基于Storm的WordCount
Storm WordCount 工作过程
Storm 版本:
1、Spout 从外部数据源中读取数据,随机发送一个元组对象出去;
2、SplitBolt 接收 Spout 中输出的元组对象,将元组中的数据切分成单词,并将切分后的单词发射出去;
3、WordCountBolt 接收 SplitBolt 中输出的单词数组,对里面单词的频率进行累加,将累加后的结果输出。
Java 版本:
1、读取文件中的数据,一行一行的读取;
2、将读到的数据进行切割;
3、对切割后的数组中的单词进行计算。
Hadoop 版本:
1、按行读取文件中的数据;
2、在 Mapper()函数中对每一行的数据进行切割,并输出切割后的数据数组;
3、接收 Mapper()中输出的数据数组,在 Reducer()函数中对数组中的单词进行计算,将计算后的统计结果输出。
源代码
storm的配置、eclipse里maven的配置以及创建项目部分省略。
Mainclass
package com.test.stormwordcount;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class MainClass {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
//创建一个 TopologyBuilder
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("SpoutBolt", new SpoutBolt(), 2); tb.setBolt("SplitBolt", new SplitBolt(), 2).shuffleGrouping("SpoutBolt");
tb.setBolt("CountBolt", new CountBolt(), 4).fieldsGrouping("SplitBolt", new Fields("word"));
//创建配置
Config conf = new Config();
//设置 worker 数量
conf.setNumWorkers(2);
//提交任务
//集群提交
//StormSubmitter.submitTopology("myWordcount", conf, tb.createTopology());
//本地提交
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("myWordcount", conf, tb.createTopology());
}
}
SplitBolt 部分
package com.test.stormwordcount;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class SplitBolt extends BaseRichBolt{
OutputCollector collector;
/** * 初始化 */
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/** * 执行方法 */
public void execute(Tuple input) {
String line = input.getString(0);
String[] split = line.split(" ");
for (String word : split) {
collector.emit(new Values(word));
}
}
/** * 输出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
CountBolt 部分
package com.test.stormwordcount;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
public class CountBolt extends BaseRichBolt{
OutputCollector collector;
Map<String, Integer> map = new HashMap<String, Integer>();
/** * 初始化 */
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/** * 执行方法 */
public void execute(Tuple input) {
String word = input.getString(0);
if(map.containsKey(word)){
Integer c = map.get(word);
map.put(word, c+1);
}else{
map.put(word, 1);
