《收获,不止SQL优化》读书笔记
原文链接:https://smilenicky.blog.csdn.net/article/details/94862797,
我的sql调优专栏:https://smilenicky.blog.csdn.net/article/category/8679315
整体性能分析
AWR、ASH、ADDM、AWRDD
整体分析调优工具
- AWR:关注数据库的整体性能的报告;
- ASH:数据库中的等待事件与哪些SQL具体对应的报告;
- ADDM:oracle给出的一些建议
- AWRDD:Oracle针对不同时段的性能对比报告
- AWRSQRPT:oracle获取统计信息与执行计划
不同场景对应工具
局部分析调优工具:
- explain plan for
- set autotrace on
- statistics_level=all
- 直接通过sql_id获取
- 10046 trace
- awrrpt.sql
整体性能工具要点
- AWR关注点:load profile、efficiency percentages、top 5 time events、SQL Statistics、segment_statistics
- ASH关注点:等待事件与sql完美结合
- ADDM:各种建议与对应SQL
- AWRDD:不同时期 load profile的比较、不同时期等待事件的比较、不同时期TOP SQL的比较
- AWRSQRPT:获取与关注点(统计信息与执行计划)
select output from table (dbms_workload_repository.awr_report_html(v_dbid,v_instance_number,v_min_snap_id,v_max_snap_id));
相关查询试图:
- v$session (当前正在发生)
- v$session_wait(当前正在等待)
- v$session_wait_history (会话最近的10次等待事件)
- v$active_session_history (内存中的ASH采集信息,理论为1小时)
- wrh$_active_session_history (写入AWR库中的ASH信息,理论为1小时以上)
- dba_hist_active_sess_history (根据wrh$_active_session_history生成的视图)
执行计划
获取执行计划的方法:
(1) explain plan for
步骤:
- 1:explain plan for 你的SQL;
- 2:select * from table (dbms_xplan. display()) ;
- 优点:不需要真的执行,快捷方便
- 缺点:没有输出运行时的统计信息(逻辑读、递归调用,物理读),因为没有真正执行,所以不能看到执行了多少行、表被访问了多少次等等
(2) set autotrace on
sqlplus登录:
用户名/密码@主机名称:1521/数据库名
步骤:
- 1:set sutoatrace on
- 2:在此次执行你的sql;
- 优点:可以看到运行时的统计信息(逻辑读、递归调用,物理读)
- 缺点:不能看到表被访问了多少次,也需要等sql执行完成才能看
(3) statistics_level=all
步骤:
- 1:alter session set statistics_level=all;
- 2:在此处执行你的SQL;
- 3:select * from table(dbms_xplan.display_cursor(null , null,'allstats last'));
假如使用了Hint语法: /*+ gather_plan_statistics */,就可以省略步骤1,直接执行步骤2和3,获取执行计划
关键字解读:
- Starts:该SQL执行的次数
- E-Rows:为执行计划预计的行数
- A-Rows:实际返回的行数,E-Rows和A-Rows作比较,就可以看出具体那一步执行计划出问题了
- A-Time:每一步实际执行的时间,可以看出耗时的SQL
- Buffers:每一步实际执行的逻辑读或一致性读
- Reads:物理读
- OMem:当前操作完成所有内存工作区操作总使用私有内存工作区(PGA)的大小
- lMem:当工作区大小无法符满足操作需求的大小时,需要将部分数据写入临时磁盘空间中(如果仅需要写入一次就可以完成操作,就称一次通过,One-Pass;否则为多次通过,Multi-Pass)。改数据为语句最后一次执行中,单次写磁盘所需要的内存大小,这个是由优化器统计数据以及前一次执行的性能数据估算得出的
- Used-Mem:语句最后一次执行中,当前操作所使用的内存工作区大小,括号里面为(发生磁盘交换的次数,1次即为One-Pass,大于一次则为Mullti-Pass,如果没有使用磁盘,则显示为OPTI1MAL)
OMem、lMem为执行所需要的内存评估值,OMem为最优执行模式所需要内存的评估值,Used-Mem为消耗的内存
优点:
- 可以从STARTS得出表被访问多少次;
- 可以清晰地从E-ROWS和A-ROWS中分别得出预测的行数和真实的行数
缺点: - 必须等到语句真正执行完成后,才可以得出结果
- 无法控制记录打屏输出,不想aututrace有traceonly命令
- 没有专门的输出统计信息,看不到递归调用的次数,看不出物理读具体数值,不过有逻辑读,逻辑读才是重点
(4) dbms_xplan.display_cursor获取
步骤
从共享池获取
//${SQL_ID}参数可以从共享池拿
select * from table(dbms_xplan.display_cursor(${SQL_ID}));
还可以从AWR性能视图里获取
select * from table(dbms_xplan.display_awr(${SQL_ID}));
多个执行计划的情况,可以用类似方法查出
select * from table(dbms_xplan.display_cursor(${SQL_ID},0));
select * from table(dbms_xplan.display_cursor(${SQL_ID},1));
优点:
- 和explain一样不需要真正执行,知道sql_id就好
缺点:
- 不能判断处理了多少行
- 无法判断表被访问了多少次
- 没有输出运行时的相关统计信息(逻辑读、递归调用、物理读)
(5) 事件10046 trace跟踪
步骤:
1:alter session set events '10046 trace name context forever,level 12';//开启跟踪
2:执行你的语句
3:alter session set events '10046 trace name context off';//关闭跟踪
4:找到跟踪产生的文件
5:tkprof trc文件 目标文件 sys=no sort=prsela,exeela,fchela(格式化命令)
优点:
- 可以看出SQL语句对应的等待事件
- 可以列出sql语句中的函数调用的
- 可以看出解析事件和执行事件
- 可以跟踪整个程序包
- 可以看出处理的行数,产生的逻辑读
缺点: - 步骤比较繁琐
- 无法判断表被访问了多少次
- 执行计划中的谓词部分不能清晰地显示出来
(6) awrsqrpt.sql
步骤:
1:@?/rdbms/admin/awrsqrpt.sql
具体可以参考我之前的博客:https://smilenicky.blog.csdn.net/article/details/89429989
解释经典执行计划的方法
可以分为两种类型:单独型和联合型
联合型分为:关联的联合型和非关联的联合型
【单独型】
单独型比较好理解,执行顺序是按照id=1,id=2,id=3执行,由远及近
先scott登录,然后执行sql,例子来自《收获,不止SQL优化》一书
select deptno, count(*)
from emp
where job = 'CLERK'
and sal < 3000
group by deptno
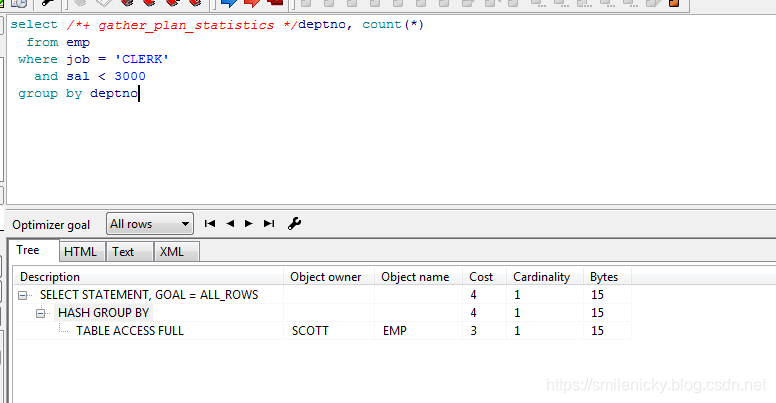
所以可以给出单独型的图例:

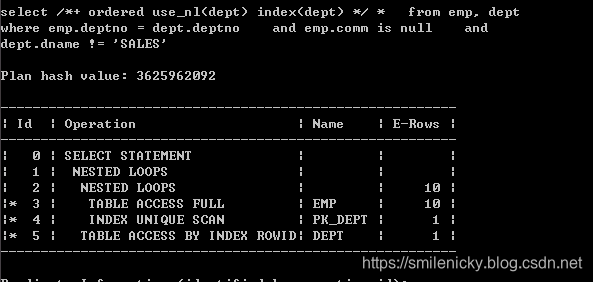
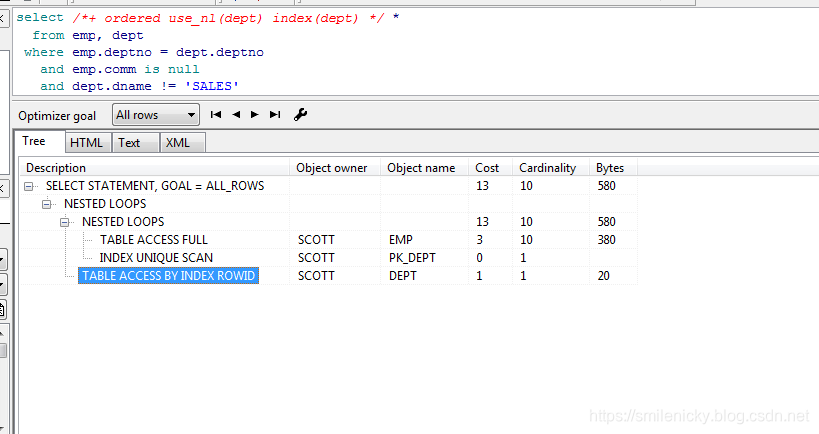
【联合型关联型】
(1) 联合型的关联型(NL)
这里使用Hint的nl
select /*+ ordered use_nl(dept) index(dept) */ *
from emp, dept
where emp.deptno = dept.deptno
and emp.comm is null
and dept.dname != 'SALES'
这图来自《收获,不止SQL优化》,可以看出id为2的A-Rows实践返回行数为10,id为3的Starts为10,说明驱动表emp访问的结果集返回多少条记录,被驱动表就被访问多少次,这是关联型的显著特征

关联型不一定是驱动表返回多少条,被驱动表就被访问多少次的,注意FILTER模式也是关联型的
(2) 联合型的关联型(FILTER)
前面已经介绍了联合型关联型(nl)这种方法的,这种方法是驱动表返回多少条记录,被驱动表就被访问了多少次,不过这种情况对于FILTER模式下并不适用
执行SQL,这里使用Hint /*+ no_unnset */
select * from emp where not exists (select /*+ no_unnset */ 0 from dept
where dept.dname='SALES' and dept.deptno = emp.deptno) and not exists(select /*+ no_unnset */ 0 from bonus where bonus.ename = emp.ename)
ps:图来自《收获,不止SQL优化》一书,这里可以看出id为2的地方,A-Rows实际返回行数为8,而id为3的地方,Starts为3,说明对应SQL执行3次,也即dept被驱动表被访问了3次,这和刚才介绍的nl方式不同,为什么不同?
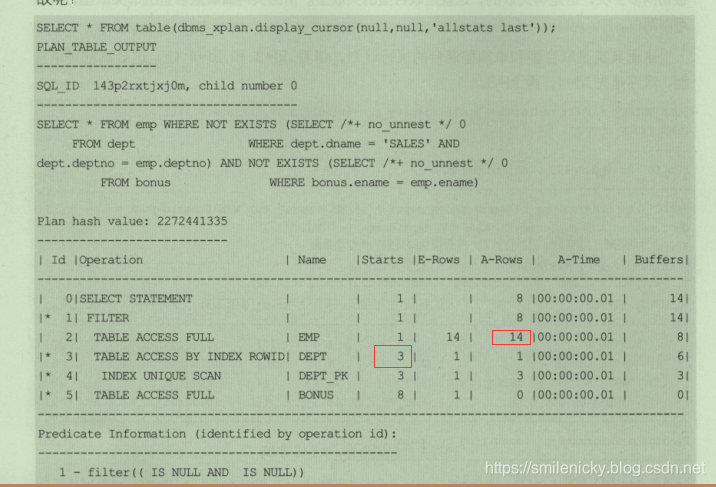 查询一下SQL,可以看出实际返回3条,其它的都是重复多的,
查询一下SQL,可以看出实际返回3条,其它的都是重复多的,
select dname, count(*) from emp, dept where emp.deptno = dept.deptno group by dname;
