MLPClassifier 隐藏层不包括输入和输出
多层感知机(MLP)原理简介
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
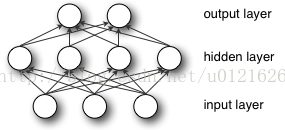
从上图可以看到,多层感知机层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
输入层没什么好说,你输入什么就是什么,比如输入是一个n维向量,就有n个神经元。
隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是
f(W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数:
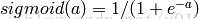
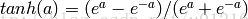
最后就是输出层,输出层与隐藏层是什么关系?其实隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。
sklearn.neural_network.MLPClassifier
- class
sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100, ), activation=’relu’, solver=’adam’, alpha=0.0001, batch_size=’auto’, learning_rate=’constant’, learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10)[source] -
Multi-layer Perceptron classifier.
This model optimizes the log-loss function using LBFGS or stochastic gradient descent.
New in version 0.18.
Parameters: - hidden_layer_sizes : tuple, length = n_layers - 2, default (100,)
-
The ith element represents the number of neurons in the ith hidden layer.
- activation : {‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, default ‘relu’
-
Activation function for the hidden layer.
- ‘identity’, no-op activation, useful to implement linear bottleneck, returns f(x) = x
- ‘logistic’, the logistic sigmoid function, returns f(x) = 1 / (1 + exp(-x)).
- ‘tanh’, the hyperbolic tan function, returns f(x) = tanh(x).
- ‘relu’, the rectified linear unit function, returns f(x) = max(0, x)
- solver : {‘lbfgs’, ‘sgd’, ‘adam’}, default ‘adam’
-
The solver for weight optimization.
- ‘lbfgs’ is an optimizer in the family of quasi-Newton methods.
- ‘sgd’ refers to stochastic gradient descent.
- ‘adam’ refers to a stochastic gradient-based optimizer proposed by Kingma, Diederik, and Jimmy Ba
Note: The default solver ‘adam’ works pretty well on relatively large datasets (with thousands of training samples or more) in terms of both training time and validation score. For small datasets, however, ‘lbfgs’ can converge faster and perform better.
- alpha : float, optional, default 0.0001
-
L2 penalty (regularization term) parameter.
- batch_size : int, optional, default ‘auto’
-
Size of minibatches for stochastic optimizers. If the solver is ‘lbfgs’, the classifier will not use minibatch. When set to “auto”, batch_size=min(200, n_samples)
- learning_rate : {‘constant’, ‘invscaling’, ‘adaptive’}, default ‘constant’
-
Learning rate schedule for weight updates.
- ‘constant’ is a constant learning rate given by ‘learning_rate_init’.
- ‘invscaling’ gradually decreases the learning rate
learning_rate_at each time step ‘t’ using an inverse scaling exponent of ‘power_t’. effective_learning_rate = learning_rate_init / pow(t, power_t) - ‘adaptive’ keeps the learning rate constant to ‘learning_rate_init’ as long as training loss keeps decreasing. Each time two consecutive epochs fail to decrease training loss by at least tol, or fail to increase validation score by at least tol if ‘early_stopping’ is on, the current learning rate is divided by 5.
Only used when
solver='sgd'. - learning_rate_init : double, optional, default 0.001
-
The initial learning rate used. It controls the step-size in updating the weights. Only used when solver=’sgd’ or ‘adam’.
- power_t : double, optional, default 0.5
-
The exponent for inverse scaling learning rate. It is used in updating effective learning rate when the learning_rate is set to ‘invscaling’. Only used when solver=’sgd’.