}
//测试输出
System.out.println("结果:"+map);
}
/** * 输出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
SpoutBolt 部分
package com.test.stormwordcount;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class SpoutBolt extends BaseRichSpout{
SpoutOutputCollector collector;
/** * 初始化方法 */
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/** * 重复调用方法 */
public void nextTuple() {
collector.emit(new Values("hello world this is a test"));
}
/** * 输出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("test"));
}
}
POM.XML 文件内容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.test</groupId>
<artifactId>stormwordcount</artifactId>
<version>0.9.6</version>
<packaging>jar</packaging>
<name>stormwordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.test.stormwordcount.MainClass</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
遇到的问题
基于Storm的WordCount需要eclipse安装了maven插件,之前的大数据实践安装的eclipse版本为Eclipse IDE for Eclipse Committers4.5.2,这个版本不自带maven插件,后续安装失败了几次(网上很多的教程都已经失效),这里分享一下我成功安装的方法:
使用链接下载,Help->Install New SoftWare
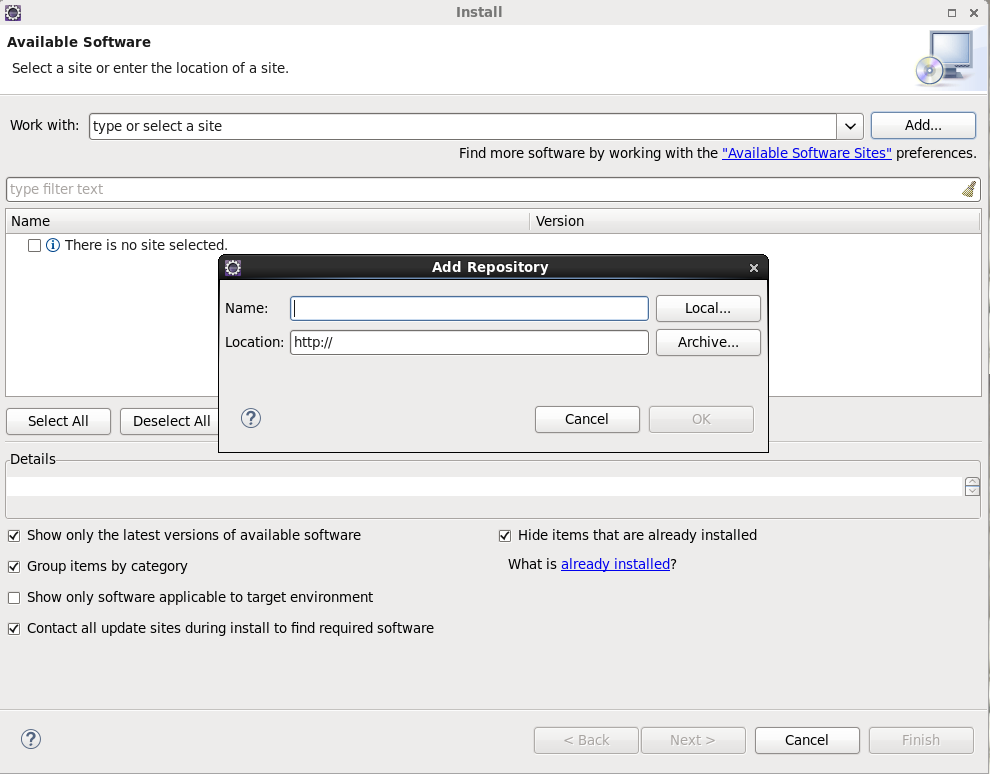
点击Add,name输入随意,在location输入下载eclipse的maven插件,下载地址可以这样获取
点击连接:http://www.eclipse.org/m2e/index.html 进入网站后点击download,拉到最下面可以看到很多eclipse maven插件的版本和发布时间,选在适合eclipse的版本复制链接即可。建议取消选中Contack all update sites during install to find required software(耗时太久)。
但是安装成功后还是无法配置(这里原因不太清楚,没找到解决办法),就直接上官网换成自带maven插件的JavaEE IDE了...
后续的maven的配置这些都比较顺利,第一次创建maven-archetype-quickstat项目报错,试了网上很多办法都还没成功,然后打开 Windows->Preferencs->Maven->Installation发现之前配置了的maven的安装路径没了...重新配置了下就可以创建项目了。
最后运行成功的结果:

基于Storm的WordCount的更多相关文章
- 一种基于Storm的可扩展即时数据处理架构思考
问题引入 使用storm可以方便的构建一种集群式的数据框架,并通过定义topo来实现业务逻辑. 但使用topo存在一个缺点, topo的处理能力来自于其启动时设置的worker数目,在很多情况下,我们 ...
- 基于storm的在线关联规则
基于storm的在线视频推荐算法.算法根据youtube的推荐算法 算法相对简单,能够觉得是关联规则仅仅挖掘频繁二项集.以下给出与storm的结合实如今线实时算法 , 关于storm见这里.首先给出 ...
- [翻译] Trident-ML:基于storm的实时在线机器学习库
最近在看一些在线机器学习的东西,看到了trident-ml, 觉得比较有意思,就翻译了一下,方便有兴趣的读者学习. 本文为作者(掰棒子熊)翻译自https://github.com/pmerienne ...
- 三:基于Storm的实时处理大数据的平台架构设计
一:元数据管理器==>元数据管理器是系统平台的“大脑”,在任务调度中有着重要的作用[1]什么是元数据?--->中介数据,用于描述数据属性的数据.--->具体类型:描述数据结构,数据的 ...
