python爬虫公众号所有信息,并批量下载公众号视频
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 数据分析实战
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
主要功能
如何简单爬虫微信公众号
获取信息:标题、摘要、封面、文章地址
自动批量下载公众号内的视频
一、获取公众号信息:标题、摘要、封面、文章URL
操作步骤:
1、先自己申请一个公众号 2、登录自己的账号,新建文章图文,点击超链接
代码
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&isMul=1&isNew=1&lang=zh_CN&token=1862390040",
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-bin/appmsg?token=1904193044&lang=zh_CN&f=json&ajax=1&random=0.9468236563826882&action=list_ex&begin={}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):

二、获取文章内视频:实现批量下载
通过对单篇视频文章分析,我找到了这个链接:
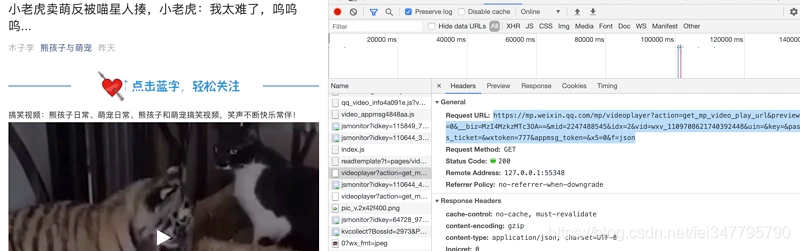
通过网页打开发现,是视频的网页下载链接:

哎,好像有点意思了,找到了视频的网页纯下载链接,那就开始吧。
发现链接里的有一个关键参数vid 不知道哪来的? 和获取到的其他信息也没有关系,那就只能硬来了。
通过对单文章的url请求信息里发现了这个参数,然后进行获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/videoplayer?action=get_mp_video_play_url&preview=0&__biz=MzI4MzkzMTc3OA==&mid=2247488495&idx=4&vid=" + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
那么所有信息就都完成了,进行code组装。
a、获取公众号信息
b、筛选单篇文章信息
c、获取vid信息
d、拼接视频页面下载URL
e、下载视频,保存
代码实验结果:

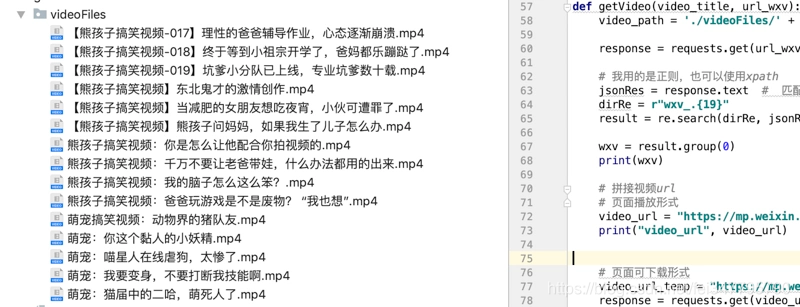
.
python爬虫公众号所有信息,并批量下载公众号视频的更多相关文章
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Python爬虫! 单爬,批量爬,这都不是事!
昨天做了一个煎蛋网妹子图的爬虫,个人感觉效果不错.但是每次都得重复的敲辣么多的代码(相比于Java或者其他语言的爬虫实现,Python的代码量可谓是相当的少了),就封装了一下!可以实现对批量网址以及单 ...
- 使用js脚本批量下载慕课网视频
慕课网(http://www.imooc.com/)上有很多不错的视频,当然我不是来给慕课网打广告的,我本人学习过很多慕课网上的免费的视频. 在线看如果网速慢时,可能会有卡顿,没网时无法观看.所有说下 ...
- 使用终端批量下载 B 站视频
需要使用一个叫做 you-get 的命令行程序 可以通过 Homebrew 安装(macOS), 安装命令为 brew install you-get, 其他平台的安装可参考 Github 主页: s ...
- 批量下载B站视频
一个一个下载:https://www.zhihu.com/question/41367609 WSDAB的回答批量下载:https://www.zhihu.com/question/49793759( ...
- 【Python 爬虫系列】从某网站下载小说《鬼吹灯》,正则解析html
import re import urllib.request import urllib.parse import urllib.error as err import time # 下载 seed ...
- Python爬虫实例(六)多进程下载金庸网小说
目标任务:使用多进程下载金庸网各个版本(旧版.修订版.新修版)的小说 代码如下: # -*- coding: utf-8 -*- import requests from lxml import et ...
- python爬虫实战(3)--图片下载器
本篇目标 1.输入关键字能够根据关键字爬取百度图片 2.能够将图片保存到本地文件夹 1.URL的格式 进入百度图片搜索apple,这时显示的是瀑布流版本,我们选择传统翻页版本进行爬取.可以看到网址为: ...
- Python 批量下载BiliBili视频 打包成软件
文章目录 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人,我给大家 ...
随机推荐
- 优先队列与TopK
一.简介 前文介绍了<最大堆>的实现,本章节在最大堆的基础上实现一个简单的优先队列.优先队列的实现本身没什么难度,所以本文我们从优先队列的场景出发介绍topK问题. 后面会持续更新数据结构 ...
- 终极CURD-4-java8新特性
目录 1 概述 2 lambda表达式 2.1 lambda重要知识点总结 2.2 java内置函数接口 2.3 方法引用 2.4 构造器引用 2.5 数组引用 2.6 lambda表达式的陷阱 3 ...
- Python文件的操作函数的使用
字符编码 二进制和字符之间的转换过程 --> 字符编码 ascii,gbk,shit,fuck 每个国家都有自己的编码方式 美国电脑内存中的编码方式为ascii ; 中国电脑内存中的编码方式为g ...
- 学生选课系统v1.0
最近两天写了下老师课上留的作业:学生选课系统.感觉自己写的特别麻烦,思路特别不清晰,平常自己总会偷懒,一些太麻烦细节的功能就不去实现了,用简单的功能来替代,直到自己这回写完这个系统(但自己写的比较lo ...
- java读取地址数据文件
在工作中遇到读取地址文件数据: 1.读取本地文件数据(如:D:\data.txt) //适用于读取绝对地址文件 public String getData(String path) { String ...
- windows + flutter +android+ vscode 安装配置运行流程(详细版本)
flutter 是由谷歌发布的一个全新的响应式.跨平台.高性能的移动开发框架,可以快速在iOS和Android上构建高质量的原生用户界面. 框架特点 快速开发:Flutter的热重载可以快速地进行测试 ...
- Springboot整合redis步骤
一.加入依赖 <dependency> <groupId>com.github.spt-oss</groupId> <artifactId>spring ...
- Leetcode547: Friend Circles 朋友圈问题
问题描述 在一个班级里有N个同学, 有些同学是朋友,有些不是.他们之间的友谊是可以传递的比如A和B是朋友,B和C是朋友,那么A和C也是朋友.我们定义 friend circle为由直接或者间接都是朋友 ...
- Vue 04
目录 创建Vue项目 Vue项目环境搭建 Vue项目创建 pycharm配置并启动vue项目 vue项目目录结构分析 项目生命周期 添加组件-路由映射关系 文件式组件结构 配置全局css样式 子组件的 ...
- javascript中常见的几种循环遍历
项目开发中,不管是建立在哪个框架基础上,对数据的处理都是必须的,而处理数据离不开各种遍历循环.javascript中循环遍历有很多种方式,记录下几种常见的js循环遍历. 一.for循环 for循环应该 ...