所以,就很明显了,被过滤了重复数据,也就是说FILTER模式的对数据进行过滤,驱动表执行结果集返回多少行不重复数据,被驱动表就被访问多少次,FILTER模式可以说是对nl模式的改善
(3) 联合型的关联型(UPDATE)
update emp e1 set sal = (select avg(sal) from emp e2 where e2.deptno = e1.deptno),comm = (select avg(comm) from emp e3)
联合型的关联型(UPDATE)和FILTER模式类似,所以就不重复介绍
(4) 联合型的关联型(CONNECT BY WITH FILTERING)
select /*+ connect_by_filtering */ level, ename ,prior
ename as manager from emp start with mgr is null connect by prior empno = mgr
给出联合型关联型图例:

【联合型非关联型】
可以执行SQL
select ename from emp union all select dname from dept union all select '%' from dual
对于plsql可以使用工具查看执行计划,sqlplus客户端的可以使用statistics_level=all的方法获取执行计划,具体步骤
- 1:alter session set statistics_level=all;
- 2:在此处执行你的SQL;
- 3:select * from table(dbms_xplan.display_cursor(null , null,'allstats last'));
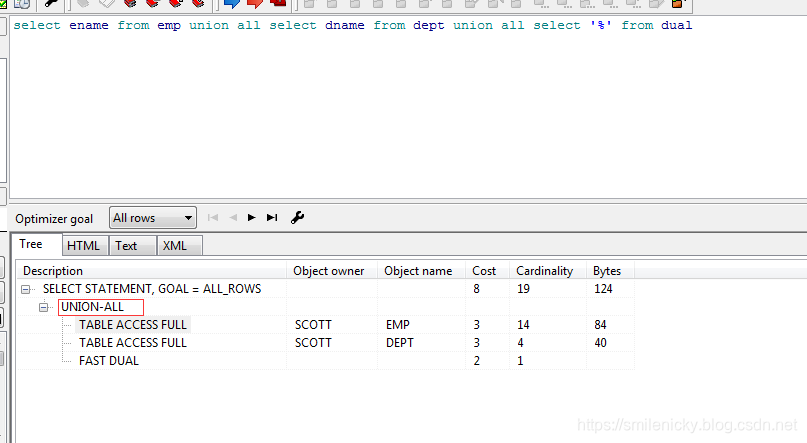
可以给出联合型非关联型的图例:

【调优TIPS】
出现哈希连接,可以在子查询加个rownum,让优化器先内部查询好再查询外部,不构成哈希连接
索引列有空值是不走索引的,模糊匹配也不能走索引
with as用法,有缓存,可以用于提高性能
select * from emp where deptno in (select deptno from dept where dname='SALES');
with tmp as (select deptno from dept where dname='SALES')
select * from emp where deptno in (select * from tmp)
虚拟索引
alter session set "_use_nosegment_indexes"=true;
create index index_name on table_name(col_name) nosegment;
物化视图
create materialized view [视图名称]
build immediate | deferred
refresh fase | complete | force
on demand | commit
start with [start time]
next [next time]
with primary key | rowid //可以省略,一般默认是主键物化视图
as [要执行的SQL]
ok,解释一下这些语法用意:
build immediate | deferred (视图创建的方式):
- (1) immediate:表示创建物化视图的时候是生成数据的;
- (2) deferre:就相反了,只创建物化视图,不生成数据
refresh fase | complete | force (视图刷新的方式):
- (1) fase:增量刷新,也就是距离上次刷新时间到当前时间所有改变的数据都刷新到物化视图,注意,fase模式必须创建视图日志
- (2) complete:全量更新的,complete方式相当于创建视图重新全部查一遍
- (3) force:视图刷新方式的默认方式,当增量刷新可用则增量刷新,当增量刷新不可用,则全量刷新,一般不要用默认方式
on demand | commit start with ... next ...(视图刷新时间):
- (1) demand:根据用户需要刷新时间,也就是说用户要手动刷新
- (2) commit:事务一提交,就自动刷新视图
- (3) start with:指定首次刷新的时间,一般用当前时间
- (4) next:物化视图刷新数据的周期,格式一般为“startTime+时间间隔”
Oracle体系结构
Oracle体系结构由实例和一组数据文件组成,实例由SGA内存区,SGA意思是共享内存区,由share pool(共享池)、data buffer(数据缓冲区)、log buffer(日志缓冲区)组成
SGA内存区的share pool是解析SQL并保存执行计划的,然后SQL根据执行计划获取数据时先看data buffer里是否有数据,没数据才从磁盘读,然后还是读到data buffer里,下次就直接读data buffer的,当SQL更新时,data buffer的数据就必须写入磁盘备份,为了保护这些数据,才有log buffer,这就是大概的原理简介
系统结构关系图如: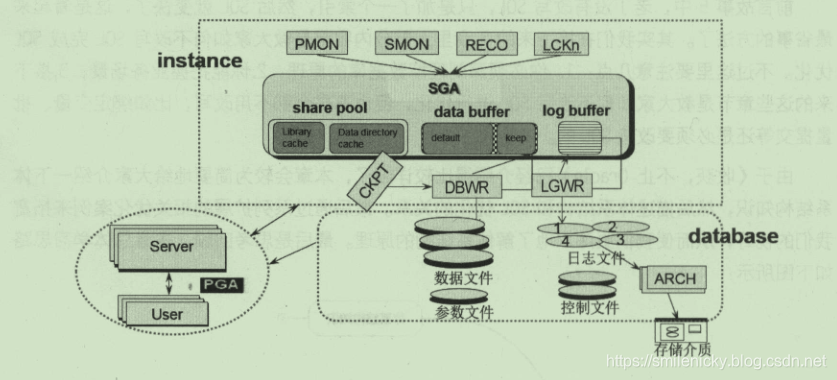
未绑定遍历SQL查询
create table t_bind_sql as select sql_text,module from v$sqlarea;
alter table t_bind_sql add sql_text_wo_constants varchar2(1000);
create or replace function
remove_constants( p_query in varchar2 ) return varchar2
as
l_query long;
l_char varchar2(10);
l_in_quotes boolean default FALSE;
begin
for i in 1 .. length( p_query )
loop
l_char := substr(p_query,i,1);
if ( l_char = '''' and l_in_quotes )
then
l_in_quotes := FALSE;
elsif ( l_char = '''' and NOT l_in_quotes )
then
l_in_quotes := TRUE;
l_query := l_query || '''#';
end if;
if ( NOT l_in_quotes ) then
l_query := l_query || l_char;
end if;
end loop;
l_query := translate( l_query, '0123456789', '@@@@@@@@@@' );
for i in 0 .. 8 loop
l_query := replace( l_query, lpad('@',10-i,'@'), '@' );
l_query := replace( l_query, lpad(' ',10-i,' '), ' ' );
end loop;
return upper(l_query);
end;
/
update t_bind_sql set sql_text_wo_constants = remove_constants(sql_text);
commit;
select sql_text_wo_constants, module,count(*) CNT
from t_bind_sql
group by sql_text_wo_constants,module
having count(*) > 100
order by 3 desc;
查询数据情况信息SQL:
select s.snap_date,
decode(s.redosize, null, '--shutdown or end--', s.currtime) "TIME",
to_char(round(s.seconds / 60, 2)) "elapse(min)",
round(t.db_time / 1000000 / 60, 2) "DB time(min)",
s.redosize redo,
round(s.redosize / s.seconds, 2) "redo/s",
s.logicalreads logical,
round(s.logicalreads / s.seconds, 2) "logical/s",
physicalreads physical,
round(s.physicalreads / s.seconds, 2) "phy/s",
s.executes execs,
round(s.executes / s.seconds, 2) "execs/s",
s.parse,
round(s.parse / s.seconds, 2) "parse/s",
s.hardparse,
round(s.hardparse / s.seconds, 2) "hardparse/s",
s.transactions trans,
round(s.transactions / s.seconds, 2) "trans/s"
from (select curr_redo - last_redo redosize,
curr_logicalreads - last_logicalreads logicalreads,
curr_physicalreads - last_physicalreads physicalreads,
curr_executes - last_executes executes,
curr_parse - last_parse parse,
curr_hardparse - last_hardparse hardparse,
curr_transactions - last_transactions transactions,
round(((currtime + 0) - (lasttime + 0)) * 3600 * 24, 0) seconds,
to_char(currtime, 'yy/mm/dd') snap_date,
to_char(currtime, 'hh24:mi') currtime,
currsnap_id endsnap_id,
to_char(startup_time, 'yyyy-mm-dd hh24:mi:ss') startup_time
from (select a.redo last_redo,
a.logicalreads last_logicalreads,