- [转]基于Storm的实时数据处理方案
1 文档说明 该文档描述的是以storm为主体的实时处理架构,该架构包括了数据收集部分,实时处理部分,及数据落地部分. 关于不同部分的技术选型与业务需求及个人对相关技术的熟悉度有关,会一一进行分析. ...
- 在Spark shell中基于Alluxio进行wordcount交互式分析
Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以 ...
- storm实战:基于storm,kafka,mysql的实时统计系统
公司对客户开放多个系统,运营人员想要了解客户使用各个系统的情况,在此之前,数据平台团队已经建设好了统一的Kafka消息通道. 为了保证架构能够满足业务可能的扩张后的性能要求,选用storm来处理各个应 ...
- 基于Storm的工程中使用log4j
最近使用Storm开发,发现log4j死活打不出debug级别的日志,网上搜到的关于log4j配置的方法都试过了,均无效. 最终发现问题是这样的:最新的storm使用的日志系统已经从log4j切换到了 ...
- 基于Storm 分布式BP神经网络,将神经网络做成实时分布式架构
将神经网络做成实时分布式架构: Storm 分布式BP神经网络: http://bbs.csdn.net/topics/390717623 流式大数据处理的三种框架:Storm,Spark和Sa ...
随机推荐
- iOS核心动画高级技巧-1
1. 图层树 图层的树状结构 巨妖有图层,洋葱也有图层,你有吗?我们都有图层 -- 史莱克 Core Animation其实是一个令人误解的命名.你可能认为它只是用来做动画的,但实际上它是从一个叫做L ...
- bash:加减乘除(bc、let)
bc *. echo "$2 * $2" | bc > file let 如果只是 let a=1 和 a=1,它们没有区别,但是 let 还可以用于带赋值的运算,例如 le ...
- 函数式接口的使用 (Function、Predicate、Supplier、Consumer)
参考:https://blog.csdn.net/jmj18756235518/article/details/81490966 函数式接口 定义:有且只有一个抽象方法的接口 Function< ...
- Jmeter---第一天配置中文环境、安装jmeter插件
一:安装就不在赘述,百度有很多优秀的文章.接下来开始我自己的学习笔记 二:设置JMETER,切换中文环境. 首先打开jmeter的安装目录,找到bin文件目录中的jmeter.propertie 打开 ...
- ArcGIS Desktop10.4安装教程
准备内容 安装环境:win10*64位专业版 安装文件:ArcGIS_Desktop_1041_150996.iso 破解文件:10.4.1crackOnly 请都以管理员身份运行安装程序 安装步骤 ...
- easywechat微信开发SDK之小微商户进件(一)
微信本身不提供小微商户进件的SDK,偶然发现easywechat这么个东西,官网地址是https://www.easywechat.com/ 整合了微信开发中常用的接口,包括微信公众号相关接口,微信 ...
- java 获取当前年份 月份 日期
import java.util.Calendar; public class Main { public static void main(String[] args) { Calendar ...
- Qt的安装
由于之前用的vs2017是集成c++环境的,加之dev c++ 编码管理起来不是很方便,Mytc (win10不支持) ,所以转而向Qt 开发工具,以下是大概安装过程 下载地址 清华源:https:/ ...
- Stack Overflow上59万浏览量的提问:为什么会发生ArrayIndexOutOfBoundsException?
在逛 Stack Overflow 的时候,发现了一些访问量像昆仑山一样高的问题,比如说这个:为什么会发生 ArrayIndexOutOfBoundsException?这样看似简单到不值得一问的问题 ...
- VLAN实验1(VLAN基础配置及Access接口)
本实验基于<HCNA网 络技术实验指南> 本实验使用eNSP软件 原理概述: 早期的局域网技术是基于总线型结构的.总线型拓扑结构是由一根单电缆连接着所 有主机,这种局域网技术存在着冲突域问 ...