机器学习之scikit-learn库
前面讲到了,这个库适合学习,轻量级,所以先学它。
安装就不讲了,简单。不过得先安装numpy和pandas库才能安装scikit-learn库。
如果安装了anaconda得话,会自带有这个库。
----------------------------------------------------------------------------------------------------------
1、首先进行字典特征提取
作用:对字典数据进行特征值提取。
API:sklearn.feature_extraction.DictVectorizer

流程:1、实例化类 DictVectorizer()
2、调用fit_transorm方法输入数据并转换
上代码:
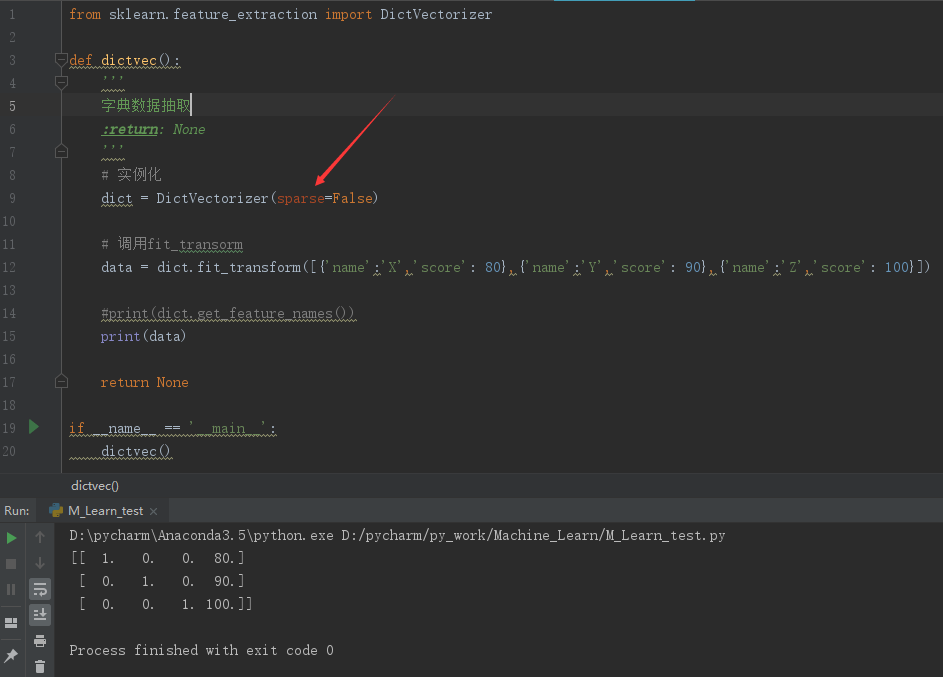
from sklearn.feature_extraction import DictVectorizer def dictvec():
'''
字典数据抽取
:return: None
'''
# 实例化
dict = DictVectorizer() # 调用fit_transorm
data = dict.fit_transform([{'name':'X','score': 80},{'name':'Y','score': 90},{'name':'Z','score': 100}]) print(data) return None if __name__ == '__main__':
dictvec()

可以看到输出结果是一个Sparse矩阵,前面得括号里面是坐标,后面的数字是这个坐标的值,比如:(0,0) 1.0 表示在第0行0列的值为1。
其他没有列出来的坐标如(0,1)、(0,2)等的值默认为0.
将DictVectorizer()中的sparse参数设置为False可以使得结果容易可读。
2、文本特征提取
作用:对文本数据进行提取 API:sklearn.feature_extraction.text.CountVectorizer上代码:假设有两篇文章分别为:'life is shortm,i like Python'和'life is too long, i dislike Python'
from sklearn.feature_extraction.text import CountVectorizer def countvec():
'''
对文本进行特征值提取
:return: None
'''
# 实例化
cv = CountVectorizer() # 调用fit_transorm
data = cv.fit_transform(['life is shortm,i like Python','life is too long, i dislike Python']) print(data) return None if __name__ == '__main__':
countvec()
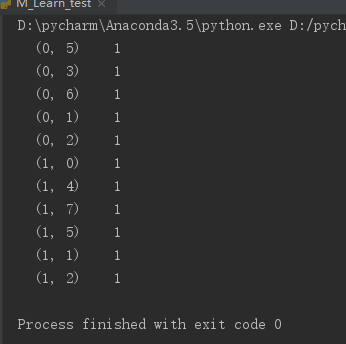
结果和字典提取是一样的,值得注意的是这里要将parse矩阵转换成比较容易读的二维矩阵的话,是在结果中调用toarray(),而不是设置sparse参数
如下图:
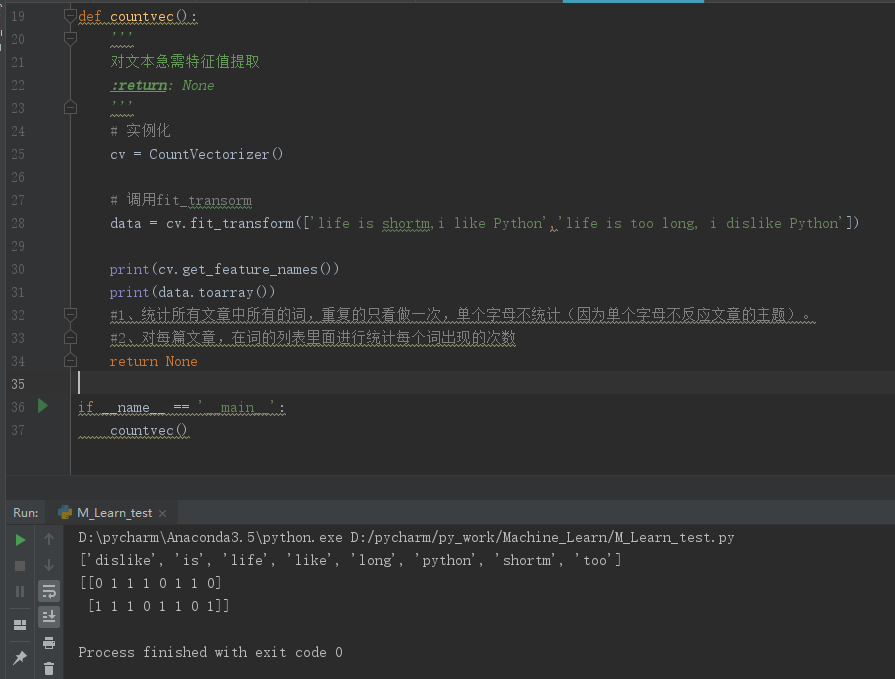
get_feature_names()返回一个列表,列表里面是提取的所有特征(本例中提取出了8个单词,单个字母不统计)。
结果中有两个列表,每个列表对应一篇文章。第一个列表中第一个0表示第一篇文章中dislike没有出现,第一个列表中第一个1表示is出现了,依次类推