a.physicalreads last_physicalreads,
a.executes last_executes,
a.parse last_parse,
a.hardparse last_hardparse,
a.transactions last_transactions,
lead(a.redo, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_redo,
lead(a.logicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_logicalreads,
lead(a.physicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_physicalreads,
lead(a.executes, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_executes,
lead(a.parse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_parse,
lead(a.hardparse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_hardparse,
lead(a.transactions, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_transactions,
b.end_interval_time lasttime,
lead(b.end_interval_time, 1, null) over(partition by b.startup_time order by b.end_interval_time) currtime,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) currsnap_id,
b.startup_time
from (select snap_id,
dbid,
instance_number,
sum(decode(stat_name, 'redo size', value, 0)) redo,
sum(decode(stat_name,
'session logical reads',
value,
0)) logicalreads,
sum(decode(stat_name,
'physical reads',
value,
0)) physicalreads,
sum(decode(stat_name, 'execute count', value, 0)) executes,
sum(decode(stat_name,
'parse count (total)',
value,
0)) parse,
sum(decode(stat_name,
'parse count (hard)',
value,
0)) hardparse,
sum(decode(stat_name,
'user rollbacks',
value,
'user commits',
value,
0)) transactions
from dba_hist_sysstat
where stat_name in
('redo size',
'session logical reads',
'physical reads',
'execute count',
'user rollbacks',
'user commits',
'parse count (hard)',
'parse count (total)')
group by snap_id, dbid, instance_number) a,
dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
order by end_interval_time)) s,
(select lead(a.value, 1, null) over(partition by b.startup_time order by b.end_interval_time) - a.value db_time,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) endsnap_id
from dba_hist_sys_time_model a, dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
and a.stat_name = 'DB time') t
where s.endsnap_id = t.endsnap_id
order by s.snap_date, time desc;
KEEP方式,固定缓存
SQL> alter system set db_keep_cache_size=100M;
系统已更改。
SQL> drop table t;
表已删除。
SQL> create table t as select * from dba_objects;
表已创建。
SQL> create index idx_object_id on t(object_id);
索引已创建。
SQL> select BUFFER_POOL from user_tables where TABLE_NAME='T';
BUFFER_
-------
DEFAULT
SQL> select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID';
BUFFER_
-------
DEFAULT
SQL> alter index idx_object_id storage(buffer_pool keep);
索引已更改。
SQL> --以下将索引全部读进内存
SQL> select /*+index(t,idx_object_id)*/ count(*) from t where object_id is not null;
COUNT(*)
----------
111113
SQL> --以下将数据全部读进内存
SQL> alter table t storage(buffer_pool keep);
表已更改。
SQL> select /*+full(t)*/ count(*) from t;
COUNT(*)
----------
111113
SQL> --执行KEEP操作后,通过如下方法查询出BUFFER_POOL列值为KEEP,表示已经KEEP成功了
SQL> select BUFFER_POOL from user_tables where TABLE_NAME='T';
BUFFER_
-------
KEEP
SQL> select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID';
BUFFER_
-------
KEEP
获取提交次数超过一个阈值的SID:
select t1.sid, t1.value, t2.name
from v$sesstat t1, v$statname t2
where t2.name like '%user commits%'
and t1.STATISTIC# = t2.STATISTIC#
and value >= 10000
order by value desc;
获取对应的SQL_ID
select t.SID,
t.PROGRAM,
t.EVENT,
t.LOGON_TIME,
t.WAIT_TIME,
t.SECONDS_IN_WAIT,
t.SQL_ID,
t.PREV_SQL_ID
from v$session t
where sid in(132);
通过SQL_ID获取对应SQL
select t.sql_id,
t.sql_text,
t.EXECUTIONS,
t.FIRST_LOAD_TIME,
t.LAST_LOAD_TIME
from v$sqlarea t
where sql_id in ('ccpn5c32bmfmf');
日志切换规律查询SQL:
SELECT SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) Day,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'00',1,0)) H00,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'01',1,0)) H01,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'02',1,0)) H02,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'03',1,0)) H03,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'04',1,0)) H04,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'05',1,0)) H05,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'06',1,0)) H06,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'07',1,0)) H07,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'08',1,0)) H08,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'09',1,0)) H09,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'10',1,0)) H10,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'11',1,0)) H11,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'12',1,0)) H12,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'13',1,0)) H13,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'14',1,0)) H14,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'15',1,0)) H15,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'16',1,0)) H16,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'17',1,0)) H17,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'18',1,0)) H18,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'19',1,0)) H19,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'20',1,0)) H20,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'21',1,0)) H21,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'22',1,0)) H22 ,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'23',1,0)) H23,