概述
以监督学习为例,假设我们有训练样本集 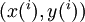 ,那么神经网络算法能够提供一种复杂且非线性的假设模型
,那么神经网络算法能够提供一种复杂且非线性的假设模型 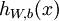 ,它具有参数
,它具有参数 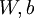 ,可以以此参数来拟合我们的数据。
,可以以此参数来拟合我们的数据。
为了描述神经网络,我们先从最简单的神经网络讲起,这个神经网络仅由一个“神经元”构成,以下即是这个“神经元”的图示:
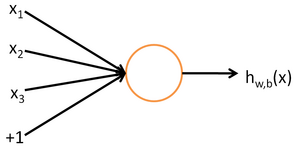
这个“神经元”是一个以 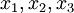 及截距
及截距 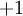 为输入值的运算单元,其输出为
为输入值的运算单元,其输出为 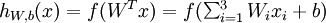 ,其中函数
,其中函数 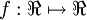 被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数
被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数 
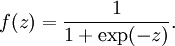
可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归(logistic regression)。
虽然本系列教程采用sigmoid函数,但你也可以选择双曲正切函数(tanh):
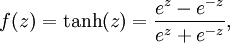
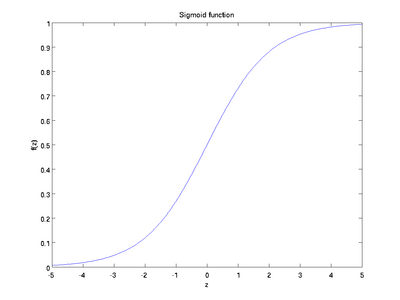
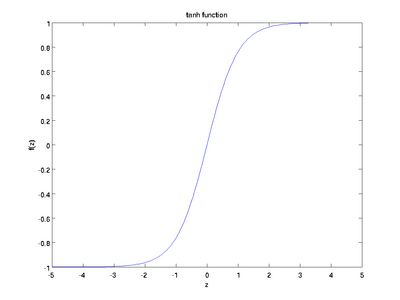
以下分别是sigmoid及tanh的函数图像
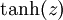 函数是sigmoid函数的一种变体,它的取值范围为
函数是sigmoid函数的一种变体,它的取值范围为 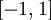 ,而不是sigmoid函数的
,而不是sigmoid函数的 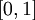 。
。
注意,与其它地方(包括OpenClassroom公开课以及斯坦福大学CS229课程)不同的是,这里我们不再令 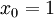 。取而代之,我们用单独的参数
。取而代之,我们用单独的参数 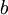 来表示截距。
来表示截距。
最后要说明的是,有一个等式我们以后会经常用到:如果选择 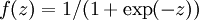 ,也就是sigmoid函数,那么它的导数就是
,也就是sigmoid函数,那么它的导数就是 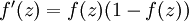 (如果选择tanh函数,那它的导数就是
(如果选择tanh函数,那它的导数就是 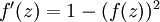 ,你可以根据sigmoid(或tanh)函数的定义自行推导这个等式。
,你可以根据sigmoid(或tanh)函数的定义自行推导这个等式。
神经网络模型
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络:
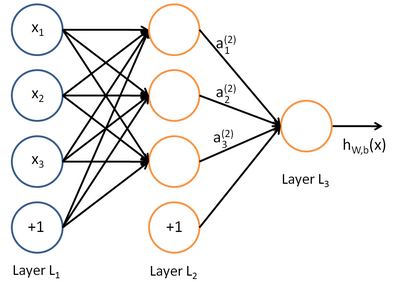
我们使用圆圈来表示神经网络的输入,标上“”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
我们用 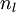 来表示网络的层数,本例中
来表示网络的层数,本例中 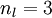 ,我们将第
,我们将第  层记为
层记为 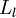 ,于是
,于是 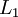 是输入层,输出层是
是输入层,输出层是 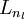 。本例神经网络有参数
。本例神经网络有参数 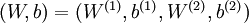 ,其中
,其中 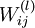 (下面的式子中用到)是第 层第
(下面的式子中用到)是第 层第  单元与第
单元与第 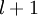 层第
层第  单元之间的联接参数(其实就是连接线上的权重,注意标号顺序),
单元之间的联接参数(其实就是连接线上的权重,注意标号顺序), 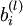 是第 层第 单元的偏置项。因此在本例中,
是第 层第 单元的偏置项。因此在本例中, 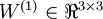 ,
, 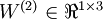 。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用
。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用 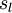 表示第 层的节点数(偏置单元不计在内)。
表示第 层的节点数(偏置单元不计在内)。
