7.InfluxDB-InfluxQL基础语法教程--INTO子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
通过INTO子句,可以将用户的查询结果插入到用户指定的measurement中。
语法
SELECT_clause
INTO <measurement_name>
FROM_clause [WHERE_clause] [GROUP_BY_clause]
INTO子句支持如下语法,使得用户可以使用不同方式来指定要插入数据的measurement:
| 子句 | 意义 |
|---|---|
| INTO <measurement_name> | 插入到指定measurement中。此时使用的是当前库、使用默认的retention policy |
| INTO <database_name>.<retention_policy_name>.<measurement_name> | 往全路径的measurement中插入数据。此时指定了库、指定retention policy、指定measurement |
| INTO <database_name>..<measurement_name> | 往指定库的指定measurement中插入数据,使用默认的retention policy |
| INTO <database_name>.<retention_policy_name>.:MEASUREMENT FROM /<regular_expression>/ | 往指定库、指定retentioin policy,并且符合FROM子句中的正则规则的measurement中插入数据 |
INTO示例sql
- 示例一
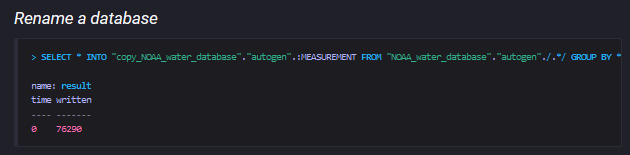
在InfluxDB中,是无法直接重命名一个库的,所以一个通常的做法是,像如上的sql那样,把一个库的所有数据全部复制到另一库中去。
其中 GROUP BY * 子句使得在源库中是tag key的字段,复制到目标库中之后依然是tag key。下面的sql就不维护tag的series上下文环境,如此一来在源库中的tag key在被复制到目标库之后,就变成fields了:
SELECT *
INTO "copy_NOAA_water_database"."autogen".:MEASUREMENT
FROM "NOAA_water_database"."autogen"./.*/
当需要复制大量的数据时,官方推荐一个一个measurement的进行复制,并且最好通过WHERE子句来指定时间区间,这样可以避免系统出现内存溢出的错误。如下面的sql就展示了通过指定时间区间来分批的进行数据复制操作:
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 100w and time < now() - 90w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>}
WHERE time > now() - 90w and time < now() - 80w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 80w and time < now() - 70w GROUP BY *
示例二
将一次查询结果写入到一个measurement中:

上面sql将它的查询结果插入到一个新建的名为h2o_feet_copy_1的measurement中。执行sql的结果显示总共插入了7604条结果数据到h2o_feet_copy_1中,时间戳1970-01-01T00:00:00Z则没有什么意思,前面说过,在InfluxDB中,使用1970-01-01T00:00:00Z来表示timestamp的null。示例三
将查询结果插入到一个全路径的measurement中
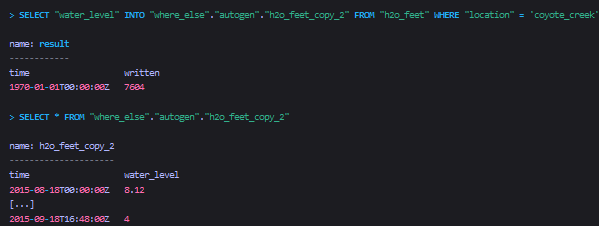
Note that both where_else and autogen must exist prior to running the INTO query.示例四
将聚合查询结果插入到measurement中(缩减取样)
SELECT MEAN("water_level") INTO "all_my_averages" FROM "h2o_feet"
WHERE "location" = 'coyote_creek'
AND time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:30:00Z'
GROUP BY time(12m)

- 示例五
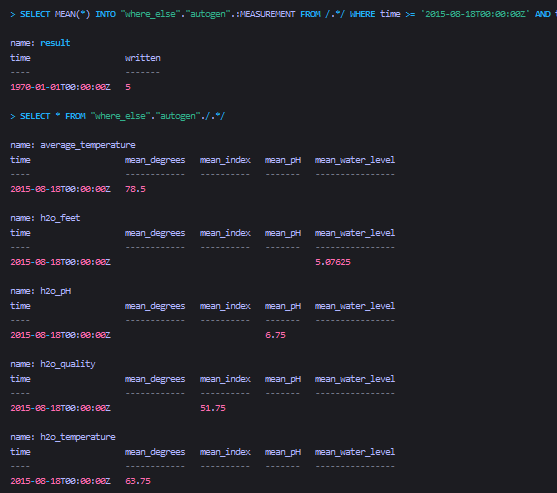
将多个表的汇总查询结果,复制到另一个库中
Sql
SELECT MEAN(*)
INTO "where_else"."autogen".:MEASUREMENT
FROM /.*/
WHERE time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:06:00Z'
GROUP BY time(12m)
查询结果
INTO子句常见问题
问题1:丢失数据
如果在一个INTO查询中,再把数据复制到目标库时会把源库的tag key转换为fields,这可能会导致influxdb覆盖先前由tag key区分的点。注意,此行为不适用于使用top()或bottom()函数的查询。在常见问题文档中可查看到该问题的详细描述。
为了防止源库的tag key复制到目标库之后编程fields,可以在INTO查询sql中使用group by有意义的tag key,或者group by \*.