COUNT(*) TOTAL
FROM v$log_history a
where first_time>=to_char(sysdate-11)
GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5)
ORDER BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) DESC;
跟踪日志暴增故障
--1、redo大量产生必然是由于大量产生"块改变"。从awr视图中找出"块改变"最多的segments。
select * from (
SELECT to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI') snap_time,
dhsso.object_name,
SUM(db_block_changes_delta)
FROM dba_hist_seg_stat dhss,
dba_hist_seg_stat_obj dhsso,
dba_hist_snapshot dhs
WHERE dhs.snap_id = dhss. snap_id
AND dhs.instance_number = dhss. instance_number
AND dhss.obj# = dhsso. obj#
AND dhss.dataobj# = dhsso.dataobj#
AND begin_interval_time> sysdate - 60/1440
GROUP BY to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI'),
dhsso.object_name
order by 3 desc)
where rownum<=5;
--2、从awr视图中找出步骤1中排序靠前的对象涉及到的SQL。
SELECT to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI'),
dbms_lob.substr(sql_text, 4000, 1),
dhss.instance_number,
dhss.sql_id,
executions_delta,
rows_processed_delta
FROM dba_hist_sqlstat dhss, dba_hist_snapshot dhs, dba_hist_sqltext dhst
WHERE UPPER(dhst.sql_text) LIKE '%这里写对象名大写%'
AND dhss.snap_id = dhs.snap_id
AND dhss.instance_Number = dhs.instance_number
AND dhss.sql_id = dhst.sql_id;
--3、从ASH相关视图中找出执行这些SQL的session、module和machine。
select * from dba_hist_active_sess_history WHERE sql_id = '';
select * from v$active_session_history where sql_Id = '';
--4. dba_source 看看是否有存储过程包含这个SQL
--以下操作产生大量的redo,可以用上述的方法跟踪它们。
drop table test_redo purge;
create table test_redo as select * from dba_objects;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
exec dbms_workload_repository.create_snapshot();
--执行了大量的针对test_redo表的INSERT操作后,我们开始按如下方法进行跟踪,看能否发现更新的是哪张表,是哪些语句。
SQL> select * from (
2 SELECT to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI') snap_time,dhsso.object_ name,SUM(db_block_changes_delta)
3 FROM dba_hist_seg_stat dhss,dba_hist_seg_stat_obj dhsso,dba_hist_snapshot dhs
4 WHERE dhs.snap_id = dhss. snap_id
5 AND dhs.instance_number = dhss. instance_number AND dhss.obj# = dhsso. obj# AND dhss.dataobj# = dhsso.dataobj#
6 AND begin_interval_time> sysdate - 60/1440
7 GROUP BY to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI'), dhsso.object_name order by 3 desc)
8 where rownum<=3;
SQL> SELECT to_char(begin_interval_time,'YYYY_MM_DD HH24:MI'),dbms_lob.substr(sql_ text,4000,1),dhss.sql_id,executions_delta,rows_processed_delta
2 FROM dba_hist_sqlstat dhss, dba_hist_snapshot dhs, dba_hist_sqltext dhst
3 WHERE UPPER(dhst.sql_text) LIKE '%TEST_REDO%' AND dhss.snap_id = dhs.snap_id
4 AND dhss.instance_Number = dhs.instance_number AND dhss.sql_id = dhst.sql_id;
Oracle逻辑结构
数据库(Database)由若干表空间(Tablespace)组成,表空间(Tablespace)由若干段(Segment)组成,段(Segment)由若干区(Extent)组成,区(Extent)又由若干块(Block)组成

Block越大,相同数据量的情况下存储的行就越多,Block需要的越少, 访问的逻辑读就越小,对应的consistent gets就越小
ps:实践情况并非Block越大越好,block越大,不同的访问的数据落在同一个Block的概率就越大,这个很容易产生热竞争
查看表空间的总体情况:
SELECT A.TABLESPACE_NAME "表空间名",
A.TOTAL_SPACE "总空间(G)",
NVL(B.FREE_SPACE, 0) "剩余空间(G)",
A.TOTAL_SPACE - NVL(B.FREE_SPACE, 0) "使用空间(G)",
CASE
WHEN A.TOTAL_SPACE = 0 THEN
0
ELSE
trunc(NVL(B.FREE_SPACE, 0) / A.TOTAL_SPACE * 100, 2)
END "剩余百分比%" --避免分母为0
FROM (SELECT TABLESPACE_NAME,
trunc(SUM(BYTES) / 1024 / 1024 / 1024, 2) TOTAL_SPACE
FROM DBA_DATA_FILES
GROUP BY TABLESPACE_NAME) A,
(SELECT TABLESPACE_NAME,
trunc(SUM(BYTES / 1024 / 1024 / 1024), 2) FREE_SPACE
FROM DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) B
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME(+)
ORDER BY 5;
Oracle表设计与调优
分区类型:分区分为范围分区、列表分区、HASH分区、组合分区四种
- 范围分区
关键字partition by range
create table range_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by range (deal_date)
(
partition p1 values less than (TO_DATE('2018-11-01','YYYY-MM-DD')),
partition p2 values less than (TO_DATE('2018-12-02','YYYY-MM-DD')),
partition p3 values less than (TO_DATE('2019-01-01','YYYY-MM-DD')),
partition p4 values less than (TO_DATE('2019-02-01','YYYY-MM-DD')),
partition p5 values less than (TO_DATE('2019-03-01','YYYY-MM-DD')),