机器学习之scikit-learn库的更多相关文章
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- 机器学习三剑客之Numpy库基本操作
NumPy是Python语言的一个扩充程序库.支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.Numpy内部解除了Python的PIL(全局解释器锁),运算效率极好,是大量机 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
随机推荐
- QQ第三方授权登录OAuth2.0实现(Java)
准备材料 1.已经备案好的域名 2.服务器(域名和服务器为统一主体或域名已接入服务器) 3.QQ号 4.开发流程:https://wiki.connect.qq.com/%E5%87%86%E5%A4 ...
- 扛住阿里双十一高并发流量,Sentinel是怎么做到的?
Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景 本文介绍阿里开源限流熔断方案Sentinel功能.原理.架构.快速入门以及相关框架比较 基本介绍 1 名词解释 服务限流 :当系 ...
- spring boot项目下的application.properties中的logging.level设置日志级别
日志级别 trace<debug<info<warn<error<fatal 默认级别为info,即默认打印info及其以上级别的日志,如下: logging.level ...
- CentOS 8 网卡设置
本次测试环境是在虚拟机上测试 网卡配置文件路径:/etc/sysconfig/network-scripts/ifcfg-ens33 [root@localhost ~]# cd /etc/sysco ...
- 【JAVA基础】JAVA基础语法
1.1 Java语言概述什么是Java语言Java语言是美国Sun公司(Stanford University Network),在1995年推出的高级的编程语言. Java语言发展历史1995年Su ...
- sublime text2解决中文乱码,支持中文的设置方法
步骤: 1.安装Sublime Package Control. 在Sublime Text 2上用Ctrl+-打开控制台并在里面输入以下代码,Sublime Text 2就会自动安装P ...
- Bran的内核开发教程(bkerndev)-05 打印到屏幕
打印到屏幕 现在, 我们需要尝试打印到屏幕上.为此, 我们需要管理屏幕滚动, 如果能允许使用不同的颜色就更好了.好在VGA视频卡为我们提供了一片内存空间, 允许同时写入属性字节和字符字节对, 可以 ...
- Python 之Re模块(正则表达式)
一.简介 正则表达式本身是一种小型的.高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配. 二.正则表达式中常用的字符含义 1.普通字符和11个元字符: ...
- MySQL 数据库的设计规范
网址 :http://blog.csdn.net/yjjm1990/article/details/7525811 1.文档的建立日期.所属的单位.2.数据库的命名规范.视图.3.命名的规范:1)避免 ...
- [HNOI2007] 理想正方形 二维ST表
题目描述 有一个a*b的整数组成的矩阵,现请你从中找出一个n*n的正方形区域,使得该区域所有数中的最大值和最小值的差最小. 输入输出格式 输入格式: 第一行为3个整数,分别表示a,b,n的值 第二行至 ...