jdk1.8HashMap底层数据结构:散列表+链表+红黑树,jdk1.8HashMap数据结构图解+源码说明
一、前言
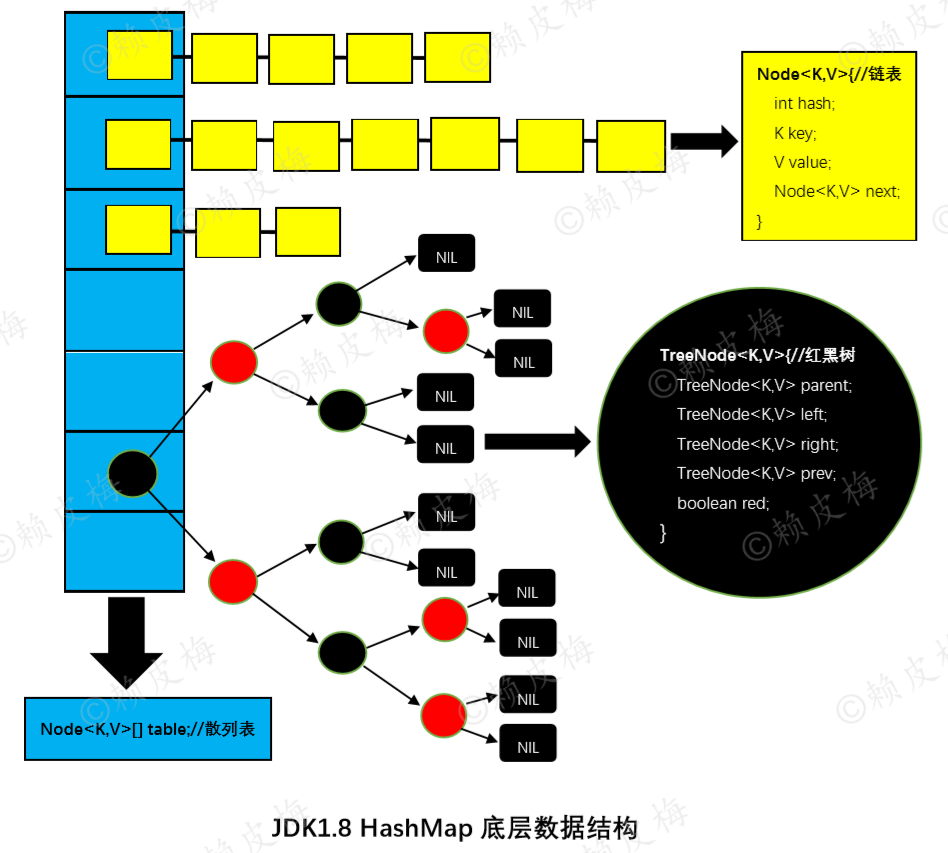
本文由jdk1.8源码整理而得,附自制jdk1.8底层数据结构图,并截取部分源码加以说明结构关系。
二、jdk1.8 HashMap底层数据结构图
三、源码
1.散列表(Hash table,也叫哈希表):
/**
* 表,第一次使用时初始化(而非实例化集合时进行初始化),并根据需要调整大小。当分配时,长度总是2的幂。(在某些操作中,我们还允许长度为零,以允许当前不需要的引导机制。)
*/
transient Node<K,V>[] table;
2.链表:
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
……
}
3.红黑树:
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
……
}
四、问题探究
1.散列表后面跟的“链表、红黑树”是怎么来的,都解决了哪些问题?
答:
①链表的由来:Hash碰撞:不同的元素通过hash算法可能会得到相同的hash值,如果都放同一个桶里,后面放进去的就会覆盖前面放的,所以为了解决hash碰撞时元素被覆盖的问题,就有了在桶里放链表。
②红黑树的由来:假设现在HashMap集合中大多数的元素都放到了同一个桶里(由hash值计算而得的桶的位置相同),那么这些元素就在这个桶后面连成了链表。现在需要查询某个元素,那么此时的查询效率就很慢了,它是在做链表查询( O(N) 的查询效率)。为了解决这个问题,就引入了红黑树( log(n) 的查询效率):当链表到达一定长度时就在链表的后面创建红黑树。
③其实,“尽量避免hash 冲突,让元素较为均匀的放置到每个桶”才是查询效率最高的( O(1) 的查询效率),这和hash算法的实现息息相关,这里不做深究。
2.如图可知,散列表后面跟的数据结构有可能是链表,也有可能是红黑树。散列表后面跟什么数据结构是怎么确定的?