我们用 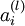 表示第 层第 单元的激活值(输出值)。当
表示第 层第 单元的激活值(输出值)。当 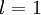 时,
时, 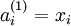 ,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合 ,我们的神经网络就可以按照函数 来计算输出结果。本例神经网络的计算步骤如下:
,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合 ,我们的神经网络就可以按照函数 来计算输出结果。本例神经网络的计算步骤如下:
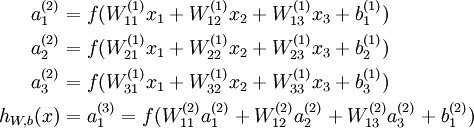
我们用 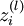 表示第 层第 单元输入加权和(包括偏置单元),比如,
表示第 层第 单元输入加权和(包括偏置单元),比如, 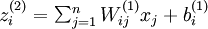 ,则
,则 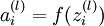 。
。
这样我们就可以得到一种更简洁的表示法。这里我们将激活函数 扩展为用向量(分量的形式)来表示,即 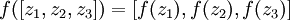 ,那么,上面的等式可以更简洁地表示为:
,那么,上面的等式可以更简洁地表示为:
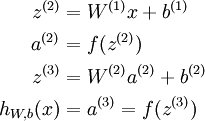
我们将上面的计算步骤叫作前向传播。回想一下,之前我们用 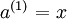 表示输入层的激活值,那么给定第 层的激活值
表示输入层的激活值,那么给定第 层的激活值  后,第 层的激活值
后,第 层的激活值 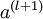 就可以按照下面步骤计算得到:
就可以按照下面步骤计算得到:
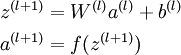
将参数矩阵化,使用矩阵-向量运算方式,我们就可以利用线性代数的优势对神经网络进行快速求解。
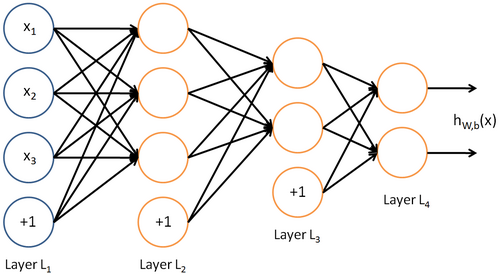
目前为止,我们讨论了一种神经网络,我们也可以构建另一种结构的神经网络(这里结构指的是神经元之间的联接模式),也就是包含多个隐藏层的神经网络。最常见的一个例子是 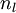 层的神经网络,第
层的神经网络,第 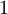 层是输入层,第 层是输出层,中间的每个层 与层 紧密相联。这种模式下,要计算神经网络的输出结果,我们可以按照之前描述的等式,按部就班,进行前向传播,逐一计算第
层是输入层,第 层是输出层,中间的每个层 与层 紧密相联。这种模式下,要计算神经网络的输出结果,我们可以按照之前描述的等式,按部就班,进行前向传播,逐一计算第 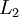 层的所有激活值,然后是第
层的所有激活值,然后是第 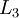 层的激活值,以此类推,直到第 层。这是一个前馈神经网络的例子,因为这种联接图没有闭环或回路。
层的激活值,以此类推,直到第 层。这是一个前馈神经网络的例子,因为这种联接图没有闭环或回路。
神经网络也可以有多个输出单元。比如,下面的神经网络有两层隐藏层: 及 ,输出层 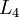 有两个输出单元。
有两个输出单元。
要求解这样的神经网络,需要样本集 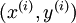 ,其中
,其中 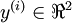 。如果你想预测的输出是多个的,那这种神经网络很适用。(比如,在医疗诊断应用中,患者的体征指标就可以作为向量的输入值,而不同的输出值
。如果你想预测的输出是多个的,那这种神经网络很适用。(比如,在医疗诊断应用中,患者的体征指标就可以作为向量的输入值,而不同的输出值 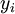 可以表示不同的疾病存在与否。)
可以表示不同的疾病存在与否。)
中英文对照
neural networks 神经网络
activation function 激活函数
hyperbolic tangent 双曲正切函数
bias units 偏置项
activation 激活值
forward propagation 前向传播
feedforward neural network 前馈神经网络(参照Mitchell的《机器学习》的翻译)
MLPClassifier 隐藏层不包括输入和输出的更多相关文章
- BackgroundWorker 的输入、输出参数、进度条与文字刷新、取消机制、返回事件
1. 定义全局变量 BackgroundWorker backgroundwoker; 2. 点击开始按钮或其它时机初始化 backgroundwoker = new BackgroundWorker ...
- 人工神经网络,支持任意数量隐藏层,多层隐藏层,python代码分享
http://www.cnblogs.com/bambipai/p/7922981.html------误差逆传播算法讲解 人工神经网络包含多种不同的神经网络,此处的代码建立的是多层感知器网络,代码以 ...
- Neural Networks and Deep Learning(week3)Planar data classification with one hidden layer(基于单隐藏层神经网络的平面数据分类)
Planar data classification with one hidden layer 你会学习到如何: 用单隐层实现一个二分类神经网络 使用一个非线性激励函数,如 tanh 计算交叉熵的损 ...