partition p6 values less than (TO_DATE('2019-04-01','YYYY-MM-DD')),
partition p7 values less than (TO_DATE('2019-05-01','YYYY-MM-DD')),
partition p8 values less than (TO_DATE('2019-06-01','YYYY-MM-DD')),
partition p9 values less than (TO_DATE('2019-07-01','YYYY-MM-DD')),
partition p10 values less than (TO_DATE('2019-08-01','YYYY-MM-DD'))
);
insert into range_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
- 列表分区
create table list_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by list (unit_code)
(
partition p1 values (211),
partition p2 values (212),
partition p3 values (213),
partition p4 values (214),
partition p5 values (215),
partition p6 values (216),
partition p7 values (217),
partition p8 values (218),
partition p9 values (219),
partition p10 values (220),
partition p0 values (DEFAULT)
);
insert into list_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
commit;
- 散列分区
散列分区也叫hash分区,partitions后接分区数,尽量设置为偶数,
create table hash_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by hash (deal_date)
partitions 12;
insert into hash_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
commit;
- 组合分区
主要有两种:oracle11之前只支持范围列表分区(RANGE-LIST)和范围散列分区(RANGE-HASH),oracle11之后支持(范围范围分区)RANGE-RANGE、 (列表范围分区)LIST-RANGE、(列表散列分区)LIST-HASH、(列表列表分区)LIST-LIST这几种组合,为了避免每个主分区中都写相同的从分区,可以用模板方式(subpartition template)
create table range_list_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by range (deal_date)
subpartition by list (unit_code)
subpartition template
(subpartition s1 values (211),
subpartition s2 values (212),
subpartition s3 values (213),
subpartition s4 values (214),
subpartition s5 values (215),
subpartition s6 values (216),
subpartition s7 values (217),
subpartition s8 values (218),
subpartition s9 values (219),
subpartition s10 values (220),
subpartition s0 values (DEFAULT) )
(
partition p1 values less than (TO_DATE('2018-11-01','YYYY-MM-DD')),
partition p2 values less than (TO_DATE('2018-12-02','YYYY-MM-DD')),
partition p3 values less than (TO_DATE('2019-01-01','YYYY-MM-DD')),
partition p4 values less than (TO_DATE('2019-02-01','YYYY-MM-DD')),
partition p5 values less than (TO_DATE('2019-03-01','YYYY-MM-DD')),
partition p6 values less than (TO_DATE('2019-04-01','YYYY-MM-DD')),
partition p7 values less than (TO_DATE('2019-05-01','YYYY-MM-DD')),
partition p8 values less than (TO_DATE('2019-06-01','YYYY-MM-DD')),
partition p9 values less than (TO_DATE('2019-07-01','YYYY-MM-DD')),
partition p10 values less than (TO_DATE('2019-08-01','YYYY-MM-DD'))
);
insert into range_list_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
commit;
普通表和分区表区别,分区表分成几部分就有几个segment
select segment_name,
partition_name,
segment_type,
bytes / 1024 / 1024 "字节数(M)",
tablespace_name
from user_segments
where segment_name IN ('RANGE_PART_TAB', 'NOR_TAB');
分区相关操作
- Split分区
拆分分区,范围分区和列表分区都适合分区,注意不能对HASH类型的分区进行拆分
create table list_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by list (unit_code)
(
partition p1 values (211),
partition p2 values (212),
partition p3 values (213),
partition p4 values (214),
partition p5 values (215),
partition p6 values (216),
partition p7 values (217),
partition p8 values (218),
partition p9 values (219),
partition p10 values (220),
partition p0 values (DEFAULT)
);
alter table list_part_tab split partition p10 at(220) into (PARTITION p11,PARTITION p12);
- 新增分区
ALTER TABLE list_part_tab ADD PARTITION P13 VALUES LESS THAN(250);
新增子分区
ALTER TABLE list_part_tab MODIFY PARTITION P13 ADD SUBPARTITION P13SUB1 VALUES(350);
- 删除分区
ALTER TABLE list_part_tab DROP PARTITION P13;
删除子分区
ALTER TABLE list_part_tab DROP SUBPARTITION P13SUB1;
- TRUNCATE分区
TRUNCATE是指删除分区的数据,并不会删除分区
ALTER TABLE list_part_tab TRUNCATE PARTITION P2;
TRUNCATE子分区
ALTER TABLE list_part_tab TRUNCATE SUBPARTITION P13SUB1;
- 合并分区
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区
ALTER TABLE list_part_tab MERGE PARTITIONS P1,P2 INTO PARTITION P2;
- 接合分区(coalesca)
将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,注意接合只适用于散列分区
ALTER TABLE list_part_tab COALESCA PARTITION;
- 重命名分区
ALTER TABLE SAlist_part_tabLES RENAME PARTITION P11 TO P1;
- 交换分区
交换分区是说交换两张表结构一样的表的数据,注意最好加上including indexs更新全局索引,不加的话,全局索引会失效
alter table list_part_tab exchange partition p1 with table range_part_tab including indexs update global indexs;
分区相关查询
*查询数据库所有分区表的信息
select * from DBA_PART_TABLES
- 查询分区表类型、是否有子分区,分区总数
select pt.partitioning_type, pt.subpartitioning_type, pt.partition_count
from user_part_tables pt
- 查询分区详细详细:
SELECT tab.* FROM USER_TAB_PARTITIONS tab WHERE TABLE_NAME='LIST_PART_TAB'
- 查询分区表哪列建分区
select column_name, object_type, column_position
from user_part_key_columns
where name = 'LIST_PART_TAB';
- 查询分区表大小