问题2:使用into子句自动化查询
本小节展示了如何通过into子句来实现手动插入复制数据的操作。可以在Continuous Queries的相关文档中查看到如何利用into子句实现实时的查询数据。
7.InfluxDB-InfluxQL基础语法教程--INTO子句的更多相关文章
- 5.InfluxDB-InfluxQL基础语法教程--WHERE子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) WHERE子句 语法 ...
- 2.InfluxDB-InfluxQL基础语法教程--目录
本文翻译自官网,官方文档地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) InfluxQL ...
- 前端开发利器 Emmet 介绍与基础语法教程
在前端开发的过程中,编写 HTML.CSS 代码始终占据了很大的工作比例.特别是手动编写 HTML 代码,效率特别低下,因为需要敲打各种“尖括号”.闭合标签等.而现在 Emmet 就是为了提高代码编写 ...
- 10.InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) OFFSET 和SO ...
- 6.InfluxDB-InfluxQL基础语法教程--GROUP BY子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) GROUP BY子句 ...
- 9.InfluxDB-InfluxQL基础语法教程--LIMIT and SLIMIT 子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) LIMIT和SLIM ...
- 8.InfluxDB-InfluxQL基础语法教程--ORDER BY子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) 在InfluxDB中 ...
- 4.InfluxDB-InfluxQL基础语法教程--基本select语句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) 基本语法如下: SE ...
- 3.InfluxDB-InfluxQL基础语法教程--数据说明
下面是本次演示的示例数据 表名:h2o_feet 数据示例: 数据描述 : 表h2o_feet中所存储的是6分钟时间区间内的数据. 该表有一个tag,即location,该tag有两个值,分别为coy ...
随机推荐
- linux修改权限
修改system目录(包括子目录)的所有者和组 sudo chown -R seven:seven system
- golang数据结构和算法之LinkedList链表
差不多自己看懂了,可以自己写测试了.:) LinkedList.go package LinkedList //"fmt" type Node struct { data int ...
- 新版本的node,全局配置
配置环境变量: 1.在你安装node环境目录下 即是node_modules同级目录中. 创建两个文件夹[node_global]及[node_cache] node_cache:缓存目录 node_ ...
- vue全局路由守卫beforeEach+token验证+node
在后端安装jsonwebtoken npm i jsonwebtoken --save 在 login.js文件中引入 // 引入jwtconst jwt = require ...
- GitHub密钥生成
前提电脑上需装有Git软件 这里提供百度云下载地址:https://pan.baidu.com/s/1r0y4XRyQCz7ZJBnZJhAtqw 提取码:88qf 1.登录GitHub账号 2.点 ...
- leetcode 贪心算法
贪心算法中,是以自顶向下的方式使用最优子结构,贪心算法会先做选择,在当时看起来是最优的选择,然后再求解一个结果的子问题. 贪心算法是使所做的选择看起来都是当前最佳的,期望通过所做的局部最优选择来产生一 ...
- jQuery function函数详解
一.$(function(){}); $(document).ready(function(){})可以简写成$(function(){}); $(document).ready 里的代码是在页面内容 ...
- monkey和monkeyrunner的区别
简单来说: 1.monkey是在设备或模拟器直接运行adb shell命令生成随机事件来进行测试 2.monkeyrunner是通过API发送特定的命令和事件来控制设备 为了支持黑盒自动化测试的场景, ...
- 让人又爱又恨的this
this是个神奇的东西, 既可以帮助我们把模拟的类实例化. 又可以在事件绑定里准确指向触发元素. 还可以帮助我们在对象方法中操作对象的其他属性或方法. 甚至可以在使用apply.call.bing.f ...
- vim跳到最后和最前
1.跳到尾部和首部 :0或:1跳到文件第一行 :$跳到文件最后一行