- C++_IO与文件5-文件的输入与输出
大多数计算机程序都使用了文件.文件本身是存储在某种设备上的一系列字节. 通常,操作系统管理文件,跟踪它们的位置.大小.创建时间等. 除非在操作系统级别上编程,否则通常不必担心这些事情. 真正需要的是将 ...
- C++——输入、输出和文件
一.C++输入和输出概述 1.1.流和缓冲区 C++程序把输入和输出看作字节流.输入时,程序从输入流中抽取字节:输出时,程序将字节插入到输出流中.对于面相文本的程序,每个字节代表一个字符,更通俗地说, ...
- 『TensorFlow』单&双隐藏层自编码器设计
计算图设计 很简单的实践, 多了个隐藏层 没有上节的高斯噪声 网络写法由上节的面向对象改为了函数式编程, 其他没有特别需要注意的,实现如下: import numpy as np import mat ...
- Caffe学习笔记(三):Caffe数据是如何输入和输出的?
Caffe学习笔记(三):Caffe数据是如何输入和输出的? Caffe中的数据流以Blobs进行传输,在<Caffe学习笔记(一):Caffe架构及其模型解析>中已经对Blobs进行了简 ...
- (转)MyBatis框架的学习(四)——Mapper.xml文件中的输入和输出映射以及动态sql
http://blog.csdn.net/yerenyuan_pku/article/details/71893689 前面对MyBatis框架的学习中,我们对Mapper.xml映射文件多少有些了解 ...
- LSTM入门学习——本质上就是比RNN的隐藏层公式稍微复杂了一点点而已
LSTM入门学习 摘自:http://blog.csdn.net/hjimce/article/details/51234311 下面先给出LSTM的网络结构图: 看到网络结构图好像很复杂的样子,其实 ...
随机推荐
- 0x09 Python连接MySQL数据库
本文介绍Python3连接MySQL的第三方库--PyMySQL的基本使用. PyMySQL介绍 PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中 ...
- Linux中命令查找顺序
第一优先级:用绝对路径或相对路径执行的命令第二优先级:别名指定的命令第三优先级:Bash内部命令第四优先级:$PATH环境变量定义的目录查找顺序中找到的第一个命令
- TLS and SSL
SSL:(Secure Socket Layer,安全套接字层),位于可靠的面向连接的网络层协议和应用层协议之间的一种协议层.SSL通过互相认证.使用数字签名确保完整性.使用加密确保私密性,以实现客户 ...
- 面试题2:实现Singleton模式(Java实现)
SIngleton(单例)设计模式 它是最简单的常用的设计模式之一,设计模式在面向对象程序设计中起着举足轻重的作用,Singleton是唯一一个能够用短短几十行代码完整实现的模式. public cl ...
- IT basic knowledge
LAMP: Linux Apache MySQL PHP URL & URI: 统一资源定位符是统一资源标志符的一个下种.统一资源标志符确定一个资源,而统一资源定位符不但确定一个资源, 而且还 ...
- Linux下运行java项目
最近初步接触了linux,感觉很有新鲜感.之前在windows下干过的事情也便想到在linux环境下实现一下.正好手头在编java,就想既然java可以在windows的DOS操作下运行,是不是也可以 ...
- C语言中auto,register,static,const,volatile的区别
1)auto 这个关键字用于声明变量的生存期为自动,即将不在任何类.结构.枚举.联合和函数中定义的变量视为全局变量,而在函数中定义的变量视为局部变量.这个关键字不怎么多写,因为所有的变量默认就是aut ...
- OpenGL学习进程(3)第一课:初始化窗体
本节是OpenGL学习的第一个课时,下面介绍如何初始化一个窗体: (1)显示一个有蓝色背景的窗体: #include <GL/glut.h> #include <st ...
- hadoop06---多线程
.1.1. 实现线程的两种方式 1.继承Thread的方式 见代码MyThreadWithExtends 2.声明实现 Runnable 接口的方式 见代码MyThreadWithImpliment ...
- 【HackerRank】Maximizing XOR
给定两个整数:L 和 R ∀ L ≤ A ≤ B ≤ R, 找出 A xor B 的最大值. 输入格式 第一行包含 L 第一行包含 R 数据范围 1 ≤ L ≤ R ≤ 103 输出格式 输出最大的异 ...