select sum(bytes / 1024 / 1024)
from user_segments
where segment_name = 'LIST_PART_TAB';
- 查询分区表各分区的大小和分区名
select partition_name, segment_type, bytes
from user_segments
where segment_name = 'LIST_PART_TAB';
- 查询分区表各索引大小
select segment_name, segment_type, sum(bytes) / 1024 / 1024
from user_segments
where segment_name in
(select index_name
from user_indexes
where table_name = 'LIST_PART_TAB')
group by segment_name, segment_type;
- 查询分区表的统计信息
select table_name,
partition_name,
last_analyzed,
partition_position,
num_rows
from user_tab_statistics
where table_name = 'LIST_PART_TAB';
- 查询分区表索引情况
select table_name,
index_name,
last_analyzed,
blevel,
num_rows,
leaf_blocks,
distinct_keys,
status
from user_indexes
where table_name = 'LIST_PART_TAB';
- 查询索引在哪些列上
select index_name, column_name, column_position
from user_ind_columns
where table_name = 'LIST_PART_TAB';
- 查询普通表失效的索引
select ind.index_name,
ind.table_name,
ind.blevel,
ind.num_rows,
ind.leaf_blocks,
ind.distinct_keys
from user_indexes ind
where status = 'INVALID';
- 查询分区表失效的索引
select a.blevel,
a.leaf_blocks,
a.index_name,
b.table_name,
a.partition_name,
a.status
from user_ind_partitions a, user_indexes b
where a.index_name = b.index_name
and a.status = 'UNUSABLE';
分区表索引失效的操作
| 操作动作 | 操作命令 | 是否失效(全局索引) | 如何避免(全局索引) | 是否失效(分区索引) | 如何避免(分区索引) |
|---|---|---|---|---|---|
| truncate分区 | alter table part_tab_trunc truncate partition p1 ; | 失效 | alter table part_tab_trunc truncate partition p1 Update GLOBAL indexes; | 没影响 | N/A |
| drop分区 | alter table part_tab_drop drop partition p1; | 失效 | alter table part_tab_drop drop partition p1 Update GLOBAL indexes; | 没影响 | N/A |
| split分区 | alter table part_tab_split SPLIT PARTITION P_MAX at(30000) into (PARTITION p3,PARTITION P_MAX); | 失效 | alter table part_tab_split SPLIT PARTITION P_MAX at (30000) into (PARTITION p3,PARTITION P_MAX) update global indexes; | 没影响 | N/A |
| add分区 | alter table part_tab_add add PARTITION p6 values less than (60000); | 没影响 | N/A | 没影响 | N/A |
| exchange分区 | alter table part_tab_exch exchange partition p1 with table normal_tab including indexes; | 失效 | alter table part_tab_exch exchange partition p1 with table normal_tab including indexes update global indexes; | 没影响 | N/A |
全局临时表:全局临时表分为两种类型,一种是基于会话的全局临时表(on commit preserve rows);一种是基于事务的全局临时表(on commit delete rows)
create global temporary table [临时表名] on commit (preserve rows)|(delete rows) as select * from [数据表];
eg:
create global temporary table tmp on commit preserve rows as select * from dba_objects;
全局临时表特点:
- 一、高效删除记录;
- 二、不同会话访问临时表看到的会话是不同的
select * from v$mystat where rownum=1;
ps:基于事务的临时表在事务提交和会话连接退出时,临时表数据会被删除;基于会话的临时表就是在会话连接退出时,临时表数据被删除
索引组织表:
压缩技术
- 表压缩
ALTER TABLE t MOVE COMPRESS ;
- 索引压缩
create index idx2_object_union on t2 (owner , object_type , object_name );
ALTER index idx2_object_union rebuild COMPRESS ;
簇表:簇由一组共享多个数据块的多个表组成,它将这些表的相关行一起存储到相同数据块中,这样可以减少查询数据所需的磁盘读取量。新建簇之后,在簇中新建的表被称为簇表
ps:表结构设计时,最好存放什么数据就设计为什么类型,避免执行时类型转换,影响性能
Oracle索引知识
索引由根块(Root)、茎块(Branch)、叶子块(Leaf)组成,其中叶子块主要存储索引列具体值(Key Column Value)以及能定位到数据块具体位置的Rowid,茎块和根块主要保存对应下级对应索引
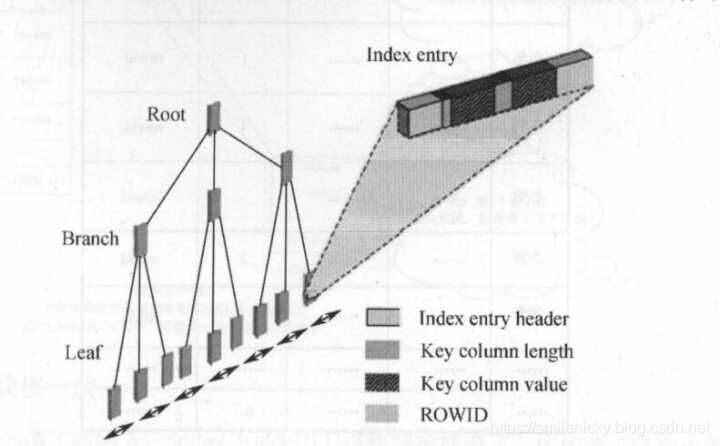
索引特性:
- 索引本身是有序的
- 索引本身能存储列值
注意:
- 仅等值无范围查询时,组合的顺序不影晌性能
drop table t purge;
create table t as select * from dba objects;
update t set object_id=rownum ;
commit;
create index idx_id_type on t(object_id, object_type) ;
create index idx_type_id on t(object_type , object_id) ;
set autotrace off;
alter session set statistics_level=all ;
select /*+index(t idx_id_type)*/ * from t where object_id=20 and object_type='TABLE';
select * from table(dbms_xplan.display cursor(null , null , 'allstats last'));
select /*+index(t,idx_type id)*/ * from t where object_id=20 and object_type= 'TABLE';
select * from table(dbms_xplan.display cursor(null , null , 'allstats last'));
- 范围查询时,组合索引最佳顺序一般是将等值查询的列置前
select /*+index (t, idx_id_type)*/ * from t where object_id>=20 and object_id<2000 and
object_type='TABLE';
select /*+index (t , idx_type_id) */ * from t where object_id>=20 and object_id<2000
and object type='TABLE';
- Oracle不能同时在索引根的两段寻找最大值和最小值
set autotrace on
select max(object_id) , min(object_id) from t;
笛卡尔乘积写法:
set autotrace on
select max, min
from (select max(object_id) max from t ) a ,
(select min(object_id) min from t ) b;
索引最新的数据块一般是在最右边
索引的缺点
- 热快竞争:索引最新的数据块一般在最右边,而访问也一般是访问比较新的数据,所以容易造成热快竞争
- 更新新增问题:索引本身是有序的,所以查询时候很快,但是更新时候就麻烦了,新增更新索引都需要保证排序
索引失效
索引失效分为逻辑失效和物理失效
- 逻辑失效
逻辑失效是因为一些sql语法导致索引失效,比如加了一些函数,而索引列不是函数索引 - 物理失效
物理失效是真的失效,比如被设置unusable属性,分区表的不规范操作也会导致索引失效等等情况
alter index index_name unusable;
索引分类:BTree索引、位图索引、函数索引、反向索引、全文索引
位图索引:位图索引储存的就是比特值
函数索引:就是将一个函数计算的结果存储在行的列中
自定义函数的情况,要加上deterministic关键字
自定义一个函数:
create or replace function f_addusl(i int) return int is
begin
return(i + 1);
end;
建函数索引
create index idx_ljb_test on t(f_addusl(id));
出现:ORA-30553:函数不能确定
方法:加上deterministic关键字
create or replace function f_addusl(i int) return int deterministic is
begin
return(i + 1);
end;
在自定义函数代码更新时,对应的函数索引也要重建,否则不能用到原来的函数索引
反向索引:反向索引其实也是BTree索引的一种特例,不过在列中字节会反转的(反向索引是为了避免热快竞争,比如索引列中存储的列值是递增的,比如250101,250102,按照BTree索引的特性,一般是按照顺序存储在索引右边的,所以容易形成热快竞争,而反向索引可以避免这种情况,因为反向索引是这样存储的,比如101052,201052,这样列值就距离很远了,避免了热快竞争)
反向索引不能用到范围查询
全文索引:所谓Oracle全文索引是通过Oracle词法分析器(lexer)将所有的表意单元term存储dr$开头的表里并存储term出现的位置、次数、hash值等等信息,Oracle提供了basic_lexer(针对英语)、chinese_vgram_lexer(汉语分析器)、chinese_lexer(新的汉语分析器)
- basic_lexer:是一种适用于英文的分析器,根据空格或者标点符号将词元分离,不管对于中文来说是没有空格的,所以这种分析器不适合中文
- chinese_vgram_lexer:这是一种原先专门的中文分析器,支持所有的汉字字符集,比如zhs16gbk单点。这种分析器,分析过程是按字为单元进行分析的,举个例子,“索引本身是有序的”,按照这种分析器,会分成词元“索”、“索引”、“引本”、“本身”、“身是”、“是有”、“有序”、“序的”、“的”这些词元,然后你发现像“序的”这些词在中文中基本是不成立的,不过这种Oracle分析器本身就不认识中文,所以只能全部分析,很明显效率是不好的
- chinese_lexer:这是一种新的中文分析器,前面提到chinese_vgram_lexer这种分析器虽然支持所有的中文字符集,但是效率不高,所以chinese_lexer是对其的改进版本,这种分析器认识很多中文词汇,能够比较快查询,提高效率,不过这种分析器只能支持utf-8字符集
drop table t purge;
create table t as select * from dba_objects where object_name is not null;
update t set object_name ='高兴' where rownum<=2;
commit;
select * from t where object_name like '%高兴%';
//设置词法分析器
BEGIN
ctx_ddl.create_preference ('lexer1', 'chinese_vgram_lexer');
END;
//授权
grant ctxapp to scott;
alter user ctxsys account unlock;
alter user ctxsys identified by ctxsys;
connect ctxsys/ctxsys;
grant execute on ctx_ddl to scott;
connect ljb/ljb;
//删除全文索引
drop index idx_content;
//查看数据文件信息
select * from v$datafile;
//建立全文索引
CREATE INDEX idx_content ON t(object_name) indextype is ctxsys.context parameters('lexer lexer1');
//执行同步命令
exec ctx_ddl.sync_index('idx_content','20M');
Oracle表连接
两个表之间的表连接方法有排序合并连接、嵌套循环连接、哈希连接、笛卡尔连接
排序合并连接(merge sort join)
嵌套循环连接(Nested loop join)
哈希连接(Hash join)
笛卡尔连接(Cross join)
【表连接方法特性区别】
(1)表访问次数区别
使用Hint语法强制使用nl
select /*+ leading(t1) use_nl(t2)*/ * from t1,t2
where t1.id = t2.id
and t1.id in (17,19);
查看执行计划
SQL> select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
PLAN_TABLE_OUTPUT
SQL_ID 245z7n1cxaf3m, child number 0
-------------------------------------
SELECT /*+ leading(t1) use_nl(t2)*/ * FROM t1, t2 WHERE t1.id = t2.t1_id
Plan hash value: 1967407726
--------------------------------------------------------------------------------
-----
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buff
ers |
--------------------------------------------------------------------------------
-----
| 0 | SELECT STATEMENT | | 1 | | 300 |00:00:00.25 | 29
747 |
| 1 | NESTED LOOPS | | 1 | 300 | 300 |00:00:00.25 | 29
747 |
| 2 | TABLE ACCESS FULL| T1 | 1 | 300 | 300 |00:00:00.01 |
27 |
|* 3 | TABLE ACCESS FULL| T2 | 300 | 1 | 300 |00:00:00.25 | 29
720 |
--------------------------------------------------------------------------------
-----
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("T1"."ID"="T2"."T1_ID")
Note
PLAN_TABLE_OUTPUT
- dynamic sampling used for this statement (level=2)
已选择24行。
Nested sort join中,驱动表被访问0或1次,被驱动表被访问0或者n次,n是驱动表返回的结果集条数
然后同样可以进行hash join、merge join的实践,hash join用/*+ leading(t1) use_hash(t2) */
Hash join中驱动表被访问0或者1次,被驱动表也一样
merge sort join中驱动表被访问0或者1次,被驱动表也一样
(2)表连接顺序影响
对于前面的用t1为驱动表的情况,现在换一下顺序,
SQL>SELECT /*+ leading(t2) use_nl(t1)*/ * FROM t1, t2 WHERE t1.id = t2.t1_id;
SQL> select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
PLAN_TABLE_OUTPUT
SQL_ID fgw5v7y16yn4m, child number 0
-------------------------------------
SELECT /*+ leading(t2) use_nl(t1)*/ * FROM t1, t2 WHERE t1.id = t2.t1_id
Plan hash value: 4016936828
--------------------------------------------------------------------------------
-----
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buff
ers |
--------------------------------------------------------------------------------
-----
| 0 | SELECT STATEMENT | | 1 | | 300 |00:00:00.30 | 70
139 |
| 1 | NESTED LOOPS | | 1 | 300 | 300 |00:00:00.30 | 70
139 |
| 2 | TABLE ACCESS FULL| T2 | 1 | 9485 | 10000 |00:00:00.01 |
119 |
|* 3 | TABLE ACCESS FULL| T1 | 10000 | 1 | 300 |00:00:00.29 | 70
020 |
--------------------------------------------------------------------------------
-----
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("T1"."ID"="T2"."T1_ID")
Note
PLAN_TABLE_OUTPUT
- dynamic sampling used for this statement (level=2)
已选择24行。
可以看出表连接顺序对NL连接是有影响的,同理实验,可以看出对hash join也是有影响的,而merger join不影响
(3)表连接排序
对于这几种表连接,可以用set autotrace on方式查看sorts属性,可以得出只有merge join是有排序的,Nl连接和hash join是无序的
(4)各表连接失效情况
hash join不支持的条件是“>、<、<>、like”的连接方式,merge join不支持的条件是“<>、like”支持“<、>”的情况,而nl连接没有限制,这是几种表连接方法的区别
EXIST一定比IN查询快?