答:
①链表节点转换成红黑树节点的阈值, 节点数 >= 8 就转:
static final int TREEIFY_THRESHOLD = 8;
②红黑树节点转换链表节点的阈值, 节点数 <= 6 就转:
static final int UNTREEIFY_THRESHOLD = 6;
③转红黑树时, table的最小长度:
static final int MIN_TREEIFY_CAPACITY = 64;
jdk1.8HashMap底层数据结构:散列表+链表+红黑树,jdk1.8HashMap数据结构图解+源码说明的更多相关文章
- Map集合、散列表、红黑树介绍
前言 声明,本文用得是jdk1.8 前面已经讲了Collection的总览和剖析List集合: Collection总览 List集合就这么简单[源码剖析] 原本我是打算继续将Collection下的 ...
- Java HashMap源码分析(含散列表、红黑树、扰动函数等重点问题分析)
写在最前面 这个项目是从20年末就立好的 flag,经过几年的学习,回过头再去看很多知识点又有新的理解.所以趁着找实习的准备,结合以前的学习储备,创建一个主要针对应届生和初学者的 Java 开源知识项 ...
- [数据结构与算法]RED-BLACK(红黑)树的实现TreeMap源码阅读
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- 红黑树插入操作---以JDK 源码为例
红黑树遵循的条件: 1.根节点为黑色. 2.外部节点(叶子节点)为黑色. 3.红色节点的孩子节点为黑色.(由此,红色节点的父节点也必为黑色) 4.从根节点到任一外部节点的路径上,黑节点的数量相同. 节 ...
- jdk1.8 HashMap 实现 数组+链表/红黑树
转载至 http://www.cnblogs.com/leesf456/p/5242233.html 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Ja ...
- [数据结构1.2-线性表] 动态数组ArrayList(.NET源码学习)
[数据结构1.2-线性表] 动态数组ArrayList(.NET源码学习) 在C#中,存在常见的九种集合类型:动态数组ArrayList.列表List.排序列表SortedList.哈希表HashTa ...
- 运行OpenGL红宝书第9版源码时Visual Studio提示“无法启动程序...ALL_BUILD。拒绝访问“的问题的解决办法
问题描述: OpenGL红宝书第9版源码采用CMake编译后,用相应的Visual Studio(如VS2012)打开“vermilion9.sln”解决方案,并运行时Visual Studio提示“ ...
- Python数据结构——散列表
散列表的实现常常叫做散列(hashing).散列仅支持INSERT,SEARCH和DELETE操作,都是在常数平均时间执行的.需要元素间任何排序信息的操作将不会得到有效的支持. 散列表是普通数组概念的 ...
- 数据结构---散列表查找(哈希表)概述和简单实现(Java)
散列表查找定义 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,是的每个关键字key对应一个存储位置f(key).查找时,根据这个确定的对应关系找到给定值的key的对应f(key) ...
随机推荐
- 【转】php7对redis的扩展及redis主从搭建
一:redis安装 1:下载并安装 cd /home/software wget http://download.redis.io/releases/redis-3.2.3.tar.gz ta ...
- uint16,uint32是什么?
记得之前在刷笔试题的时候就看见过这个问题,发现当时上网百度后又忘了. 最近在看CryEngine3引擎代码的时候又晕了,趁现在赶紧记下来~ 在查看CE3的代码时我发现了这个变量,TFlowNodeId ...
- Spring注解之-自定义注解
1.自定义注解,先自定义三个水果属性的注解 元注解: java.lang.annotation提供了四种元注解,专门注解其他的注解(在自定义注解的时候,需要使用到元注解): @Documented ...
- bitmap-如何判断某个整数是否存在40亿个整数中?
有这样一道面试题:现有40亿个整数,如果再给定一个新的整数,怎么判断这个整数是否在这40亿个整数中? 你可能首先会想到用一个set存储,那个新数只需判断是否在set中.但是如果用set存储的话,如果一 ...
- 美化Div的边框
CSS修饰Div边框 大部分时候,Div的边框真的做的太丑了,如果不用很多样式来修饰的话,它永远都是那么的突兀.作为一个后端开发,前端菜鸡,在没有设计和前端开发自己独自做项目的时候常常会遇到Div边框 ...
- kafka入门(一)简介
1 什么是kafk Apache kafka是消息中间件的一种,在开始学习之前,先简单的解释一下什么是消息中间件. 举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就 ...
- C语言学习推荐《C语言参考手册(原书第5版)》下载
- [Usaco2007 Open]Fliptile 翻格子游戏题解
问题 B: [Usaco2007 Open]Fliptile 翻格子游戏 时间限制: 5 Sec 内存限制: 128 MB 题目描述 Farmer John knows that an intell ...
- 番外:深浅copy
进击のpython 深浅copy copy是什么意思? 复制 (又学一个单词!开不开森) 那啥叫复制呢? 百度百科上给的解释是:仿原样品制造 我们曾经有过这样的印象 a = "zhangsa ...
- 第三章.定制专属的kali
1.更新升级 • apt-get update • apt-get upgrade • apt-get dis-upgrade 2.根据个人喜好需求安装软件包 • 库 • Apt-get命令 • ...