__ == '__main__'
刚开始学习Python时,对于有些书出现的函数带有“if __name__ == '__main__'”总是迷惑不解,比如<dive into Python>中开头的哪个根据输入的数字计算 ...
- Webpack4 学习笔记七 跨域服务代理
webpack 小插件使用 webpack 监听文件变化配置 webpack 处理跨域问题 Webpack 小插件使用 clean-webpack-plugin: 用于在生成之前删除生成文件夹的Web ...
- 【2018 ICPC焦作网络赛 G】Give Candies(费马小定理+快速幂取模)
There are N children in kindergarten. Miss Li bought them N candies. To make the process more intere ...
- 【CodeForces 803 C】Maximal GCD(GCD+思维)
You are given positive integer number n. You should create such strictly increasingsequence of k pos ...
- github 常用
1.创建KEY,这个文件生成完了后,要保存好公钥和私钥文件 ssh-keygen -t rsa -C "abc@mail.com" 2.github上添加ssh密钥 3.拷贝公钥信 ...
- 微信小程序引用iconfont图标字体解决方案;
1)首先,登录阿里巴巴iconfont.cn 2)新建项目 3)点击icon收藏 4)加入到test项目中 5)下载到本地解压 6)生成代码 7)复制iconfont.css到xxx.wx ...
- SQL优化之语句优化
昨天与大家分享了SQL优化中的索引优化,今天给大家聊一下,在开发过程中高质量的代码也是会带来优化的 网上关于SQL优化的教程很多,但是比较杂乱.整理了一下,写出来跟大家分享一下,其中有错误和不足的地方 ...
- Angular : 绑定, 参数传递, 路由
如何把jquery导入angular npm install jquery --savenpm install @type/jquery --save-dev "node_modules/z ...