count(列名)一定比count(*)查询快?

《收获,不止SQL优化》读书笔记的更多相关文章
- csapp读书笔记-并发编程
这是基础,理解不能有偏差 如果线程/进程的逻辑控制流在时间上重叠,那么就是并发的.我们可以将并发看成是一种os内核用来运行多个应用程序的实例,但是并发不仅在内核,在应用程序中的角色也很重要. 在应用级 ...
- CSAPP 读书笔记 - 2.31练习题
根据等式(2-14) 假如w = 4 数值范围在-8 ~ 7之间 2^w = 16 x = 5, y = 4的情况下面 x + y = 9 >=2 ^(w-1) 属于第一种情况 sum = x ...
- CSAPP读书笔记--第八章 异常控制流
第八章 异常控制流 2017-11-14 概述 控制转移序列叫做控制流.目前为止,我们学过两种改变控制流的方式: 1)跳转和分支: 2)调用和返回. 但是上面的方法只能控制程序本身,发生以下系统状态的 ...
- CSAPP 并发编程读书笔记
CSAPP 并发编程笔记 并发和并行 并发:Concurrency,只要时间上重叠就算并发,可以是单处理器交替处理 并行:Parallel,属于并发的一种特殊情况(真子集),多核/多 CPU 同时处理 ...
- 读书笔记汇总 - SQL必知必会(第4版)
本系列记录并分享学习SQL的过程,主要内容为SQL的基础概念及练习过程. 书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL i ...
- 读书笔记--SQL必知必会18--视图
读书笔记--SQL必知必会18--视图 18.1 视图 视图是虚拟的表,只包含使用时动态检索数据的查询. 也就是说作为视图,它不包含任何列和数据,包含的是一个查询. 18.1.1 为什么使用视图 重用 ...
- 《C#本质论》读书笔记(18)多线程处理
.NET Framework 4.0 看(本质论第3版) .NET Framework 4.5 看(本质论第4版) .NET 4.0为多线程引入了两组新API:TPL(Task Parallel Li ...
- C#温故知新:《C#图解教程》读书笔记系列
一.此书到底何方神圣? 本书是广受赞誉C#图解教程的最新版本.作者在本书中创造了一种全新的可视化叙述方式,以图文并茂的形式.朴实简洁的文字,并辅之以大量表格和代码示例,全面.直观地阐述了C#语言的各种 ...
- C#刨根究底:《你必须知道的.NET》读书笔记系列
一.此书到底何方神圣? <你必须知道的.NET>来自于微软MVP—王涛(网名:AnyTao,博客园大牛之一,其博客地址为:http://anytao.cnblogs.com/)的最新技术心 ...
- Web高级征程:《大型网站技术架构》读书笔记系列
一.此书到底何方神圣? <大型网站技术架构:核心原理与案例分析>通过梳理大型网站技术发展历程,剖析大型网站技术架构模式,深入讲述大型互联网架构设计的核心原理,并通过一组典型网站技术架构设计 ...
随机推荐
- get与post一些特殊情况下
p=574"> 文章已经迁移至http://androiddevelop.cn/?p=574 版权声明:本文博客原创文章.博客,未经同意,不得转载.
- INCORRECT PERMISSIONS ON /USR/LIB/PO1KIT-AGENT-HELPER-1(NEEDS TO BE SETUID ROOT)
INCORRECT PERMISSIONS ON /USR/LIB/PO1KIT-AGENT-HELPER-1(NEEDS TO BE SETUID ROOT) # sudo chmod +s /us ...
- App.xaml介绍
在App.xaml.cs中指定 public App () { InitializeComponent(); MainPage = new XamarinDemo.MainPage(); } 同时,这 ...
- ItemsPanelTemplate
用以定义集合控件的容器外观,如ListBox,Combox 等等使用一个自定义的ListBox用以说明,其默认外观是上下排列,这里修改成横向排列 <Window.Resources> &l ...
- SingletonBaseTemplate
public static byte[] writeValueAsZipByte(List<CraneDataDtls> dtls) { ObjectMapper mapper = new ...
- mysql 优化 读写分离 主从复制
1:mysql所在服务器内核 优化 ---------此优化可由系统运维人员完成 2:mysql配置参数优化(my.cnf) -------- 此优化需进行压力测试来进行参数调整 3:sql语句及表 ...
- QLocalServer与QLocalSocket进程通讯
在Qt中,提供了多种IPC方法,作者所用的是QLocalServer和QLocalSocket.看起来好像和Socket搭上点边,实则底层是windows的name pipe.这应该是支持双工通信的. ...
- Windows 10开发基础——启动默认应用的URI
主要内容:通过指定的URI来启动默认的应用(设置,应用商店,地图,人脉) 方法一:直接在XAML中添加如下代码 <TextBlock x:Name="LocationDisabledM ...
- 零元学Expression Blend 4 - Chapter 14 用实例了解布局容器系列-「Pathlistbox」II
原文:零元学Expression Blend 4 - Chapter 14 用实例了解布局容器系列-「Pathlistbox」II 本章将延续上一章的范例,步骤解析. 本章将延续上一章的范例,步骤解析 ...
- shell转义符
转义是一种引用单个字符的方法. 一个前面放上转义符 (\)的字符就是告诉shell这个字符按照字面的意思进行解释, 换句话说, 就是这个字符失去了它的特殊含义. 在某些特定的命令和工具中, 比如ech ...